こんにちは。ウォンテッドリーでデータサイエンティストをしている合田です。推薦システムの国際会議である Recsys2022 に参加して気になった発表内容をまとめましたので紹介します。一緒にRecSysに参加したメンバーたちのブログ記事は以下のリンクでまとめているので、ぜひ一緒にご覧ください。
今回の記事ですが、 RecSys in HR というワークショップの内容をまとめてみました。またせっかくの機会なので、本会議のHR関係の発表も追加しています。RecSys in HRは RecSys2021 から開催されているワークショップであり、その名前の通りHRアプリケーションにおける推薦システムの課題および取り組みについて議論する場となっています。
以降で添付している画像は RecSys in HR 2022 より引用しています。
目次 シゴトを取り巻く環境の変化 マッチング 公平性 1. シゴトを取り巻く環境の変化 ワークショップのパネルディスカッションの冒頭では、いま世界でどのような事象が発生していて働き方や仕事がどのように変化しつつあるのか紹介されていました。
世界的な人材不足 アメリカのコンサルティング会社の調査 によると、2030年までに世界的に8520万以上のジョブが空く可能性があり、年間収益に換算すると8兆4520億ドルほどと言われています。またアメリカだけでも、労働力不足により1兆7480億ドルの収益(経済全体のおよそ6%に相当)が失われる可能性があります。
要因として、 少子高齢化と労働人口の高齢化 が挙げられます。全世界で見ても高齢化が進んでおり、特に日本はその傾向が顕著です( 詳細 )。また 労働市場が逼迫している 状況であったりします。アメリカの有効求人倍率は2021年最終四半期で大きな値を取っており、求職者1人に対しておおよそ2つ分の求人があることになります( 詳細 )。
働き方や仕事の変化 コロナによって働き方や仕事に大きな変化が生じました。働き方という観点では リモートワーク の導入が大きく進み、労働者と労働場所に近郊に住むという実質的な制約が薄れてきています。また ワークライフバランス への注目も大きくなってきています。
仕事の変化としては、世界的なパンデミックによって収益が低下したセグメントがある一方で、ヘルスケアやECなどその間に急激に成長したセグメントもあったりします。新しい技術の導入によって 業務効率化 が実現し、仕事の進め方や種類も変化しつつあります。
公平性の重視 ジェンダーや人種など様々な点でバイアスが存在しますが、これらを是正しようという動きが世界で出ています。例えば、フィラデルフィアでは公正な雇用機会法を設けており、犯罪歴の有無にかかわらず雇用するようにしています。またリクルートホールディングスでは、2030年度までに年齢や障がい、人種などさまざまな障壁に直面している求職者3,000万人が有意義な雇用を得られるようサポートすることを約束しています( 詳細 )
これからの推薦システムについて 人材不足に対応するアプローチの1つは推薦システムです。求職者と雇用者のマッチングがより効率的に行えるようになる、つまりこれまで起きていた採用におけるミスマッチを減らして求職者が自身の興味やキャリアに対してマッチした仕事と出会えるようになることで、求職者に対してより多くの機会が与えられることが期待されます。
