


Xavi's Recsys 2025 Keynote
https://amatria.in/recsys25.html
ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。推薦システムのトップカンファレンスである RecSys 2025 に参加してきたので、現地の様子や、面白そうな研究についていくつかピックアップして紹介します。昨年オンラインで参加したときのレポートもありますので、よろしければこちらもご覧ください。
今回の RecSys では我々と半熟仮想株式会社の共同研究の成果が Full Paper で採択されており、私自身の発表のためにも現地参加しました。我々の研究成果は以下から見ることができますので、ご興味のある方は是非ご一読ください。
RecSys とは
大会の概要
Opening
Keynotes
ピックアップ論文
SEMORec: A Scalarized Efficient Multi-Objective Recommendation Framework
You Don’t Bring Me Flowers: Mitigating UnwantedRecommendations Through Conformal Risk Control
Prompt-to-Slate: Diffusion Models for Prompt-Conditioned Slate Generation
まとめ
RecSys (ACM Conference on Recommender Systems) は、ACM(計算機学会)が主催する推薦システムに関する主要な国際会議の1つです。この会議には、推薦システムの研究を行う研究者や、Eコマースやメディア、HR など多様な領域で活躍するデータサイエンティスト・MLエンジニアが集まり、推薦システムに関する最新の学術研究成果や産業界での応用など、幅広い内容に関する発表や議論が行われます。
今年はチェコの首都プラハにある、O2 universum という会場で 9/22 ~ 9/26 の 5 日間にわたって開催されました。O2 universum は下の写真のような会場で、国際会議などに使えるスペースの他、ホールなどもあるような大規模な施設です。
5日間の学会期間のうち、初日と最終日は併設のチュートリアルやワークショップ、中3日が本会議という構成でした。本会議では毎朝最初に Keynote から始まり、その後 Full Paper や Industry のオーラル発表があるという形です。
あくまで自分の主観ですが、今年の RecSys では特に推薦システムの透明性や信頼性に対する注目度が高かったように感じました。1日目の Keynote では、EU における政策決定と推薦システムを関連づけながら、システムの説明性などの重要性が強調されていました。加えて Best Paper Award を受賞した "You Don’t Bring Me Flowers: Mitigating Unwanted Recommendations Through Conformal Risk Control" も、ユーザーが望まないアイテムを推薦しないための方法をテーマにしたもので、ユーザーがサービスに抱く信頼性とも深く関わる非常に興味深い研究でした。
