WantedlyのMatching領域でデータサイエンティストをしている角川です。9/27-10/1にRecSys2021が開催されており、こちらに参加させていただきました。
この記事ではRecSys2021で参加したセッションの中でも、初日のKeynoteのテーマにもなっており、個人的に面白い分野だと感じた Graphを活用した推薦システム についてご紹介したいと思います。
明日以降もRecSys2021の参加レポートを社内のメンバーがブログとして投稿していきますので、どうぞお楽しみください!
Keynote: Graph Neural Networks for Knowledge Representation and Recommendation 初日のキーノートセッションでGraph Neural Networkの活用と推薦システムへの応用をテーマにアムステルダム大学のMax Welling氏からご講演がありました。
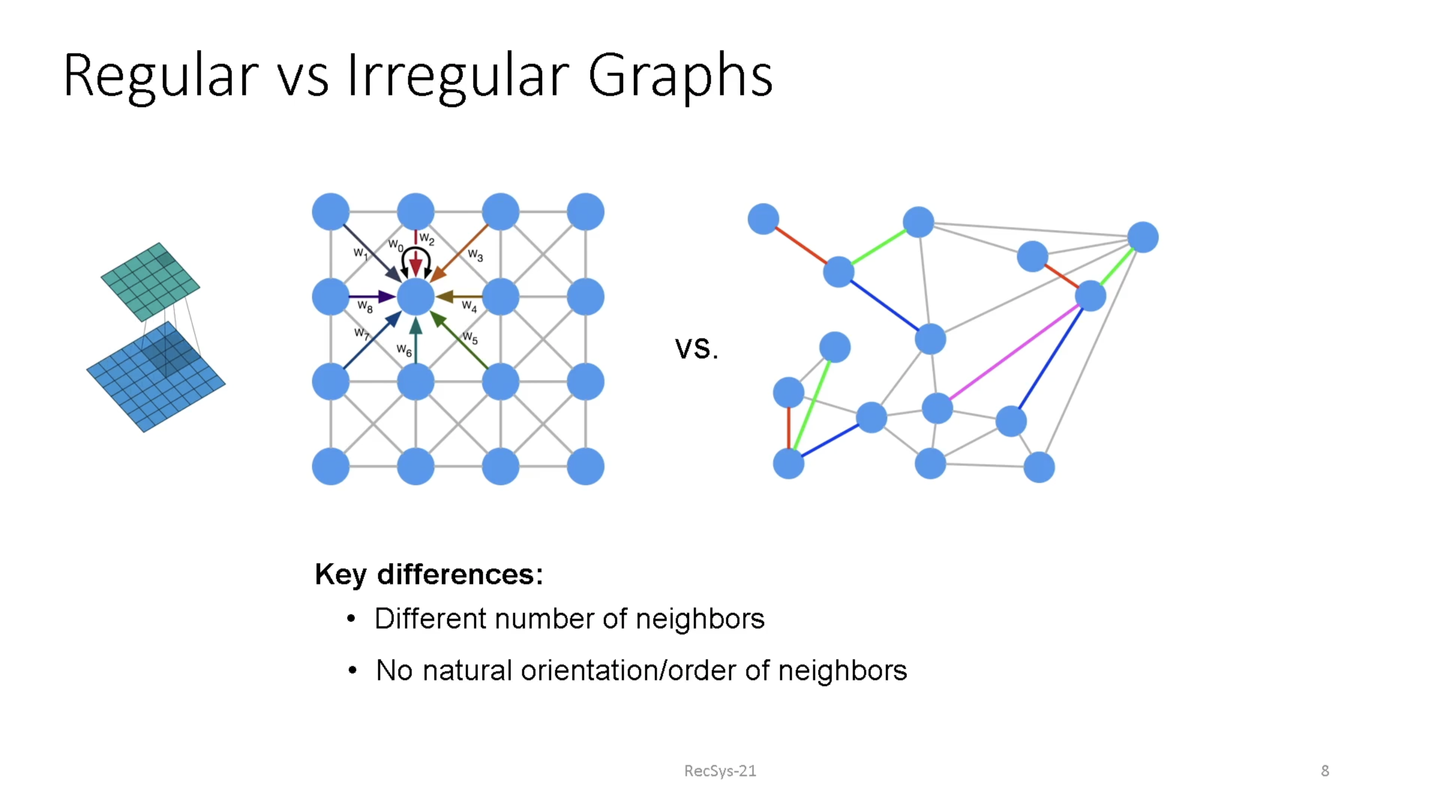
Graph Neural Network (GNN) Graph構造は、ノードとエッジを組み合わせて表現されるデータ構造です。 一般的に使用される二次元や三次元の格子状の空間は、均等に整列されたGraph構造と捉えることができます。
一般的なConvolutional Neural Network (CNN)では格子状の空間に対して畳み込み演算を適用することで分類や推論を行っています。GNNは、この CNN を整列していない Graph構造に変形したものであるとみなすことができます。