ある日、自分が開発を担当していたページで「Google Chrome の翻訳機能を使うと正常に表示されない」という報告を受けました。調べてみると、React と Google Chrome のページ翻訳機能(以降 Google 翻訳)の相性の問題であることがわかりました。
既にいくつかの対応策も存在しており、先人たちの知恵を借りて今回の問題も無事解決することができました。ただ、その対応が「なぜ効いたのか」という点についてはいまひとつ腑に落ちないままで、React や Google 翻訳の中で何が起こっているのか好奇心を抱き調査しました。
この記事では、Google Chrome のページ翻訳機能が React アプリケーションにどのような影響を与えるのか、なぜその対策が効いたのかについて React の挙動と Google 翻訳の挙動を観察しながら掘り下げていきます。
なお今回の記事では React 19.0.0 を利用します。
目次 Google Chrome のページ翻訳機能と React の相性問題について
なぜ <span> などで囲むと問題を回避できるのか
Google Chrome のページ翻訳機能の仕組み
翻訳された DOM で React はどう動くのか
1. MixedPattern
2. Wrapped Pattern
3. Simple Pattern
4. Nested Parttern
5. Multiple Mixed Pattern
6. Span Test Pattern
7. Depth Test Pattern
React Fiber に関する仮説
Deep wiki を利用して調査する
shouldSetTextContent
なぜ HostText の場合は正常に更新されないのか
まとめ
おまけ
さいごに
参考
Google Chrome のページ翻訳機能と React の相性問題について 前提の整理から始めます。Google Chrome のページ翻訳機能による React アプリケーションへの影響は大きく2つあります。
React の state が正しく更新されない アプリケーションがクラッシュする 例えば次のような React Component があったとします。
function TrailOfBreadCrumbs ( { breadcrumbsCount } ) { return ( < p > A landmark on the way home : There are { breadcrumbsCount } trails of crumb 🍞 </ p > ) ; } 翻訳前では正常に state が更新されていたにも関わらず、翻訳後では state が更新されなくなります。
これは既知の問題として知られており、React の GitHub でも問題が報告されています。
次のブログではいくつかの回避策を紹介しています。その中の1つが テキストノードを <span> タグで囲む という手段です。
実際に先程の React Component を翻訳後も正常に動作させるには以下のような DOM 構造にすることで問題を回避することが可能です。
function TrailOfBreadCrumbs ( { breadcrumbsCount } ) { return ( < p > < span > A landmark on the way home : There are </ span > < span className = "text - orange - 500 font - bold” > { breadcrumbsCount } </ span > < span > trails of crumb 🍞 </ span > </ p > ) ; } なぜ <span> などで囲むと問題を回避できるのか 結論から言うと、React Fiber において、HostComponent(たとえば span タグ)が唯一のテキストノードを子要素として持つ場合、そのテキストは HostText Fiber として生成されず、textContent として直接扱われます。この場合、Google 翻訳によって挿入される font タグなどの装飾ノードは React によって上書きされ、意図通りのテキストだけが画面に描画されます。
