ウォンテッドリーでデータサイエンティストをしています林 ( @python_walker ) です。先日チェコのプラハで開催された RecSys 2025 において、我々ウォンテッドリーと半熟仮想株式会社の齋藤優太 ( @usait0 )さんとの共同研究の成果が採択され、私の方から 口頭発表 をしてきました。
こちらの論文は大変ありがたいことに、今年の Best Paper Candidates の 1 本に選出されました。これは RecSys 2025に投稿された計261本のFull Paperのうち、新規性やインパクトの最も大きい上位5本の論文に選ばれたことを意味します。
このストーリーでは、この論文の内容や執筆にいたる背景、採択後の反響などをご紹介させていただければと思います。なお、RecSys の参加ブログについては下で別に執筆しておりますので、ご興味のある方はご覧ください。
はじめに 我々が日常的に用いるYoutubeやAmazonなどの様々なサービスは膨大な量のコンテンツを保有していることが多く、ユーザーがその中から自身の嗜好にあうコンテンツを探し出すのは容易なことではありません。推薦システムは 多数の候補の中から価値のあるものを選び出し、意思決定を支援するシステム です。推薦システムによって、ユーザーは自分が求めているものを簡単に見つけることができ、サービスをもっと利用したいと思うようになります。このように、推薦システムはユーザーの体験を設計する上で非常に重要な位置にあり、ビジネス的にも大きなインパクトを持つシステムであると言えます。
今回RecSysに採択された我々の論文は、特にマッチングサービスにおける推薦システムのオフライン評価に関する新手法を提案したものです。我々の提案した手法により、 マッチングプラットフォームにおいて、過去のログデータのみを用いた性能評価の正確性が大きく向上することになります 。
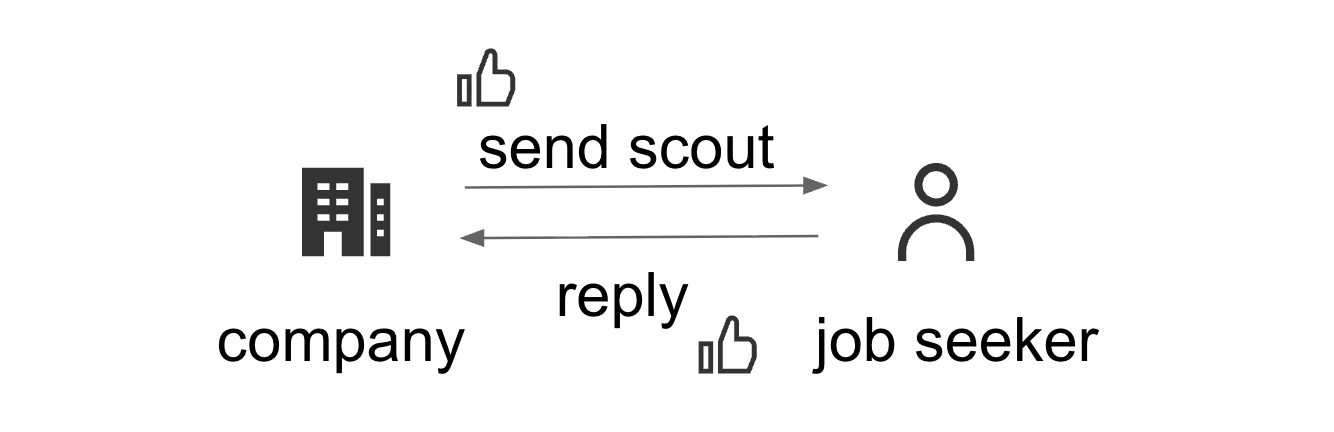
研究の背景 マッチングサービスにおける推薦の特徴 ウォンテッドリーが提供する会社訪問アプリ Wantedly Visit は、ヒトとシゴトの最適なマッチングを生み出すことを目指すサービス、いわゆる マッチングサービス です。マッチングサービスとしては、我々のようなジョブマッチングサービスの他に、デーティングサービス、フリマサービス、不動産サービスなど多種多様なものがあります。
マッチングサービスにおける推薦では、一般的なECサービスにおける「あなたにおすすめの商品」のような形の推薦とは異なる特殊な性質があります。それは 推薦の成功に相互の嗜好の合致が必要 であることです。ジョブマッチングサービスを例にとって説明します。企業の採用担当者が求職者を探してスカウトを送れるサービスを考えましょう。推薦システムは企業が興味を示しそうな求職者を推薦しますが、企業がその候補者にスカウトを送信した段階では、推薦が成功したとは必ずしも言えません。なぜなら、スカウトを受け取った求職者が企業に対して返信をしなければマッチングが成立したとは言えず、面接や採用などその後の行動につながらないからです。つまり推薦の成功には、企業の嗜好を正しく読み取れるだけでなく、求職者の企業に対する嗜好も同時に正しく読み取れていることが必要になります。
