
AIが候補者リストを作成提案する「AIエージェントモード」提供開始 | Wantedly, Inc.
この度、ビジネスSNS「Wantedly」において、企業が採用活動を行う際にAIが採用要件理解から候補者のスクリーニング、リスト化までを一元的に行う新機能「AIエージェントモード」を提供開始しま...
https://www.wantedly.com/companies/wantedly/post_articles/1025286
ウォンテッドリーでバックエンドエンジニアをしている冨永(@kou_tominaga)です。2025年11月に AI エージェントモード機能をリリースしましたが、リリース後の利用データを分析する中で、LLMが意図しない条件を一定割合で生成されていることが分かりました。本記事では、この問題をどのように発見し、どのように改善し、どのような成果につながったのかを紹介します。
AIエージェントモード機能とは
背景
分析のアプローチ
結果
まとめ
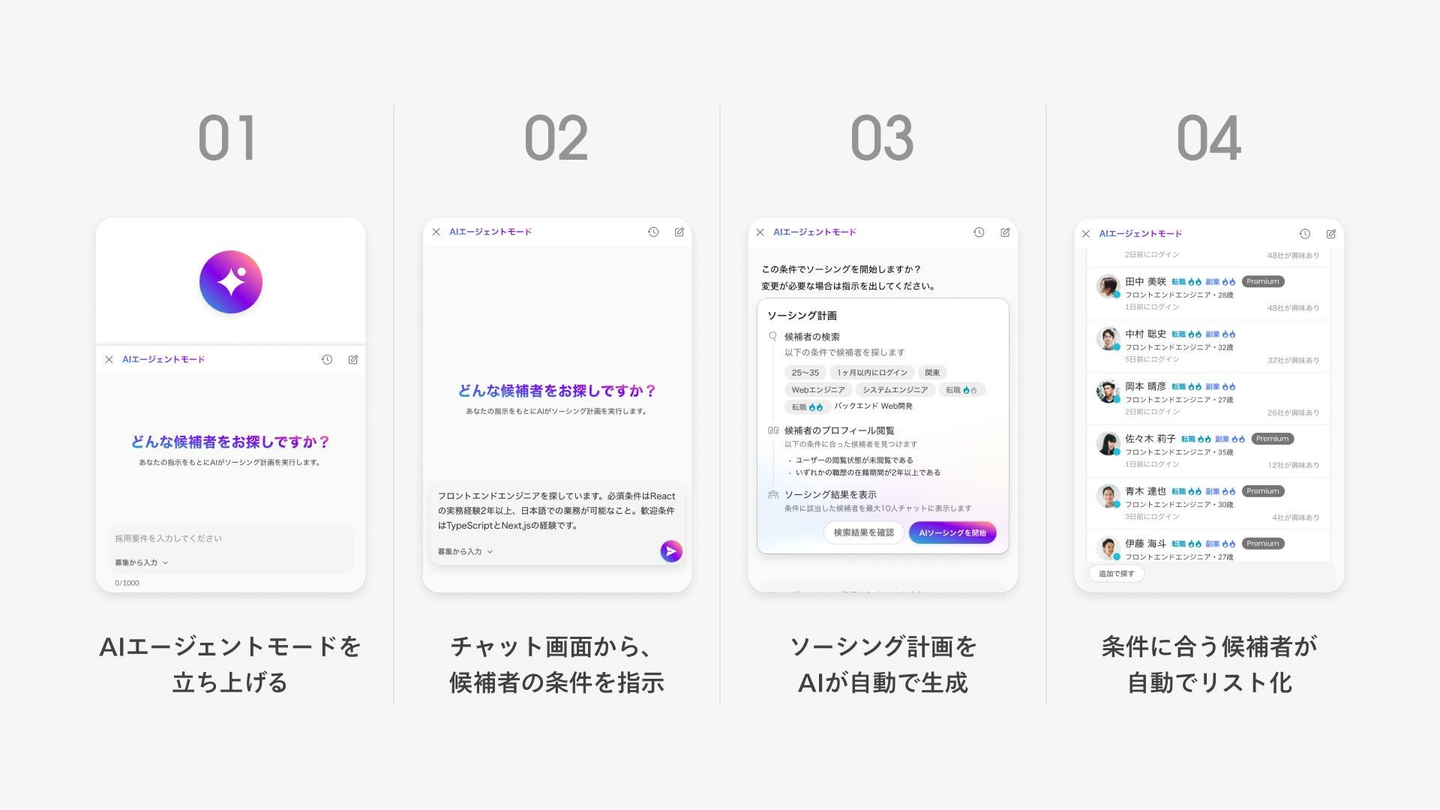
AIエージェントモード機能とは2025年11月25日にリリースした機能で、AIが採用担当者に代わってスカウト送信対象の候補者を自動で探索するものです。採用担当者が採用要件を入力するだけで、AI がソーシング計画を生成し、候補者を自動リスト化する体験を提供します。
この機能により、これまで採用担当が時間をかけて行っていた「採用要件の整理・検索・候補者選定」の一連の作業を AI が自動化することで、ソーシングに割いていた工数を大幅に削減し、担当者が本来注力すべきコミュニケーションにリソースを戻すことを目指しています。