一方で、テキストが HostText として明示的に Fiber として生成されている場合、React は nodeValue を通じてそのテキストノードを直接更新しようとします。しかし、Google 翻訳により元の TextNode が意図せず削除されていると、React が保持していた参照は無効となり、再レンダリング時に更新が反映されない、または例外が発生するといった問題が起こります。つまり、span タグなどでテキストを囲むことで、React がテキストを textContent として管理し、翻訳による破壊的な DOM 操作の影響を受けにくくなるということです。
ここからは Google 翻訳の仕組みや、React Fiber がどのようにテキストノードを扱っているのかについて自身がどのように調査し結論に辿りついたのかについて記述します。
Google Chrome のページ翻訳機能の仕組み Google 翻訳は、ユーザーにとって非常に便利な機能ですが、その内部の挙動については公開されておらず、基本的にブラックボックスです。そこで実際に React Component が生成した DOM を翻訳してみることで、Google 翻訳が DOM に対してどのような影響を与えているのか観察してみました。
これから記述することはあくまで実験に基づいた仮説であり、仕様として保証されたものではありません。その点はあらかじめご了承ください。
例えば次のようなシンプルな React Component で試してみます。
function TrailOfBreadCrumbs ( { breadcrumbsCount } ) { return ( < p > A landmark on the way home : There are { breadcrumbsCount } trails of crumb 🍞 </ p > ) ; } このとき、実際にブラウザ上で生成される DOM は以下のようになります。
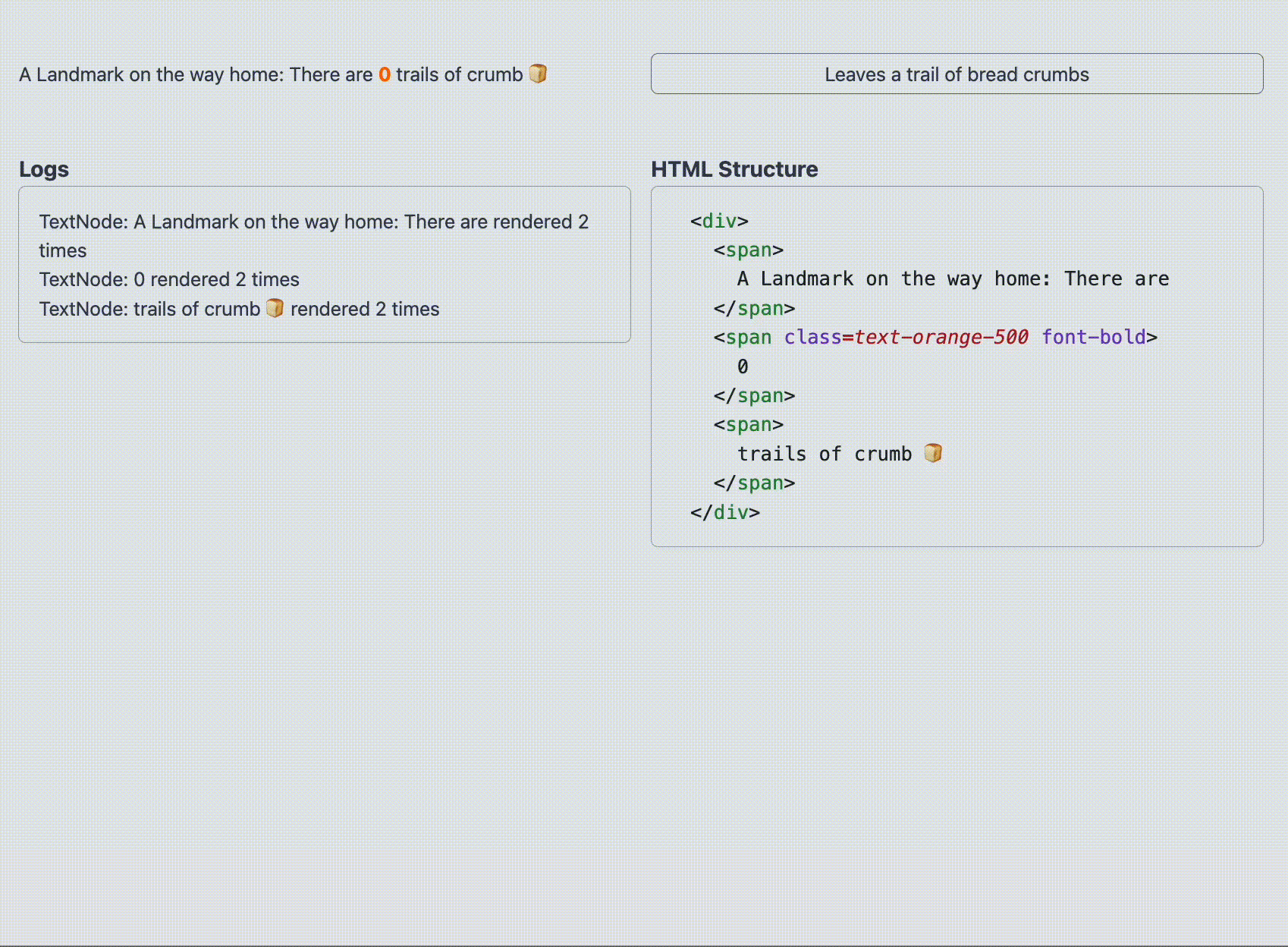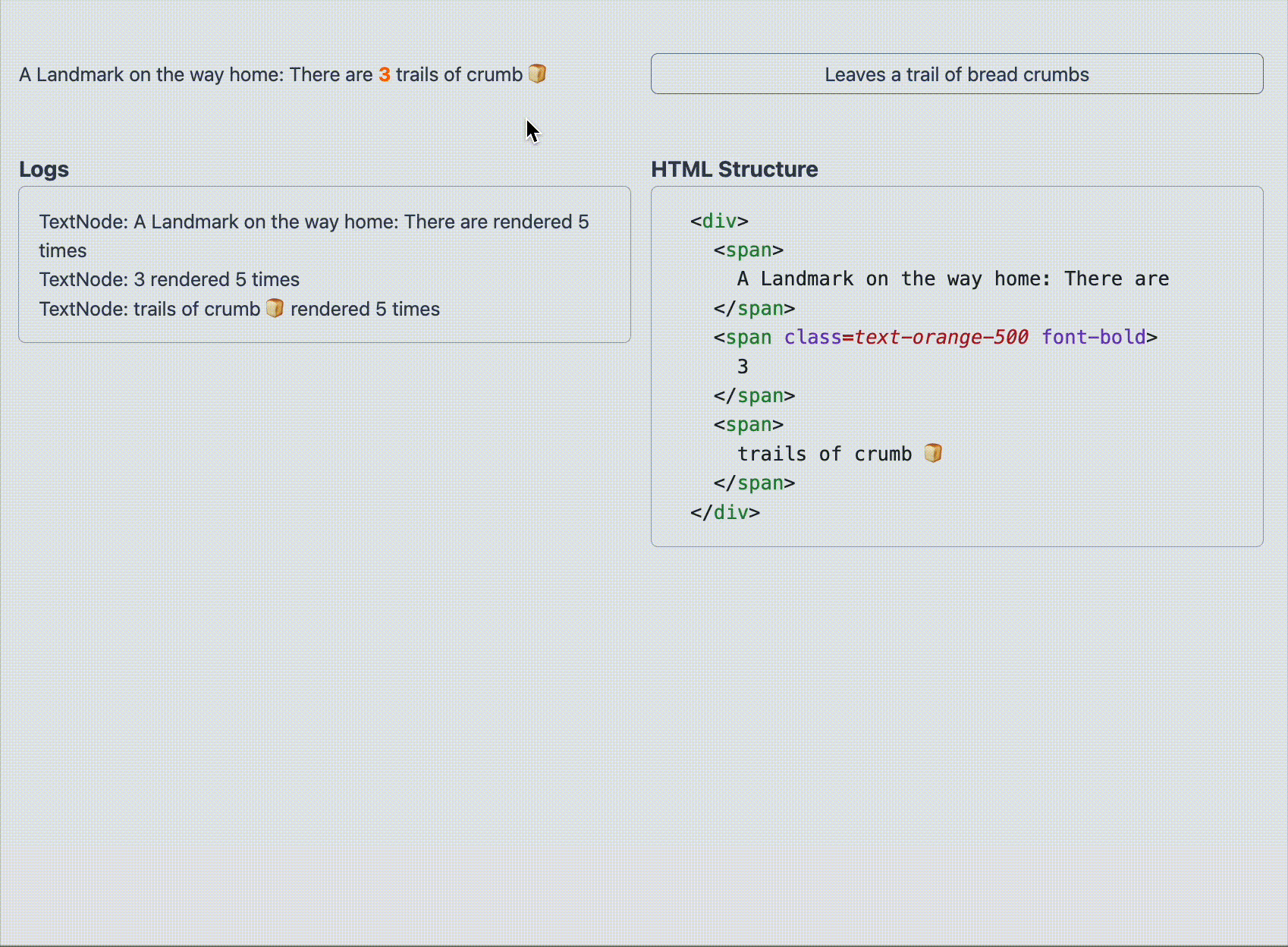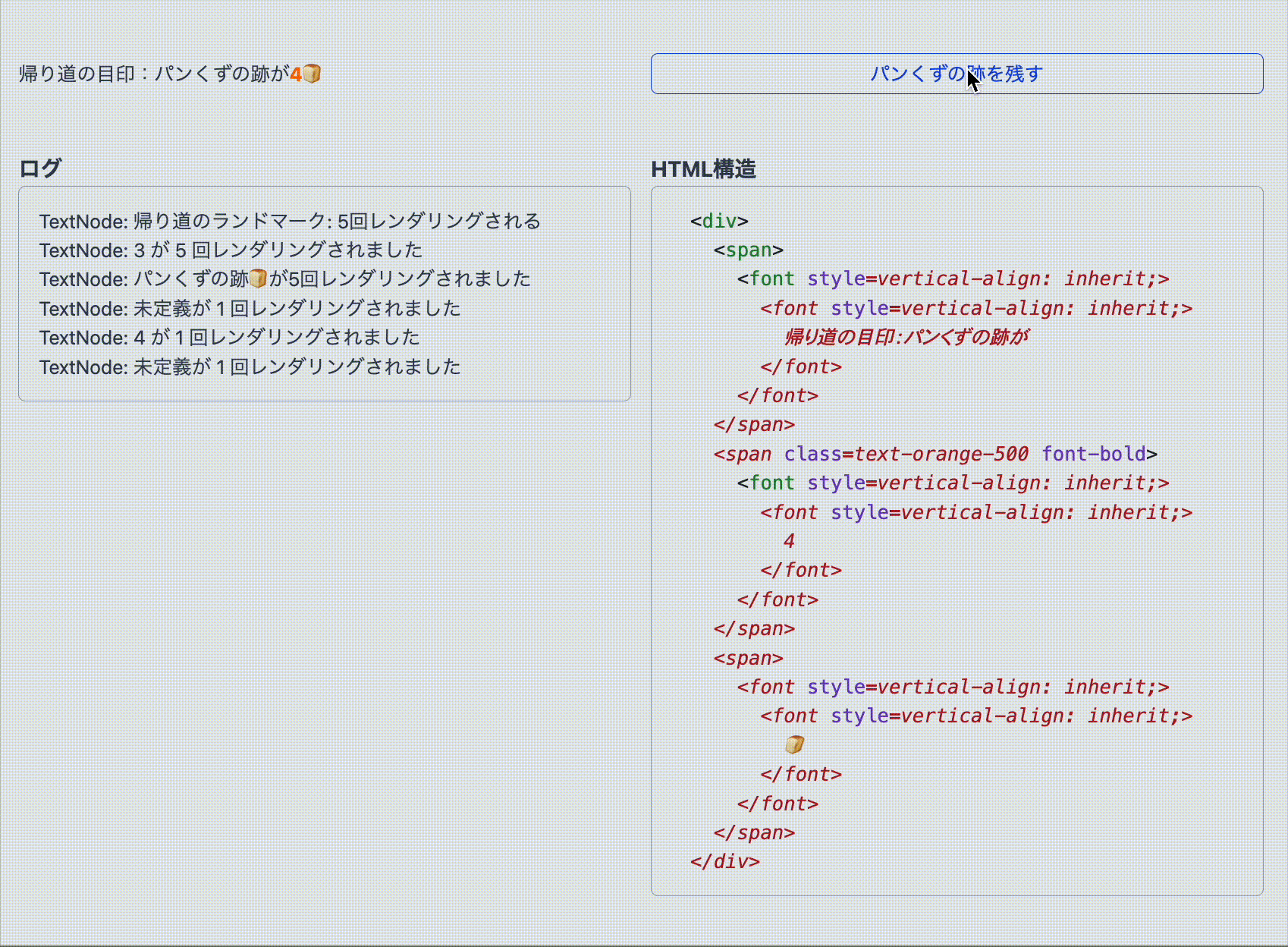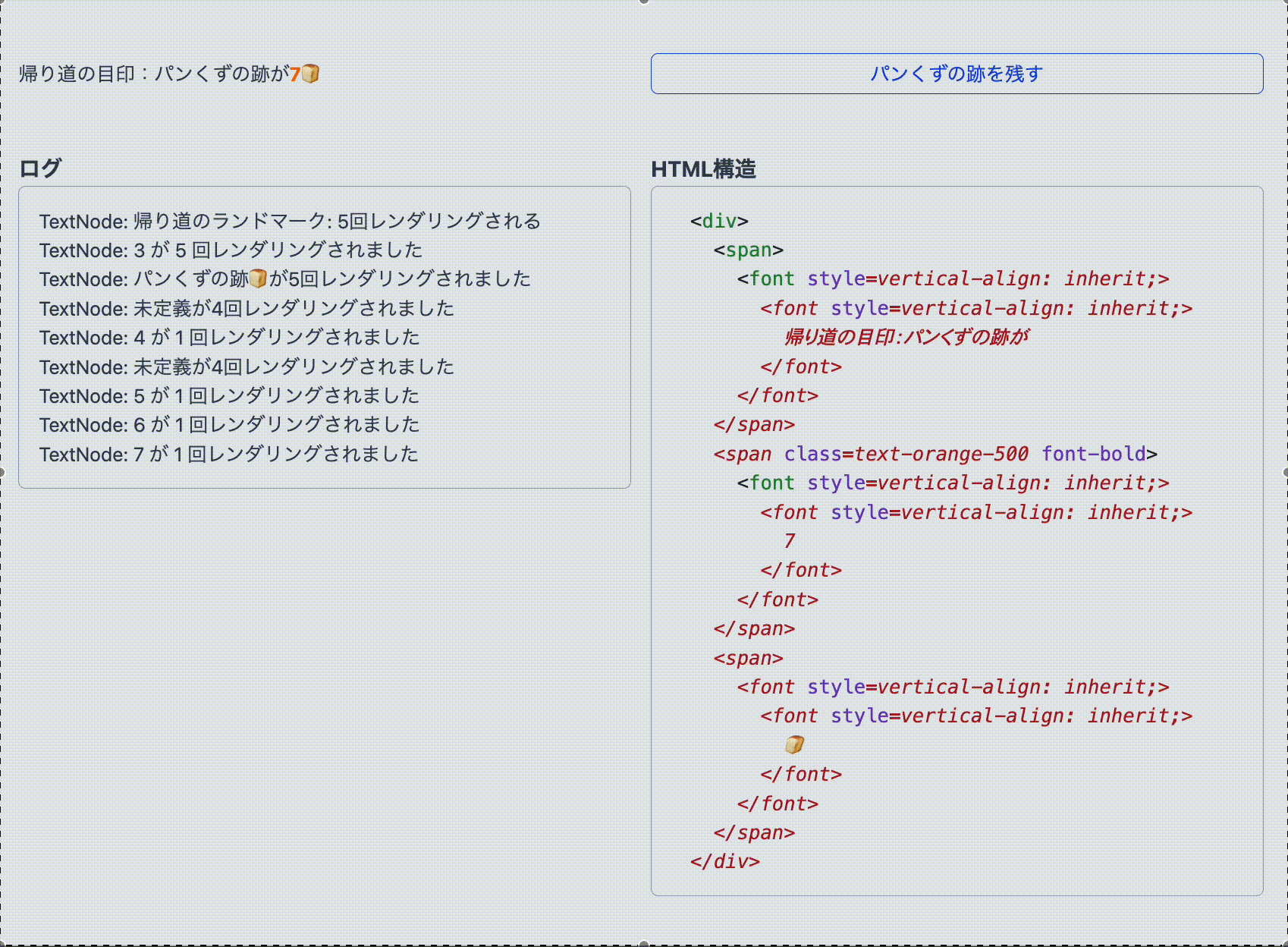
< p > A landmark on the way home: There are 0 trails of crumb 🍞 </ p > では、この DOM を Google 翻訳で日本語に翻訳してみましょう。
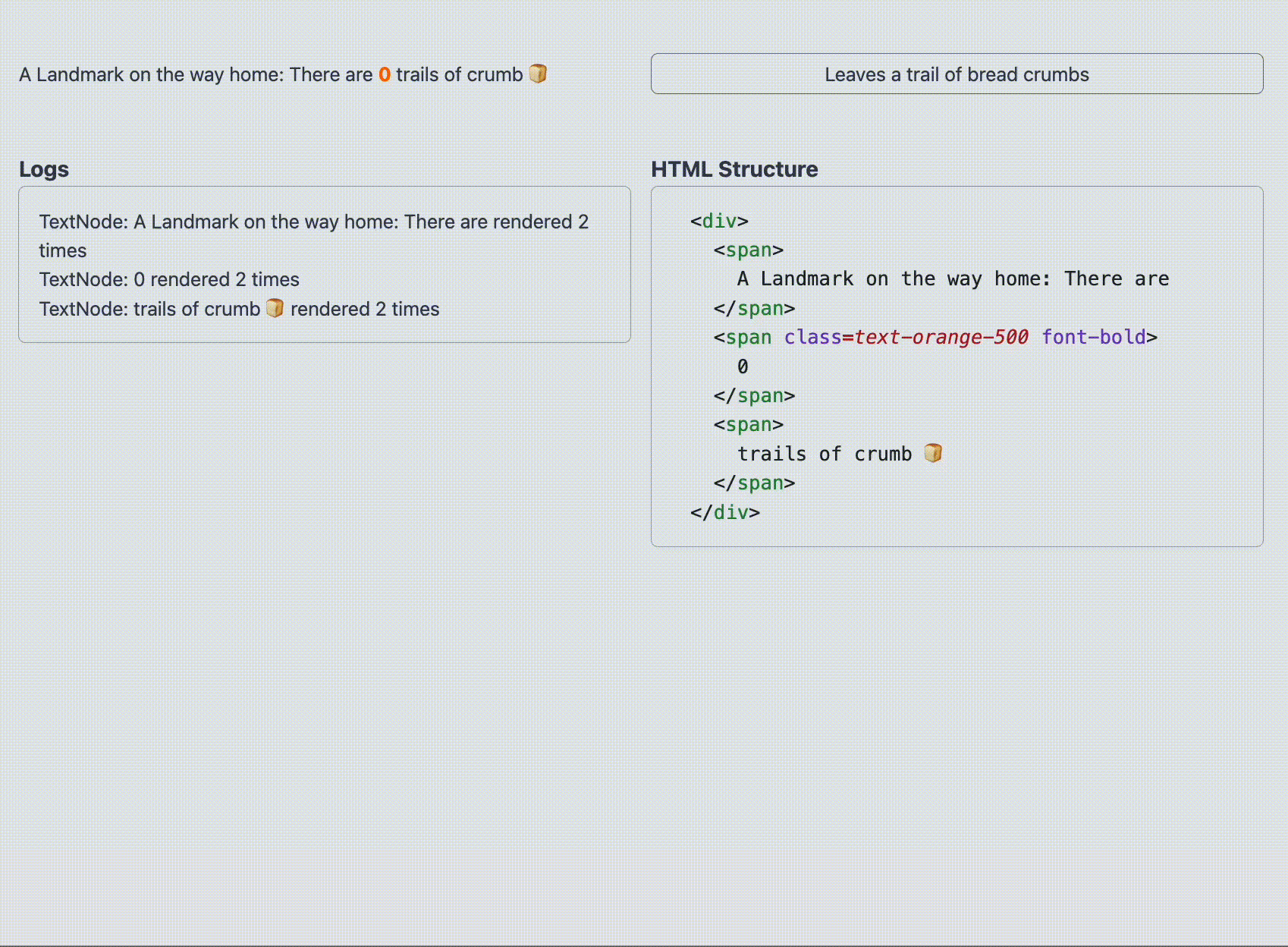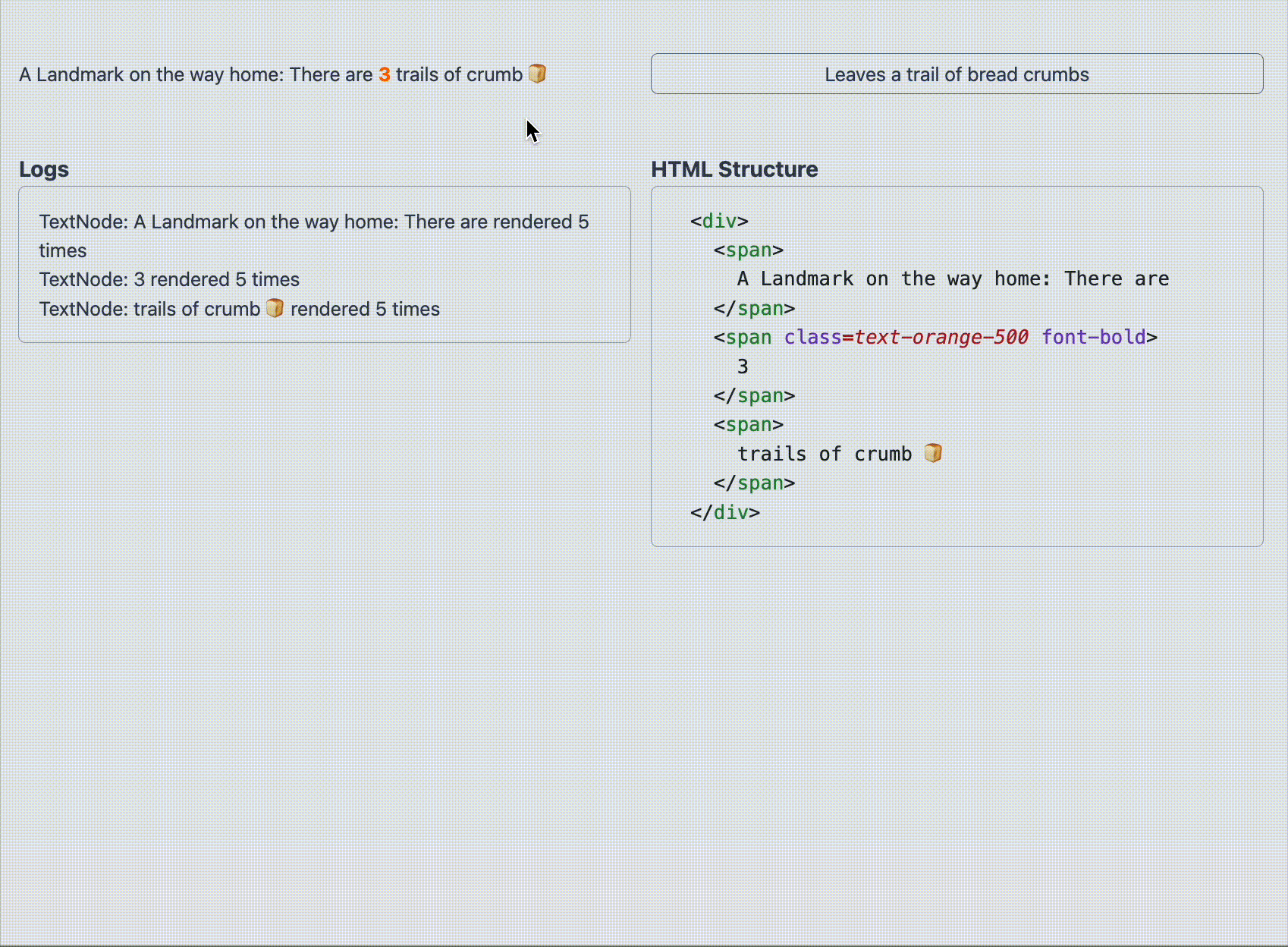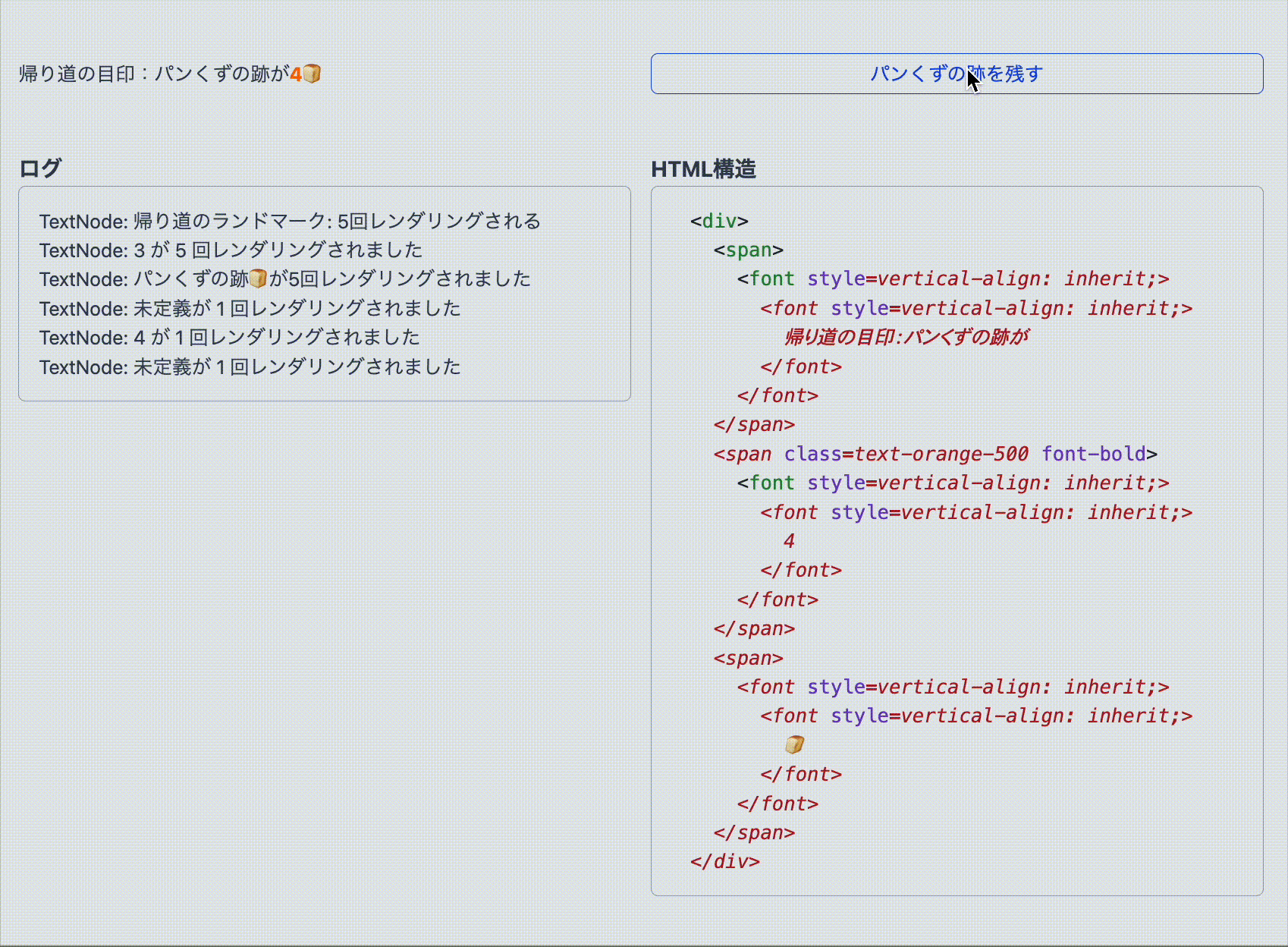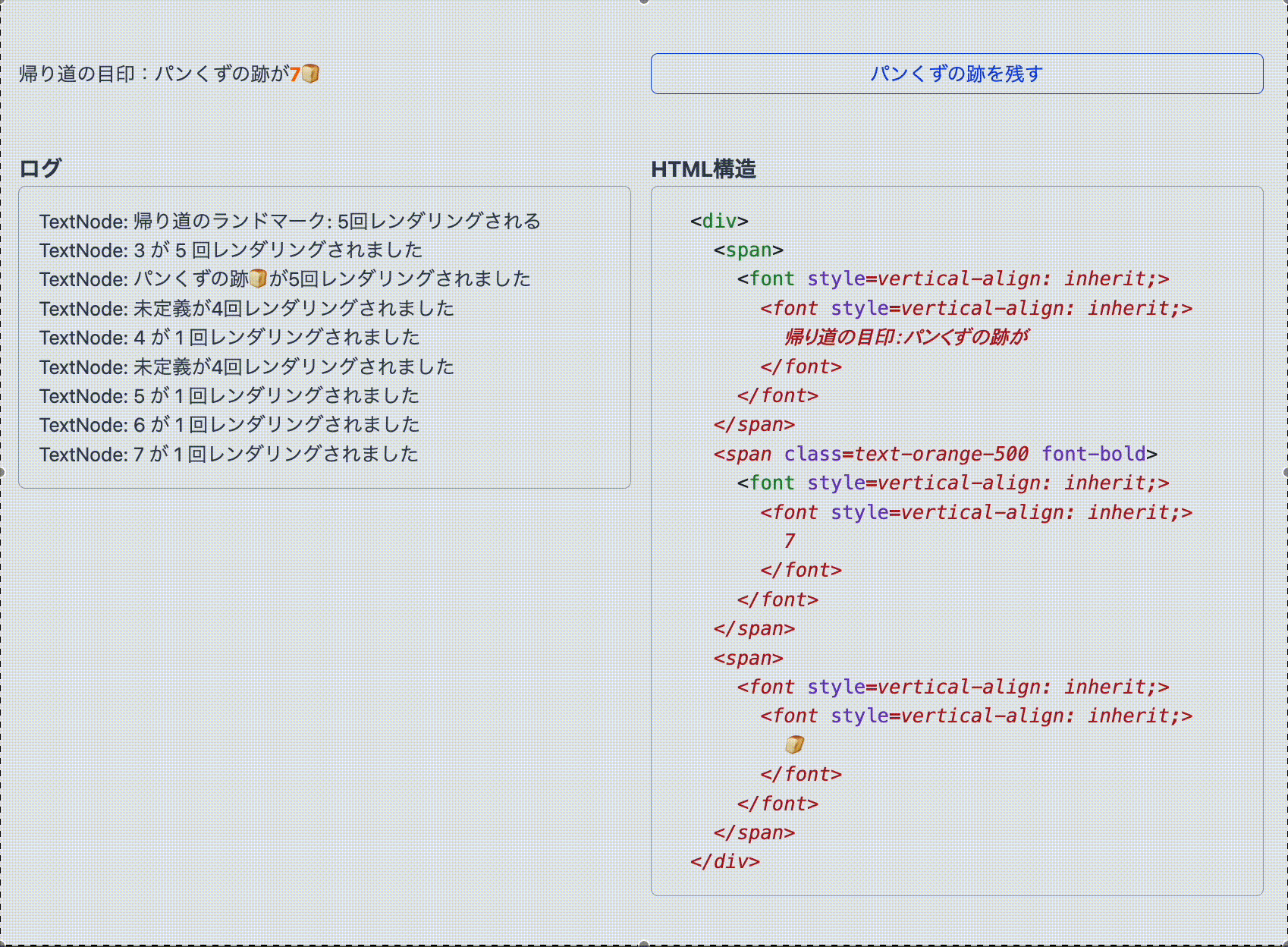
< p > < font style = vertical-align : inherit; > < font style = vertical-align : inherit; > 帰り道の目印:パンくずの跡は </ font > </ font > < font style = vertical-align : inherit; > < font style = vertical-align : inherit; > 0個 </ font > </ font > < font style = vertical-align : inherit; > < font style = vertical-align : inherit; > 🍞 </ font > </ font > </ p > Google 翻訳はテキストノードを検出したあと、文を意味のまとまりごとに分割し、翻訳した文章を含む FontElement に置き換えているようです。
