/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

ウォンテッドリーにおける推薦システム開発の流れ | Wantedly, Inc.
はじめにこんにちは、ウォンテッドリーの合田(@hakubishin3)です。私は推薦チームに所属していて、機械学習領域のテックリード兼プロダクトマネージャーとして会社訪問アプリ「Wantedly...
https://www.wantedly.com/companies/wantedly/post_articles/864502
こんにちは、ウォンテッドリーでデータサイエンティストをしている林(@python_walker)です。
ウォンテッドリーでは、テクノロジーの力で人と仕事の適材適所を実現するために推薦システムの開発を行っています。これまでのウォンテッドリーでの推薦システムの開発に興味のある方はぜひ下の記事も読んでみてください。
この記事では、企業の採用担当者が見るおすすめ候補者の一覧画面での推薦において、直近の候補者や採用担当者の情報をうまく推薦に活用できていなかった状態を解消し、採用担当者にとっては魅力的な候補者が一覧に多く表示される体験を実現した施策について紹介します。
Wantedly Visitには、採用担当者が気になる候補者に対してスカウトを送るという機能があります。スカウトを送る候補者を探すときにリクルーターは下図のようなおすすめ候補者の一覧画面を使うことが一般的です。Wantedly Visitではこのおすすめ候補者の一覧に表示する候補者とその並び順を、機械学習を使って採用担当者に対してパーソナライズするということを行っています。
ここで使っているシステムは、2-stageからなる推薦システムとなっており、1段目では採用担当者が興味を持ちそうな候補者をおおまかに抽出し、2段目でマッチする順に並び替えを行っています。この記事で紹介する施策は、2段目のReRankerに関するものです。ReRankerには機械学習モデルを利用しており、候補者と採用担当者の過去の行動ログなどを活用したモデルの学習を行っています。ここでは、モデルの学習に使うためのデータをどのようにして構成しているのかをもう少し深堀りします。
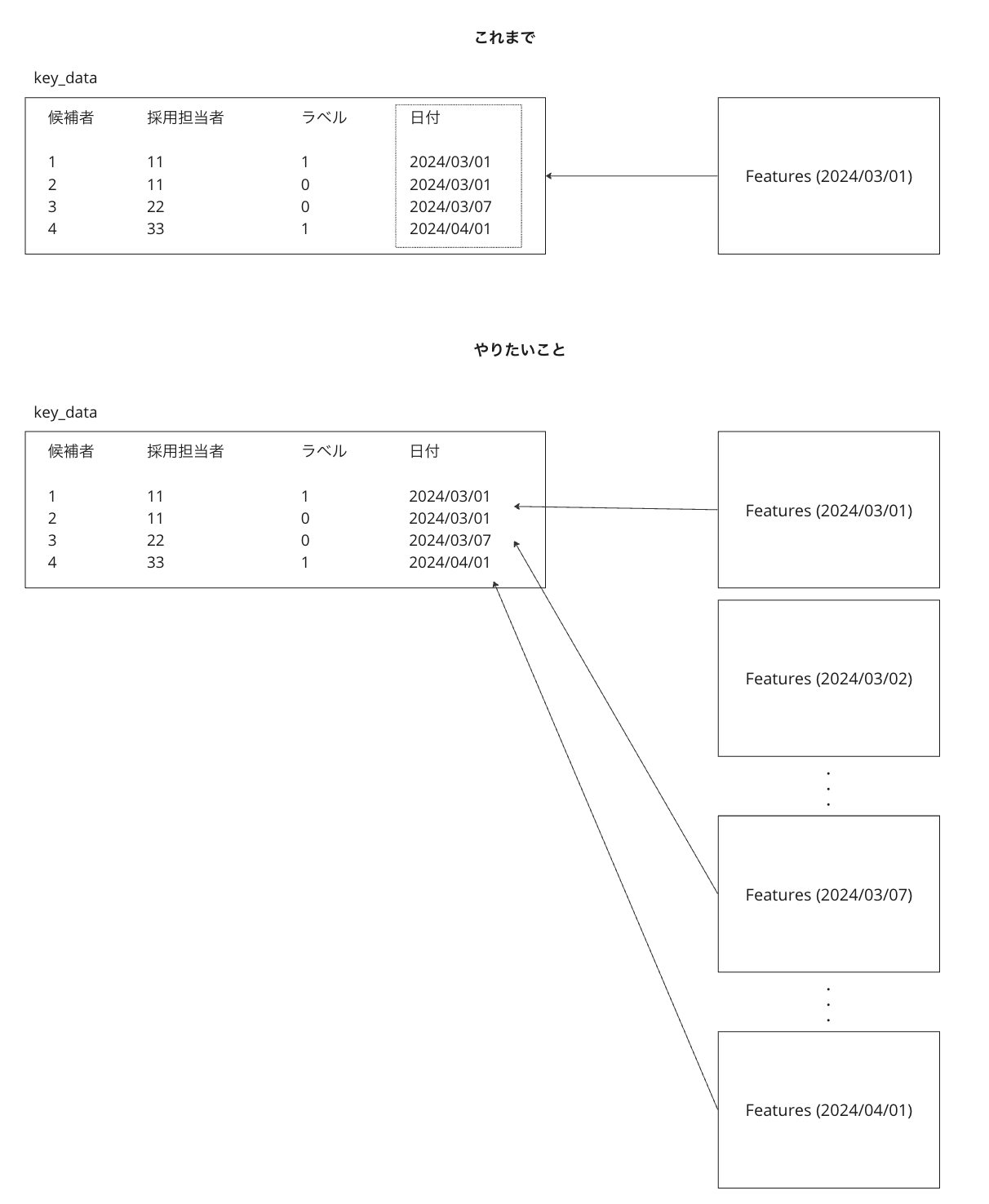
下図は、学習用データをどのような時間軸から取ってきているかを示した例です。学習用データのベースとなるのは、インタラクションがあった候補者・採用担当者のペアとインタラクションの種類です。学習の際にはこの3つ組(キーデータ)を過去の一定期間のログデータから構築します。このキーデータに紐づける特徴量に関しては、インタラクションが発生した時点より過去の候補者・採用担当者のログを取得して紐づけるという形を取っています。
上に紹介した学習用データの作り方には1つ大きな問題がありました。それは、候補者と採用担当者のインタラクションが発生した時点と、そのインタラクションに紐づける特徴量を計算した日付の間にずれが発生するということです。これを上の図を使って簡単に説明します。例えば、ある採用担当者Aが候補者Bに2024/4/1にスカウトを送ってマッチングが成立したというインタラクションがあったとします。このデータをモデルの学習に使うとき、それに紐づく特徴量は2024/2/1 ~ 2024/3/1の期間の採用担当者Aと候補者Bの行動を表すものになってしまいます。つまり、このデータを使った学習では、モデルに1ヶ月前までの特徴量を与えてマッチするかどうかを予測させるというタスクになっており、タスクが必要以上に難しいものになっています。