しかし、HRにおける推薦システムには公平性が担保されていないことが課題に挙げられています。欧州ではユーザの人生に影響を与えうるHRのAIはハイリスクと考えられており、公平性を是正する流れにおいてバイアスを助長しうるAIを作らないためにも公平性に強い関心が寄せられています。
以降では、「マッチング」と「公平性」というテーマに分けて、RecSys in HRや本会議におけるHRに関連したコンテンツ(論文、パネル、Industry talk、keynote など)を紹介します。
2. マッチング ワークショップの1つ目のkeynoteでは 定量と定性をかけ合わせたサービス改善 について紹介されました。
なぜ 定量と 定性をかけ合わせるべきなのか 講演者のRobyn Rapさんは、機械学習の業界では実験における 観測が少ない ことを疑問視しています。本来、科学的手法は観測から始まりそこから課題や仮説を立てて実験に進めますが、観測をすっ飛ばして実験を行うケースを耳にすると話していました。例えば「データを更に増やすことでうまくいくだろう」や「新しい機能を追加すればうまくいくだろう」など、適切な課題もしくは仮説に沿っていない実験を進めてしまうことで結果的にユーザに寄り添わない仕事になってしまうことを懸念しています。
また業界で使われている観測のアプローチにおいて ユーザスタディが少ない ことを指摘しています。既存の情報検索や推薦システムに関連する書籍では、RMSEやAccuracyなどのオフライン評価指標について記載していることが多く、ユーザースタディについて触れている書籍は少ないです。より直接的にユーザの行動を観測しないと、ユーザのためと言っても間違った目標を設定してしまう可能性があります。
これらの課題から、 量的な方法と質的な方法を組み合わせて観測する ことを提案しています。量的な方法は「現象がどの程度起きているのか」という問いを答えられるのに対して、質的な方法は「なぜ現象が生じているのか」という問いに答えるのが得意です。それぞれの方法の得意なことを組み合わせることで、様々な観点から多角的に対象を調べて今まで知りえなかった仮説を見出し、それがどの程度起きているものか調べることができます。
なぜ求人サービスで定性と定量のかけ合わせが重要なのか 従来の推薦システムと求人サービスにおける推薦システムには異なる点があります。例えばECではユーザのほぼ全ての行動はプラットフォーム上で行われます。一方で求人サービスではプラットフォーム上で仕事を探したり応募できますが、選考はプラットフォーム外での行動となるので、ユーザが仕事を得るまでのフローにおいて後ろのファネルほど可視性が失われてしまいます。このように プラットフォーム上で取れるデータだけではユーザの経験したことを全て把握することができない ことも、定量だけでなく定性も重要視するべき理由になっています。