GNNはGraph構造上における未知のエッジ(つながり)・ノードの予測や、Graph構造をもとにした分類などで使用されます。 GNNがCNNと異なる点としては近傍にあるノードの数が異なり、更に位置関係や順序が整列していない空間が対象になっている点だとしています。GNNではこうした整列されていない非構造な空間に対して、結合関係をもとに近傍のノードやエッジの情報を使用して畳み込み演算を実現します。
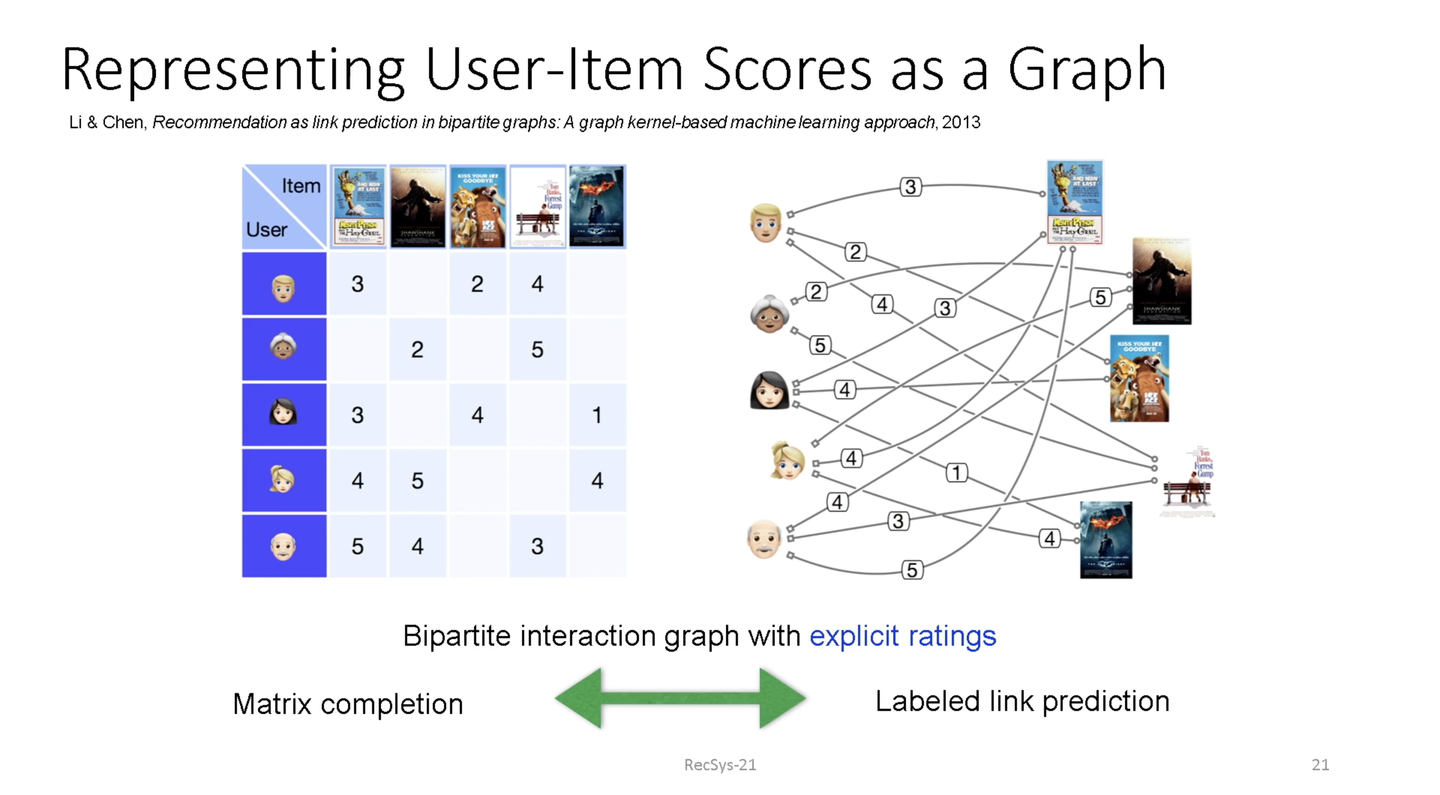
GNNと協調フィルタリング 興味深いことに、推薦システムで広く使用される協調フィルタリングで行っている二部グラフのMatrix Completionは、GNNを用いたエッジの推定(Link prediction)と、同じ役割を果たしています。
つまり、協調フィルタリングベースで行われている推薦はGNNが適用できる可能性があるということです。
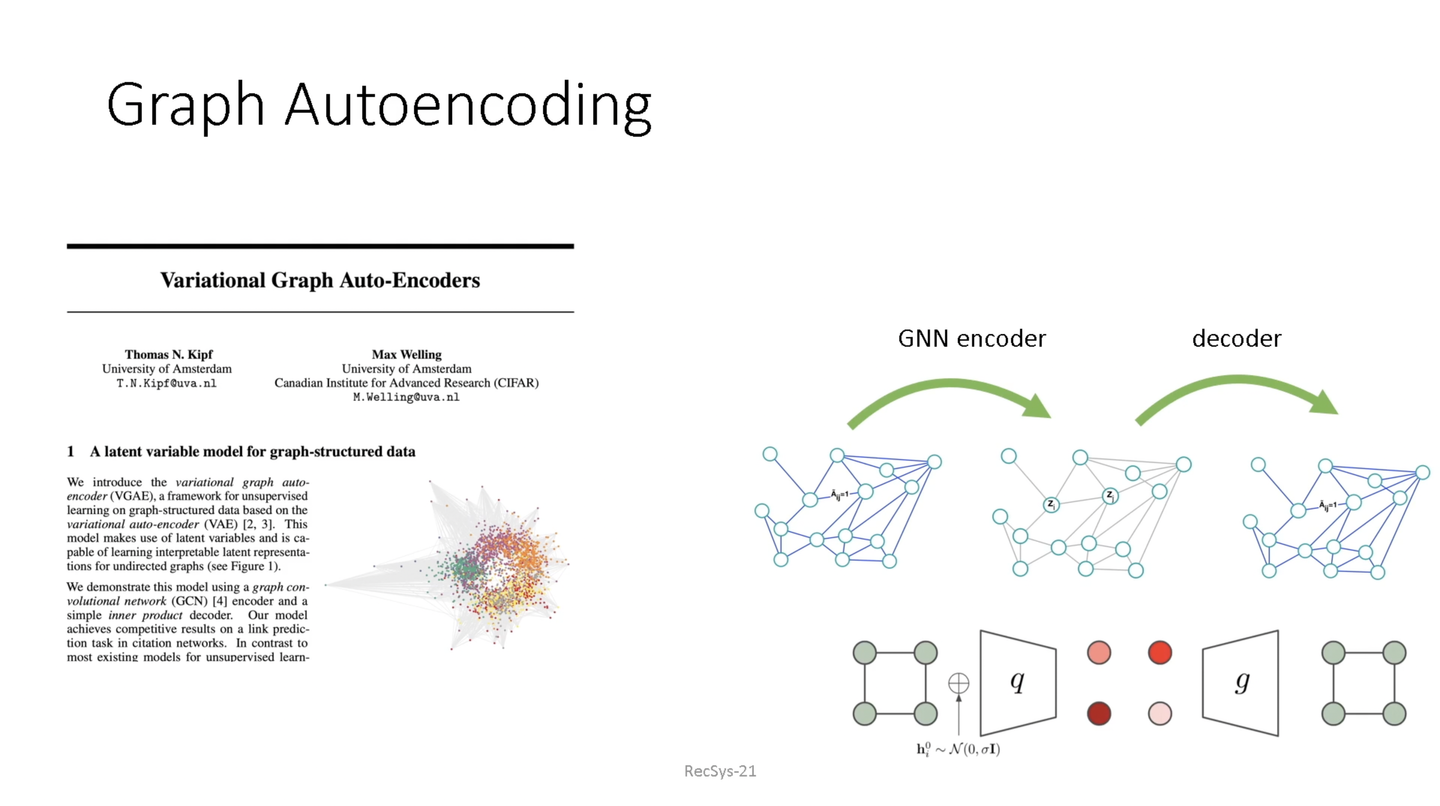
また、GNNの応用事例としてGraph Auto Encoderが紹介されていました。Graph Auto Encoderのアイデアはグラフ構造のエッジの情報をもとにノードの埋め込みを算出(Encode)し、そしてそのノードの埋め込みからエッジの結合を推定 (Decode)するというものです。
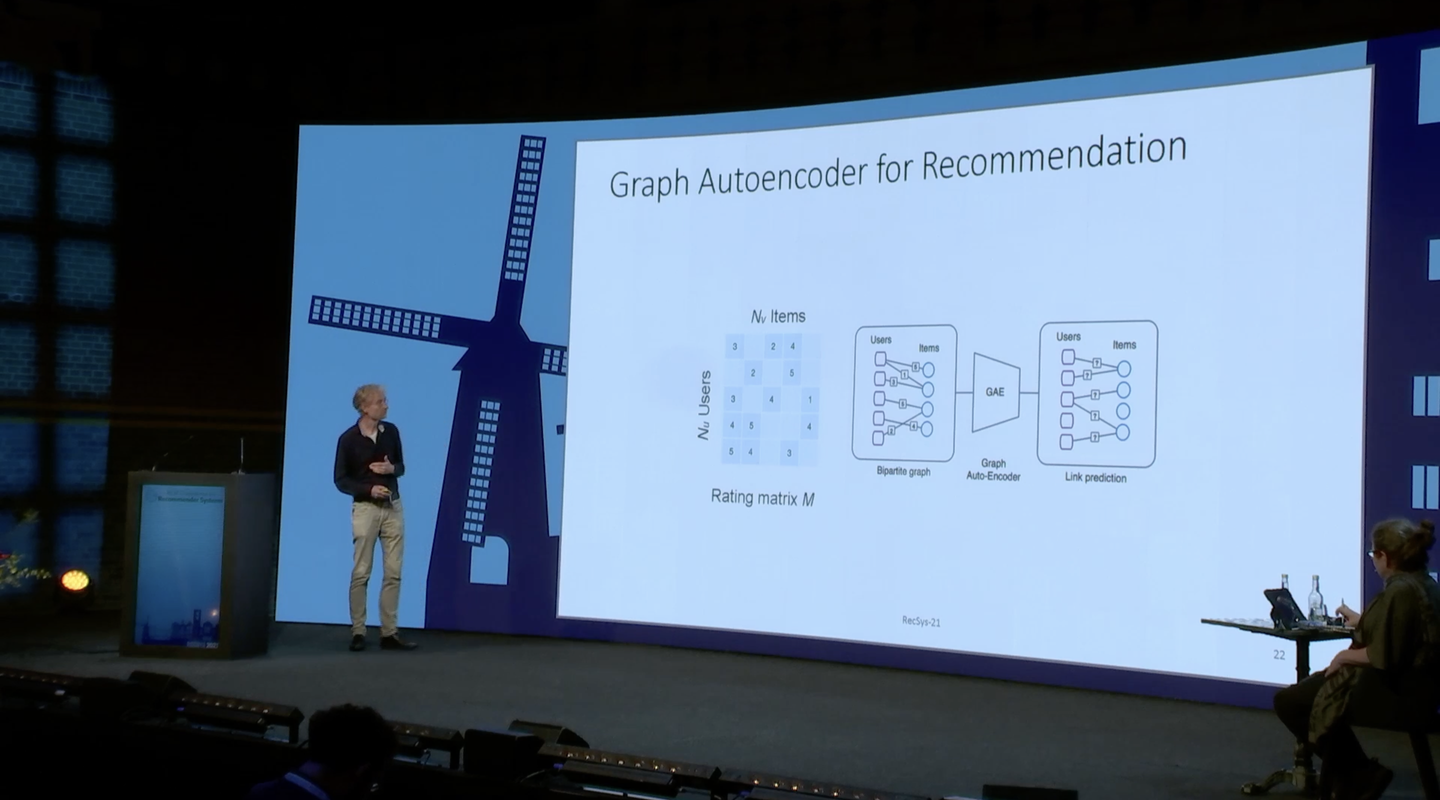
Graph Auto Encoderは、学習データのGraph構造をもとにノード間のエッジの関係を推定します。これを推薦システムに適用することでGNNを適用する事例が紹介されていました。
