Wantedly のデータサイエンスチームのリーダーをしている松村です。推薦システムの国際会議である RecSys2021 にチームメンバーでオンライン参加しましたので、各自が気になった論文などの紹介を行っています。他の記事については以下の概要記事からご参照ください。
背景
さて、私からは推薦システムにおける"探索(Exploration)"をテーマとした Google の Minmin Chen 氏による口頭発表があった論文『Values of User Exploration in Recommender Systems』の内容を紹介致します。
推薦システムにおける探索は私が現在最も関心を寄せているテーマの1つであり、世の中的にも関心が高まっているように感じます。その背景には、推薦システムの社会実装が大きく進んできているという事実があることは間違いないでしょう。何より、私が関心を寄せている理由も、現在 Wantedly における推薦システム開発の実務においてぶつかっている課題を解決するには探索の要素をうまく取り入れる必要があると考えているからです。
推薦システムにおける"探索"とは
推薦システムにおける探索を簡単に説明すると、何らかの推薦アルゴリズムによって過去のデータなどに基づいてユーザの嗜好に最も合うであろうアイテムが決定される中で、あえてアルゴリズムによって決定された以外のアイテムをユーザに提示するという行為のことを指します。これは、その時点においてあるアイテムが最適だとされているのはあくまで偶然であったりその時点で分かっている情報に依存しているだけかもしれないので、その確度をより高めたり、存在するかもしれない本当はもっと良いアイテムを探し出そうという考えに基づくものです。逆に、現時点で分かっていることから最もユーザの嗜好に合うと考えられるアイテムをそのまま推薦することを活用(Exploitation)と言い、探索とは対照的な行為となります。
探索によってユーザに提示されるアイテムは、提示する時点では活用によって提示されるアイテムよりもユーザの嗜好に合わない(もしくは嗜好に合うのか分からない)とされるものなので、ユーザ体験を悪化させるリスクが常に存在することとなります。確実に一定以上の体験を担保するために素直に活用を行うのか、より良い推薦を求めて一定のリスクを許容してでも探索を行うのか、この活用と探索のトレードオフをうまく扱うことが探索を利用した推薦システムでは重要な課題となります。そして、この活用と探索の考えに基づいた強化学習あるいはバンディットアルゴリズムを用いた推薦システムが近年注目を集めています。
