

基盤モデルによる生成 AI アプリケーションの構築 - Amazon Bedrock - AWS
基盤モデルを使用して生成 AI アプリケーションを構築およびスケールする最も簡単な方法
https://aws.amazon.com/jp/bedrock/
こんにちは。ウォンテッドリーのEnablingチームでバックエンドエンジニアをしている冨永(@kou_tominaga)です。Enablingチームでは技術的な取り組みを社外にも発信すべく、メンバーが週替わりで技術ブログをリレー形式で執筆しています。前回は市古さんによる「なぜ、仕事が大きくなると手が止まるのか」 でした。今回は「生成AIを用いて履歴書からプロフィールを自動生成する試みについて」です。
サービス登録時の「プロフィールや経歴の記入」など手間がかかる作業はユーザが離脱しやすい箇所です。私たちはこの課題に取り組むべく、AWS様と共同でハッカソンを開催しました。そこで、ユーザーがアップロードした履歴書からプロフィールを自動生成する機能を実装しました。結果的に通常は数分かかるプロフィール登録を数十秒で完了するようにできたので、方法や学びをまとめます。
※この機能はハッカソンで試作したものであり、2025年7月30日時点ではプロダクトに未実装です。
背景
履歴書→プロフィール自動生成の PoC
工夫・学び
構造化データを取得するコツ
プロダクト組み込みの留意点
まとめ
サービス内でプロフィールが十分に入力されていないと、企業からのスカウトやユーザー同士のマッチングがうまく機能しません。この状態が続くとユーザーが「使いにくい」と感じて離れてしまうことや、採用担当者が魅力的と感じる候補者をなかなか見つけられず、採用にかかる時間やコストが増えるといった問題が生じます。そこで「生成AIを利用してプロフィール入力を手軽にできないか」という問いから検討を始めました。
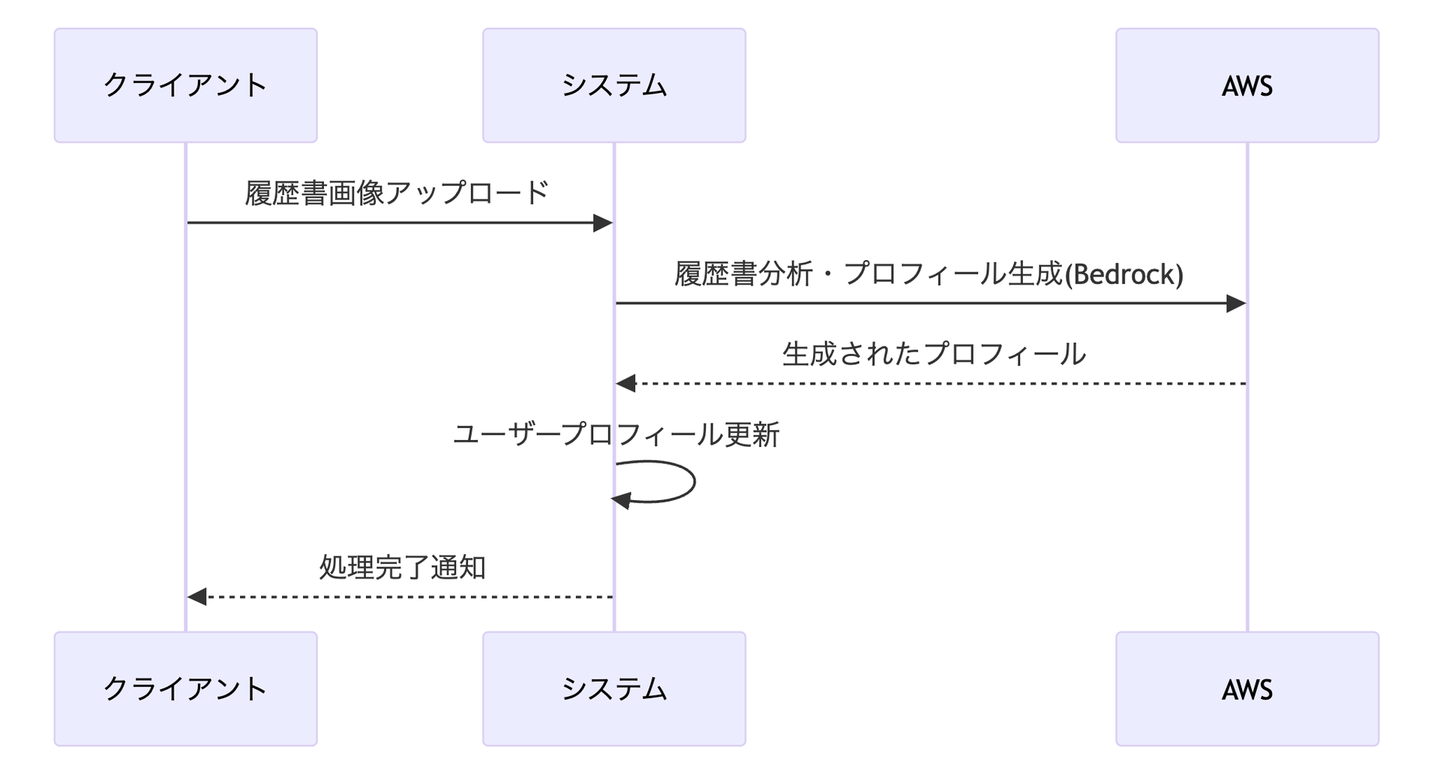
プロフィール自動生成の大まかな流れは、ユーザーがアップロードした履歴書から「基本情報 (名前、性別、生年月日)、職歴(会社名、期間、業務内容)、スキル(言語、フレームワーク、ツール)」といった情報を抽出します。この情報をベースにWantedlyのプロフィールに反映します。今回はシンプルに以下フローで実装しました。