AIエージェントモードでは「魅力的な候補者に出会えた数」を測る指標として、スカウト送信数を主要KPIに設定しています。リリース後は、機能のさらなる成長余地を見極めるために離脱率へ着目し、改善につながる示唆を探りました。
離脱率を可視化するにあたり、ファネル分析を実施しました。ファネル分析とは、ユーザーが目的のアクションに到達するまでのプロセスを段階ごとに分解し、どのステップに最適化の余地があるかを明らかにするための手法です。
ユーザーが目的のアクションに至るまでの流れを最適化するために、以下のステップに整理して状況を確認しました。
1. ユーザーが AI エージェントを起動し、メッセージを送信する
2. 生成されたソーシング計画にもとづいてAI ソーシングを実行する
3. 推薦された候補者にスカウトを送信する
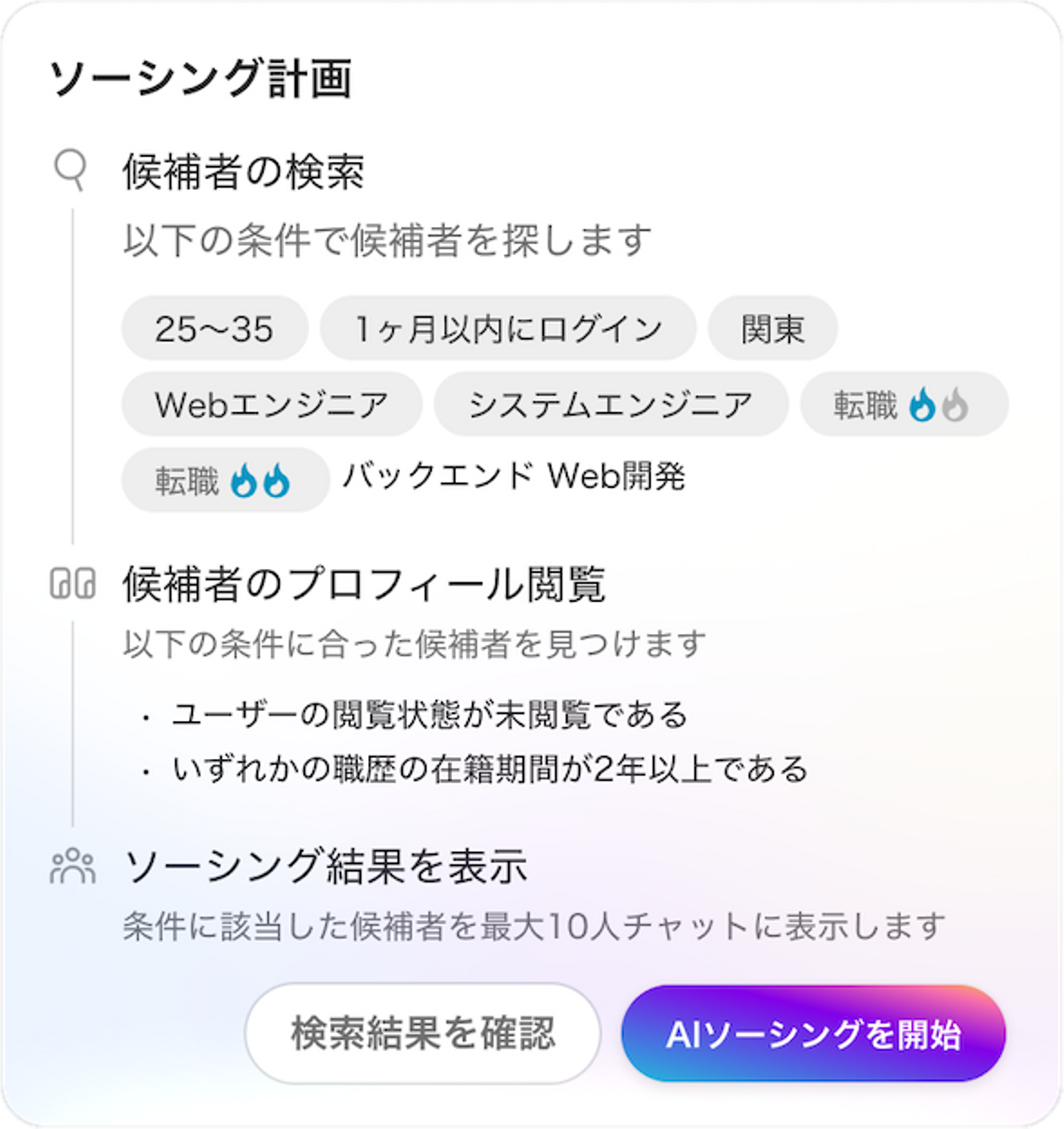
結果、「②生成されたソーシング計画にもとづいて AI ソーシングを実行する」で20%の離脱が発生していることが分かりました。 ソーシング計画を確認した直後の段階でこれだけの離脱が発生していることは、当初の想定よりも多く、ユーザー体験上のボトルネックになっている可能性があると判断しました。
原因の1つとして、ソーシング計画がユーザーの意図を正しく反映できていない可能性があると仮説を立てました。ソーシング計画の内容が意図と乖離している場合、ユーザーは機能の利用を中断したり、計画を再作成するために新しいチャットを開始してしまうと考えられるためです。