なぜ推薦システムに"探索"が必要なのか
では、なぜ推薦システムにおいて探索が必要であり、社会実装が進むにあたってその必要性が高まっているのでしょう。その大きな理由の1つとして、 推薦システムにおけるバイアス(bias)の存在が挙げられます。最近の推薦システムのアルゴリズムでは、ここ数年で大きく進展した機械学習あるいは深層学習の技術を応用したものが増えてきています。それらは実際のユーザがサービスを利用するうちに大量に蓄積されるユーザとアイテム間のインタラクションに関するログデータをなどを利用してユーザの嗜好や行動傾向を学習することでモデルを作成し、次にユーザに提示するべきアイテムを予測しサービス内で推薦します。
しかしここで問題となってくるのは、機械学習により学習されるのはあくまで過去に実際にユーザがアイテムとインタラクションした結果のログデータに基づくものであり、過去にインタラクションのあったアイテムへの嗜好の予測は得意だが、未知のアイテムへの嗜好の予測は苦手であるということです。この結果どういうことが起きるかというと、ユーザがシステム内で実際にインタラクションできるアイテムは現実的にサービス内のアイテムのほんの一部であるにも関わらず、その限定的なデータの中で傾向を学習した結果同じようなアイテムばかりが推薦されるようになってしまい、ユーザが本当は好ましいはずのアイテムと出会う機会を失ってしまうことになってしまいます。
また、過去に実際にインタラクションしたデータがなければ学習できないということは、サービス内のデータが少ない新しく追加されたアイテムであったりマイナーなアイテムを正しく推薦することが難しくなります。同様の理由で、サービスを使い始めたばかりでインタラクションデータがないユーザへの推薦も難しくなります。