本会議の最初には、今回の RecSys の参加者数や査読プロセスについて触れられました。今年の RecSys は参加者数は 1,056 人でした。一番参加が多いのはアメリカですが、今年は日本からの参加も多く、62 人の参加者がいました。
論文の採択率は Full Paper が最も低く 19 %, 続いて Short Paper が 20 %, Workshop 32 %, Industry 36 %という感じだったようです。Full と Short は特にですが採択率は低く、変わらず論文を通す難易度は高い状況となっています。Industry Track は昨年は50 %近くありましたが、投稿数が昨年の倍以上と大幅に伸びたためか36 %まで低下していました。また、この段階で Full Paper と Short Paper のそれぞれについて、Best Paper Award の候補が発表されました。
我々が出した論文は大変光栄なことに Full Paper Track の候補に選出されていました (写真下から2つ目)
本会議初日のスピーカーは Emilia Gómez という、 EU でシニアデータサイエンティストを務められている方です。EU での政策立案という立場から推薦システムに求められるリスク管理や透明性について講演されていました。
2日目は Jure Leskovec という、スタンフォード大学の教授をされている方です。この方は Kumo.ai という企業の共同設立者であり、講演はこちらのプロダクトに関する内容でした。近年 LLM を既存の推薦に組み込むということが盛んにされていますが、本来 LLM はユーザーの行動パターンを学習して未来の行動を予測するタスクにフォーカスした学習はされていないので、推薦で活用するためには、予測をする部分を別に分けることが必要だということを主張されており、そのためのモデルとして Relation Foundation Model (RFM) を紹介されていました。Kumo.ai では大規模に RFM を学習しており、ここにプロダクトごとに固有のデータを In-context で与えることで、従来のモデルより圧倒的に性能が向上するという結果には驚きました。
