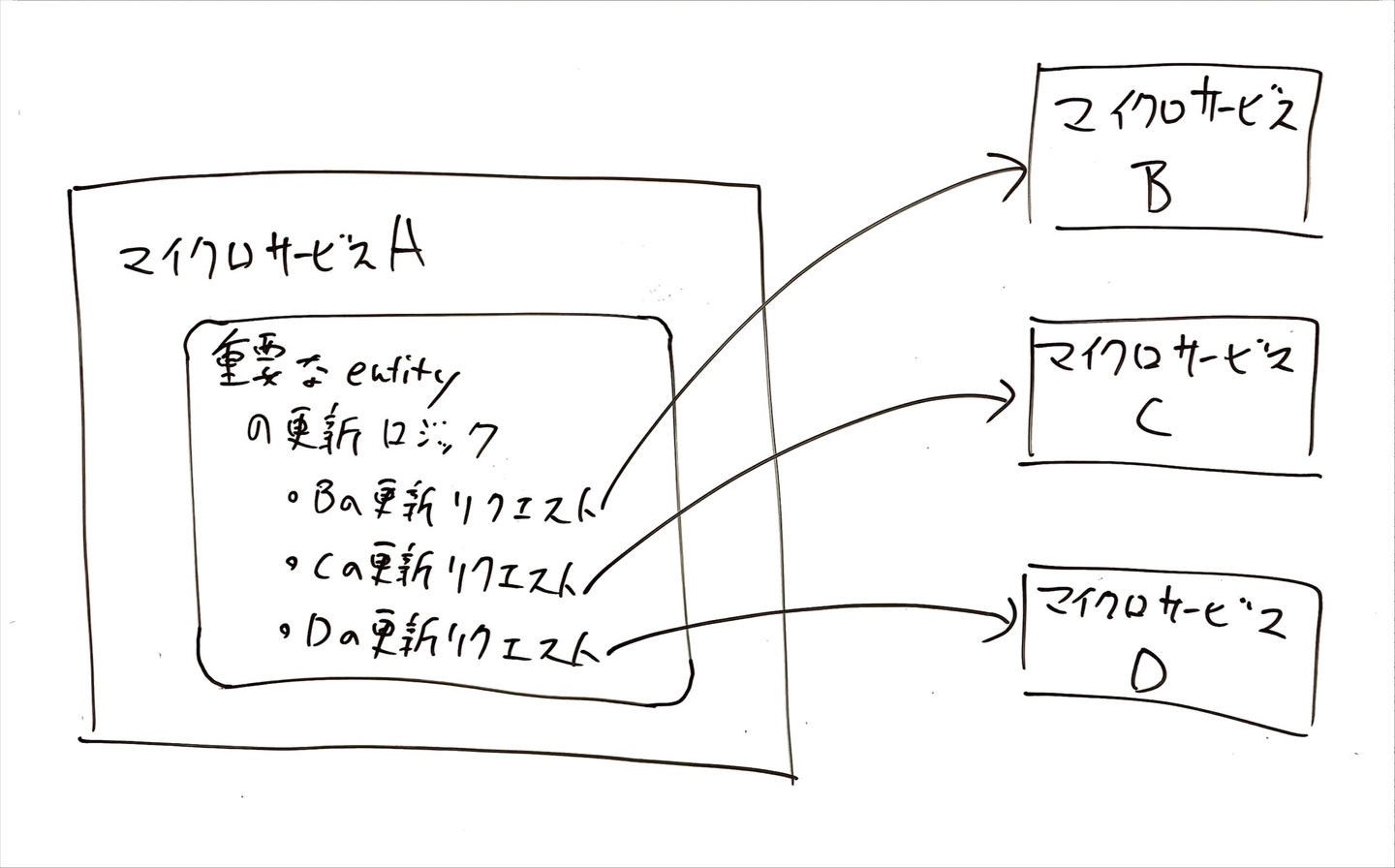
具体例を考えてみましょう。プロダクトにとってとても重要な Entity(e.g. ユーザーおよびそのプロフィールなど)を扱うマイクロサービス A が存在していて、その A に依存する形で複数のマイクロサービス B, C, D が存在するとします。B, C, D が Search 用のミドルウェア(e.g. Elasticsearch)や Cache 用のミドルウェア(e.g. Redis)を内部で保持している場合、重要な Entity の更新があった場合にはそれぞれのミドルウェアのデータを更新する必要があります。
この時、Event-Driven Architecture を採用せず、gRPC などの「リクエスト/レスポンスのコミュニケーション」で更新を行おうとするとどうなるでしょうか?この場合、「重要な Entity の更新を行っている処理」の全てに、「B, C, D へ更新リクエストを送る」という処理の実装が必要になります。このアーキテクチャを模式的に表したのが以下の図です。
図1. 「リクエスト/レスポンスのコミュニケーション」を利用したアーキテクチャの模式図
このアーキテクチャは以下のような問題を抱えています。
1. マイクロサービス A が「マイクロサービス B, C, D の障害や過負荷」の影響を受けてしまう