このように、過去に実際にインタラクションしたアイテムとのデータに偏った、つまりバイアスのあるデータのみを利用した機械学習などによる推薦には問題が生じます。さらに、バイアスのあるデータを用いて学習したモデルによる推薦の結果蓄積されるデータには、学習に用いたデータの傾向がより強く反映される、つまりバイアスが強くなることとなります。そして、次に機械学習モデルの学習に利用されるデータは、そのバイアスがより強くなったデータとなります。このように、バイアスのかかったデータを利用して学習した機械学習モデルを用いて推薦を行い続けるとバイアスの影響がどんどん強くなっていってしまいます。このことを推薦システムのフィードバックループ(Feedback Loop)と言います。そしてこの問題は、実験用の切り出されたデータでアルゴリズムの検証を行うような場面でなく、実在するユーザに利用されるサービスにおいて推薦システムを運用するにあたって大きくなります。だからこそ、推薦システムの社会実装が進んだ近年においてこの問題の重要度は高まっており、解決する手段として、今回のテーマである探索が注目されているのです。
実務において"探索"を導入する難しさ
一方で、実務において探索を用いた推薦システムを採用するには障壁があります。それは先程説明したとおり、その時点で最適だと考えられるアイテムを推薦する活用と探索はトレードオフの関係にあり、探索を用いるということは短期的にユーザ体験あるいはサービスとして追いかけているビジネス目標を損なうリスクがあるということです。理論上、長期的に考えるとフィードバックループの問題が解消されることでアルゴリズムの性能は良くなっていき、結果としてユーザ体験もビジネス目標にも良い影響が与えられるはずだとは分かってはいても、実際のサービス運用でその意思決定を行うことはなかなか難しいことです。
実際に私も Wantedly における推薦システムの開発において、探索はきっと長期的にサービスの改善になるものであるから導入していくべきであろうと考えていつつも、探索を導入したアルゴリズムに対して過去のデータに基づくリリース前のオフライン評価を行うと、正解率などの尺度で測られる性能が落ちるという事実からなかなか意思決定が難しいなと感じています。オフライン評価で性能が向上することがこれまでの新しい推薦アルゴリズムリリースの要件であったのにもかかわらず、それを守らないということはある程度の改善サイクルを回してきて仕組み化が進んだ組織においては、その仕組みを改めることとなるリスクの高い決断です。あるいは、そのリリースの意思決定者が推薦システムに明るくない上司であったりした場合、なかなかその意義を説明して承認を得ることも難しいのではないでしょうか。