ケーススタディ1: アイトラッキング Indeedにおける定性と定量を組み合わせた事例が3点紹介されました。Ⅰつ目の事例はアイトラッキングです。これは、ユーザに機器を装着してもらった状態で実際にサービスを触ってもらいながら視線を追跡します。このアプローチを使うことで、ユーザの視線が指定のページのどこにあるのかというログで取れない情報を取得することができます。
Indeedでは求職者がどのぐらい求人情報を見ているのか調べるためにアイトラッキングを実施し、その結果 モバイルで表示されている求人の25%が実際には見られていない ことが分かりました。Indeedでは応募数/impressionという指標として定義して最適化していましたが、アイトラッキングはこの指標の分母に大きなノイズが含まれていることを明らかにしています。この調査の結果を持って、impressionログの修正を取り組んでいると述べていました。
ケーススタディ2: 日記調査 2つ目の事例は日記調査(Diary studies)です。ユーザに数日から数ヶ月にかけて定期的に質問に回答してもらう調査であり、ユーザーの習慣や意見が時間とともにどのように変化していくかを理解する場合に有効です。
Indeedでは新しい仕事を始めた30人の求職者を対象に調査を行ったところ、 調査開始からⅠヶ月後には30人中4人が仕事を離職している ことが分かりました。離職の理由は給料の仕組み(例えば時給か歩合制か)などが起因しており、本来ユーザが応募する前に知っておきたい情報が仕事を得てから初めて知るというケースが存在していたことを明らかにしています。
このように仕事を得てからミスマッチに気づくことは求職者にとっても企業にとっても不幸なことなので、例えば後ろのファネルで求職者が離脱する割合を指標として導入するなど、ミスマッチを未然に防ぐための取り組みを進めているそうです。
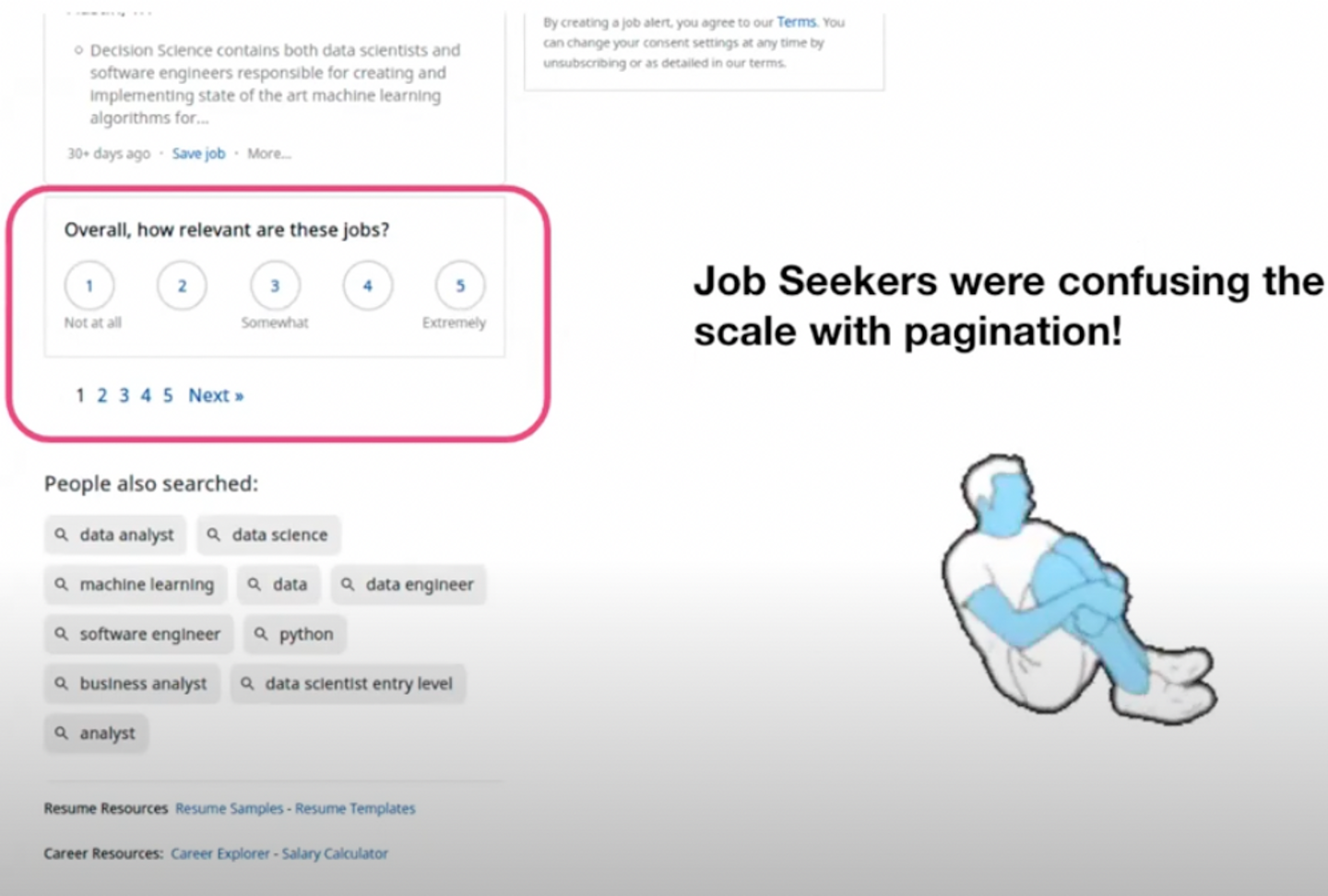
ケーススタディ3: アンケート調査とユーザビリティテスト 3つ目の事例はアンケート調査とユーザビリティテストになります。Indeedではユーザに関する解像度を上げるために、仮説に基づいたアンケート調査を実施しています。アンケートはサンプルサイズを確保しやすい一方でバイアスが乗りやすいため、アンケート結果がどのぐらい使えるものか確認するためにユーザビリティテストを実施しました。
以下のスライドのようにアンケートは検索結果ページの一番下に表示されていましたが、ユーザビリティテストにおいて ユーザがページネーションとアンケートの選択肢を混同している ことを明らかにしました。このUIでのアンケート結果は使えないことが分かったので、アンケートの選択肢を数字ではなく顔文字での表現に変更することで問題を解消しています。
2つ目のkeynoteでは Linkedinにおける推薦の取り組み事例 が紹介されました。
毎秒で100件以上の求人への応募や21件以上のメールが送信されているほどの巨大プラットフォームのLinkedinでは、求人検索や求人推薦、Push通知など様々な経路で求職者に対して最適な募集が推薦されます。また求職者だけでなく求人側のリクルータに対しても求職者推薦や検索機能を提供しています。
