リクエスト間のプロンプトキャッシュ - Amazon Bedrock プロンプトキャッシュ - AWS
Amazon Bedrock プロンプトキャッシュにより、サポート対象モデルはリクエスト間で繰り返されるプロンプトの一部をキャッシュできます。
https://aws.amazon.com/jp/bedrock/prompt-caching/
こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。この記事は夏のアドベントカレンダー15日目の記事です。
この記事では、WantedlyにおいてAmazon Bedrockを活用したコンテンツモデレーション業務を半自動化した取り組みについてご紹介しようと思います。
はじめに
モデレーションのフロー概要
Amazon Bedrockを用いたモデレーションシステム
Prompt Cachingによるコスト削減
Bedrock Prompt Managementによるエンジニア・非エンジニアの協働
導入後の変化
まとめ
Wantedlyでは、新しくコンテンツが投稿された際にその内容がガイドラインと照らし合わせて適切かどうかを確認する作業(モデレーション)が行われています。現在ではWantedlyのサービス内で新規公開されるコンテンツ量の増加に伴い、モデレーション担当者の作業工数が増大し、手動での確認ですべてをこなすことが困難な状態になりつつありました。
このような状況に対し、Wantedlyでは生成AIを活用してモデレーション業務を半自動化しています。
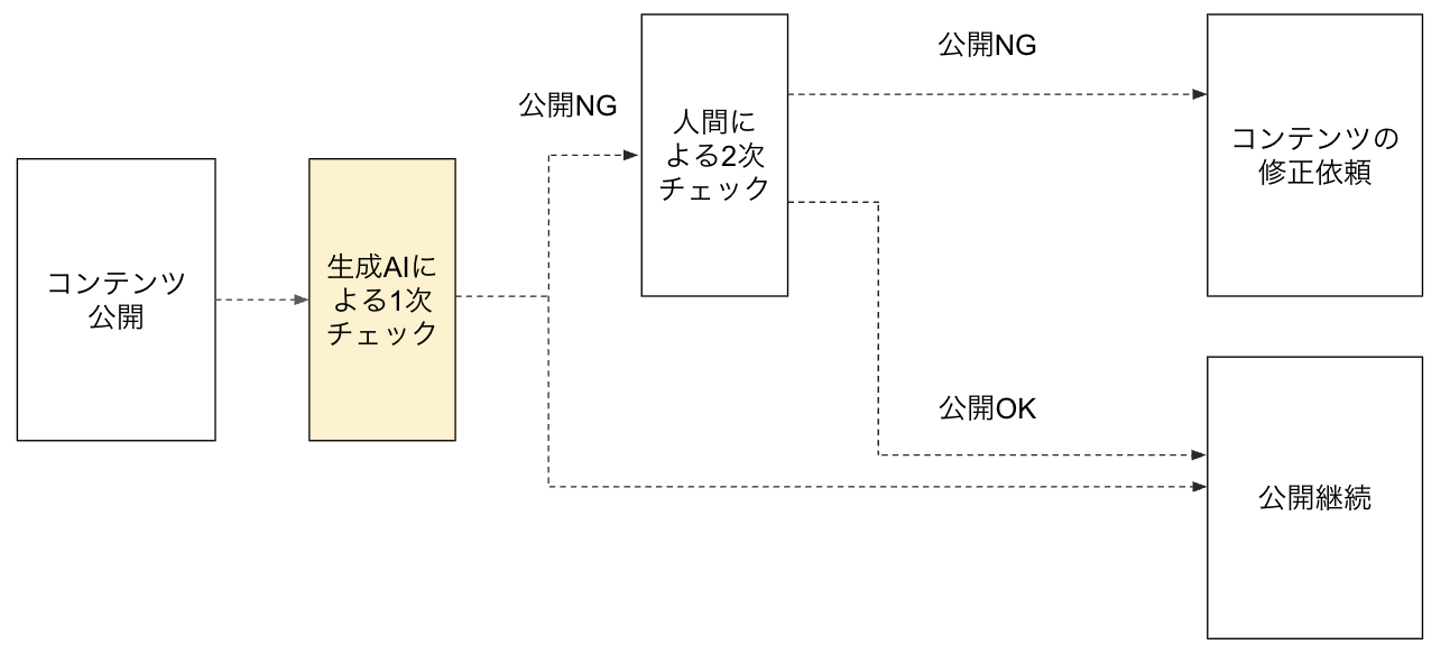
現在のモデレーション業務は大まかには下記のようなフローで行われています。
はじめに1次チェックとしてAmazon Bedrockの生成AIを活用してコンテンツのガイドラインと照合して違反がないかチェックします。ただし、生成AIによるチェックだと過剰にガイドライン違反に指摘するケースがあるため、生成AIによる判定理由を踏まえて人間による2次チェックが行われています。(現在は精度検証のために一部のチェックに限り生成AIがOKの判定を出したものについても目視確認も実施しています)
もともと1次チェックも人間が行っていましたが、コンテンツ量の増大に伴いモデレーション担当者の作業工数が増大していたため、現在では1次チェックを生成AIに部分的に置き換えています。
WantedlyではAWSのサービスを多く利用しており、今回のモデレーションの機能もAmazon Bedrockを活用して実現しています。今回は特に下記の2点については意識してシステム化しています。
これら2点についてどのように取り組んでいるかについてご紹介します。
モデレーション業務の対象になるコンテンツは日々大量に作成されており、単純に生成AIを使用する場合コスト増が懸念されます。ここでコストを気にして低コストのモデルを利用して、判定自体の精度が低下してしまっては本末転倒になってしまいます。