推薦システムにおける"探索"の新たな価値
前置きが長くなってしまいましたが、ここで本題に入ります。今回メインセッションで口頭発表された『Values of User Exploration in Recommender Systems』は、先程紹介したような悩みを一定解消してくれるかもしれないような内容でした。
これまで説明したように探索とは、それを活用した強化学習などによるアルゴリズムにおいて短期的なリスクを取りながらも中長期的には十分なデータを得られることにより推薦システムの性能の改善が見られる、という役割を担うものでした。一方でこの論文では、そもそも探索という行為そのものが直接的にユーザの体験を向上させうるものである。つまり、探索とはフィードバックループの問題を解決してアルゴリズムの性能を向上させる手段である以上に、本質的に推薦システムに必要なものであるという主張を行っています。これが真なのであれば、探索によって長期的なユーザ体験が向上することはもちろんですが、一定のリスクを取る必要があると考えられていた短期的な目線でも探索によってユーザ体験が向上するということが言えることとなりそうです。
もしこれが推薦システムにおける探索の通説になれば、先程説明したような実務における探索の導入の障壁が大きく取り除かれることとなるでしょう。その先駆けとなる研究であるという意味でこの取り組みの価値は大変大きい取り組みであると感じ、かつ実際に私自身も困っていた点でありましたので興味を惹かれ、今回は紹介することとした次第です。
Values of User Exploration in Recommender Systems
さて、ここからがいよいよ論文の紹介です。最初に大まかな流れを紹介しておきます。まずはじめに、推薦システムに探索を導入するための手法について、これまでの強化学習分野における探索の研究をもとにそのアルゴリズムを説明します。次に、探索の導入に影響を受けると考えられる異なる4つの推薦システムの質を測りうる評価尺度について定義します。