ユーザーとアイテムの間の繋がりの関係をGraph Auto Encoderによって学習し、まだ得られていない未知のつながりを予測することで、ユーザーにとって親和性の高い新しいアイテムの推薦が可能になります。
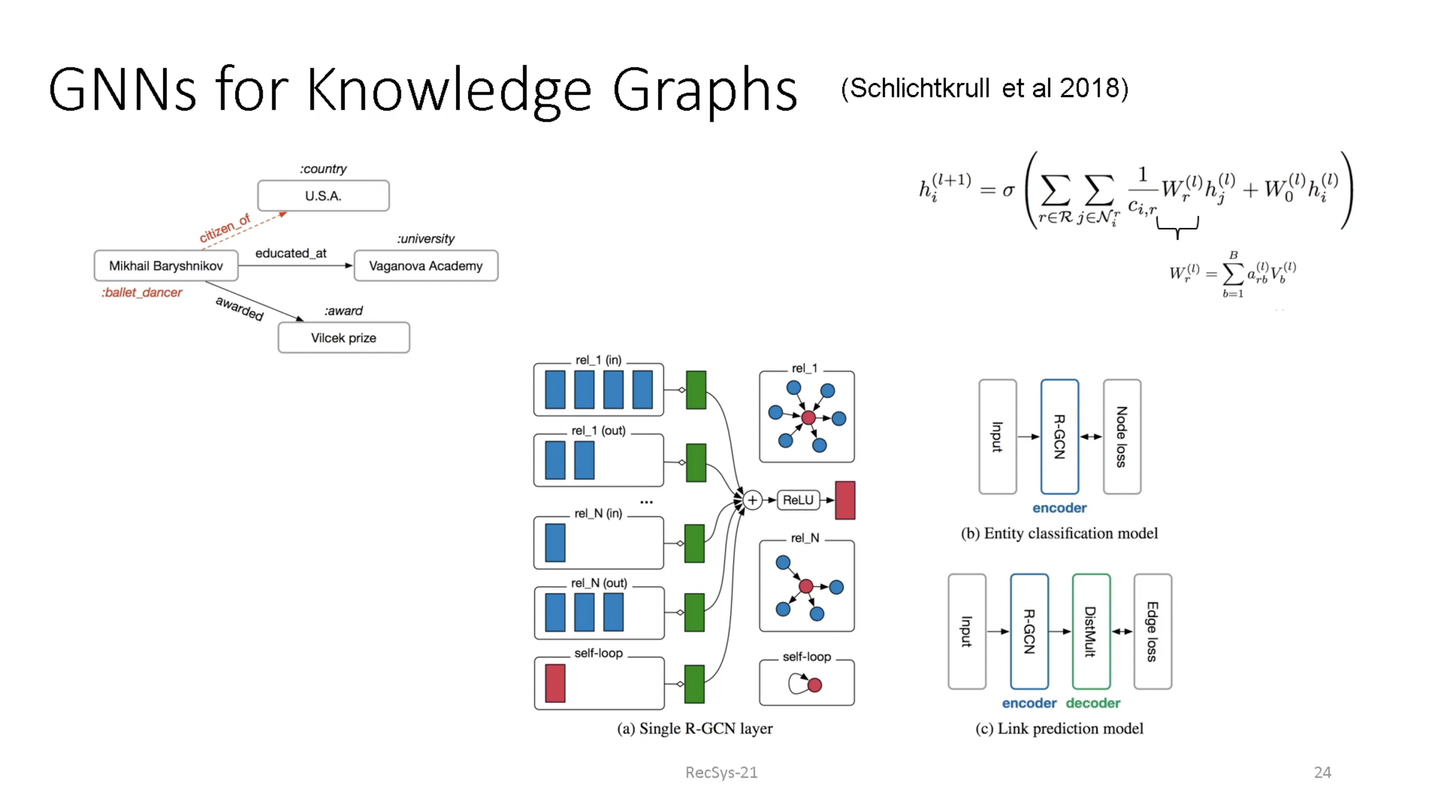
GNN for Knowledge graph また、Knowledge graphに対してもGNNを適用する紹介がありました。
Knowledge graphは、ノード間の繋がりの関係をエッジとして表現した方法と考えることができます。このとき、Knowledge graphにおけるエッジはそれぞれ異なる意味を持つことができ、Knowledge graphによってより多くの情報を表現する事ができます。そして、このKnowledge graphに対してもGNNを適用することができるとしています。
このときすべてのエッジは同じ意味を持つわけではないため、繋がりの意味ごとに畳み込みを行うことでGCNを適用することができるようになります。これにより、二部グラフだけではなく n部グラフの構造であってもKnowledge graphに対する畳込みを行うことで未知のつながりを予測することが可能になり、より複雑な推薦タスクに応用することが可能になります。
感想 社会には数多くのGraph構造のデータがあり、GNNとこれらのデータとの親和性は非常に高いと考えられます。その意味でも、GNNは知識表現や情報検索、推薦システムにおいても非常に強力なツールとなる可能性を感じました。