※プロフィール生成は時間がかかるので、プロダクトに組み込む際は非同期にするなどの対策が必要です。
生成AIは社内で利用しているAWSですぐ利用できること、IAMで権限管理ができる事などからAmazon Bedrockを利用しました。
利用したプロンプトは以下です。
あなたは履歴書から情報を抽出し、構造化されたJSONに変換する専門家です。
以下のルールに従ってください:
1. 提供された履歴書(PDF、Markdown、または画像)から情報を抽出し、指定されたJSON形式で出力してください
2. 情報が見つからない場合は "N/A" と表示してください
3. 日本語と英語の両方の履歴書に対応してください
4. 出力は必ず有効なJSON形式にしてください
5. 説明や補足は一切含めず、JSONのみを出力してください
6. 画像の場合は、画像内のテキストを認識し、履歴書情報を抽出してください
jsonの各フィールドは次の意味を持ちます
<field_description>
employment_type:雇用形態のカテゴリ値 ["フルタイム", "インターン", "副業", "その他"] から選択
job_type: 職種のカテゴリ値 ["エンジニアリング", "デザイン・アート", "PM・Webディレクション", "編集・ライティング", "マーケティング・PR", "セールス・事業開発", "カスタマーサクセス・サポート", "コーポレート系", "コンサルティング", "メディカル系", "その他"]
</field_description>
添付された履歴書から情報を抽出し次のJSON形式で出力してください。
情報が見つからない場合は "N/A" と表示してください。
最初の一文字は{でお願いします。
出力例:
{
"basic_info": {
"last_name": "string",
"first_name": "string",
"date_of_birth": "YYYY-MM-DD string",
"area": "string",
"contact": {
.... プロフィールに必要な情報 .....