そして、探索を導入した推薦アルゴリズムのオフラインの評価において、それぞれの評価尺度がどのように変化するのか比較を行うことで、探索が推薦システムの質に与える影響について検証します。さらには、数十億人規模のユーザが利用する実サービスにおいて本手法を適用するオンラインテストを実施し、実際に探索がユーザ体験を改善していることを示していきます。
探索を導入する推薦アルゴリズム
まずは推薦システムに探索を導入するためのアルゴリズムについて、過去の強化学習分野における探索の研究をもとに提案されています。アルゴリズムは3種類あり、後ほどのオフラインテスト・オンラインテストでは利用するアルゴリズムによる差異についても検証しています。それぞれについて簡単に紹介します。
Algorithm 1: Entropy Regularization
まずはエントロピーを正則化項として導入する Entropy Regularization です。累積報酬に対して第二項の正則化を加えることで、できるだけランダムな(偏らない)アイテムを選択するポリシーを学習することを狙うアルゴリズムです。
![]()
(数式は論文に記載のもののスクリーンショットを利用。本節における他の数式についても同様。)
Algorithm 2: Intrinsic Motivation
続いて、初めて見るタイプのアイテムを推薦した際の報酬を大きくするような調整を報酬関数に加える Intrinsic Motivation です。ユーザがそれまでに見たことのないタイプのアイテムを推薦すると、定数 c(>1) の分だけ報酬が大きくなります。
![]()
Algorithm 3: Actionable Representaion
最後に、ユーザが新しい嗜好に出会ったことにエージェントが気づきやすいように、ユーザが未知でかつ嗜好に合ったアイテムに出会ったかどうかを表現するためのインディケータ(i)を加えてあげる Intrinsic Motivation です。このインディケータの追加によって、ユーザが未知かつ嗜好に合ったアイテムを推薦された際の状態の変化を大きくする狙いです。
![]()
![]()
推薦システムの質の評価尺度
![]()
(画像は本会議における発表スライドを引用)
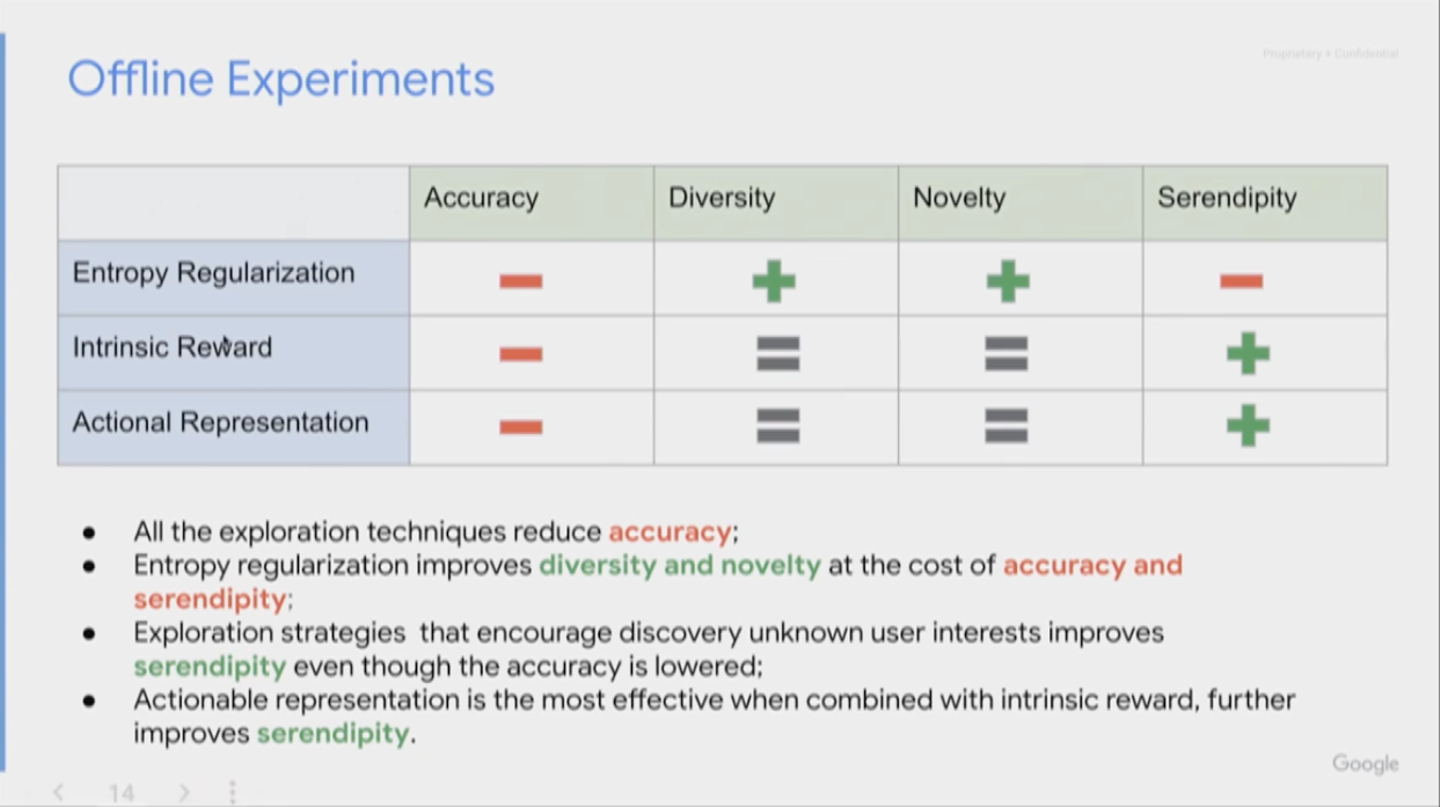