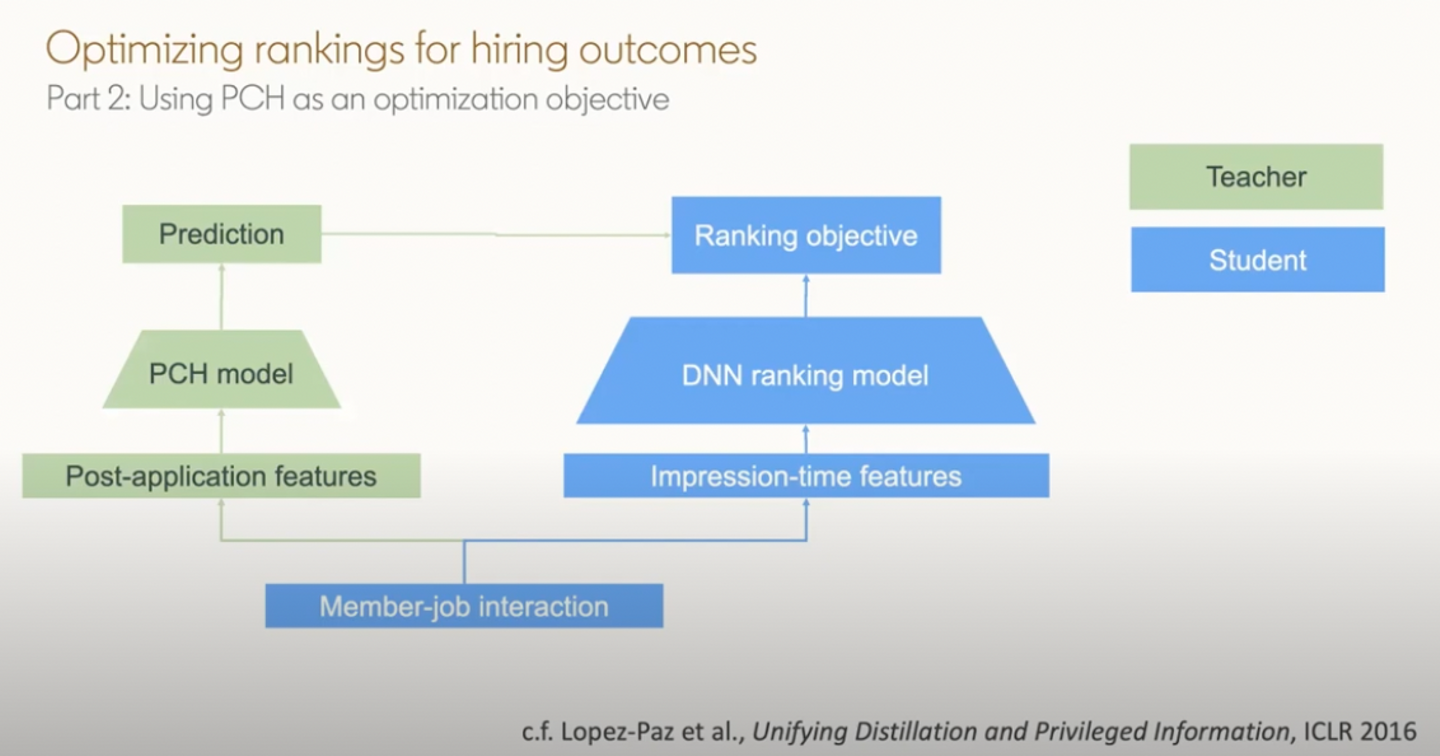
代理指標の導入 Linkedinでは 採用の確定 (Confirmed Hires)をユーザの成功体験としてサービスを最適化していますが、一般的にユーザが仕事を探し始めてから採用が確定するまでおおよそ数ヶ月と長い日数を要します。またユーザの採用活動が終わったとしても、その情報が取得できるようになる(例えばプロフィールに新しい仕事が更新される)までに更に時間がかかったり、そもそも情報が取得できないこともあります。このようにサービス運用で追いかけたい指標が確定まで数ヶ月の遅延があったり一部しか観測できないという難しい性質を持っているので、 短期的に観測可能な代理指標を採用しています 。この代理指標は短期的に測定可能な特徴量を採用した機械学習モデルの予測値(Predicted Confirmed Hires; PCH)であり、本当に見たい指標(Confirmed Hires)との強い相関や因果関係など様々な制約のもとで設計されています( 論文 )。
PCHをランキングに利用する このPCHはモニタリングやA/Bテストだけではなく、ランキングの生成にも活用されています。ナイーブにはPCHの値をそのまま使ってランキングを作れば良さそうですが、データ取得のタイミングの都合上推論で使うことができません。そこで以下の図のようにPCHを 教師モデルとして扱い ランキングモデルを学習しています。
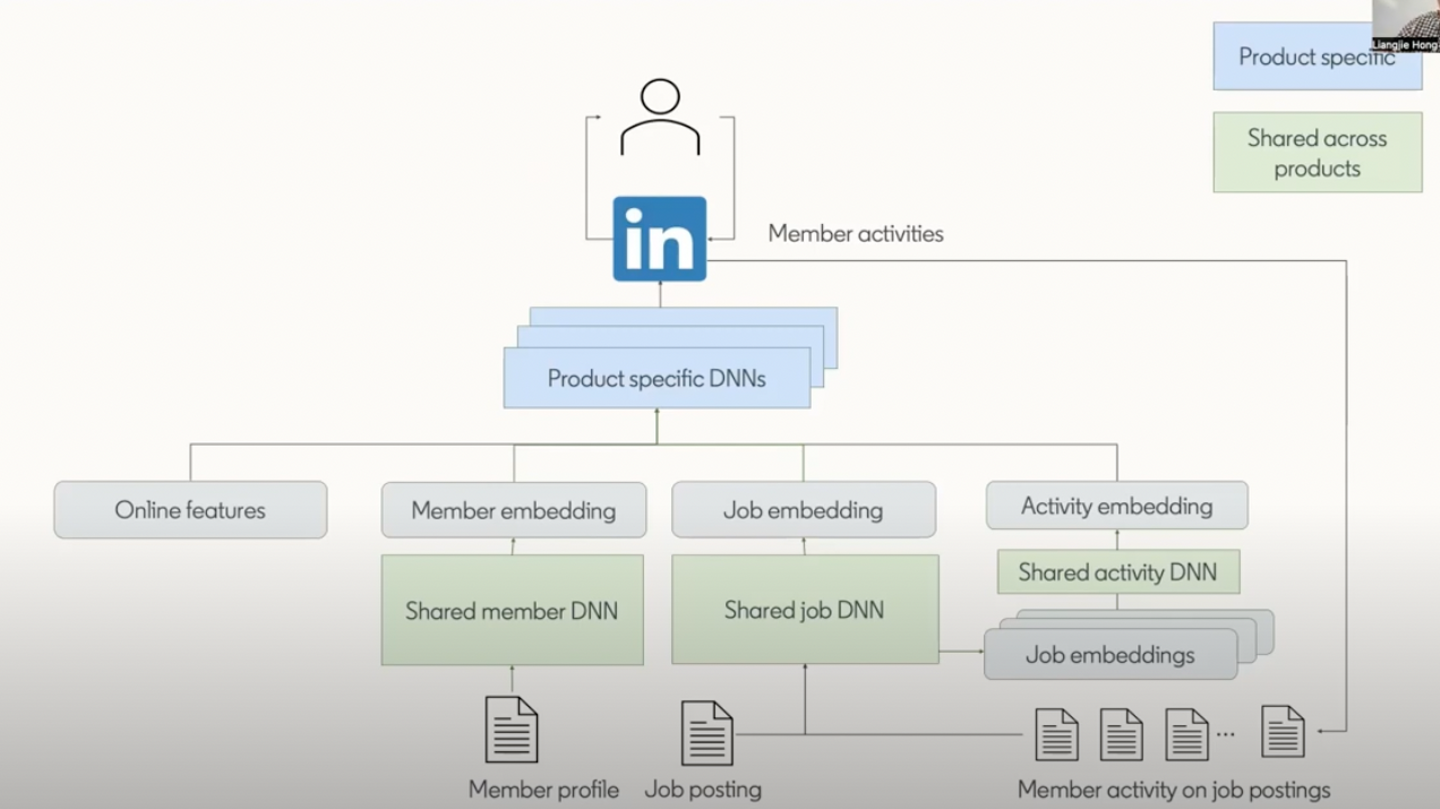
Pensieve: An embedding feature platform Linkedinでは推薦システムや検索システム、Push通知など多くのアプリケーションが存在しており、それらは最終的に同じ目標を持っていますが体験設計や要件定義がそれぞれ異なります。このような状況下でサービス開発を加速させるために、サービス全体でのユーザや求人に関する共通の表現を用意し、これらの表現を利用して各アプリケーションに特化したモデルを運用する仕組みを構築しています。
Linkedinが運用しているPensieveはembeddingベクトルの生成や管理を行うことができるプラットフォームです。Pensieveに組み込まれているPensieve Modelingは共通表現を学習する機能です。初期は層が浅いtwo-towerモデルから、skip connectionを導入して層を深くすることで表現力を大きくしたり、Linkedinのテキスト情報で事前学習されたLiBERTの導入など、モデル構造を継続的にアップデートしています( Pensieveの詳細記事 )
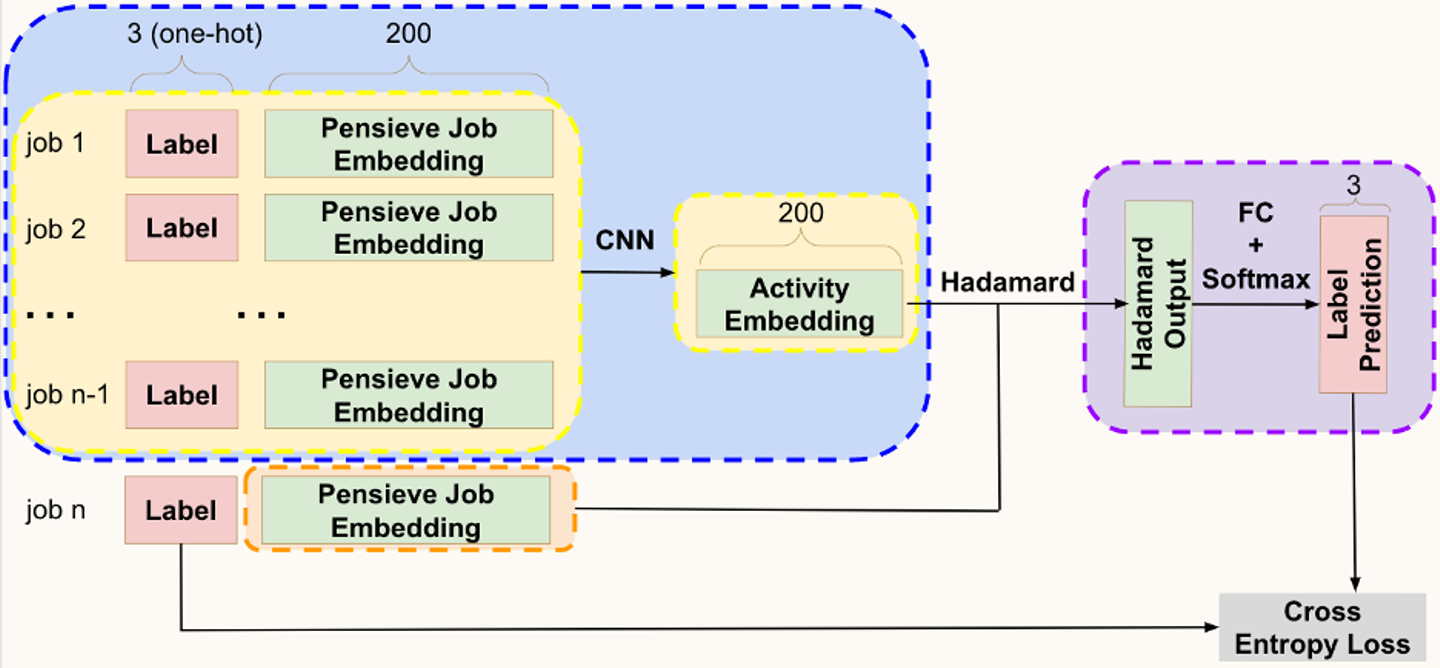
Job-Seeker Activity Embeddings embeddingベクトルの品質を上げるための手段として、求職者の活動を捉えてembeddingベクトルを作るコンポーネントを構築しています( 詳細記事 )