推薦アルゴリズムの性能評価 上に述べたようなマッチングサービスの特殊性から、これまで様々な「マッチングサービス用の」推薦アルゴリズムが研究されてきました。このような研究の活発化により選択可能なアルゴリズムの候補が増加する一方で、個々の現場において各アルゴリズムの性能を適切に評価することの重要性が高まっていました。様々なアルゴリズムの中から最適なものを選択する際、A/B テストが利用される場面が多くあります。しかし、A/B テストは結果を得るまでに時間がかかる他、性能の低いアルゴリズムを比較対象としてしまうと実験期間においてユーザー体験やビジネス指標を毀損してしまう可能性がある、といったリスクを抱えています。
そこで、A/Bテストを行うことなく、あるいはA/Bテストを行う前段階の性能評価のための方法論として、 オフ方策評価 (OPE) と呼ばれる研究分野に関心が集まってます。オフ方策評価は、既にサービス上で利用されている推薦アルゴリズム (オフ方策評価においては、“方策”と呼ばれる) のもとで収集されたログデータのみを利用して、未だ実装したことのない新たな方策の性能をできる限り正確に評価するための手法を提供します。この分野においては、方策の性能を正確に推定するための推定量がこれまでに多数提案されてきましたが、マッチングサービスにフォーカスしたものは存在しませんでした。
マッチングサービスにおいて収集されるデータは、他のサービス領域とは異なり、データの中に 推薦の成功を表すラベルが極端に少ない(正解ラベルがスパース) という特徴があります。これは、すでに述べたように、マッチングサービスにおける推薦の成功に相互の嗜好が同時に合致することが要求されるためです。既存の OPE の手法では、このようなスパースなデータに基づいた信頼性の高い評価をおこなうことが難しく、マッチングサービスにおける OPE に関する重要かつ未解決の研究課題となっていました。
研究の目的 我々の研究の目的は、マッチングサービスの推薦アルゴリズムに対して、上記の課題を解決することで、より正確なオフライン評価を可能にすることです。これにより、マッチングプラットフォームにおいて従来と比べより高速かつ正確にアルゴリズムの検証をできるようになると期待できます。
また、ログデータのみを用いてさらに性能の高い推薦モデルを学習する オフ方策学習 (OPL) と呼ばれる問題に対して有用な推定量を開発することも、我々の研究目的の一つとなります。
基本的な推定量 これまで提案されてきた推定器は数多くあります。ここでは、論文中でもベースラインとして用いている基本的な3つの推定器について簡単に説明します。以降の説明では、ジョブマッチングサービスを仮定して話を進め、推薦アルゴリズムの性能として「発生するマッチ数の期待値」を考えることにします。
