


この記事は、Google Cloud Next Tokyo 2025の2日目の参加報告です。1日目の参加レポートも公開しておりますので、ぜひ併せてご覧ください。
2日目はバックエンドエンジニアの小室、データサイエンティストの林、右手が現地参加し、基調講演や各企業のセッションを聴講しました。本記事では、基調講演の概要と、私たちが参加したセッションの内容をご紹介します。
目次
基調講演
聴講したセッションの紹介
Gemini CLIで実現する AI Agent 時代のプロダクト開発
Agent Development Kit 徹底解説!マルチエージェントによるカスタム AI エージェント開発
日本最大級のアルバイト求人サイト「マイナビバイト」 における Vertex AI の 適用事例のご紹介
freee が目指す生成 AI 時代に向けた次世代 データ プラットフォームと ガバナンスとは
Datadog による AI エージェント オブザーバビリティの最前線
まとめ
基調講演
2日目の基調講演では、AI時代のインフラに焦点を当てた内容が紹介されました。まず、ラスベガスでのGoogle Cloud Nextにて発表された新世代Ironwood TPUの紹介と、NVIDIAのVera Rubin GPUをGoogle Cloudが先行提供することが発表されました。最新ハードウェアをいち早く活用できることは、開発者にとって非常に価値があります。
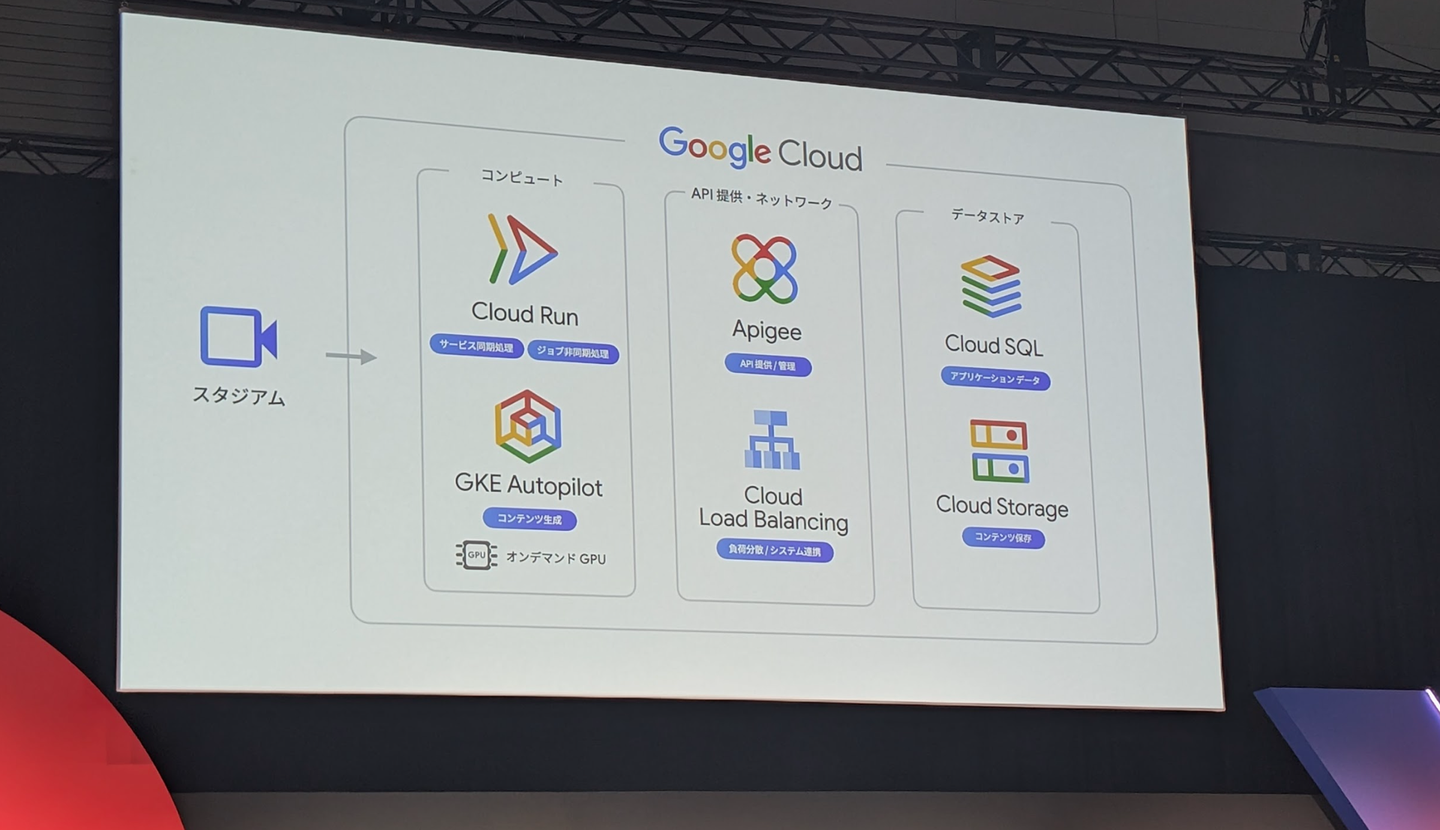