探索の導入に影響を受けると考えられる異なる4つの推薦システムの質を測りうる評価尺度について定義します。定義する評価尺度は上記画像の通りで、正解率(accuracy)、多様性(diversity)、新規性(novelty)、セレンディピティ(serencipity)の4つです。
それぞれの数式を詳しく説明することはしませんが、それぞれの評価尺度の直感的な理解は以下のようになるでしょう。特にセレンディピティについては、ただユーザが知らない(びっくりする)ものを推薦するだけではなく、その上でユーザが興味を持つものでなければいけないというのは抜けがちですので注意が必要です。
- 正解率
- 推薦したアイテムにユーザがどれほどインタラクションするか
- 多様性
- 推薦されたアイテムの集合の中で、それぞれのアイテムがお互いどれほど似ていないか
- 新規性
- 推薦されたアイテムが、システムの中でどれほど推薦されていないものか(人気なアイテムではないか)
- セレンディピティ
- 推薦されたアイテムのうちユーザが興味を持ってかつ、そのアイテムをシステム内で知らないものが含まれるか
オフラインテスト
![]()
(画像は本会議における発表スライドを引用)
探索を導入した推薦アルゴリズムのオフラインにおけるテストにおいて、先程の4つの評価尺度がそれぞれどのように変化するのか比較を行うことで、探索が推薦システムの質に与える影響について検証します。
まず分かりやすいのは、探索を導入する3つのアルゴリズムのアプローチのすべてで正解率が悪化していることです。続いて、できるだけランダムなアイテムを選択しようとする1つ目のアルゴリズム Entopy Regularization は、多様性と新規性の向上が見られますが正解率とともにセレンディピティも悪化しています。一方で、ユーザの未知かつ嗜好に合ったアイテムの選択を試みる2つのアルゴリズム Intrinsic Reward と Actionable Representation においては、正解率は悪化しつつもセレンディピティが向上するという結果となりました。さらにこの2つのアルゴリズムを組み合わせた場合はさらに大きくセレンディピティの向上が見られたそうです。
オンラインテスト
![]()