ユーザの行動にはユーザの志向性に関する情報が含まれており、それらを活用することでユーザの興味を捉えることができます。ナイーブにやるなら過去の行動履歴の平均を取るだけですが、ユーザのキャリアは時間変化したりパンデミック時にリモートワークなどの働き方に大きくシフトするなど、ユーザの興味は時間変化するため、ユーザの行動の軌跡からユーザの興味を捉えることが重要です。
そこで、ユーザの行動履歴をLSTMやCNNなどのシーケンスベースの深層学習モデルを使って集約するアプローチを採用しています。これによって時間方向に対して適切な重みで集約した特徴を獲得することができます。
これからのチャレンジ 最後にチャレンジングな要素として、 ユーザのキャリア戦略 、 スキルの理解 、 市場の変化への対応 という3点が紹介されました。どれも難しいものばかりですが、推薦システムにこれらの要素をうまく取り入れることでユーザのマッチング体験が大きく向上することが期待されます。
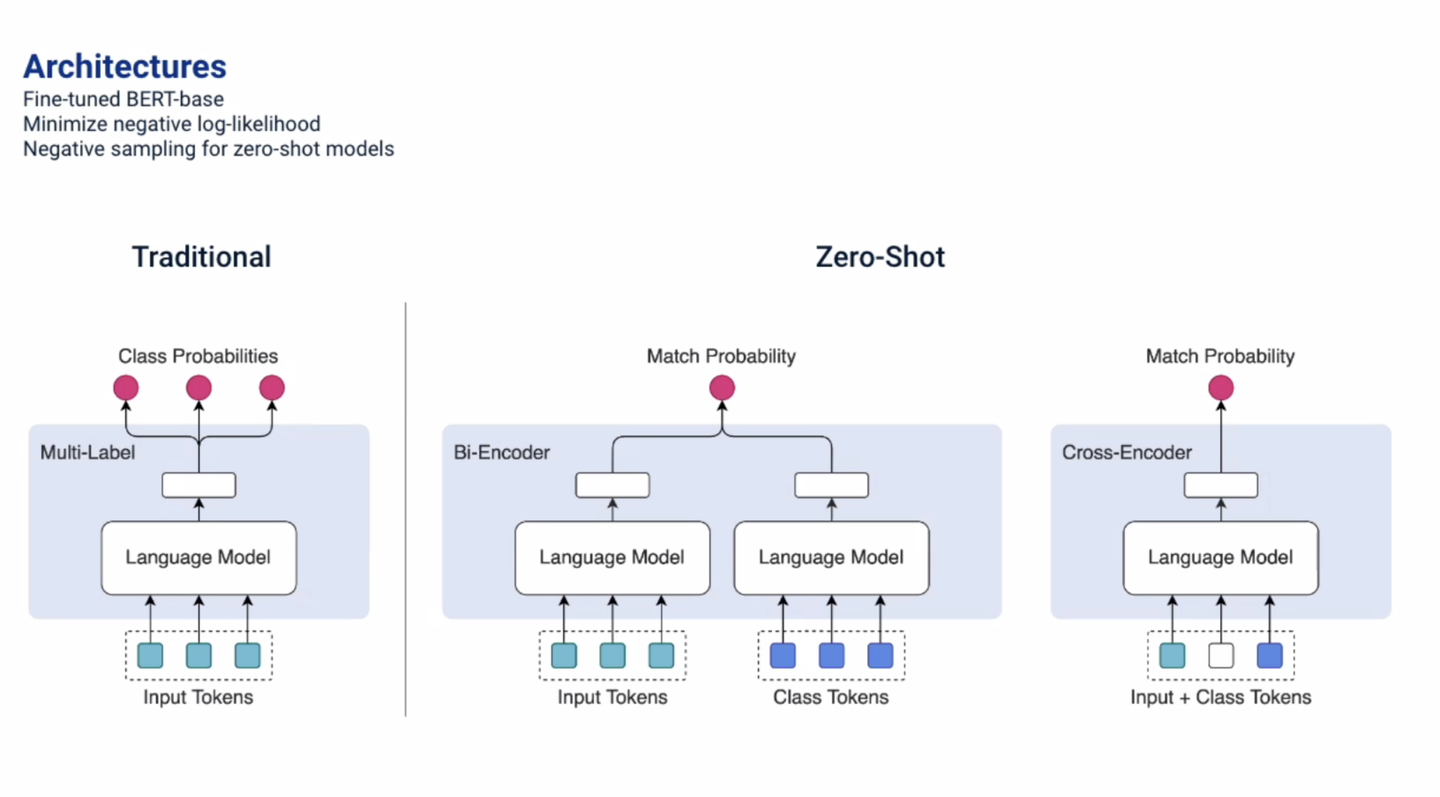
こちらはワークショップに採択された論文です。 常に変化し続けるHR領域 で運用する機械学習モデルの運用コストを削減するために ゼロショットで変化に追従できるようにします。
課題 HR領域には仕事に関する多くの種類の情報が存在しており(例えば職種やスキル、資格など)、履歴書や求人情報から構造化された属性情報を抽出することで、多くの機能の改善に利用することができます。属性情報の抽出は分類タスクとして解かれることが多いですが、新しいクラスが追加されたりクラスの定義が更新されると、学習データを追加してモデルを再学習する必要があります。HR領域における属性情報は頻繁に変化するため、属性抽出のための機械学習モデルの運用コストが大きいことが課題です。
アプローチ 従来の分類タスクだと新しく追加されたクラスに対応することができないので、 入力とクラス情報の一致率を推定する ようにします。例えば求人の職種を推定する職種分類タスクの場合、「求人のテキスト」と「職種クラスの定義」の一致率を求めます。
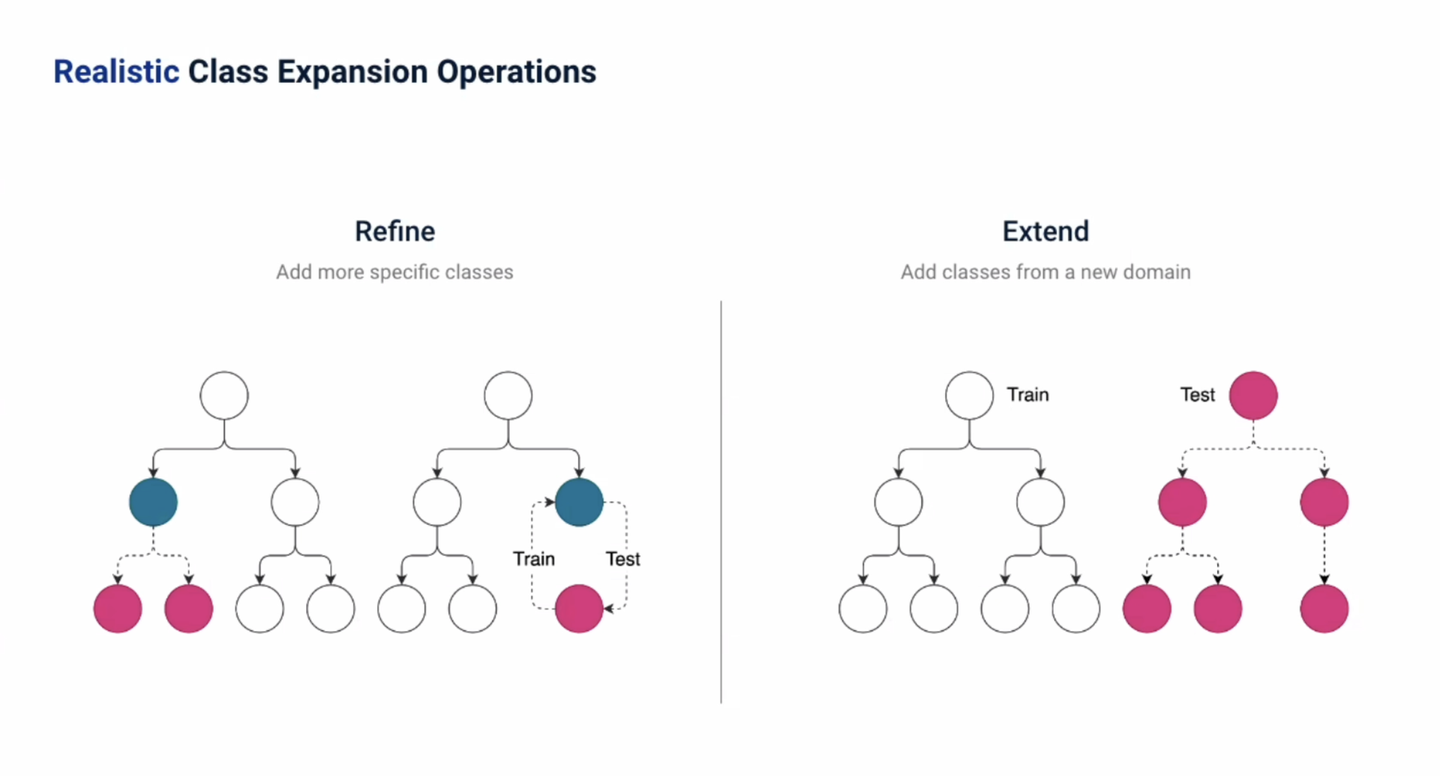
実験結果 実験では、Indeedに掲載されている求人情報とIndeedで管理している階層構造型の職種分類セットを使い、求人に該当する職種の推定精度を評価します。現実に起こり得る状況を再現するために、職種分類に対するクラスの追加を Refine(分類構造の細分化) と Extend(分類構造の拡張) の2パターンに分解して、それぞれのパターン毎にテストデータセットを作成しています。実験では提案手法のアーキテクチャにBi-EncoderとCross-Encoderを候補としており、 Bi-Encoderを採用する ことでベースラインの分類モデルと同程度かそれ以上の性能を発揮することを明らかにしました。
こちらはワークショップに採択された論文です。新しいキャリアの選択はユーザにとって大きなインパクトのあるイベントであるにも関わらず、その意思決定のサポートに使うための既存のキャリアパス予測手法がブラックボックスであることを課題としています。LSTM/CNNベースの説明性のあるキャリアパス予測モデルを構築し、ユーザテストでは既存のブラックボックス手法と同程度の予測性能であることとリクルータと同程度の説明力であることを検証しています。