さらに、Cloud RunでのGPU利用の対応や、AIワークロード向けのゾーンバケットRapid Storageなど、AIを活用したプロダクト開発を支える重要な基盤機能が多数紹介されました。Cloud Runに関しては、NPBエンタープライズがソニーの技術と組み合わせて開発している新しい野球観戦体験の事例が紹介され、非常に興味深い内容でした。
GoogleのAIであるGeminiについても、新機能が発表されました。Gemini CLI GitHub Actionsは、その名前の通りGitHub ActionsにGemini CLIを統合できる機能で、プルリクエストレビューなどの自動化が可能になります。類似するプロダクトが既に存在する分野ではありますが、Geminiの強みであるロングコンテキスト処理能力がどの程度効果を発揮するかが注目されます。是非実際に使ってみたいですね。

聴講したセッションの紹介
ここからは、3人がそれぞれ聴講したセッションの内容について簡単にまとめていきます。
Gemini CLIで実現する AI Agent 時代のプロダクト開発
Gemini CLIはGoogleが提供しているOSSのCLIコーディングエージェントツールです。このセッションではGemini CLIを使った実践的な使い方がデモを交えて紹介されていました。
Gemini CLIでは、コード生成やファイルの管理などのコア機能の他、MCP (Model Context Protocol)やカスタムのスラッシュコマンド*定義に対応しています。セッションでは、「Gemini CLIとの会話は揮発的であり、必要に応じてドキュメント化するなどして永続化する」ことや、「Gemini CLIにやってほしい操作で対象のファイルが明確であるのならば明示的にそのファイルやディレクトリをプロンプトで指定する」ことが紹介されていました。
*スラッシュコマンド: /から始まる特定の操作をまとめたコマンド 例: /quit、/complressなど

また、Geminiはコンテキストサイズが大きいことで有名ですが、/compressコマンドなどを適切に使用してGeminiとのセッションにおけるコンテキストを小さくしておくことに言及されていました。コストを抑えつつ、効率的に推論が可能となるので非常に有用な機能だと感じました。なお、今後Gemini CLIに追加される機能はロードマップとして公開されており、例えば/deployでCloudRunへデプロイできるようになるそうです。
Agent Development Kit 徹底解説!マルチエージェントによるカスタム AI エージェント開発
Agent Development Kit (ADK)はAIエージェントを開発するためのフレームワークです。2025年8月6日(セッション開催日)時点でPythonとJava向けにOSSで提供されています。本セッションではAIエージェントと従来のLLMとの違い、ADKの概念、Vertex AI Agent Engine、Google Agentspaceとの統合方法が紹介されていました。