生成AIによってコンテンツモデレーションを自動化する場合、コンテンツの内容は毎回異なりますが、OK/NGの判断基準となるルール・ガイドラインの情報については毎回共通したものが使用されることになります。こうしたリクエストのたびに毎回共通したプロンプトを使用するような場合、Amazon Bedrockではプロンプトキャッシュと呼ばれる機能によってコスト削減可能になっています。
プロンプトキャッシュは、繰り返し利用されるプロンプトをキャッシュとして保存しておき、同じプロンプトが使用される際にキャッシュからトークンを読み取ることができ、読み取られたトークンについては割引きされた価格での課金に抑えることができます。
生成AIアプリケーションに広く利用されているLangChainでこの機能を実現する場合には、下記のように記述することでプロンプトキャッシュを利用することができます。
import requests
from langchain_aws import ChatBedrockConverse
llm = ChatBedrockConverse(model="us.anthropic.claude-3-7-sonnet-20245219-v1:0")
# Pull LangChain readme
get_response = requests.get(
"https://raw.githubusercontent.com/langchain-ai/langchain/master/README.md"
)
readme = get_response.text
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's LangChain, according to its README?",
},
{
"type": "text",
"text": f"{readme}",
},
{
"cachePoint": {"type": "default"},
},
],
},
]
response_1 = llm.invoke(messages)
response_2 = llm.invoke(messages)
usage_1 = response_1.usage_metadata["input_token_details"]
usage_2 = response_2.usage_metadata["input_token_details"]
print(f"First invocation:\n{usage_1}")
print(f"\nSecond:\n{usage_2}")このようにして毎回呼び出される同じプロンプトについてキャッシュを利用することでコスト効率化を行っています。
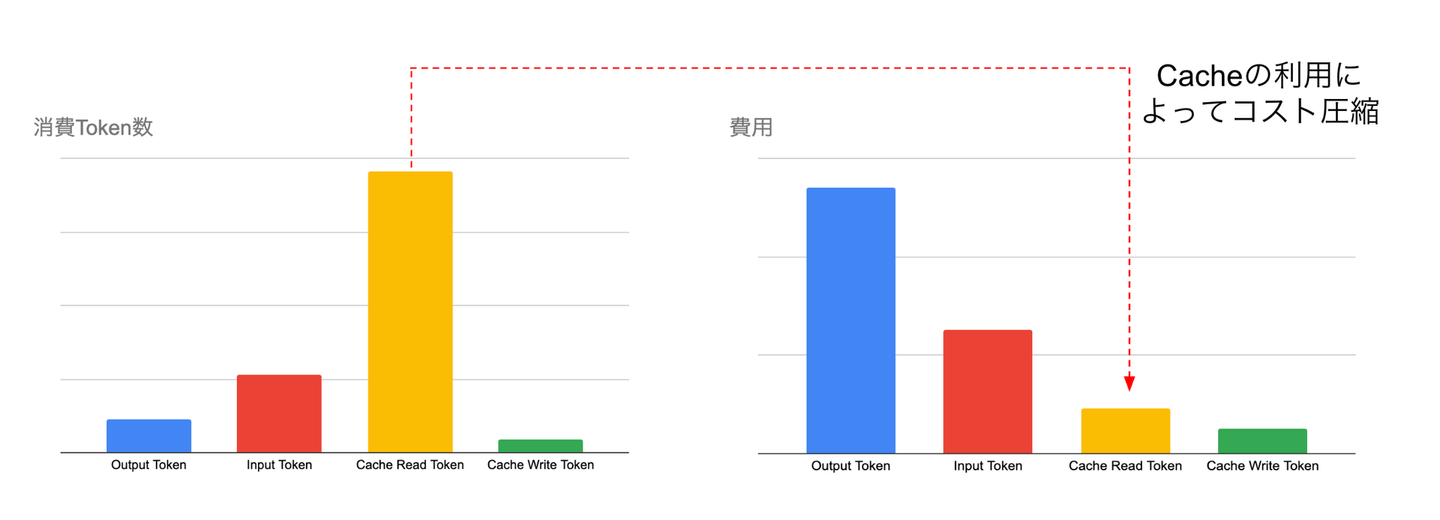
実際利用を開始したある日のToken数と費用について確認してみると、下記のようになっていました。
Input Tokenの多くでキャッシュが活用されることでコストを大幅に削減できていることが確認できます。これにより、今回の事例ではプロンプトキャッシングがコスト削減に対して非常に有効であることが確認できました。
コンテンツに関するガイドラインやチェックに用いるプロンプトは現在の状態が完璧というわけではなく、実際に使用していくうちに少しずつ修正されていきます。