(画像は論文より引用)
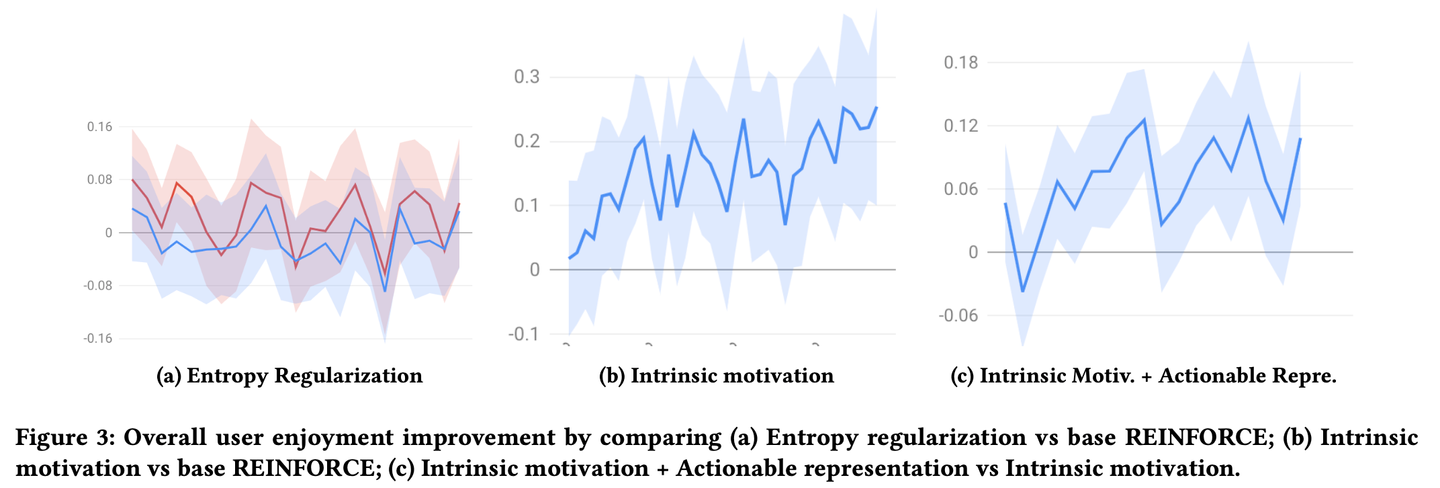
続いて、数十億人規模のユーザが利用する実サービスにおいて本手法を適用するオンラインテストが実施されています。上の図は、比較対象のベースラインとしてボルツマンサンプリングで単純な探索を行う強化学習アルゴリズムを採用した際に各アルゴリズムがどれほどユーザ体験を向上させたかを表しています。
グラフ(a) から読み取れるように、Entropy Regularization ではベースラインに対する有意な指標の向上が見られません。これはつまり、多様性や新規性が向上するだけではユーザ体験は向上しないことを表しています。一方でグラフ(b)を見ると、Intrinsic Motivation ではベースラインに対して有意に指標が向上しており、時間の経過とともに差が大きくなっていっていることが見て取れます。これはつまり、セレンディピティが向上することが長期的なユーザ体験の向上につながっていることを表しています。
![]()
(画像は論文より引用)
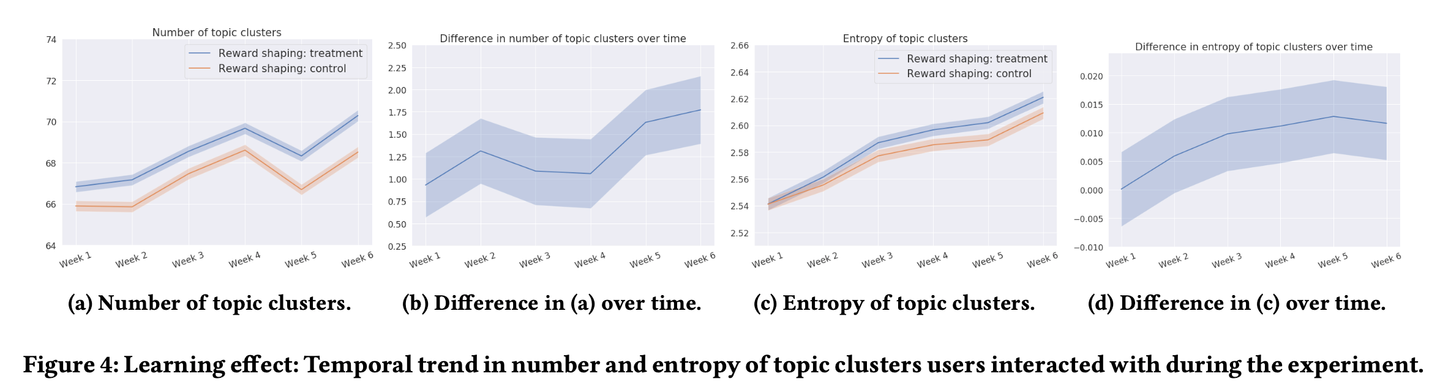
また、こちらのグラフは学習に探索を導入する(Intrinsic Motivation)ことによって他のどのような変化が出るのかを検証する目的で、オンラインテスト期間中においてユーザがインタラクションしたアイテムのトピックの数とそのエントロピーの大きさをベースラインと比較したグラフです。グラフ(a)と(c)から読み取れるように、実験期間中一貫して提案手法のほうがトピック数及びエントロピーが大きいことが分かります。さらにグラフ(b) と(d)から、ベースラインと提案手法の差は時間経過ともにどんどん大きくなっていっていることも読み取れます。
![]()
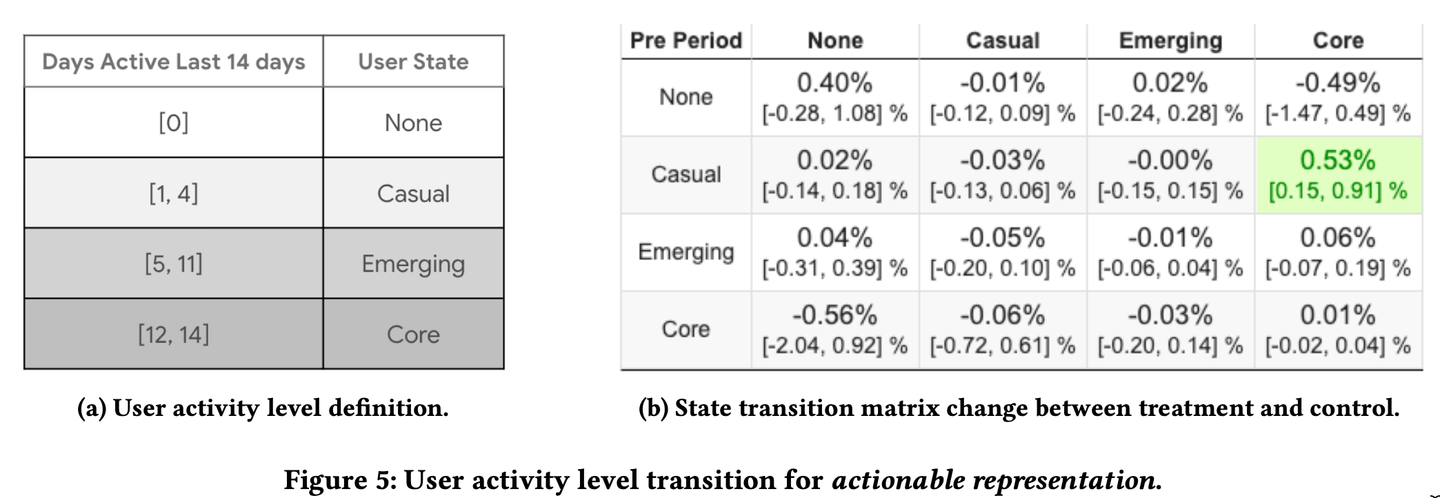
(画像は論文より引用)
次に、探索がユーザのアクティブ度にどのような影響を与えるのかを示した表がこちらになります。過去14日間においてユーザがアクティブであった日数に応じて表(a)のように None、Casual、Emerging、Core の4つのセグメントにユーザを分類し、実験期間の最初と最後の時点でどのような変化が起きたかを表(b)にまとめています。