こちらはワークショップに採択された論文です。全ての求職者が等しく最適な仕事を得られることを理想としているが、実際には職種セグメント間で推薦品質にギャップがあることを課題としています。推薦モデルの学習後に職種セグメントごとに個別に最適化する処理を追加することで対応し、実サービスのA/Bテストで問題の緩和を確認しています。
こちらはワークショップに採択された論文です。テキスト中に存在する細かい粒度のスキルを抽出してHRサービスで活用することを目的としています。細かい粒度でのスキルの種類は非常に数が多くアノテーションコストが非常に高いため、 ESCO (European Skills/Competences, Qualifications and Occupations; EUの労働市場や教育分野に関するスキルや資格、職業を体系的に分類したもの)のスキル分類とDistant Supervisionを用いたスキル抽出アプローチを提案しています。また3種類のHard Negative Sampling戦略を組み合わせることで、スキル抽出の性能を引き上げています。
3. 公平性 ここからは、HR領域の推薦システムの公平性に関連するコンテンツをまとめていきます。AIの社会実装が着実に進んでいるこの世界において公平性は非常にホットなトピックであり、パネルディスカッションでのテーマとして選定されたり、HR領域の公平性を解消することを目的とした論文が何本かワークショップで採択されていました。
ワークショップのパネルディスカッションでは、「 公平性の実践 」をテーマとしてパネリストたちが各社における取り組みを紹介していました。
Linkedinでは、ユーザの属性に基づく公平性の測定とバイアスの緩和を行うツールを開発し、公平性が損なわれていないかモニタリングできる体制を構築しています( 詳細記事 )。
ある会社では専門の社内組織を立ち上げて公平性に取り組んでいます。多くのステークホルダーを有するプラットフォームでは公平性の取り組みがプラットフォーム全体でうまく動作するように設計する必要があったり、様々な技術的課題が積み重なっているという状況から、少しずつ進めているみたいです。しかし最も大きなボトルネックは技術的な部分よりも 理想をどう定義するか であり、ここは重点的に議論して慎重に進めていく必要があると回答していました。
別の会社では雇用における AI倫理を専門としたチーム を作っています。ヨーロッパやアメリカでの法規制などサービスを展開している各国の状況を監視して法律に準拠した企業活動を行うための取り組みをしていたり、HR領域におけるAIについて社内で議論を重ねているみたいです。
実際の定性評価を行う際の取り組みも紹介されていました。サービス改善のためのユーザインタビューではサンプリングバイアスが発生するため(例えば、時間に余裕がある人やモチベーションがある人が参加しやすい)、 インタビューに参加する機会が少ない人に対してコンタクトを取れるような体制 を構築しています。直接現地に行って求職者を支援するグループを作り、サービスが求職者にとってどのように機能しているか、もしくは機能していないかについて意見を聞くことによって、通常の手段では到達しにくい人々からデータを収集する方法を確立させています。