3日目は Xavier Amatriain という、Google で VP Product, AI and Compute Enablement をされている方です。Recommender system in the age of AI というタイトルで、これまでの推薦システムの発展から、LLM が出現することでこれからどのような形で発展していくのか、という内容について講演されていました。講演の中では Google Cloud の Agentspace を利用したデモも行われており、Agent 時代の推薦の一端を体感することができました。この記事を執筆している時点ではリファレンスしか上がっていませんが、以下のページに Video がアップロードされるようです。
ここでは、大会期間中に聞いた発表の中から、自分が興味を持った論文をいくつかピックアップして紹介しようと思います。我々の論文に関しては、また別のブログで詳細をまとめようと思っていますので、そちらをご期待ください。
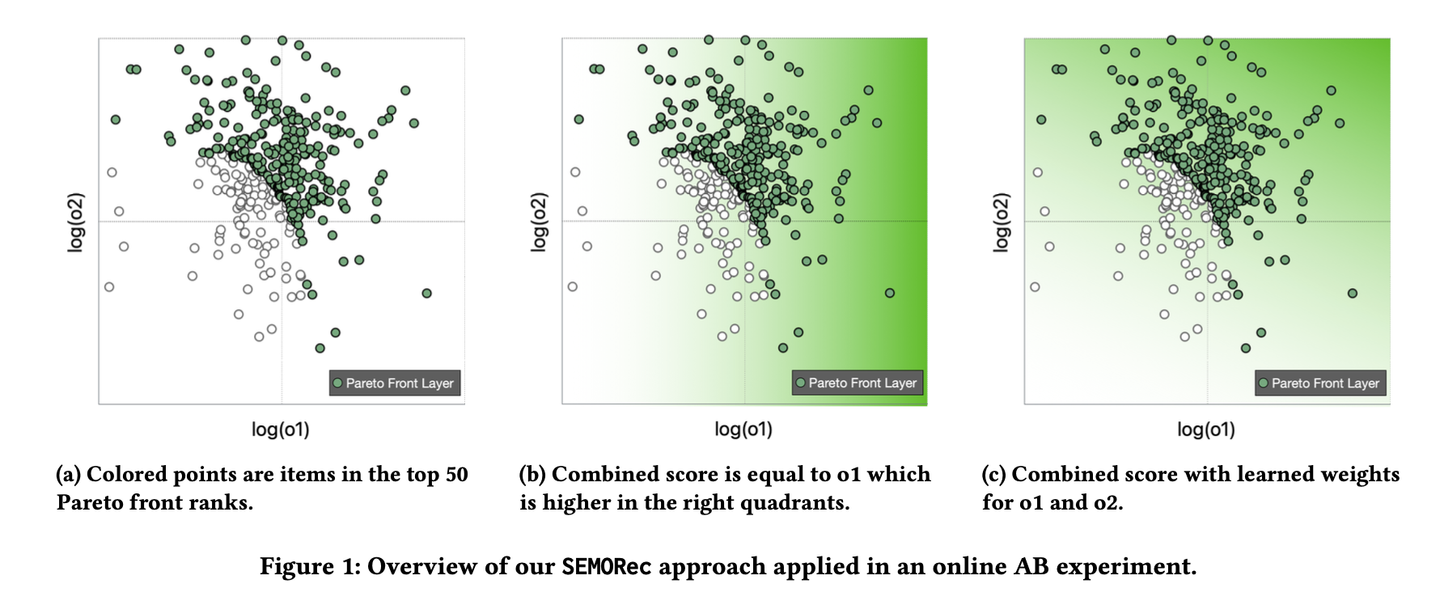
Apple が発表した論文です。プロダクトには複数のステークホルダーがいる場合がほとんどであり、推薦システムが最大化すべき Objective もそれに応じて複数存在することが多いです。このような最適化対象が複数あるときに、それらを上手くバランスさせて推薦システムを構築するのは簡単なことではありません。この論文が提案したのは、複数の Objective が存在するときでも高速にランキングを計算することができ、かつ Human-in-the-loop に Objective の重みを調整することができる新しい手法です。
論文では分割統治をベースとしたランキングの候補生成をしており、Objective が 4個未満の場合にはランキングのアイテム数 n に対して O(nlogn) での計算を実現しています。論文中では A/B テストを行なった結果も示しています。テストでは o1, o2 という 2つの Objective を用意しており、提案手法を用いることにより、下図の一番右のように o1 も o2 も大きくなる領域でスコアが高くなる (緑が濃くなる) ことが示されています。また、オンラインテストの結果、各 Objevtive が 35 %を超える大きな改善を実現したことが報告されています。
栄えある今年の Full Paper Track の Best Paper Award を受賞した論文です。ユーザーの嗜好に無関係だったり、出して欲しくないアイテムを推薦することによるユーザー体験へのリスクに着目し、Conformal Risk Control を用いた回避手法を提案しています。
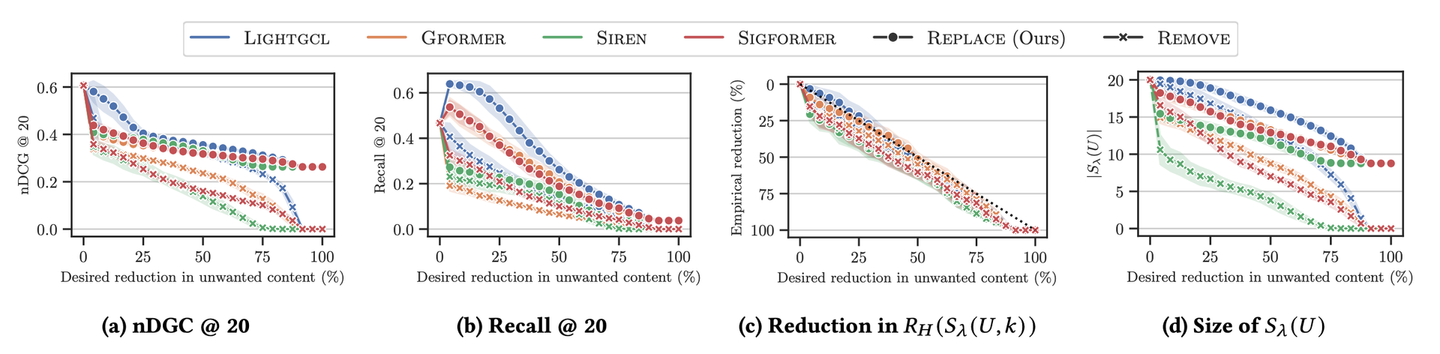
なんらかの形でリスク関数を定義して、それが閾値を超えないように推薦の並び換え対象の集合(候補集合)を作成するというのが提案手法の要点です。論文中では、あるスコア関数を用意して、そのスコアが λ を超えたときに候補集合に入れるという場面を考えています。このスコア関数とリスク関数、較正用データセットを利用することで、リスクが閾値を超えないようにするための最適な λ を計算することができます。