特に注目すべきは、数字(0)や絵文字(🍞)も、それぞれ個別に FontElement でラップされている点です。おそらく日本語の助数詞(0個、1つ、3本)に対応するため、数字は文脈によって独立して扱われ、別のノードとして処理されているのではないかと推測できます。絵文字も同様に、視覚的な意味を持つため特別扱いされているようです。
この構造を見る限り、元のテキストノードは DOM から完全にアンマウントされていることがわかります。つまり、Google 翻訳は React が管理している DOM を直接操作していることになり、これが後の問題の理由となるわけです。
翻訳された DOM で React はどう動くのか 今回は主にテキストノードの変更・再利用の有無を観察することで、React による 差分検出が実 DOM にどのようなコミットを行うのか確認します。以下のような方法で検証してみましょう。
各テストパターンで <div> の ref を取得 初回レンダリング後、 div.current.childNodes からテキストノードを抽出 テキストノードを Map<Node, number> に記録 次に state を更新し、React による再レンダリングを発生させる 再度同様にテキストノードを抽出し、ノードオブジェクトが同一かどうかを比較 ここからは 7 パターンに分けて調査してみます。
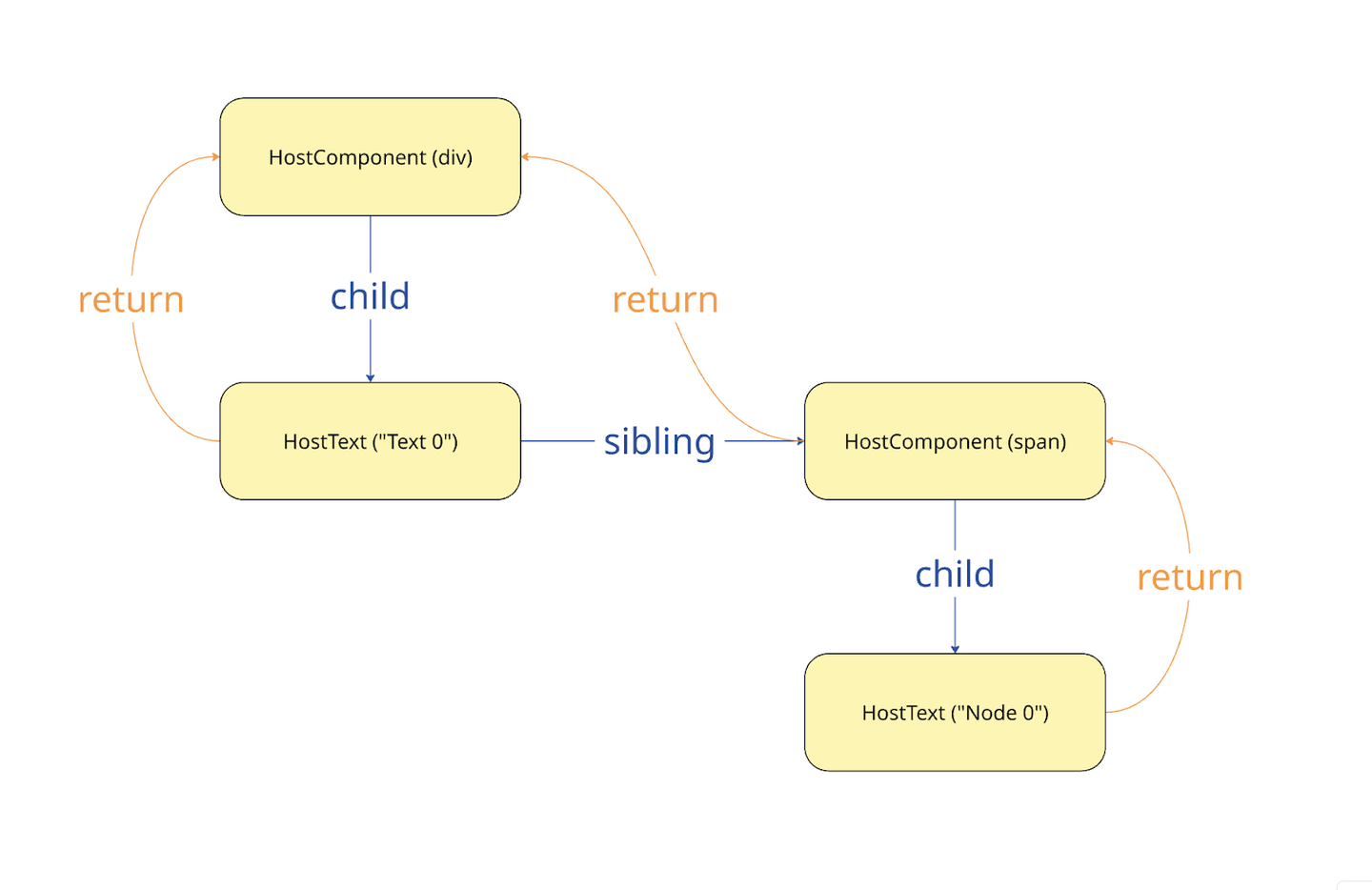
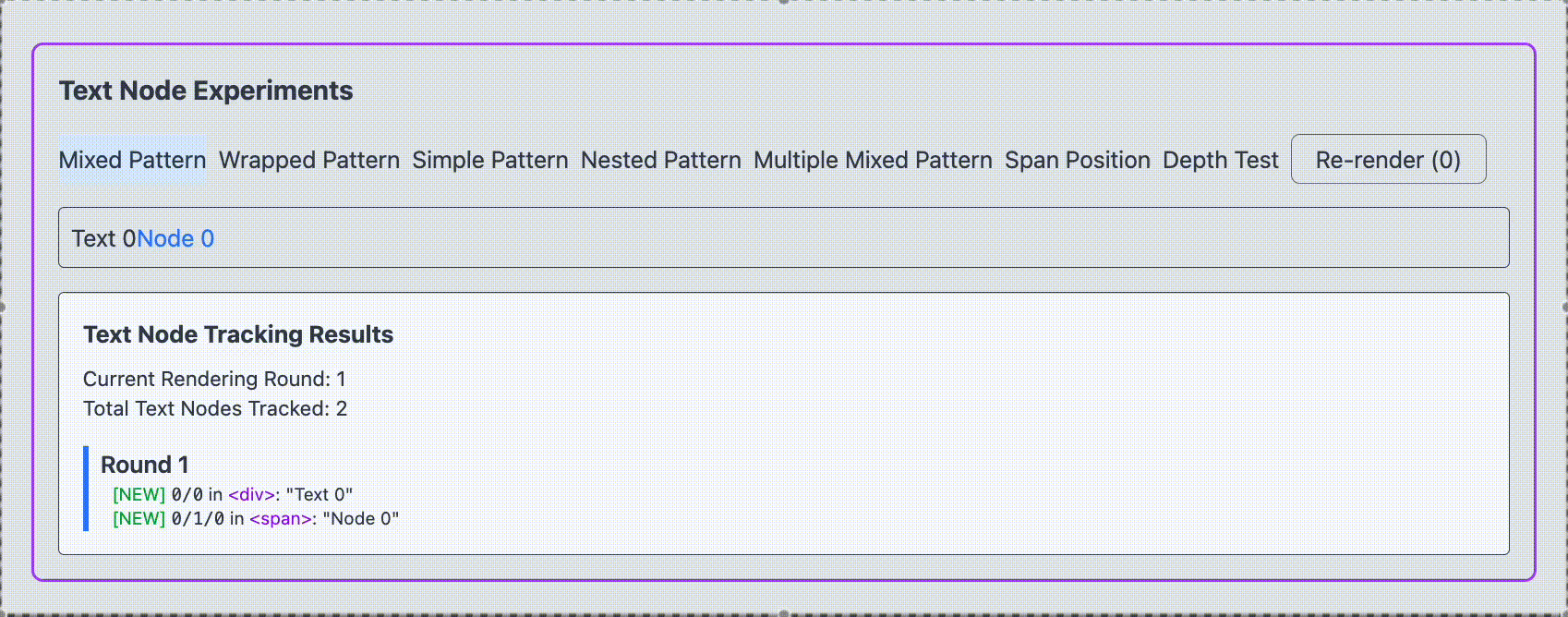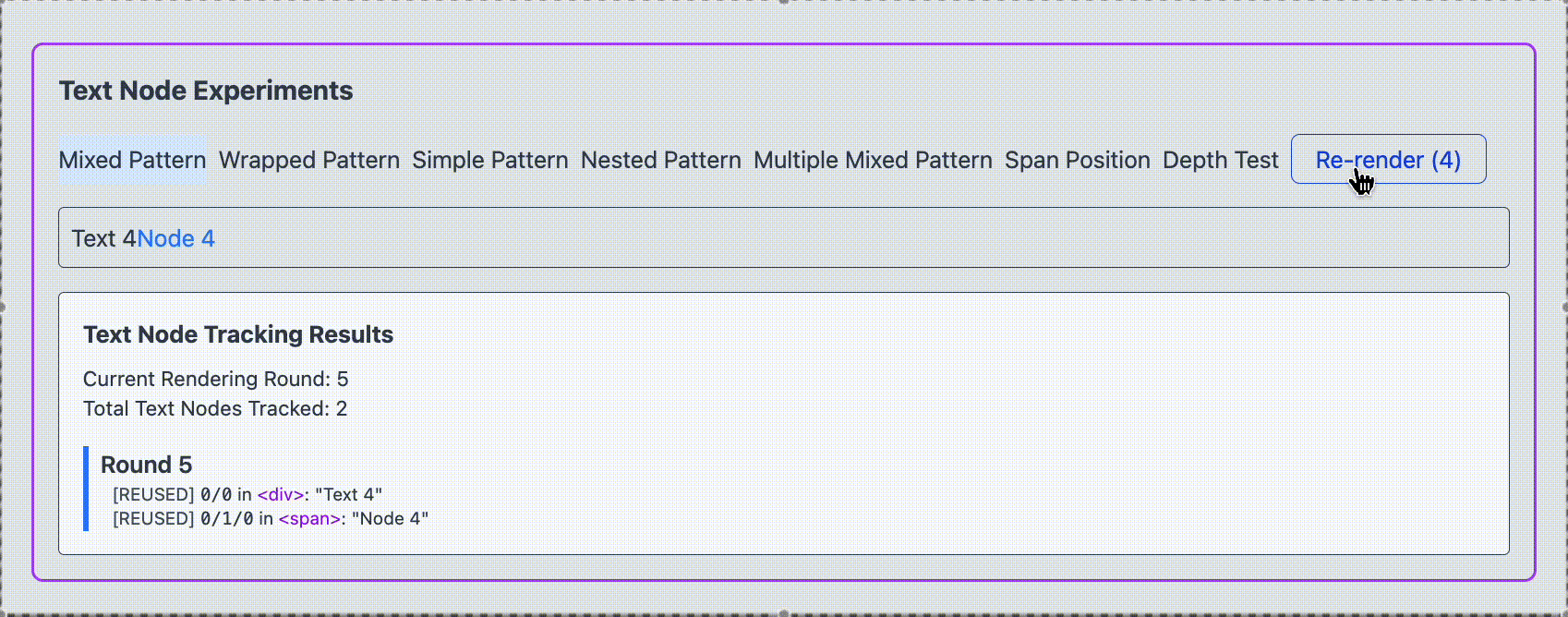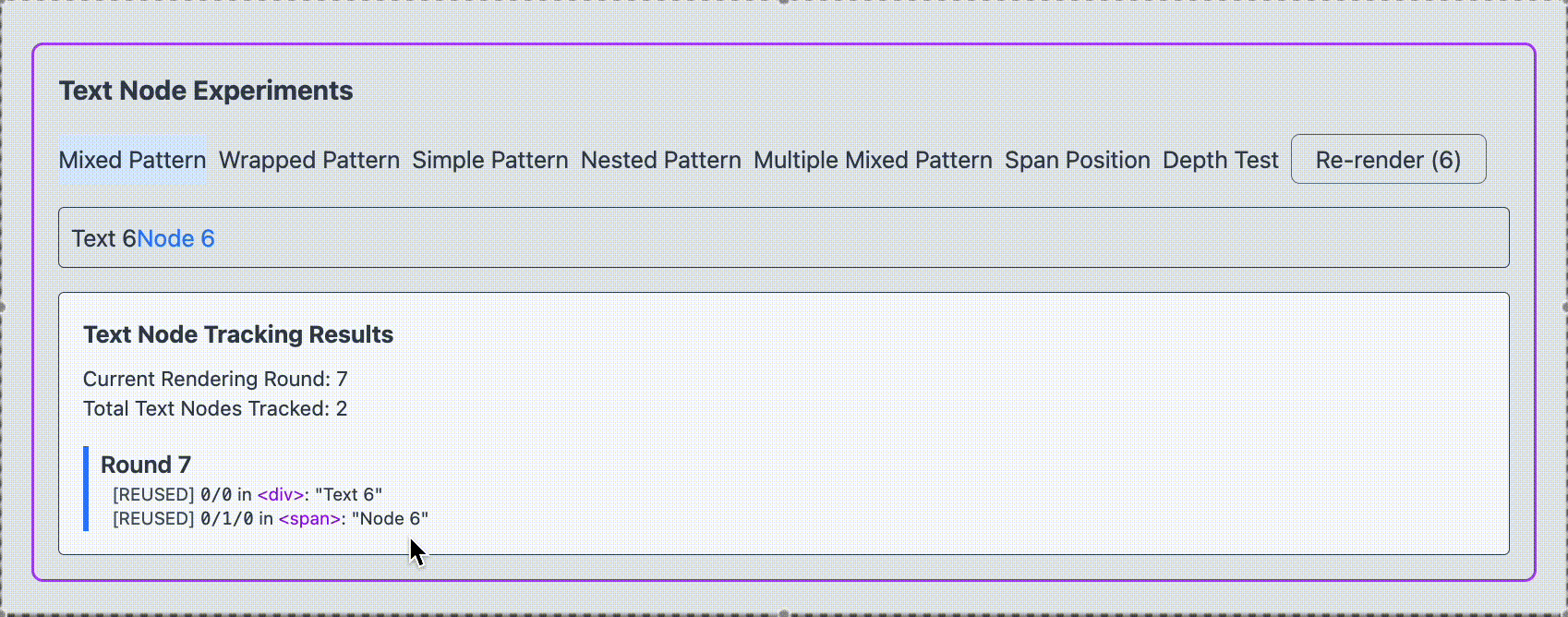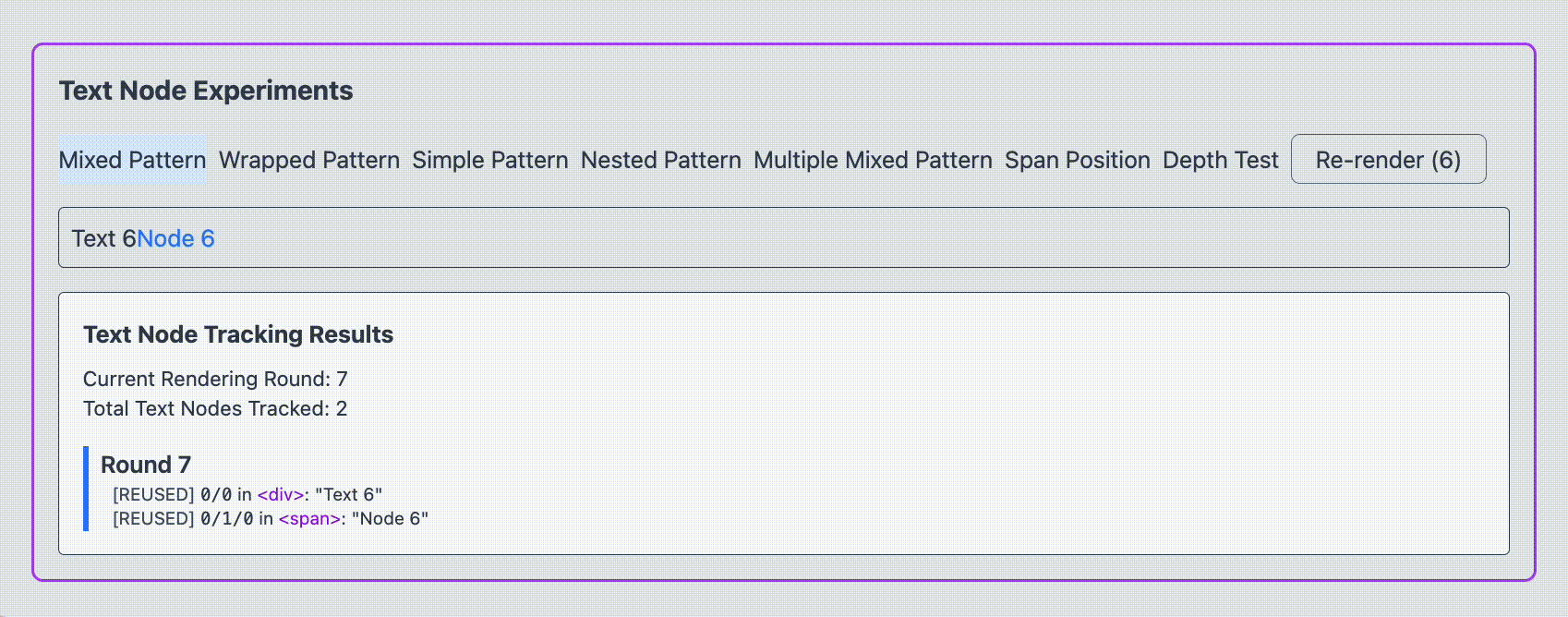
1. MixedPattern function MixedPattern ( { renderCounter } ) { const text1 = ` Text ${ renderCounter } ` ; const text2 = ` Node ${ renderCounter } ` ; return ( < div > { text1 } < span > { text2 } </ span > </ div > ) } これが生成する DOM 構造は次のようになります
< div > Text 0 < span > Node 0 </ span > </ div > つまり、 HostComponent(div) の中に HostText("Text 0") と HostComponent(span) が sibling の関係にある構造です。
翻訳前ではどちらも再レンダリングされ、ノードは再利用されることがわかりました。
それでは翻訳後はどうでしょうか。
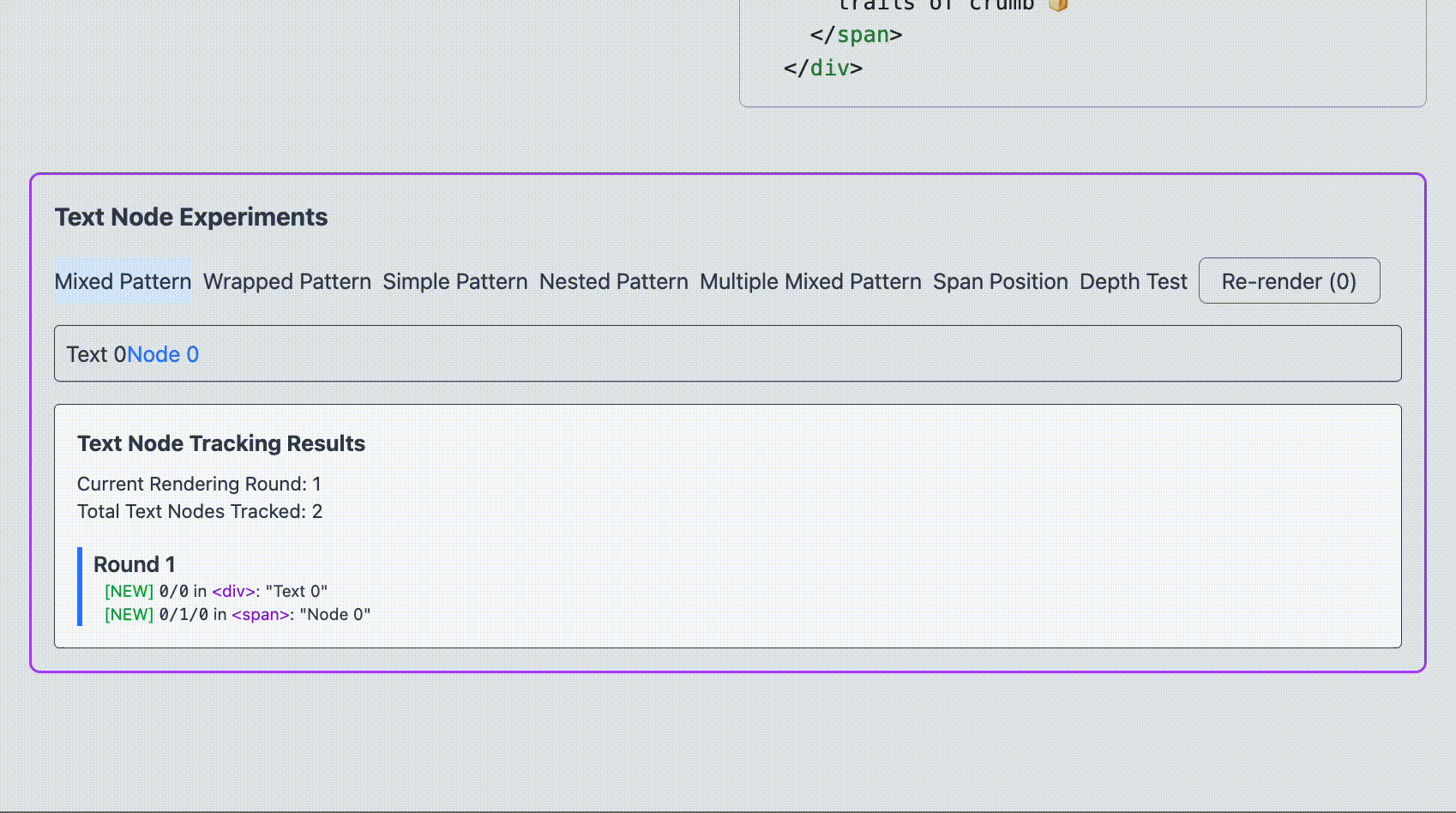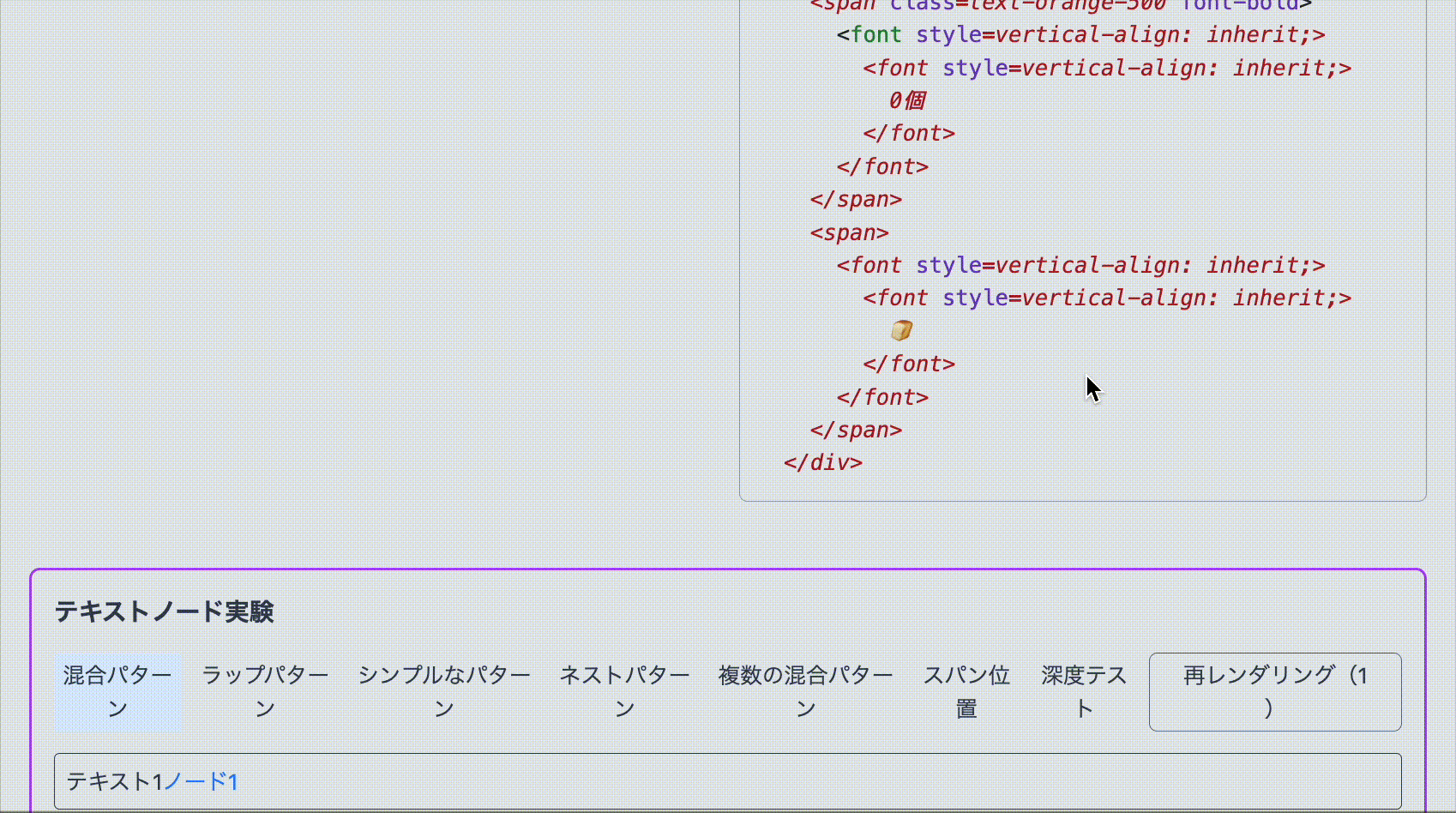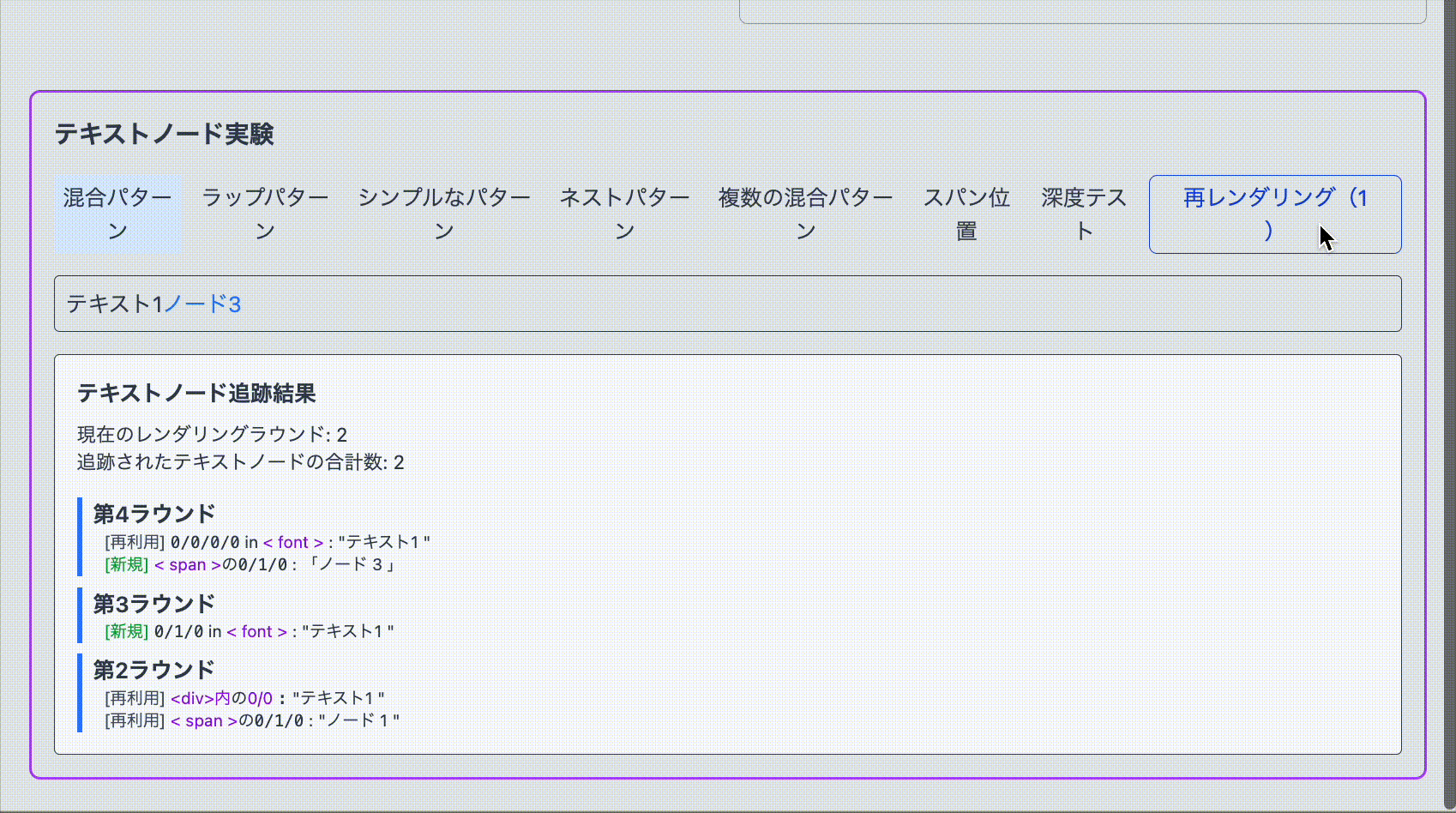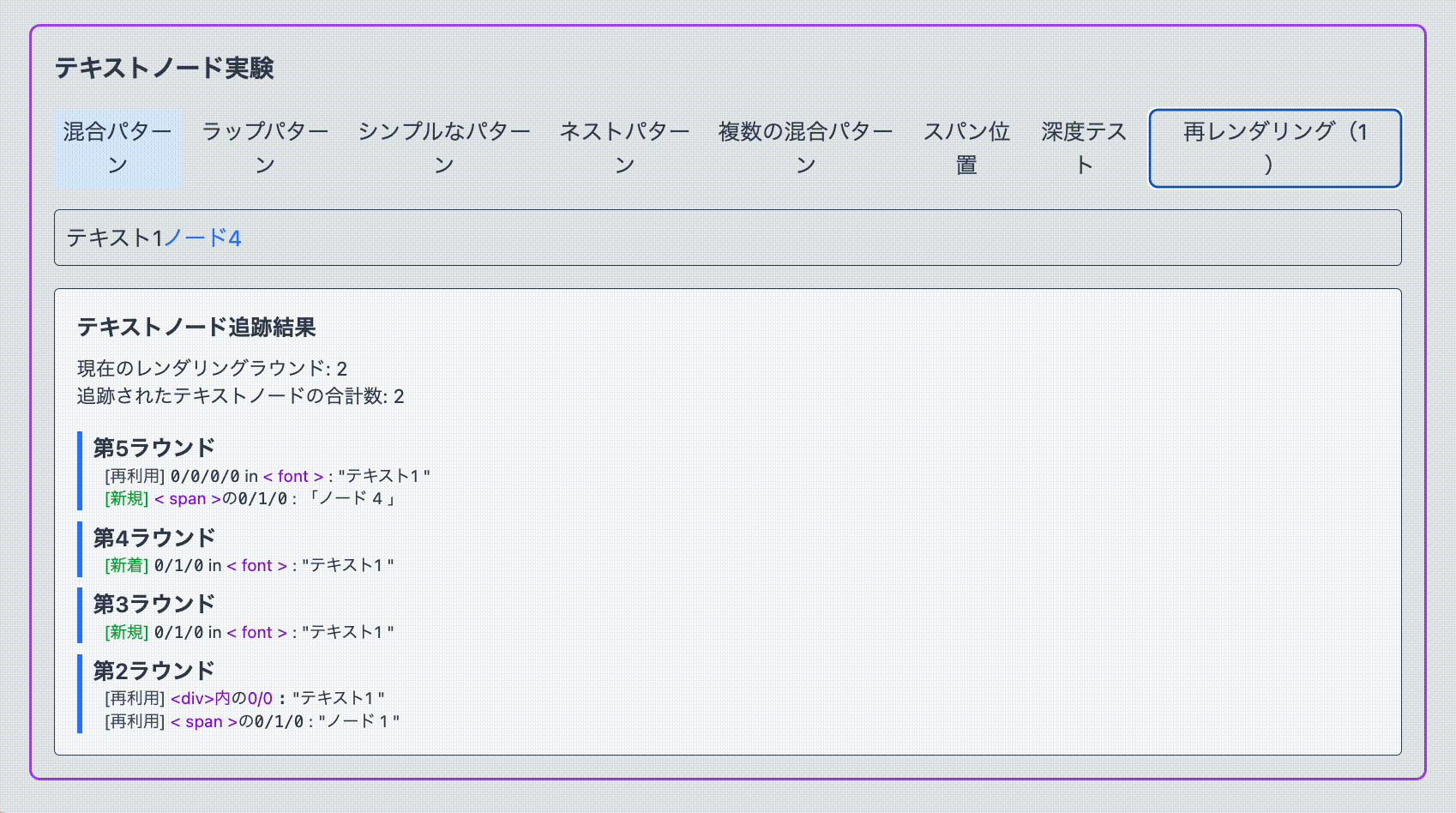
span タグで囲ったテキストノードが再レンダリングを強制する度に新規で作成されている様子がわかります。一方で text1 は再レンダリングされません。