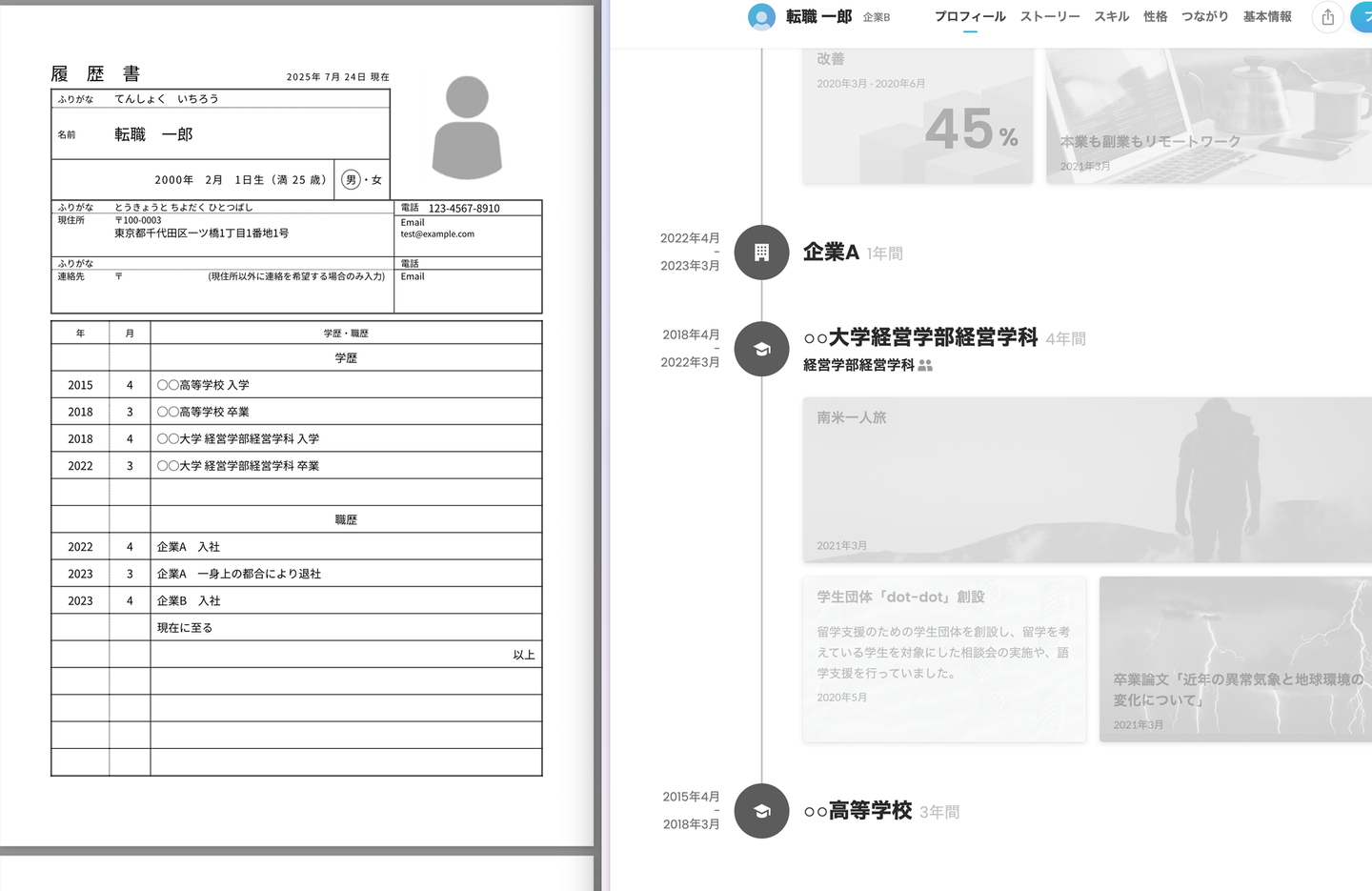
}左の履歴書から右のプロフィールを生成でき、数分かかる作業を20秒程度で終える事ができました。今回は履歴書をベースに登録を行いましたが、経歴を登録しているSNSのURLを入力する事などでも可能そうです。
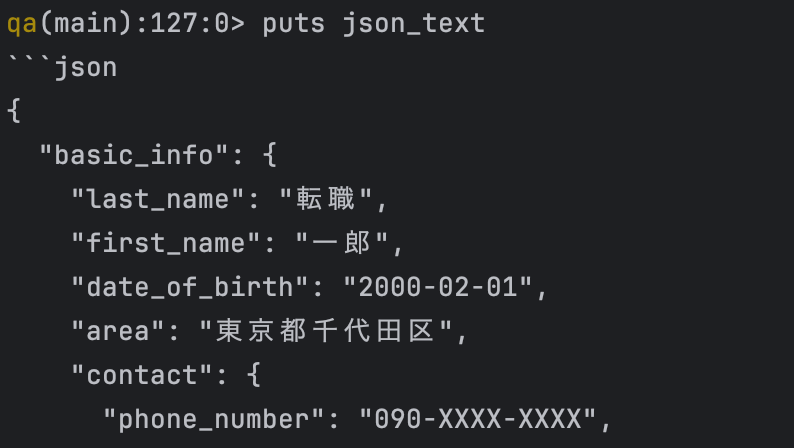
生成AIのレスポンスはJSONを想定していたのですが、初回の検証では以下のようにMarkdownで返却されました。※生成AIはClaude系のモデルを利用しています。
プロンプト
添付された履歴書から情報を抽出し次のJSON形式で出力してください。
情報が見つからない場合は "N/A" と表示してください。
出力例:
{
"basic_info": {
"last_name": "string",
"first_name": "string",
"date_of_birth": "YYYY-MM-DD string",レスポンス( 意図せず```jsonが含まれている)
対策としてプロンプトに「最初の一文字は{でお願いします」を追加する事でJSON形式で返却されるようになりました。モデルClaudeを利用した場合の構造化データを取得する他の方法として、以下がありました。PoCなので簡易的な対策をしましたが、本番利用の場合はAnthropic側で構文を補正するJSONモードを利用するのが良いと考えています。
この機能はレスポンスの初期テキストを指定できます。「{」を指定してアプリケーション側でレスポンスの先頭に { をつける事でJSONとしてパースが可能になります。
※ただし、JSONより前に「{」が含まれる場合やJSONの後に文章が含まれる場合にJSONとしてパースできなくなり、本番利用には向きません。