Reference (文中の画像は RecSys 2021 初日の Keynote Sessionの映像から引用)
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders Keynoteだけでなく、Main SessionでもGraph構造を推薦に応用した事例が紹介されていました。ここでは、Graph構造のデータを推薦システムに活用した事例について目立ったものをいくつかご紹介します。
Cold Start Similar Artists Ranking Problem Graph構造を Cold start問題へ対処するために使用した事例について紹介がありました。
音楽配信サービスでは、ユーザーの嗜好に合わせて音楽やアーティストを推薦することが求められます。 新規に登録されたアーティストをこのような推薦で取り扱う場合、アーティストに関する説明等の情報は利用できるものの、再生やいいねなどのログは記録されておらず、ユーザーの行動からアーティストの類似度を算出して推薦することは困難であるという問題があります。
Graph Auto Encoderを用いたCold start問題への対応 上記の問題に対し、ノードをアーティスト、エッジを「この楽曲が好きな人はこちらもおすすめ」といった関連性を表すグラフ空間において、新規のアーティストと既存のアーティストとの関連性を予測するLink predictionのタスクに帰着させる手法があります。このような手法によって、再生やいいねのログを使用せず、アーティストに関する説明情報のみを使用して他のアーティストとの関連性を予測することができます。
従来ではこの手法は無向グラフのために設計された手法となっていました。しかし、アーティストAの楽曲が好きなユーザーはアーティストBの楽曲も好きかもしれないが、Bの楽曲を好きなユーザーがAの楽曲を好むことはほとんどないといった、ユーザーの嗜好が非対称であることがわかっていました。そのため、今回の場合ではアーティストの関連性を有向グラフとしてモデリングしており、直接Link predictionの手法を適用できない問題があります。
Gravity-Inspired Graph Autoencoders そこで、万有引力の法則を参考に、関連性の大きさと質量情報をあわせて推測するモデルを導入します。 Graph Auto Encoderを使用して、埋め込みと合わせて質量についても同時に学習し、その質量の値を使用します。これにより、単に距離が近いだけでなく、ノードの質量という概念を導入することで関連性の強さとバランスを取り、非対称性を実現することができるそうです。
感想 こちらの論文はRecSys2021でもbest paperの候補になっており、非常に興味深い内容だと感じました。 Cold start問題は推薦システムにおいて一つの大きなトピックではありますが、その解決策の一つとしてGCNが活用された興味深い事例だと感じました。
Reference (文中の画像は RecSys 2021 Session時の映像から引用)
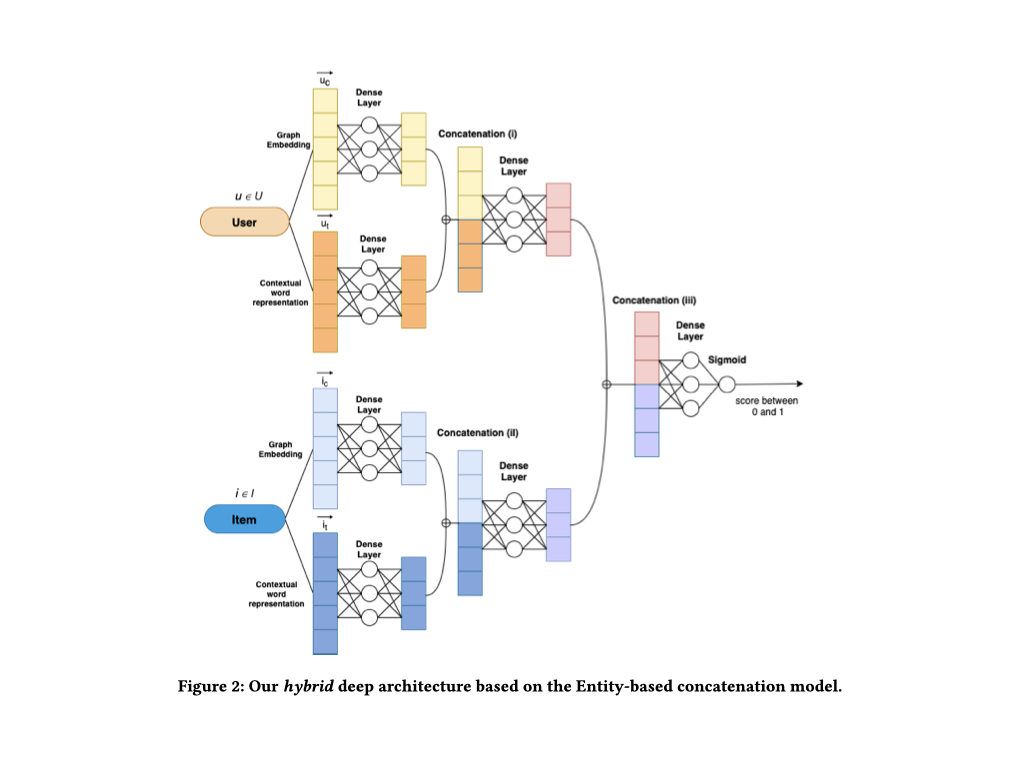
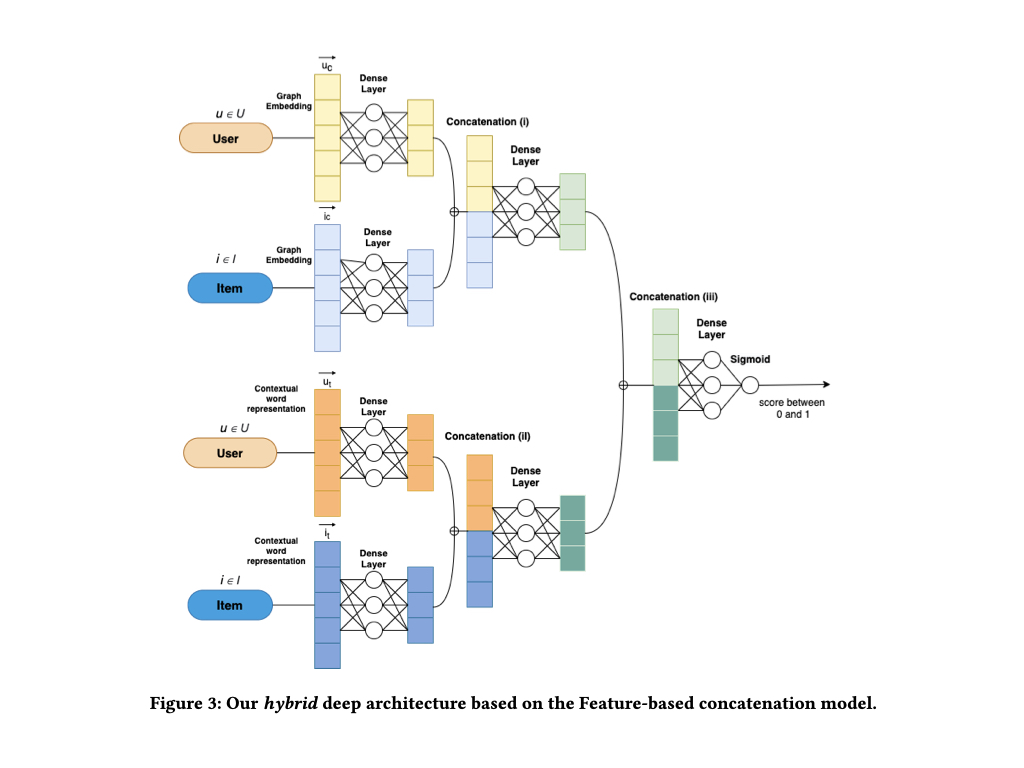