ここで、 q_s(c, j) は企業( c )が求職者( j )にスカウトメッセージを送信する確率、 q_r(c, j) は求職者がスカウトメッセージに対して返信をする確率を表します。また、方策は各企業に対して1人の求職者を推薦するというような設定で話を進めます。
Direct Method (DM) DM ではシンプルに、企業と求職者がマッチングする確率 q_m(c,j) を機械学習モデルによって学習し、その予測値を使って推薦アルゴリズムの性能を推定します。
この手法は推定値の変動 (バリアンス) は小さいものの、マッチング確率の予測モデルの精度によっては推薦アルゴリズムと推定量の間に大きなずれ (バイアス) が発生します。
Inverse Propensity Scoring (IPS) IPS では、既存の方策 (π0) による推薦の傾向と新方策 (π) による推薦の傾向の違いを補正することで新方策の性能を推定すべく、両者の比である重要度重みを用います。
ここで m _ c はマッチングの成立有無を表す2値ラベルです。
この手法はバイアスの無い推定(不偏推定)を実現できる利点がある一方で、新旧方策の推薦傾向に大きな乖離が存在したり、ラベルがスパースな場合など、重要度重みの分母が小さくなる状況ではバリアンスが増大し、推定が非常に不安定になる欠点があります。マッチングサービスはまさにこのケースに該当し、信頼性の高い性能推定が困難になります。
Doubly Robust (DR) DR は DM と IPS を組み合わせた手法で、両者をバランス良く組み合わせることによって IPS の不偏推定を維持しつつもバリアンスを低減することができます。
しかし、DRも依然として重要度重みを利用しているために、マッチングサービスに代表される重要度重みが増大する場面では、バリアンスが発散してしまう可能性を持っています。
提案手法 既存手法の課題を解決するために、我々はマッチングサービスに特有の構造を活用することで、新たな推定量を設計・提案しました。先に述べたように、マッチングの成立のためには企業から求職者への嗜好と逆向きの嗜好が同時に存在している必要があります。我々は、この2方向の嗜好を明示的に分離して活用することによって、より正確な推定量を設計できるのではないかと考えました。つまり、
マッチング成立 = (スカウト送信が発生) x (スカウトに対して返信が発生)
のように分解してみてはどうかということです。前者は比較的ラベルが密であるのに対して、後者のラベルは非常にスパースです。そのため、前者の スカウト送信に関しては重要度重みを利用 することで、欠点が顕著になることなく不偏推定が可能だと期待できます。一方で後者の 返信に対して重要度重みを活用してしまうと推定が不安定になるため、 DM のように返信確率をモデリング することで、バリアンスを抑えた推定が可能だと期待できます。以上の推論を具体化すると、以下の DiPS ( Di rect and P ropensity S core) 推定量を新たな推定量として構築できます。