B, C, D のうちどれか1つでもマイクロサービスが落ちていた場合、全体の処理が失敗してしまう。また、失敗させずに retry などを行う場合、「どのマイクロサービスでどういった retry を行うべきか」という知識をマイクロサービス A が持つ必要が出てしまう。エラーレポーティングなどもマイクロサービス A で行う必要がある。
B, C, D のどれか1つでも処理が遅くなった場合に、マイクロサービス A の処理の latency が増えてしまう。
結果的に、「マイクロサービス B, C, D の信頼性が、マイクロサービスA の信頼性に影響を与える」という構図になってしまう
2. マイクロサービス A が「マイクロサービス B, C, D へリクエストを送るための知識」を持つ必要がある
新しく「Entity の変更を検知したいマイクロサービス」を作りたい場合、マイクロサービス A にリクエスト先を追加する変更を行う必要がある
上記のような問題は、結果的に「システム全体の信頼性低下」や「開発速度の低下」に繋がります。例えば、「マイクロサービス A がそのほかのマイクロサービスの障害や過負荷の影響を受ける」構造である場合、マイクロサービスが増えるほどにマイクロサービス A の信頼性は下がってしまいます。あるいは、マイクロサービス A の信頼性を下げないために、不必要に高い SLO を設定してしまって開発速度が低下してしまうかもしれません。また、「マイクロサービス A の変更」が必須の状態だと、変更対象が増える分だけ開発コストも上がってしまいます。
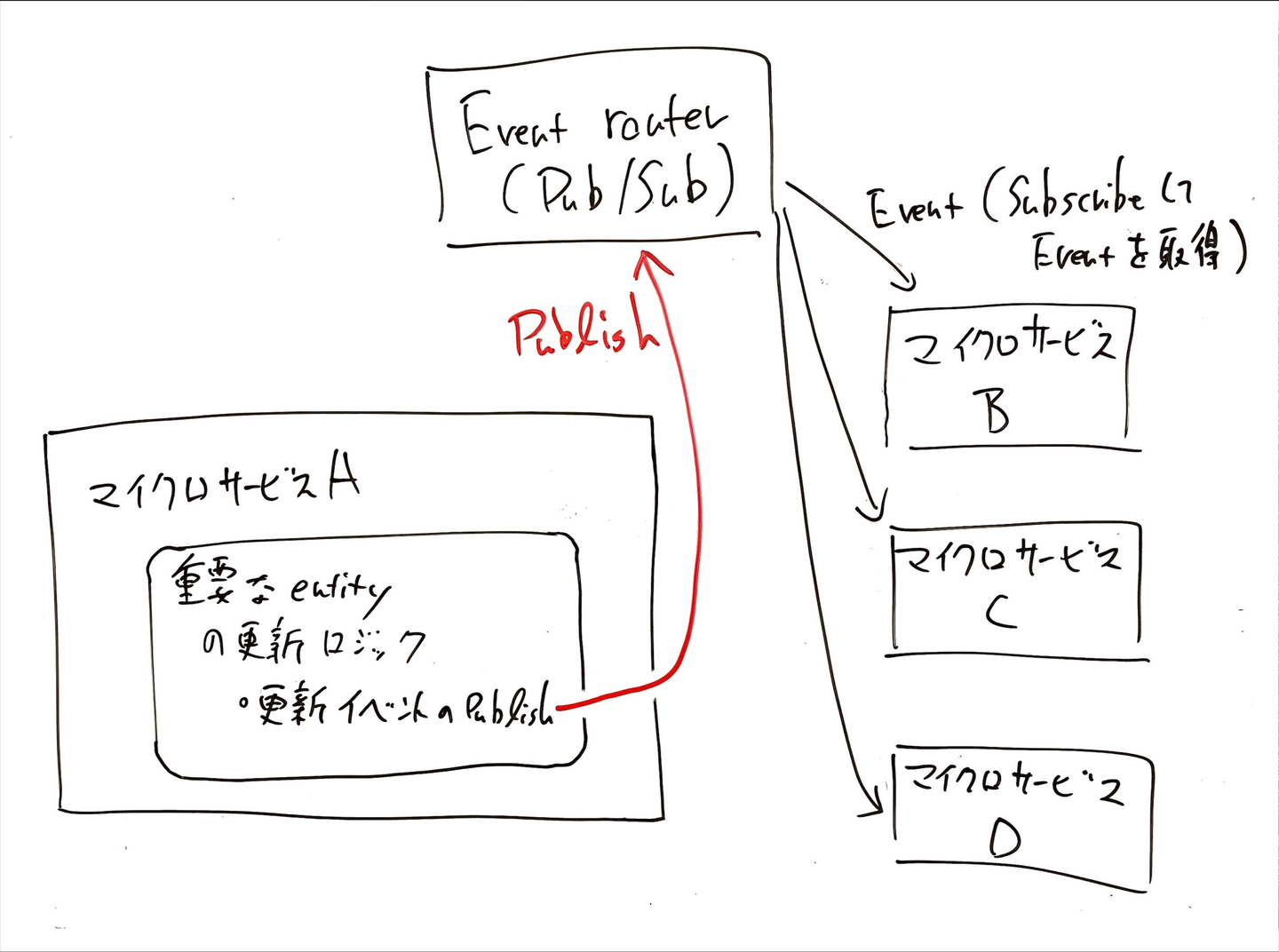
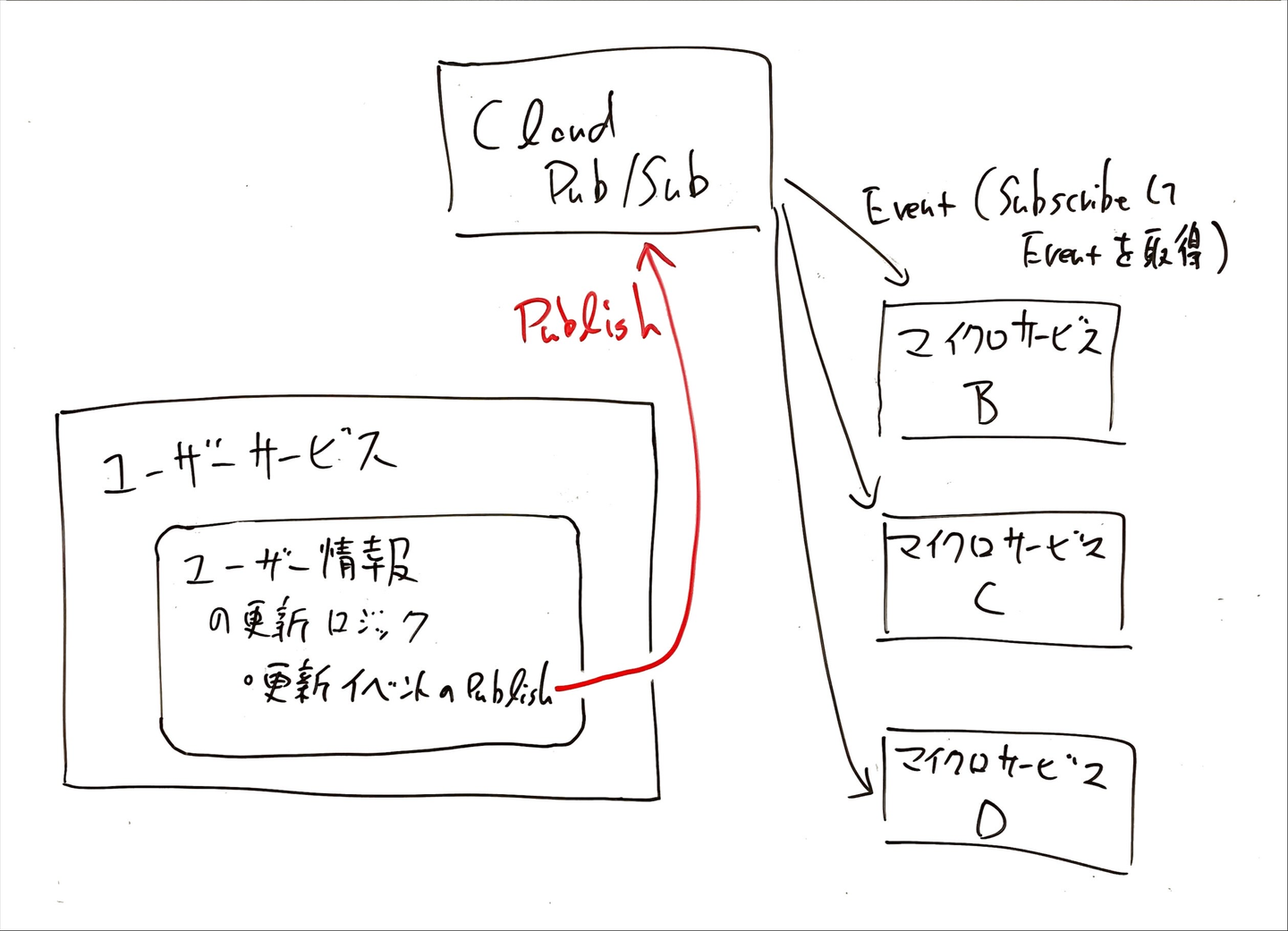
それでは、「リクエスト/レスポンスのコミュニケーション」を行う代わりに、Event-Driven Architecture を採用するとどうなるのでしょうか?この場合、マイクロサービス A の責務は「重要な Entity の更新を行った際に、あらかじめ定義した形式の Event を Publish すること」だけになります。「Event を取得して適切に処理をする」という責務はマイクロサービス B, C, D が持つことになります。このアーキテクチャを模式的に表すしたのが以下の図です。
さて、What is an Event-Driven Architecture? の「1. Scale and fail independently」の説明に戻ります。このドキュメント中ではもう1つの要素として、「Event router が buffer として機能する」という部分にも言及しています。このお陰で、Spike が来てもシステムが止まることはなく柔軟に処理を継続する事ができます。
Event-Driven Architecture のメリット2: Scale and fail independently
次に What is an Event-Driven Architecture? の「2. Develop with agility」についてですが、実はこれは既に説明した内容で、「Publisher と Subscriber を独立して開発可能」ということを指しています(注: Document 中では、Publisher と Subscriber の間の Heavy coordination をなくす事が出来る、という表現になっています)。あらかじめ Event の format を定義しておけば、それが「公開インターフェース」となるため、Publisher は「公開インターフェースを満たす事」だけを念頭において開発出来ますし、Subscriber は Publisher の実装詳細を知ることなく開発が可能です。こういった特徴のお陰で、Event-Driven Architecture では生産性高く開発を進める事が可能です。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