先にご紹介した通りWantedlyのコンテンツモデレーション業務において2次チェックは人間の目で行っており、これは非エンジニア組織であるSupport Squadが担当しています。そのため、Support Squadがコンテンツのガイドラインについては詳細まで把握しており、Support Squadの方が実際に動かすプロンプトについてより正確に記述することができると予想されます。一方で、機能開発は開発組織が担っており、高速に改善サイクルを回すにはSupport Squadと開発組織がうまく協働する必要があります。
直感的にはSupport Squadだけでガイドライン・プロンプトを管理し、それ以外のシステムの部分を開発組織が担当すると効率が良さそうに思われます。このような状況に対してAmazon Bedrockではコンソール上からプロンプトを設定したり、プロンプト自体のバージョン管理を行うPrompt Managementの機能を活用しています。
現在では、このPrompt Managementの機能を活用して非エンジニアであるSupport Squadがプロンプトの作成を行う運用にしています。このように、エンジニアと非エンジニアの効率的な協働を実現できるよう工夫しています。
実際にAmazon Bedrockを用いたモデレーション機能を稼働させた効果も少しずつですが見え始めています。
今回のモデレーション機能を稼働させる前と比べて、人間によるチェック対象は約45%削減されました。もちろん判定精度についてはまだまだ完全ではありませんが、プロンプト調整によって精度向上が期待できる部分もあり、今後も継続的にプロンプト調整によって判定精度向上を図っていきます。
それだけでなく、1次チェックでは生成AIによってOK/NGの判定結果だけでなく、どのガイドラインについてどのような理由で違反と判定したかについても出力するようにしています。これにより、2次チェックでもコンテンツの中の一部に絞ってチェックすれば良くなり、2次チェックの負担軽減にもつながっています。
ガイドラインやプロンプトの微調整が必要になった際にもSupport Squad主導で判定精度を確認することができるため、Support Squad主導で改善活動が進められるようになりました。これにより、ガイドライン自体やそれに伴うプロンプトの調整にかかる作業も小さくなりました。
以上、新着募集のモデレーションを半自動化するためにAmazon Bedrockを活用した取り組みについてご紹介しました。コスト・運用面などを考慮してBedrockの機能を活用して担当者の負担軽減しているだけでなく、今後もSupport Squad主導で精度改善を行っていけるような仕組みにしています。まだまだモデレーション機能の判定精度は完璧とは言えませんが、今回の仕組みを使って今後も継続してモデレーション業務の効率化を進めていけたらと思っています。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
![]()





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