2. Wrapped Pattern それでは複数のテキストノードを sibling が存在しない HostText になるように構築してみます。
function MixedPattern ( { renderCounter } ) { const text1 = ` Text ${ renderCounter } ` ; const text2 = ` Node ${ renderCounter } ` ; return ( < div > < span > { text1 } </ span > < span > { text2 } </ span > </ div > ) } ■ 結果
翻訳前 すべてのテキストノードがすべて再利用され、カウントアップする 翻訳後 すべてのテキストノードが新規作成されカウントアップする sibling が存在しない HostText は翻訳後も正常に動作することがわかりました。
3. Simple Pattern それではシンプルなパターンではどうでしょうか。
function SimplePattern ( { renderCounter } ) { const text = ` Text Node ${ renderCounter } ` ; return ( < div > { text } </ div > ) } ■ 結果
翻訳前 翻訳後 テキストノードが毎回新規ノードとして作成されカウントアップする 4. Nested Parttern function NestedPattern ( { renderCounter } ) { const text1 = ` Text ${ renderCounter } ` ; const text2 = ` Node ${ renderCounter } ` ; const text3 = ` Extra ${ renderCounter } ` ; return ( < div > { text1 } < div > { text2 } < span > { text3 } </ span > </ div > </ div > ) } これまでの検証から、直感で判断すると翻訳後は text3 のみカウントアップしそうですね。
■ 結果
翻訳前 すべてのテキストノードがすべて再利用され、カウントアップする 翻訳後 text3 のみ毎回新規ノードとして作成されカウントアップする 5. Multiple Mixed Pattern HostText と HostComponent を交互に配置するとどうなるでしょうか
function MultipleMixedPattern ( { renderCounter } ) { const text1 = ` Text ${ renderCounter } ` ; const text2 = ` Node ${ renderCounter } ` ; const text3 = ` Extra ${ renderCounter } ` ; const text4 = ` Final ${ renderCounter } ` ; return ( < div > { text1 } < span > { text2 } </ span > { text3 } < span > { text4 } </ span > </ div > ) } ■ 結果
翻訳前 すべてのテキストノードがすべて再利用され、カウントアップする 翻訳後 text2 と text4 のみ毎回新規ノードとして作成され、カウントアップする 6. Span Test Pattern inline 要素のみ新規ノードとして作成され正常にカウントアップする可能性があるので、念のため div タグでも試してみましょう。