この問題をよりプロダクトに近い視点から見てみます。上の例を再度使うと、採用担当者Aと候補者Bはマッチングが成立していますが、モデルが持っているデータは古いので、特徴量を計算した時点では候補者BはWantedly Visitに登録したばかりでプロフィールがあまり記入されていないかもしれません。すると、このデータを見てモデルは「プロフィールがあまり記入されていなくてもマッチングが成立する」という関係を学習する可能性があります。すると採用担当者がおすすめ候補者の一覧を見たときに、プロフィールが少ししか書いていなくてスカウトを送るべきかどうか判断できないような候補者が多く上位に表示されるといった体験をする可能性があります。
一見すると、この課題は「直近の特徴量を結びつけるようにする」という解決策で簡単に解決しそうに見えます。しかし施策前のシステムでは単純には解決できない問題でした。というのも、これまではキーデータに紐づける特徴量は単一の日付のもとで計算すればよかったのですが、直近の特徴量を結び付けられるようにするためにはインタラクション情報を取得する期間すべての特徴量を計算して持っておく必要があります。施策前は特徴量の計算をモデルの学習と同じジョブ中で行っていましたので、特徴量の紐づけ方法を変えることによって計算負荷が大きく増大することになり、そのままでは実現することができませんでした。
課題に対する解決策まではわかっていて、その解決策を実行する際のボトルネックとなっている部分は特徴量を計算する負荷に関する部分だということまでわかったので、とるべき手法は特徴量をあらかじめ計算してどこかに持っておくというものになります。このような仕組みはすでにFeature Storeとして広く知られており商用のサービスもAWSやGCP上に存在していました。ただ商用のFeature Storeは機能として充実しすぎており今の自分達のプロダクトに必要な部分はごく一部であったこと、そして必要な部分だけであれば自分たちで実装できそうであることがわかったため、内製を行うという判断をしました。Feature Store内製の詳しい経緯や構造は下の発表資料にまとまっていますのでぜひ読んでみてください。
自分たちが実装したFeature StoreではBigQuery上で特徴量テーブルを管理する構成になっています。これにより、キーデータに対する特徴量の結び付けをBigQuery上で行うことができるようになり、リソースの問題が解決されました。Feature Storeを利用したときの学習用データの作成フローは以下のようになります。
このような構成にしたことにより、今までは図の"Ranking Job"で示されている部分でPythonを使ってキーデータと特徴量を紐づけていた処理はBigQueryでの処理に置き換わりました。このとき、ランキングの計算に使っている特徴量を管理するために、使う特徴量をYAMLで管理して、実行時にはYAMLから対応するクエリを動的に生成する仕組みを導入しています。YAMLは以下のような形式で作成しています。
feature_group1:
use_features: true
fill_strategy: hoge
feature_cols:
- feature1
- feature2
key_cols:
- key1
- key2このとき、生成されるSQLは以下のようになります。
with
key_data as (
select * from key_data_table
),