ADKは「Runner」、「LlmAgent」、「SessionService」の主要なオブジェクトで構成されていることが紹介されていました。特に、SessionServiceはユーザーとエージェントの会話履歴を管理するサービスで、主に開発用途で使用するInMemorySessionService、VertexAIと統合した本番用途のVertexAiSessionService、任意のRDBで永続化を実現できるDatabaseSessionServiceが紹介され、非常に柔軟なオプションが用意されているフレームワークだと感じました。
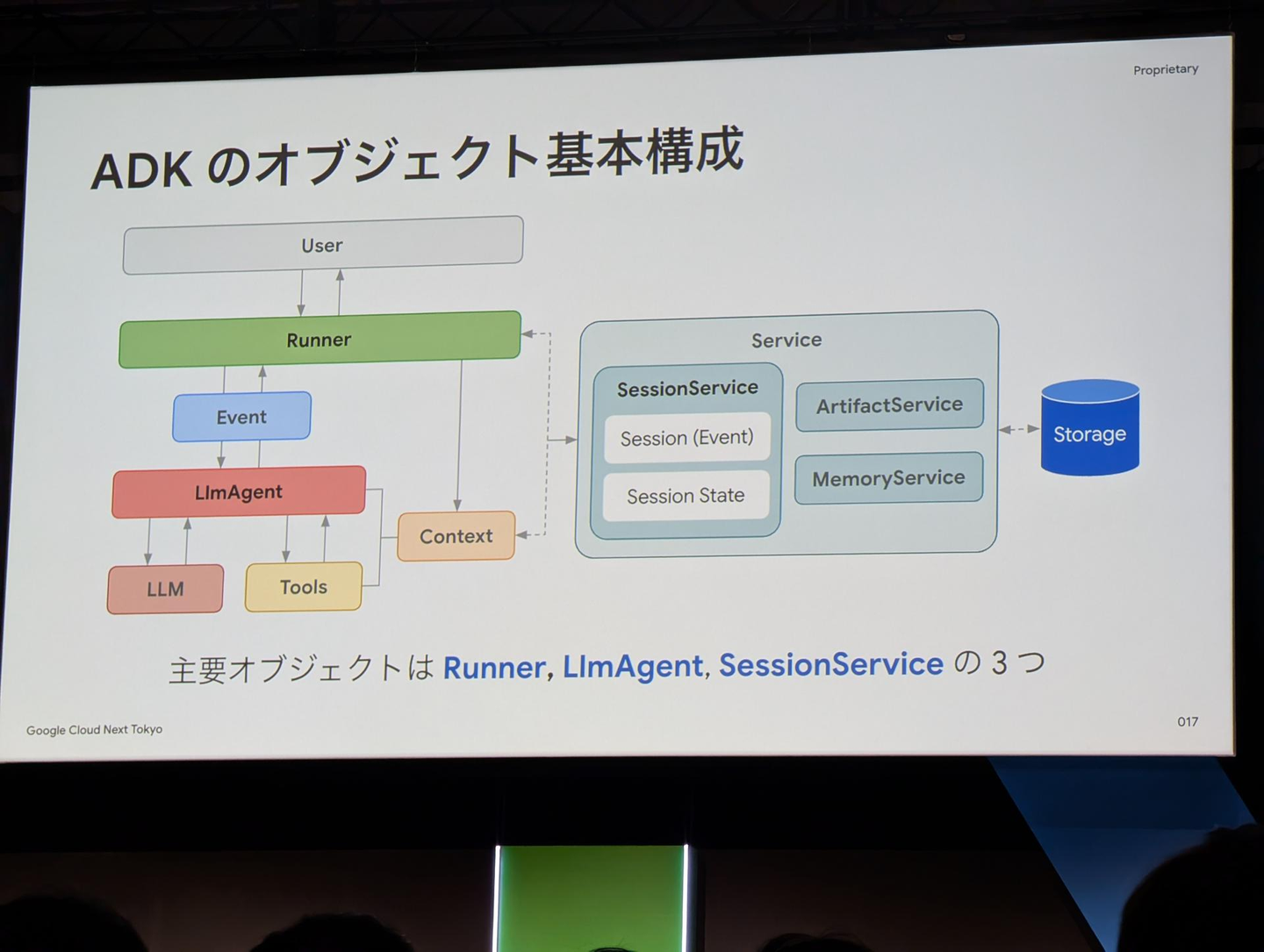
また、マルチエージェント構成において、メインとなるエージェントとその他のエージェントの関係性には2種類存在することに言及されていました。タスク自体をエージェント同士て委任可能な「Sub Agent」とタスクはメインのルートエージェントが担当してルートエージェントがその他のエージェントをツールとして使う「Agent as a Tool」が存在し、ユーザと対話するエージェントもそれぞれ異なることが示されており、解きたいタスクに応じた方式設計が重要だと感じました。

日本最大級のアルバイト求人サイト「マイナビバイト」 における Vertex AI の 適用事例のご紹介