function MultipleMixedPattern ( { renderCounter } ) { const text1 = ` Text ${ renderCounter } ` ; const text2 = ` Node ${ renderCounter } ` ; const text3 = ` Extra ${ renderCounter } ` ; return ( < div > < div > { text1 } </ div > < div > { text2 } </ div > < span > { text3 } </ span > </ div > ) } ■ 結果
翻訳前 すべてのテキストノードがすべて再利用され、カウントアップする 翻訳後 すべてのテキストノードが毎回新規ノードとして作成されカウントアップする どうやらタグの種類は関係無いみたいです。
7. Depth Test Pattern 最後に深層テストです。
function MultipleMixedPattern ( { renderCounter } ) { const text1 = ` L1 ${ renderCounter } ` ; const text2 = ` L2 ${ renderCounter } ` ; const text3 = ` L3 ${ renderCounter } ` ; const text4 = ` L4 ${ renderCounter } ` ; return ( < div > < div > { text1 } < div > { text2 } < span > { text3 } < span > { text4 } </ span > </ span > </ div > </ div > </ div > ) } 深さがあったとしても、単一からなるテキストノードである text4 のみ更新され一貫性があります。
これらの検証を元にどうやら sibling が存在する HostText と単一である HostText でなにか違いがある ように見えます。
React Fiber に関する仮説 React Fiber について、検証をもとに次のような挙動があるのではないかと推測できます。
HostComponent が唯一の HostText を保持している場合に限って HostComponent は HostText を考慮せず更新を行う HostComponent が複数の Fiber を含む場合は更新が失敗する 結果として、特定の構造を持つ Fiber とそれに由来する DOM に対して React が期待しない形で改変が行われると壊れるのではないかという仮説を立てます。これらの仮説を握りしめて React の実装を確認することにしました。
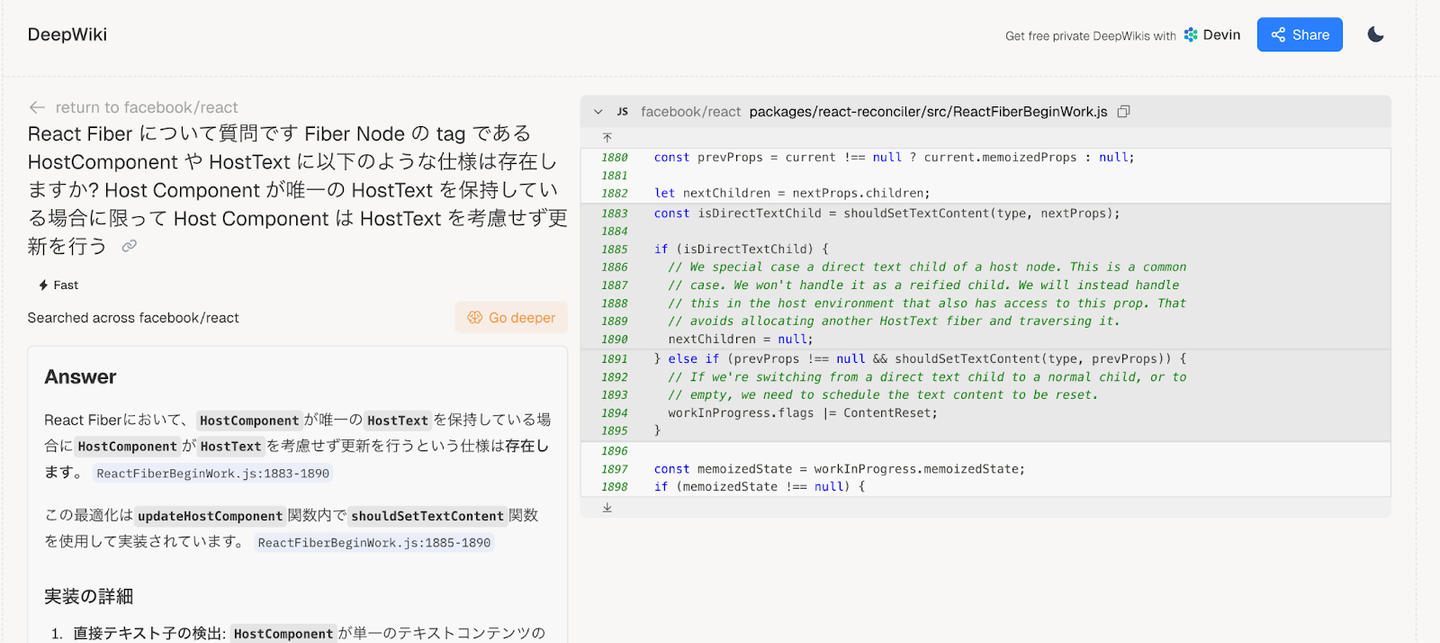
Deep wiki を利用して調査する 仮説を元に Deep wiki に以下のような質問を投げてみました。
React Fiber について質問です。 Fiber Node の tag である HostComponent や HostText に以下のような仕様は存在しますか? - Host Component が唯一の HostText を保持している場合に限って Host Component は HostText を考慮せず更新を行う 結果として yes が返ってきました。いくつかヒントをもらえたので実際にコードベース上で調査してみることにしました。
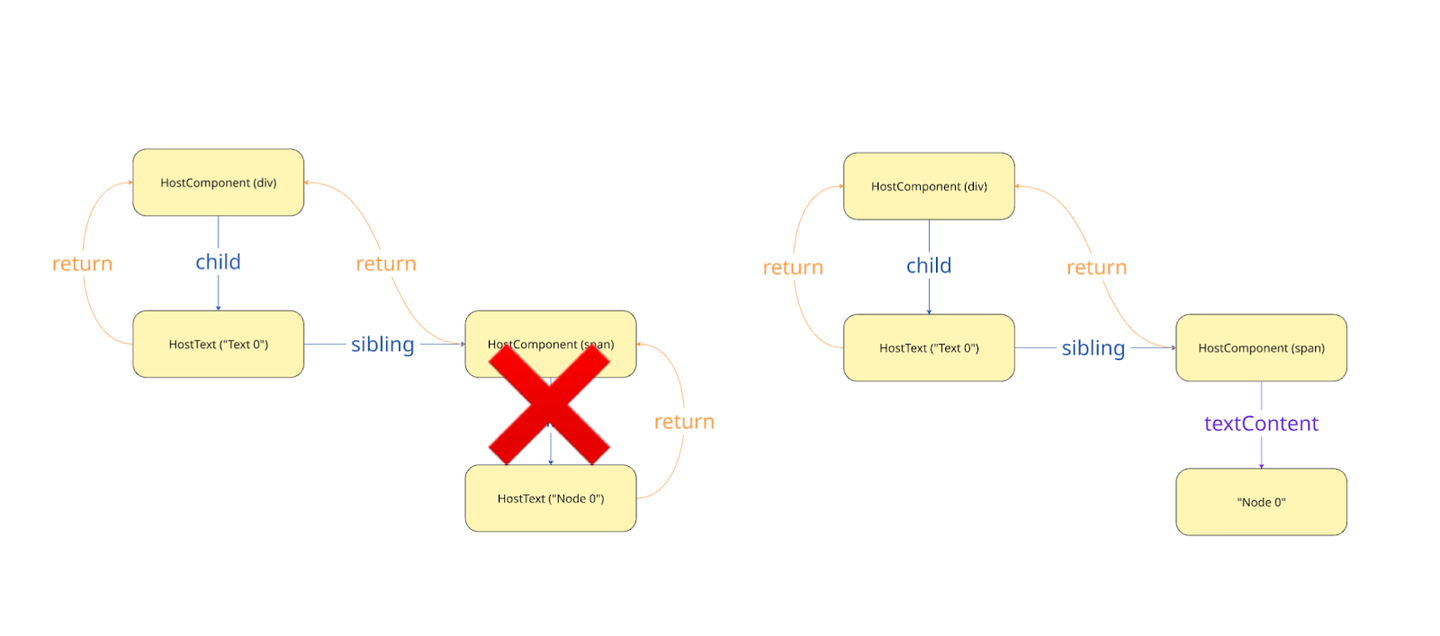
shouldSetTextContent 調査の結果、React の DOM 要素が単一のテキストの場合は HostText が作成されず、DOM 要素の textContent として直接処理されることがわかりました。テキストを HostText として管理しないことでパフォーマンス向上を目的としているようです。つまり、検証の時に紹介した図には一部誤りがあったことがわかりました。正しくは以下です。