このように候補集合の段階においてリスクのあるアイテムが入りにくいようにすると、候補集合が小さくなり、ユーザーに十分なアイテムを推薦できない可能性があるという問題が別の問題として発生しえます。この問題を解消するために、筆者らは既にユーザーが過去に消費したアイテムを再度推薦するということを提案しています。論文で検証に使ったデータセットはショート動画データセットであり、過去にユーザーが試聴したアイテムを再度推薦してもユーザーからのネガティブフィードバックが来づらいということが分析からわかっていたためです。図が小さくて恐縮ですが、下図の丸が過去に試聴したアイテムで置換した場合、バツ印が置換せずにリスクのあるアイテムを除去した場合です。一番左は nDCG をプロットしたものですが、置換することによって性能劣化をかなり抑えられていることが示されています。
ただ、我々が扱っているジョブマッチングの領域では、過去に応募した募集に再度応募するということはなかなかありませんので、自分たちのプロダクトに応用しようとするとこの辺りは考えるべきポイントになると感じました。
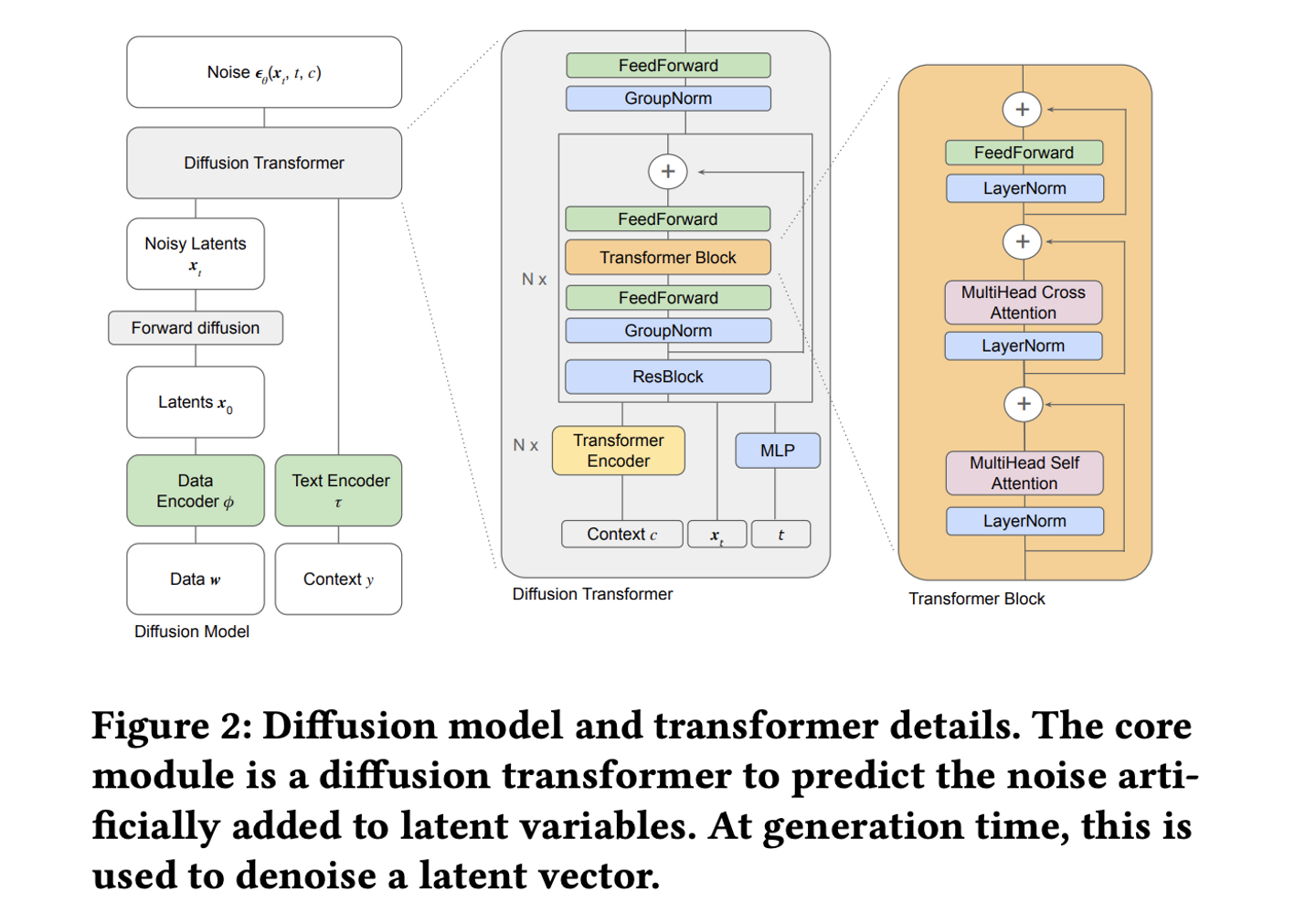
Spotify による、拡散モデルに基づいたスレート推薦に関する論文です。スレートというのは、複数のアイテムをまとめたものを指しており、Spotify でいうとプレイリストなどがこれに当たります。論文では、従来のスレート推薦では推薦するリストの一貫性が十分に考慮できていなかった点を課題に挙げ、拡散モデルを活用することによってリストの一貫性とプロンプトによる多様で柔軟なリスト生成が可能であることを主張しています。
論文で提案している手法 Diffusion Models for Slate Generation (DMSG) では、アイテムの Embedding とプロンプトの Embedding を利用して、プロンプトによって条件付けられたアイテムの集合を生成するというタスクで学習されています。
スレート全体の結合分布をモデル化するため、柔軟性と多様性が高まるというのがこの手法の利点です。
論文では、音楽プレイリスト生成とeコマースにおけるバンドル生成という2つのタスクについてオフラインの評価が行われている他、オンラインA/Bテストの結果も示されています。特にオンラインテストの結果ではユーザーのエンゲージメントが増加しているほか、推薦されるアイテムの重複が減少して推薦アイテムの多様性が増加していることも確認されており、この手法の有効性が確かめられています。
今年の RecSys の様子と、いくつか自分が気になった論文の軽い紹介をさせていただきました。来年の RecSys はアメリカのミネアポリスで開催されるそうです。推薦システムの研究は非常に活発で、日々新しい研究が出ているような状況です。来年はどのようなテーマが盛り上がっているのか楽しみです。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