本セッションではVertex AIを用いた事例として、「マイナビバイト」における検索精度の向上と広告運用の最適化の2つの取り組みが紹介されました。
検索精度の向上については、Vertex AI Search や BigQueryを用いたセマンティック検索機能の実装が紹介されました。また精度向上だけでなく、不適切な検索ワードをGeminiでフィルタリングして企業ブランドを守るという、ビジネス上の配慮もなされていました。
広告運用の最適化については、データドリブンな広告運用に向け、MMM(マーケティング・ミックス・モデリング)を用いた広告費用最適化モデルの実装事例が紹介されました。モデルの前処理と学習にVertex AI Pipelineを用いており、実際にマーケティング担当者が最適化シミュレーションできるようにstreamlitでUIが整備されているとのことでした。
Wantedlyではこれまで推薦や検索に力を入れてきましたが、広告運用の最適化のように、推薦や検索以外の分野でもデータの利活用を進めていきたいと感じました。
freee が目指す生成 AI 時代に向けた次世代 データ プラットフォームと ガバナンスとは
本セッションでは、freee社のデータプラットフォーム整備に関する取り組みが紹介されました。
freee社では、データプラットフォームにメッシュ型アーキテクチャを採用しており、コンテクスト(プロダクト、ビジネス、社内)とフェーズ(データ統合、データ共有、データ活用)の2軸でデータを整備しているとのことでした。