ここで s_c はスカウト送信のラベル、 q_r は返信が発生する確率であり、ハットが付いているのはこれがモデルによる予測値であることを示しています。理論的な解析により、この推定量が IPS と比較して低いバリアンスを実現していることを理論的に証明できます (詳細は論文中Theorem 4.3を参照下さい)。
さらにDRを参考に、DiPS に対して DM を組み込む拡張を行うことにより、更にバリアンスを低下させることができます。これが2つ目の提案手法である DPR ( D irect P ropensity and doubly R obust) です。
実験結果 提案した2つの推定量の精度検証のために、合成データを用いた実験と、Wantedly Visit 上で行われた過去のオンラインテストのログデータを利用した実験を行いました。
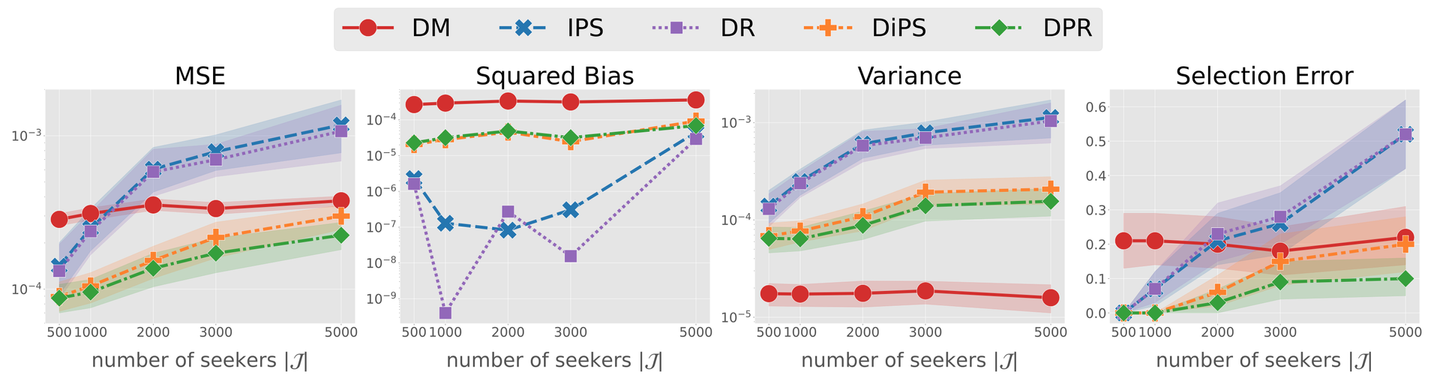
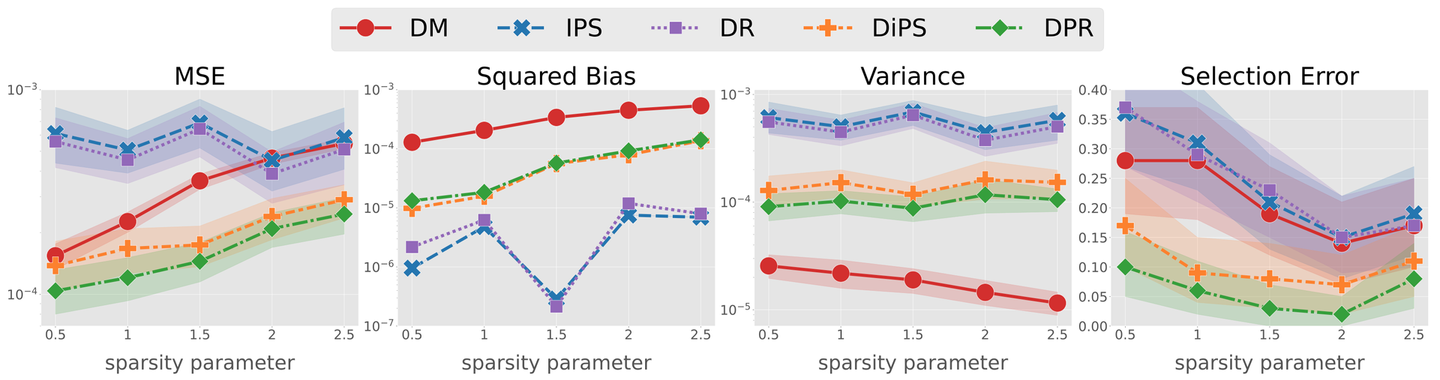
合成データを利用した実験結果 以下のグラフは、OPEの研究において典型的な精度指標であるMSE (平均二乗誤差) とそれを二乗バイアスとバリアンスに分解したもの、そして Selection Error と呼ばれる、意思決定時により良い方策を見落とす確率を示しています。横軸はデータ中の求職者の数になっており、これが増えるほど方策の行動空間(= 取りうる選択肢の数)が増大するため、重要度重みが不安定になるなど、OPEが困難な状況になります。
結果を見ると、ベースラインである IPS と DR は求職者数が増加するにつれバリアンスが急激に増大してしまい、 MSE が悪化する様子が見てとれます。このバリアンスの増大は、まさに上述の重要度重みの不安定性に起因するものです。一方で、我々が提案したDiPS と DPRはともに バリアンスの増加をかなり緩やかに抑えることができています 。DiPS と DPR も重要度重みを用いてはいるものの、よりスパースな返信確率の部分を DM 方式で扱っていることが、バリアンスの大きな減少に寄与しています。
一方で、提案推定量は IPS や DR と比較してより大きなバイアスを生じていることがわかります。これは 提案推定量が返信確率の推定に用いているDM の項に起因するものです。しかし、提案推定量に発生するバイアスは DM と比較してかなり小さく抑えられており、バリアンスの大幅な減少と総合すると、二乗バイアスとバリアンスの和である MSE はすべてのベースラインと比べて大きく改善 しています。
Selection Error の結果を見ても、提案手法はベースラインと比較して低く抑えられています。ここから、我々の手法は方策選択の意味でも既存の推定量よりも精度が優れており、 実務上において複数の方策を比較検討する場面において高い有用性を発揮する ことが期待されます。
次に、以下のグラフはデータ中の正解ラベルのスパーシティー (スパースさの度合い)を変化させたときの比較です。横軸の数値が大きくなるほどログデータ中のマッチラベルがスパースになります。