こちらはワークショップに採択された論文です。求職者の履歴書に基づいた求人推薦における 男女賃金格差の緩和 を目的としています。
課題 民族やジェンダーなどの軸に関する雇用の不公平性は以前から存在しており、このような不公平性が暗黙的に存在する過去の求人データを使って推薦モデルを学習してしまうと、推薦結果に性別で偏りが生じて賃金格差が生じます(例えば男性に高給の求人を推薦しやすく、女性に低給の求人を推薦しやすい)
筆者らが実施した実験においては、実際の求人データ(履歴書や求人情報)を使った履歴書に対する求人推薦タスクで 推薦結果の性別間賃金格差が年間平均1680ユーロという大きな差 を生み出しており、過去のデータを素朴に使い続けることでバイアスが継続してしまうことを問題視しています。
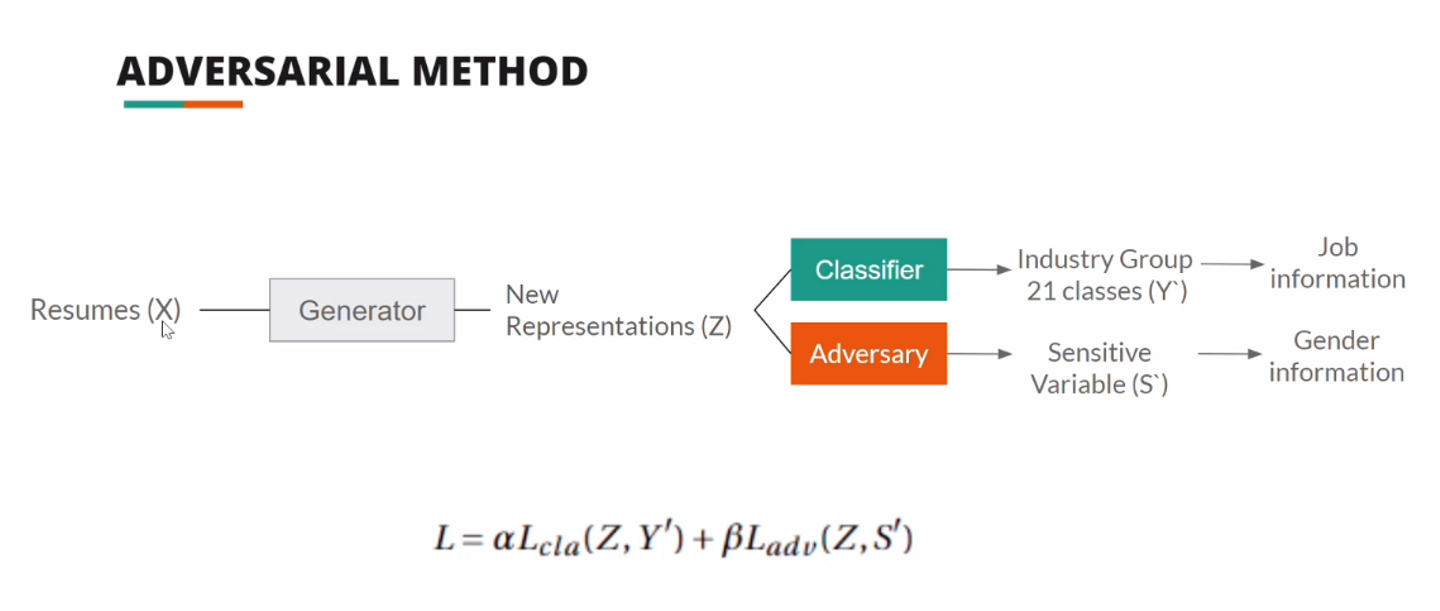
アプローチ 本論文では、バイアスを緩和する取っ掛かりとして「テキスト中のジェンダーを表す単語を中立的な表現に置き換える」手法を使った実験を行っています。しかしこの手法ではベースラインと比べてほとんど実験結果が変わらず、 表面的に情報を除去しても相関した特徴が残ってしまい 、ジェンダーバイアスを除去することの難しさを示しています。
そこで、有用な情報を残したままジェンダー情報を取り除くように表現を学習する手段として、 敵対的手法 を採用しています。求職者の履歴書情報を入力として、求職者のジェンダー情報を予測するタスクと求職者の仕事の業種情報を予測するタスクを解き、前者の損失の最大化と後者の損失の最小化を実行します。
実験結果 実験用のデータセットとして実サービスの情報を使っており、「性別と業種が紐付いている履歴書情報」と「給与が紐付いている求人情報」の2種類を利用しています。
匿名の履歴書から履歴書に紐づく業種情報を予測するタスクによって、提案手法による推薦システムの質(精度)と公平性の変化を評価しています。敵対的手法によって質を示す評価指標が低下した一方で、公平性を示す評価指標は大きく向上する結果となりました。また履歴書に対する求人推薦タスクでは、推薦結果の賃金格差が年間1680ユーロから180ユーロへと89%減少しています。
RecSys本会議に採択されたIndustry Talkで、アジアやラテンアメリカでHR事業を展開している企業SEEKの発表になっています。 男女グループ間のデータ量の違いによって生じる推薦品質の差異とその公平性バイアスを軽減するための手段 について紹介しています。
課題 協調フィルタリングは、似たようなアイテムを好むユーザを類似ユーザとして扱い、類似ユーザ群が好むアイテムを推薦するアルゴリズムです。このアルゴリズムはデータが多いほど良い品質の推薦結果が得られる一方で、データが少ないほど品質が低下します。