コンテクストを分離することで各コンテクストで独立した開発・運用を可能にし、フェーズを分割することで(データ共有フェーズで適切にデータを共有することで)ガバナンスを効かせたデータ利活用を可能にしています。
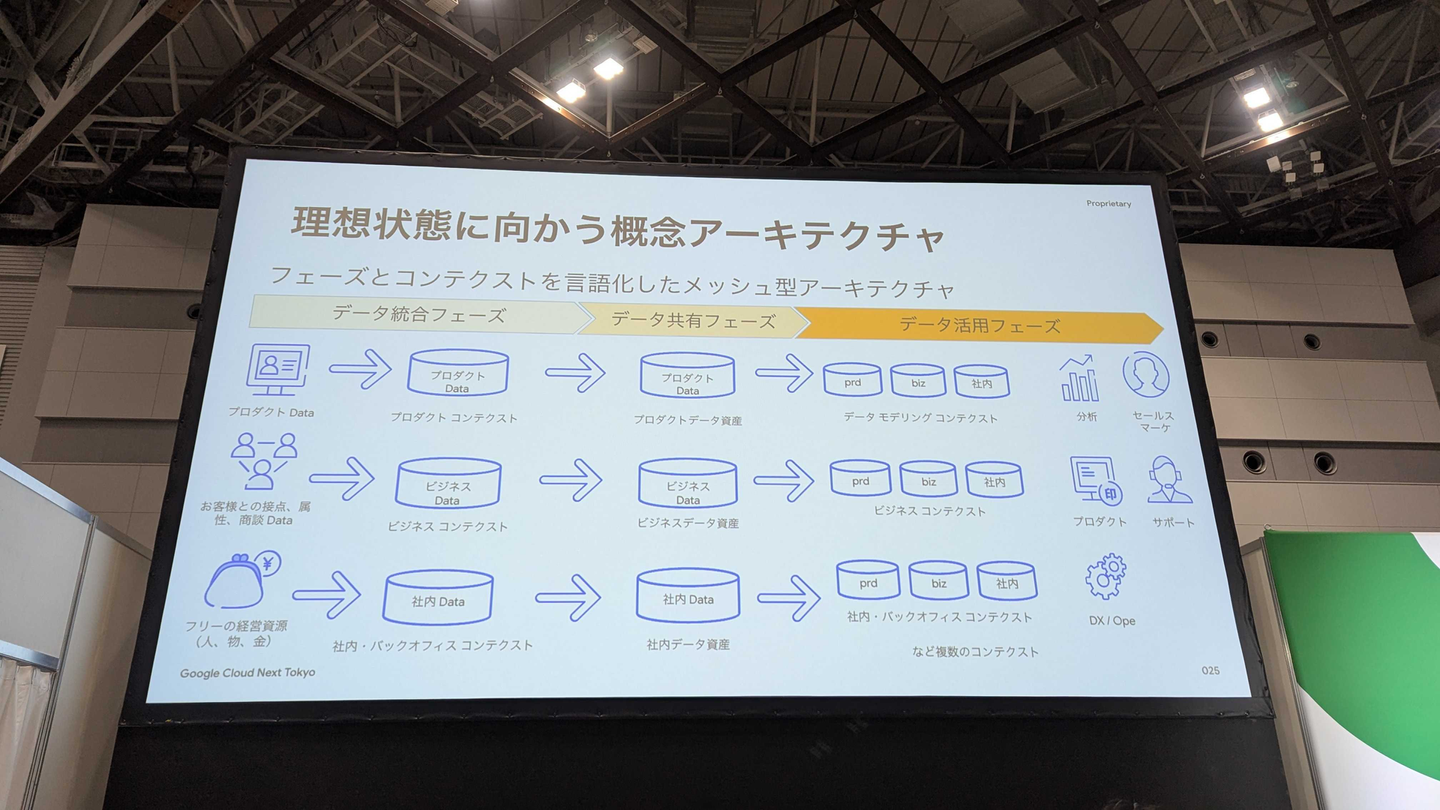
このデータメッシュをGoogle Cloudで構築する際は、フェーズごとにプロジェクトを分割しているようです。データ統合フェーズのデータをBigQuery Sharingで共有フェーズのプロジェクトに公開することで、データをコピーすることなくセキュアに共有しています。
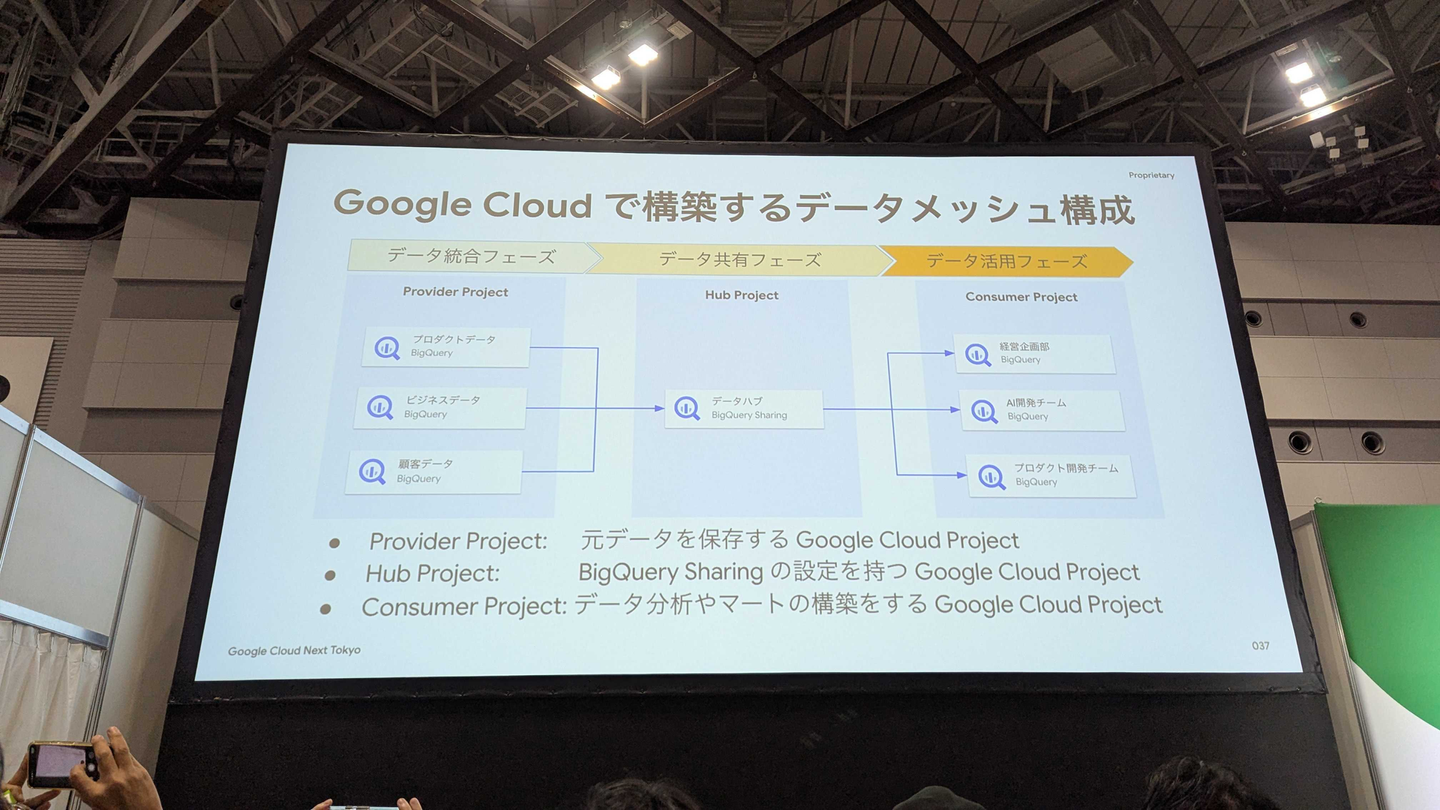
この他にも、Policyタグを使ったガバナンス強化や、Policyタグ自体を生成AIで分類するなどの取り組みが共有されました。
本セッションを通じて、生成AIを効果的に活用するためには、基盤となるデータの整備が最も重要であることを改めて認識しました。
Datadog による AI エージェント オブザーバビリティの最前線
AIエージェントの挙動にはブラックボックス的な側面が多く、機能改善や問題対処時の効率が課題となっています。Datadogのセッションでは、このような状況下でいかにAIのオブザーバビリティを確保するかについて紹介されました。