仕組みは簡単で shouldSetTextContent で最適化の適用を決定します。
isDirectTextChild = shouldSetTextContent ( type , nextProps ) ; この関数は以下の場合に true を返します。
props.children が string, number または bigint の場合 textarea や noscript 要素の場合 dangerouslySetnnerHTML が設定されている場合 export function shouldSetTextContent ( type : string , props : Props ) : boolean { ] return ( type === 'textarea' || type === 'noscript' || typeof props . children === 'string' || typeof props . children === 'number' || typeof props . children === 'bigint' || ( typeof props . dangerouslySetInnerHTML === 'object' && props . dangerouslySetInnerHTML !== null && props . dangerouslySetInnerHTML . __html != null ) ) ; } isDirectTextChild が true の場合は以下の処理が実行されます
nextChildren = null が設定され、子の調整がスキップされる HostText Fiber が作成されず、DOM 要素の textContent として直接処理される if ( isDirectTextChild ) { nextChildren = null ; このように、HostComponent が唯一の HostText を保持している場合、TextNode は HostText として生成されず、 DOM 要素の textContent として直接処理されます。その結果 Google翻訳で挿入された FontElement は削除され、画面上に正しい文字列が表示されるのです。
余談ですが、この時 Google 翻訳は再度挿入された TextNode を翻訳しなおすのでちらつきが発生することがあります。
なぜ HostText の場合は正常に更新されないのか 対照的に、HostText として管理される場合は、特定のテキストノードインスタンスへの参照を保持し、そのノードの nodeValue を直接更新しようとします。
export function commitTextUpdate ( textInstance : TextInstance , oldText : string , newText : string , ) : void { textInstance . nodeValue = newText ; } Google 翻訳により元のテキストノードがアンマウントされていると、この操作が失敗する訳です。
まとめ textContent として処理される場合は、要素全体の内容を置き換えるため Google翻訳による内部構造の変更に関係なく、常に正しいテキストが表示されることがわかりました。これが、spanで囲んだ部分のみが正常に再レンダリングされる理由です。
これらの調査結果から、次の React Component を正しく動かすようにしてみましょう。大切なことは、Google 翻訳が FontElement を挿入するであろう部分を単一の要素からなるテキストノードにすることです。