この表から、提案手法ではベースラインに比べて Casual 層のユーザが Core 層のユーザに変化する動きが特に大きいことが読み取れます。探索を用いた学習は、つまりセレンディピティの向上は、そこまでモチベーションが高くないユーザを大変モチベーションが高い状態に変化させる効果もあると言えるでしょう。
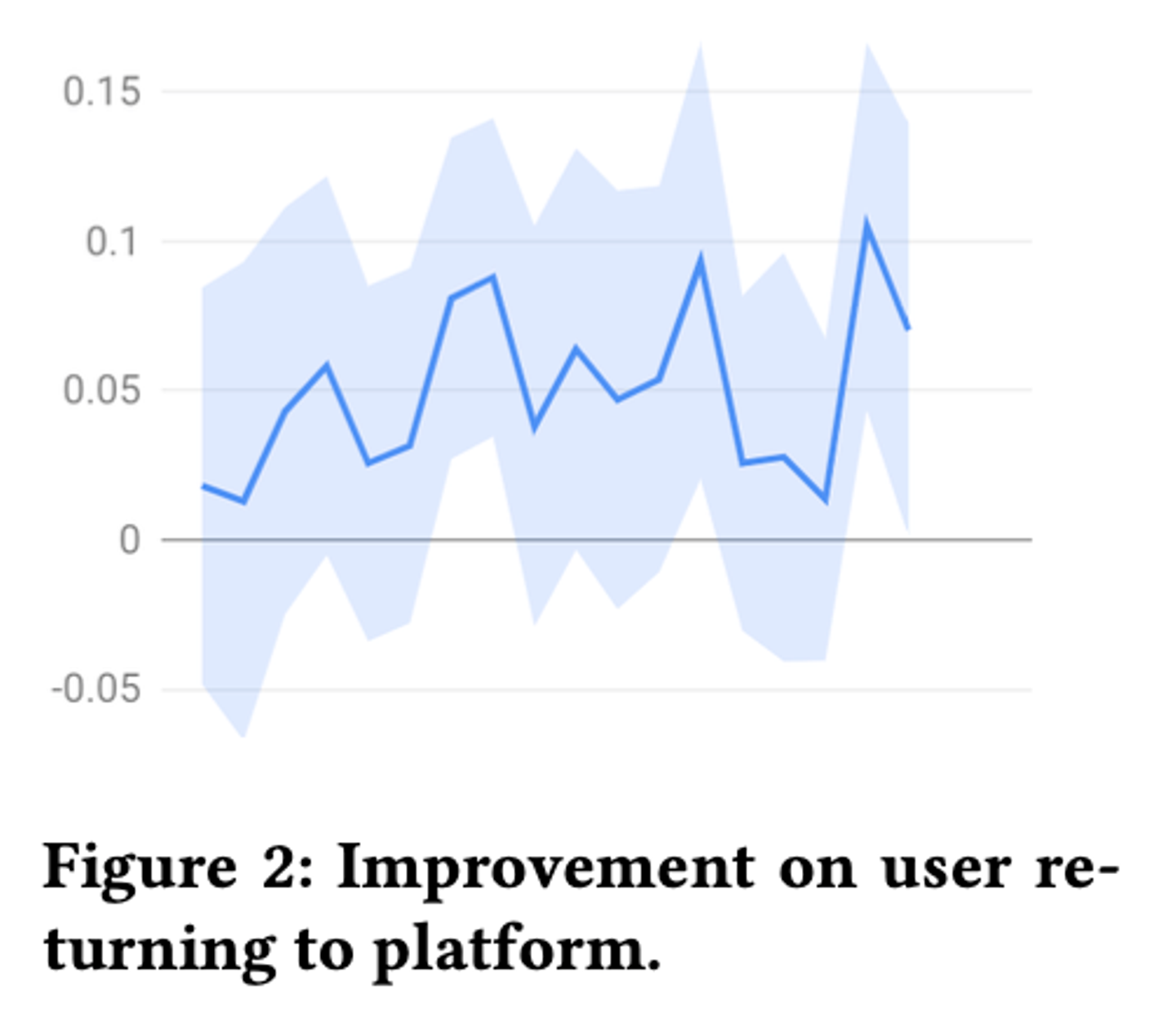
![]()
最後に、サービスの長期的な目標でもある、ユーザがサービスの利用して離脱した後にどれほど戻ってきてくれるかをベースラインと比較した図がこちらになります。学習に探索の要素を追加した場合、ユーザの離脱後の復帰という長期的な行動にもポジティブな影響を与えていることからも、セレンディピティの向上がいかにユーザ体験の向上につながっているかが読み取れるでしょう。
感想
以上、推薦システムにおける"探索"が、フィードバックループによる問題を解決する強化学習の手段としてだけではなく、探索の仕組みそのものが生み出すセレンディピティによって直接的にユーザ体験を向上しているという主張の論文の紹介でした。序盤にも記載したとおり、このような検証結果が公開されその認識が一般的になってくれば、推薦システムに探索を導入すると短期的にユーザ体験が損なわれてしまうため実サービスに導入しにくいという問題が起きなくなっていくのではと期待しています。
また、Wantedly の推薦チームとしてはこの情報でも十分に探索の導入をさらに進めていけると考えており、フィードバックループの悪影響を受けずらい高い性能のアルゴリズムを実現しつつも、セレンディピティによってユーザ体験を向上するという取り組みをもっと積極的に進めていきたいと思いました。
メモ✍
他にも、Accuracy だけじゃなくて Serendipity も向上させるような推薦を行おうって趣旨の論文がいくつかあったので後できっと追記する。

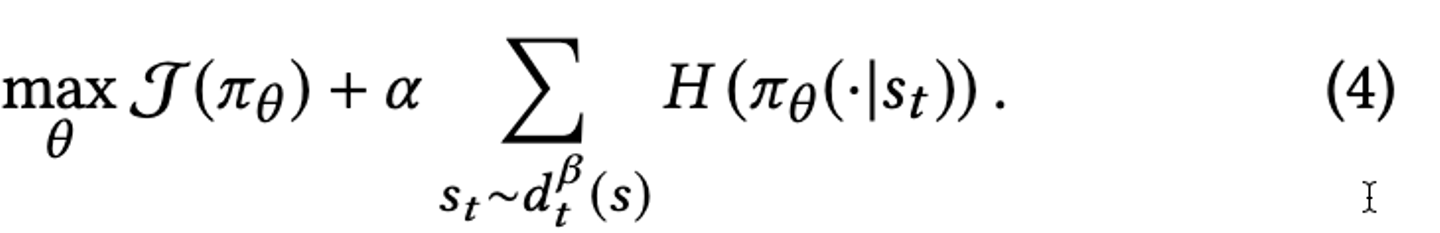


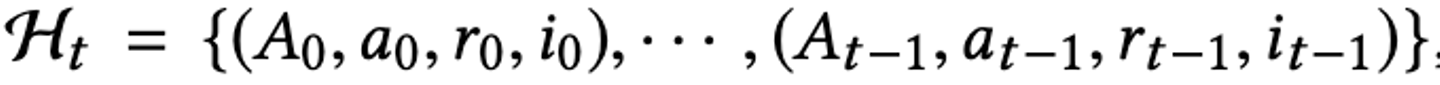

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