セッション内で紹介されたAIエージェントの行動フロー可視化機能では、エージェントの動作プロセスを図で確認できることが示されました。この機能により、最終的な出力で発生したハルシネーションが上流のツール呼び出しの失敗に起因していることを容易に特定可能であることが紹介され、問題の原因切り分けにかかる時間を大幅に削減できる可能性を感じました。
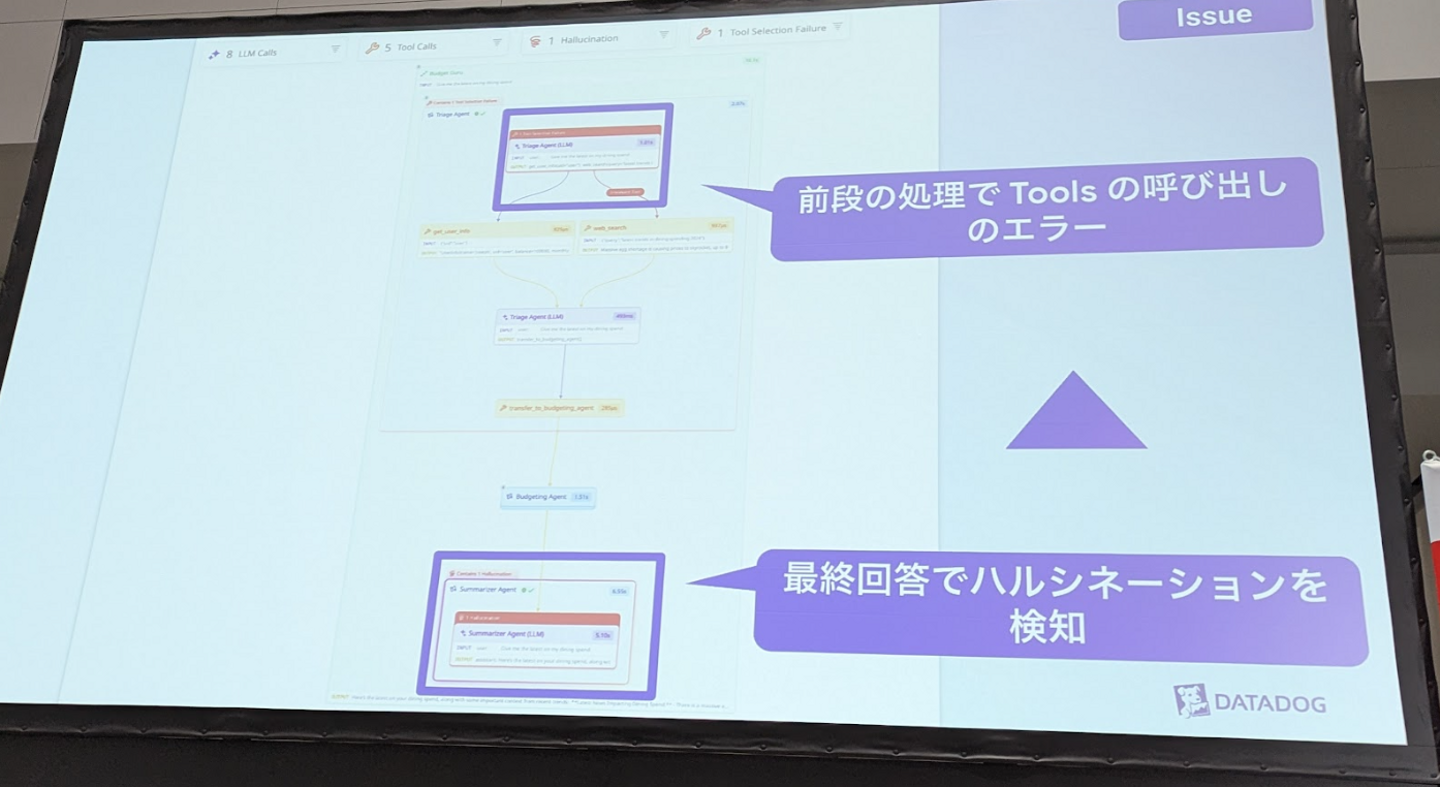
また、Datadogが開発するAIエージェント「Bits AI」では、同社の強みであるトレース機能を活用し、問題の特定から解決まで一貫して自律的に実行できることが紹介されました。これにより、問題調査のコストや解決までの時間を大幅に削減できる可能性があると感じました。
まとめ
Google Cloud Next Tokyo 2日目の基調講演の概要と、聴講した各セッションの内容を紹介させていただきました。近年様々な生成AI系ツールが出現する中、今回の講演では、それらを十二分に活用するためにどのように基盤技術を利用したり、データ整備を進めればいいかについての発表が多い印象でした。
わたしたちもプロダクト開発で日々Google Cloudの技術を活用していますが、他の企業がどのような工夫をされているかという話には、多くの新しい発見がありました。今回の Google Cloud Next Tokyo で学んだ知見をわたしたちの開発に活かし、より良いプロダクトを作っていきたいと思います。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