Together is Better: Hybrid Recommendations Combining Graph Embeddings and Contextualized Word Representations 繋がりとコンテンツ情報の併用 推薦システムでは、協調フィルタリングベースのアプローチとコンテンツベースのアプローチ、そしてこれらを組み合わせたハイブリッドアプローチを採用していることが多いかと思います。
ハイブリッドアプローチでは、これら2つの異なる特徴をうまく組み合わせることが必要になります。 多くの場合、繋がり情報はGraph Embedding、テキスト情報はContextual Word Embeddingとして取り扱われるため、これら双方の情報をうまく活用することが求められます。
こちらの研究ではEntity-basedとFeature-basedの2種類のパターンについてハイブリッドアプローチを実現するネットワーク構造が提案されていました。
これにより、Graph Embedding、Contextual Word Embeddingをうまく組み合わせることができ、先行研究より高い精度を達成したとのことです。
感想 推薦システムにGraph構造のデータを活用しようとした際に、つながりの情報とコンテンツの情報の両方を活用したくなるというモチベーションには納得でした。 こちら研究ではGraph EmbeddingとContextual Word Embeddingの両方をうまく結合したとのことで、こうした組み合わせ方も一つの大きなポイントになりそうだと感じました。
Reference (文中の画像は RecSys 2021 Session時の映像及び論文から引用)
Sparse Feature Factorization for Recommender Systems with Knowledge Graphs 協調フィルタリングとコンテンツベース推薦 協調フィルタリングは推薦システムの領域において優れた性能を達成することが知られていますが、データセットのサイズが大きくなるにつれて学習時間が必要になるという問題があります。コンテンツベースの推薦を行うこともできますが、コンテンツ情報に過度に影響を受けてしまう問題があります。
さらに、これらを組み合わせて使用する場合も多くありますが、その場合には協調フィルタリングよりも多くの計算コストがかかってしまいます。
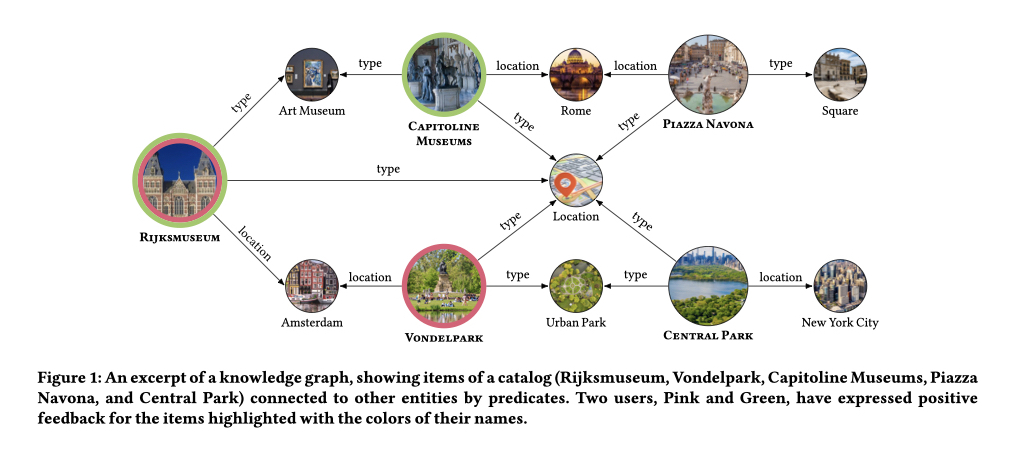
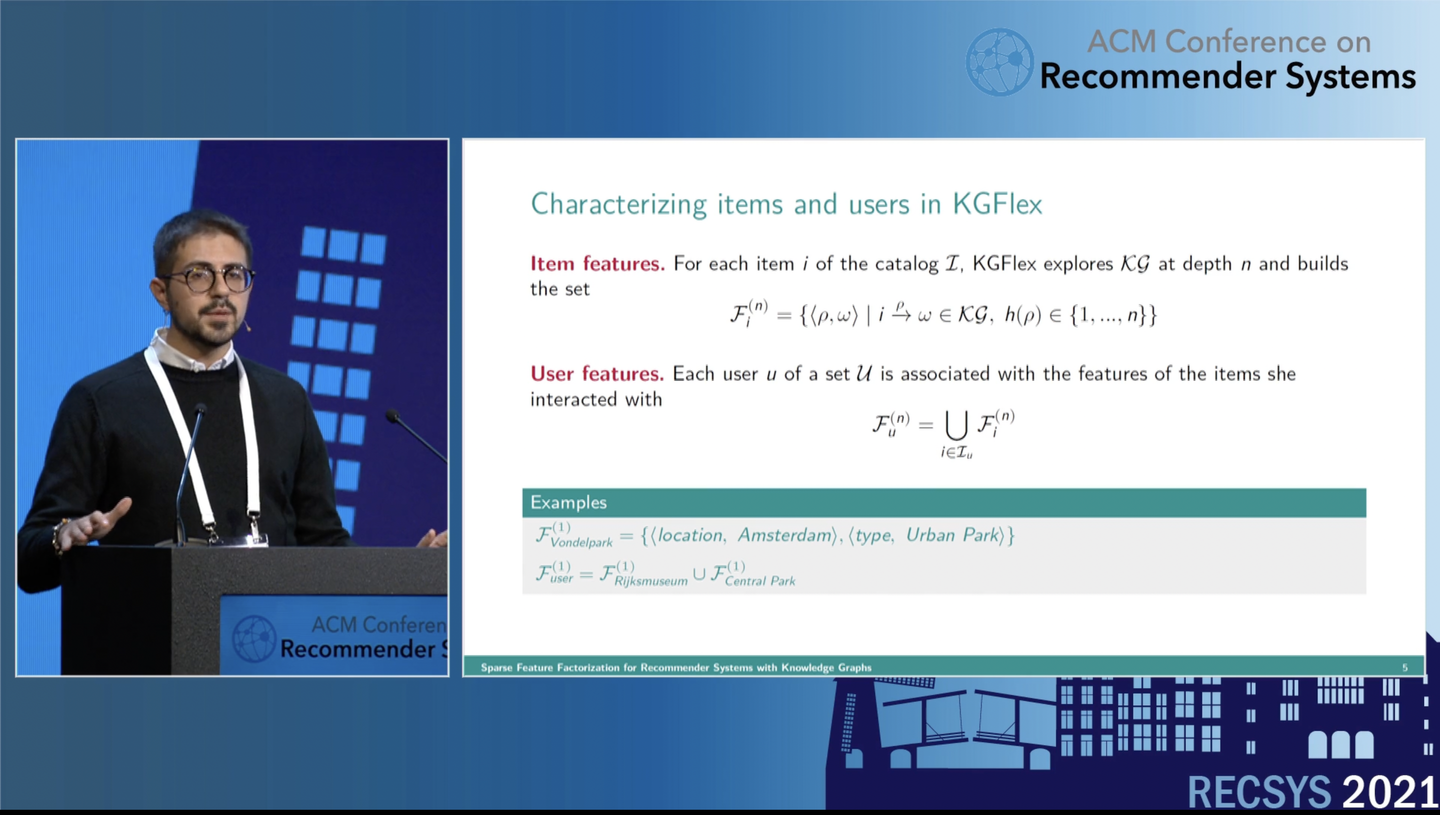
KGFlex こうした問題に対し、Knowledge graphを活用してアイテムやユーザーの特徴を低次元の埋め込みとして表現して使用することで協調フィルタリングと比べて計算量を削減するKGFlexが提案されました。 Knowledge graphにおいて、各アイテムは個別に付随する情報と連結されているため、アイテムのノードを中心に付随する情報を取得することができます。
ここで、アイテムとそれに付随する情報をもとに、低次元の埋め込みへと変換します。同様に、ユーザーについてもポジティブなフィードバックをしたアイテム情報を使用して埋め込みへ変換されます。