feature_group1 as (
select
feature1,
feature2,
key1,
key2,
_table_suffix as date,
from `projects.feature_store_datasets.feature_group1*`
where
_table_suffix between '20240301' and '20240401'
)
select
key_data.*,
coalesce(feature1, 'hoge') as feature1,
coalesce(feature2, 'hoge') as feature2,
from key_data
left join feature_group1
on key_data.key1 = feature_group1.key1
and key_data.key2 = feature_group1.key2
and key_data.date = feature_group1.dateYAMLで管理することにより、ランキングでどの特徴量をどのように使っているのかシンプルに管理できるようになり、新しい特徴量を追加したり削除したりするのも簡単にできるようになりました。
学習用データの作成方法を改善することによる推薦への効果を測るために、過去ログを用いたオフラインテストを実施したところ、より採用担当者にとって魅力的な候補者が一覧の上位に増えそうであるということが定量指標からわかりました。そのためこの変更のオンラインテストを実施し、この手法の価値を本番環境で検証しました。
インターリービングを使ったオンラインテストを行ったところ、主要KPIが大きく改善する変化が見られました。さらに、オンラインテストの結果を分析したところ、オフラインテスト時に期待されていた採用担当者にとって魅力的な候補者が一覧の上位に増えるという変化が実際にプロダクト上でも引き起こされていることが検証できました。
これは、より直近の候補者・採用担当者のデータをモデルで使えるようになったことで、最新の候補者・採用担当者の嗜好をモデルが読み取りやすくなったことで生じた傾向変化なのではないかと考えています。
この記事では、より直近のデータを機械学習モデルの学習に活用できるようにすることで、採用担当者が見るおすすめ候補者の一覧をより魅力的なものにした施策について紹介しました。この施策では解決のために技術的な課題もあり、それを解消するためにFeature Storeを内製するというチャレンジもありました。実装したFeature Storeにはまだまだ改善点が多いですが、Feature Storeというシステムに対する解像度を施策を通じて上げることができたので、今後継続的によりよいものにしていければと思っています。
また、私たちと一緒に、推薦システムという技術活用を促進して人と会社の理想的なマッチングを追求するデータサイエンティスト・機械学習エンジニアの仲間を探しています。少しでも私たちの取り組みに興味を持っていただけたら、以下の募集から「話を聞きに行きたい」ボタンをクリックしてください!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
![]()








/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
/assets/images/17431604/original/b63d01a0-86a0-4b2b-9c6e-cff7751f0752?1711528948)