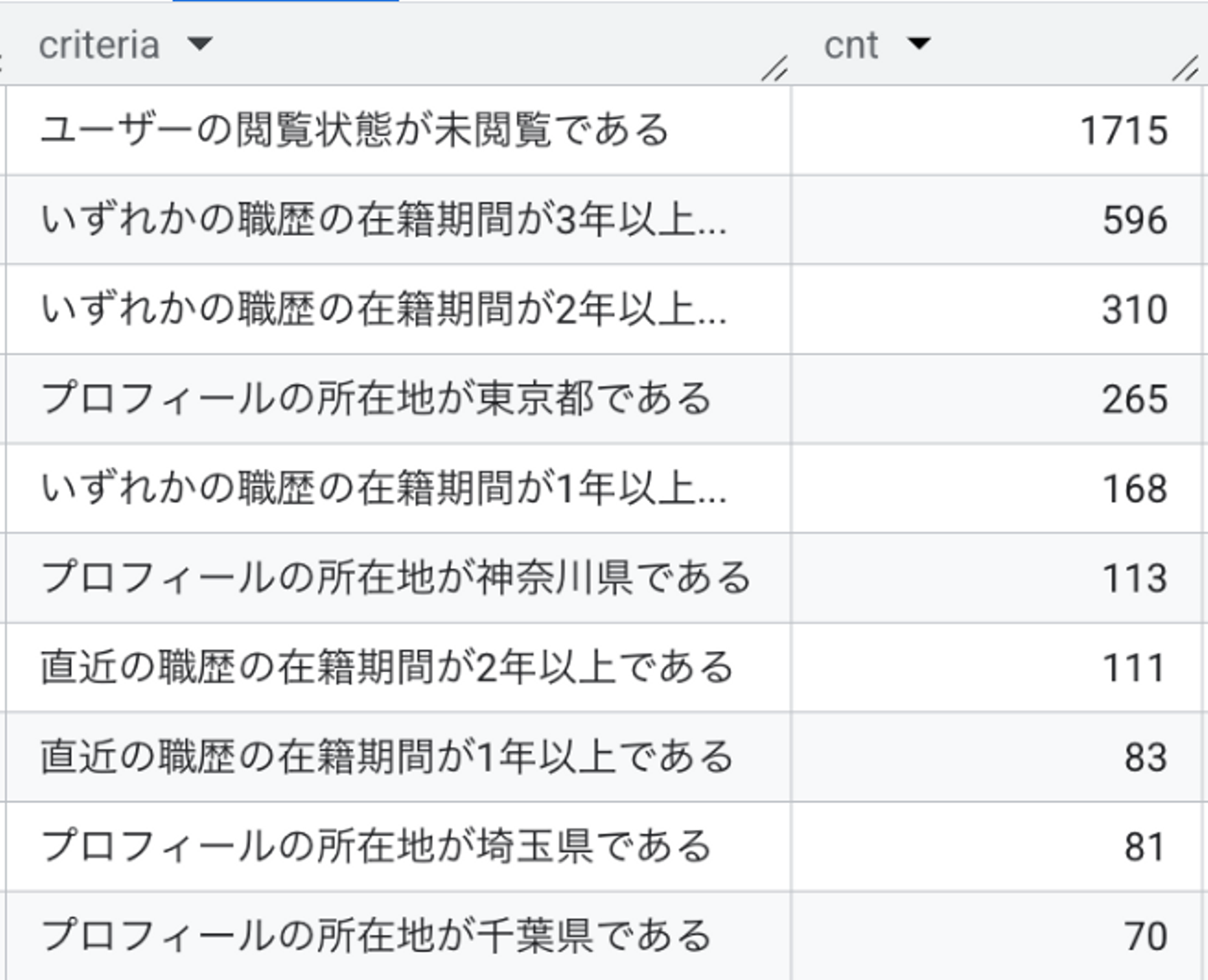
「ソーシング計画がユーザーの意図を正しく反映できていない」という仮説を検証するため、実際に作成されたソーシング計画を分析しました。 結果、想定では利用頻度が低いはずの条件である「いずれかの職歴の在籍期間が◯年以上である」が、全体の半数以上のソーシング計画に含まれていることが分かりました。この出現頻度は事前の想定と大きく乖離しており、ユーザーの意図が正しく反映されていない可能性を示唆しています。
実際に当該条件が生成されたケースのユーザー入力を確認すると、多くの場合で明示的に指定されていない条件であることが確認できました。原因は、LLMがあらかじめ定められたルールの範囲内でソーシング計画を生成するよう設定されており、意図しない組み合わせが選ばれやすい状態になっていたためです。
ソーシング計画のルールは、「[対象]の[属性]は[条件]である」というフォーマットに対して、選択肢となる単語を列挙し、LLMがそこから選ぶ仕組みを採用していました。これはブランドイメージを損なう可能性のある出力を避けること、そして定義されたルールから逸脱させないことを目的としていました。しかし、その制約とシステムプロンプトの組み合わせが適切ではなく、意図しない条件が生成されやすい状況を招いていました。
そのためシステムプロンプトを修正し、意図せず該当条件が生成されないよう改善しました。
修正のリリース後、「生成されたソーシング計画にもとづいて AI ソーシングを実行する」までの到達率が3.9%、「推薦された候補者にスカウトを送信する」の到達率は5.7%増加しました。これは、生成されたソーシング計画が、利用者の意図を適切に反映していると受け取られる割合が増え、ユーザーが次のアクションに進む意思決定をしやすくなったことを示しています。LLM の出力品質が、定量指標としてユーザー行動に反映された結果と言えます。
今回の取り組みを通じて得た最も重要な学びは、LLM を組み込んだ機能では、リリース後に想定外の出力パターンが必ず発生するという点です。主要なユースケースについては事前にテストを行っていましたが、自然言語入力を受け付ける AI エージェント機能の特性上、入力表現の多様性をすべて網羅し、精度を完全に担保することは現実的ではありません。
そのため、LLM 機能の開発においては「リリースして終わり」ではなく、実利用データを前提に継続的に改善する設計が不可欠です。具体的には、問題の発生箇所を特定できるログをあらかじめ仕込んでおくことや、改善サイクルを事前に設計しておくことが、安定した体験提供につながると考えています。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()

/assets/images/16907545/original/ec791cd3-ea53-45e2-bc6f-a1262b413594?1753696883)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