function TrailOfBreadCrumbs ( { breadcrumbsCount } ) { return ( < p > A landmark on the way home : There are { breadcrumbsCount } trails of crumb 🍞 </ p > ) ; } この React Component では HostComponent が複数の子要素を保持していることが原因で state が HostText として処理されてしまうことが問題でした。 jsx element で表現すると以下のように複数の children を持つ構造になります。
{ $$ typeof : Symbol . for ( "react.transitional.element" ) , type : "p" , ref : null , key : null , props : { children : [ "A landmark on the way home: There are " , breadcrumbsCount , " trails of crumb 🍞" ] } } 回避策は 2 つ存在します。
テンプレートリテラルを利用し、単一のテキストノードとして扱う 必ず state を HostComponent として扱う実装にする 1 にしてしまうと、 state を更新の度に React が文章全体を書き変えるので Google 翻訳と競合し、ちらつきが発生してしまいます。なので今回は 2 の実装に修正します。
function TrailOfBreadCrumbs ( { breadcrumbsCount } ) { return ( < p > < span > A landmark on the way home : There are </ span > < span className = "text - orange - 500 font - bold” > { breadcrumbsCount } </ span > < span > trails of crumb 🍞 </ span > </ p > ) ; } 翻訳後も無事に state が更新されていますが、日本語の様子が少しおかしいです。しかし、これは次のように説明ができます。
数字を <span> タグで囲んでいるため、React はテキストノードを Fiber として管理せず、直接 <span> タグの textContent を変更しようとします。そこへ Google 翻訳が介入し、「3」という数字に日本語の助数詞を考慮して、「3つあります」といった翻訳を <span> の中に挿入してきます。つまり、DOM 上では Google 翻訳によって助数詞が表示されていますが、state の更新が行われると数字のみに置き換えられるのです。とはいえ、state 自体は正しく更新されており、React のロジックとしては問題ないため、ここは「翻訳による表示のズレ」として目を瞑ってもよいでしょう。
おまけ 実験の中でおもしろい挙動を見つけたのでおまけとして共有します。
Google 翻訳は次のように文脈に応じて既存の DOM 構造を破壊的に変更し、FontElement で React の HostComponent をまるごと囲んでいるように見えることがあります。しかし、実際には HostComponent は remove されていません。
< div > < div > A landmark on the way home: There are < span class = text-orange-500 font-bold > // HostComponent 1 </ span > trails of crumbs < span > 🍞 </ span > </ div > </ div > < div > < div > < font style = vertical-align : inherit; > < font style = vertical-align : inherit; > 