この変換した埋め込みを使用して、ユーザーとアイテムの親和性を予測します。 ユーザーの埋め込みとグローバルなアイテムの埋め込みとバイアスを組み合わせることで算出されます。
このとき、Knowledge graph上で繋がりがあるものだけが計算対象になり、高い推論性能を達成したとのことです。
感想 協調フィルタリングは、ユーザーやアイテム数の増加に応じて計算量が大きくなりがちですが、Knowledge graphの構造をうまく活用することで計算量を削減することができるのは非常に興味深いと感じました。
Reference (文中の画像は RecSys 2021 Session時の映像及び論文から引用)
まとめ 私個人としては今回初めて RecSys に参加しましたが、参加させていただいたどのセッションも興味深い発表ばかりでした。今回ご紹介した Graph 構造を使用した推薦も、活発に研究が進められている注目分野だと思っており、その意味でも楽しい発表ばかりで非常に勉強になりました。
Wantedlyではユーザーにとってより良い推薦を行うために日々務めています。ユーザーファーストの推薦システムを作ることに興味があるというデータサイエンティストがいらっしゃいましたら、下の募集から「話を聞きに行きたい」ボタンを押してみてください!
次回のRecSys2021参加レポートはWantedly Visitデータサイエンティストの合田さんのブログです。どうぞお楽しみに!







/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