この機能は出力がJSON形式になるようAnthropic側で構文を補正してくれます。JSONモードを利用することで曖昧なマークダウン形式やテキスト形式ではなく、常に厳密な構文のJSONとして出力されるように制御できます。
プロダクトへの生成AIの組み込みは技術的には容易で、着手したその日に API から呼び出して動かすところまでできました。しかし、本質的に難しかったのは「何を自動化し、どこに人間の判断を残すか」という設計方針でした。以下に検討時に意識したポイントを記載します。
1. 扱う情報を明確する
生成対象となるプロフィールの項目を以下の2種類に分類しました。
今回のPoCでは、事実情報を自動生成する事に限定して実装しました。
2. 創造情報を扱う際には「ユーザーの納得感」を担保する仕組みを用意する
創造情報はプロンプトのチューニングや入力するコンテキストの工夫により、人間が書いたものと遜色ないアウトプットが得られました。しかし、ユーザーが「これは自分の言葉だ」と納得できるプロセスが必要で、以下のようなユーザが介入できる工夫が必要だと考えています。
生成AIは適切なシナリオを選定すればユーザー体験と事業指標の双方を押し上げる有効な手段です。プロフィール入力を改善した具体例を紹介しましたが、入力負荷の高いフォームやオンボーディングフローなど 他のボトルネックにも応用が可能です。本記事が同様の課題に取り組む皆さまのヒントとなれば幸いです。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
/assets/images/16907545/original/ec791cd3-ea53-45e2-bc6f-a1262b413594?1753696883)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