Linkedinのレポート( Gender Insights Report )では、男性は60%程度の条件を満たせば応募することが多い一方で女性は100%条件を満たさないと応募できないと感じるなど、 女性と男性の求人への応募傾向が異なる ことが報告されています。このような男性と女性の行動傾向の違いによって生じるデータ量の差異が 女性への推薦品質に悪影響を与える問題 を対応しようとしています。
どのように公平性バイアスを軽減するか 本発表では具体的なアプローチとして次の2つを紹介しています。1つ目が ハイブリッド型の推薦システム を採用することです。例えば協調フィルタリングとコンテンツベースフィルタリングの組み合わせなど、複数の形式の推薦アルゴリズムを組み合わせることで各アルゴリズムが有するバイアスを軽減することを狙います。
2つ目の手段として データサンプリング を紹介しています。ネガティブデータサンプリングなどのサンプリング手法を使うことで、グループ間のバランスが取れるような訓練用データの選定を実現させます。
最後に上記のようなモデルの改善だけではなく、例えば男女ともに歓迎されているような求人広告の作成をリクルータに推進するなど、 サービス内のコンテンツからバイアスを減らしたりステークホルダーの意識改革をするなどの取り組み が重要であることを話していました。
こちらはワークショップに採択された論文です。求人に対する候補者推薦システムのジェンダーバイアスを抑えることを目的とし、「 擬似的な学習データの生成 」という学習データに対して男女間のデータ量の格差を補正するアプローチと「 男性と女性が公平に配置されるよう予測結果をリランクするアルゴリズム 」という予測結果に対するアプローチを組み合わせることで、公平性バイアスを抑えつつ高い推薦品質を維持することを狙っています。
最後に RecSys in HRは自分たちの仕事をテーマにしているワークショップであり、世界のHRサービス・企業がどのような点に関心を持っていて推薦システムの開発を取りくんでいるか最先端の状況を知ることができて非常に有意義な時間でした。
今回は公平性について特に関心を持って参加しましたが、深い議論が積極的に行われているのが印象的で、今回発表された企業では日毎議論を繰り広げられている様子を想像しました。また各社とも公平性に対して最低限は対応されているように見えました(例えば属性のマスクやモニタリングなど)が、一方で根本的な対応はまだで慎重に検討を進めている段階でした。今後、理想の定義について進展があることを期待しつつ、常日頃のキャッチアップの継続と自分自身もどのような形でも動けるよう準備していこうと思います。
最後に、私たちと一緒に 「シゴトでココロオドルひとをふやす」 ためにデータを駆使してサービスを成長させていただける データサイエンティスト を探しています。少しでも興味を持っていただけたら是非「話を聞きに行きたい」ボタンを押してください。 Twitter の DM でも構いません。カジュアルにお話できたら嬉しいです!


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