帰り道の目印 </ font > </ font > < font style = vertical-align : inherit; > // ====ここから==== < font style = vertical-align : inherit; > : </ font > < font style = vertical-align : inherit; > パンくずの跡が </ font > < span class = text-orange-500 font-bold > // この span は Google 翻訳が自動生成したもの < font style = vertical-align : inherit; > 1つ </ font > </ span > </ font > // ====ここまで==== < font style = vertical-align : inherit; > < font style = vertical-align : inherit; > あります </ font > < span > < font style = vertical-align : inherit; > 🍞 </ font > </ span > </ font > < span class = text-orange-500 font-bold > // React が管理している HostComponent はここにある < font style = vertical-align : inherit; > // よって、state 更新をするとここが increment される </ font > </ span > < font style = vertical-align : inherit; > </ font > < span > // これはパンの span < font style = vertical-align : inherit; > </ font > </ span > </ div > </ div > Google 翻訳は文の意味を保つためにどうしても既存の DOM を破壊的に変更する必要がある場合において特別な処理を行うようです。具体的には、翻訳のために該当の Element の clone を生成し、それを含む全体を翻訳します。既存の Element はテキストノードだけを remove し視覚的な影響を与えない工夫が施されます。React は Google 翻訳によって生成された文章を考慮しないため、HostComponent に対して state の更新を行い、予期しない動作になることがあります。
さいごに 今回の問題を通じて、自力で問題を切り分けるためには、以下のいくつかの道具が必要になることを改めて実感しました。
言語仕様や処理系の挙動に関する理解 ライブラリやフレームワークの内部構造に対する知識など もちろん、そういった知識が不十分な場合でも、やらなければならない局面は訪れます。そのときに大切なのは「問題を明らかにしていくぞ」という執念と、仮説と検証を繰り返す科学的な態度だと強く感じました。
実際の業務では目の前の課題に対して、今ある知識と道具でなんとか対応するしかない場合がほとんどです。一方で、将来の自分のためにその道具を少しずつでも増やしておくことも重要だと感じています。今回の問題も「とりあえず解決したからそれで良し」とすることもできましたが、これをきっかけに自力で問題を切り分ける力を身につけたいと思い、行動に移せたことは今後の自分にとってとても大切な時間だったなと感じています。
参考



/assets/images/21324147/original/2e61cea1-cc5c-4546-84c1-3b1cbb1e1546?1765417792)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