結果を見ると、正解ラベルがスパースでその観測数が少なくなるほど、DM のバイアスが増大していることがわかります。一方で、提案手法は予測モデルに基づくラベル推定のみに依存した設計にはなっていないために、 DM と比較するとバイアスを低く抑えることができています。バリアンスについては先程と同様、 IPS や DR と比較して大幅に減少させることができており、結果として MSE を低く抑えることができています。
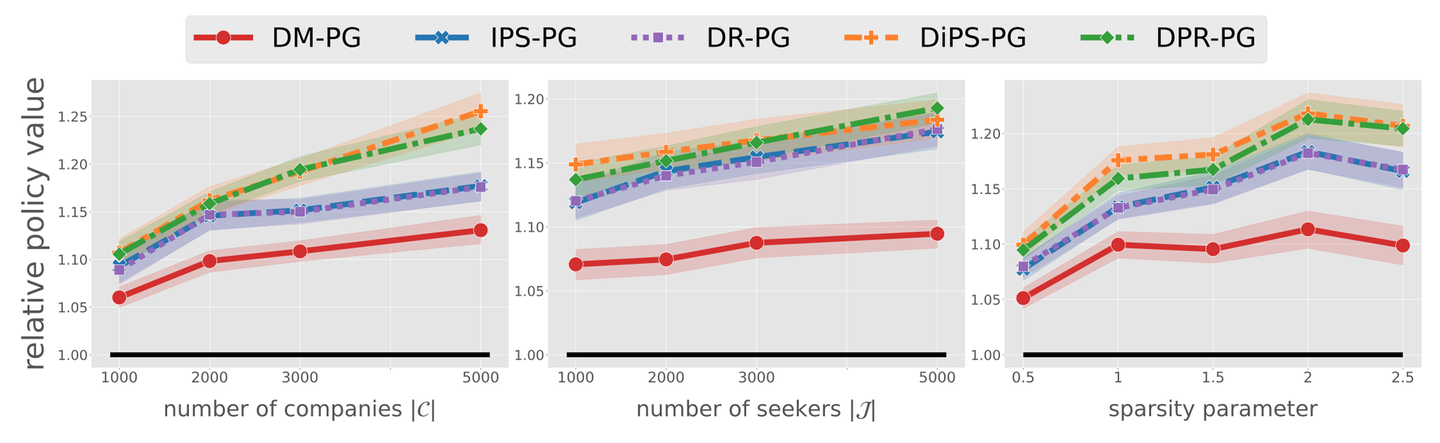
最後に、以下のグラフは推定量を使ってオフ方策学習を実行したときのテストデータにおける獲得マッチ数を比較した結果です。ここでは、各推定量によって推定した勾配をもとにマッチ数を最大化する目的でモデルパラメーターを更新しており、横軸が学習に用いたログデータ数、縦軸がモデルの性能を示しています。
縦軸が1.0のところに示されている太い黒線は、既存方策(π0)の性能を表す基準線です。こちらの結果を見ると、学習データ数によらず、ベースラインの推定量による推定結果を利用して推薦モデルを学習した場合(DM-PGやIPS-PG, DR-PG)よりも、提案手法を活用した推薦モデル学習(DiPS-PG, DPR-PG)がより高い性能を達成していることがわかります。
Wantedly Visit の実データを利用した実験結果 合成データによる実験のみならず、我々はサービス上で発生した実際のデータを用いることによって、提案手法の実用性をより強固に示すべく、追加の実験を行いました。具体的には、過去に Wantedly Visit のスカウト推薦に関して実施されたオンラインテストで収集されたデータを用いた検証を行いました。
Wantedly Visit における求職者の推薦は、これまで想定していた1企業に対して1求職者を推薦する簡易な形ではなく、各企業に対して複数の求職者をランキング形式で推薦するより実践的な実装を採用しています。我々の実験においてはこの現実と定式化のギャップを埋めるべく、(企業ID, 日付, 注目順位) の組を "企業" とみなし、(求職者ID, 日付) の組を "求職者" とみなした実装を行いました。それぞれの定義に日付を含めて区別しているのは、Wantedly Visit での方策がデイリーで再学習されているため、同じ企業IDでも日付によって方策による推薦傾向が変化するためです。
各種方策による推薦傾向については、オンラインテストのログデータから推定しています。ここで、例えば c = (企業1, "2025-10-01", 順位2)、 j = (求職者1, "2025-10-01") の場合には π( j | c ) は、説明が少々冗長ですが、 2025-10-01 の状態の企業1が、ランキングの上から2番目において 2025-10-01の状態の求職者1を見る確率となるようにします。方策の推定には LightGBM を利用しました。
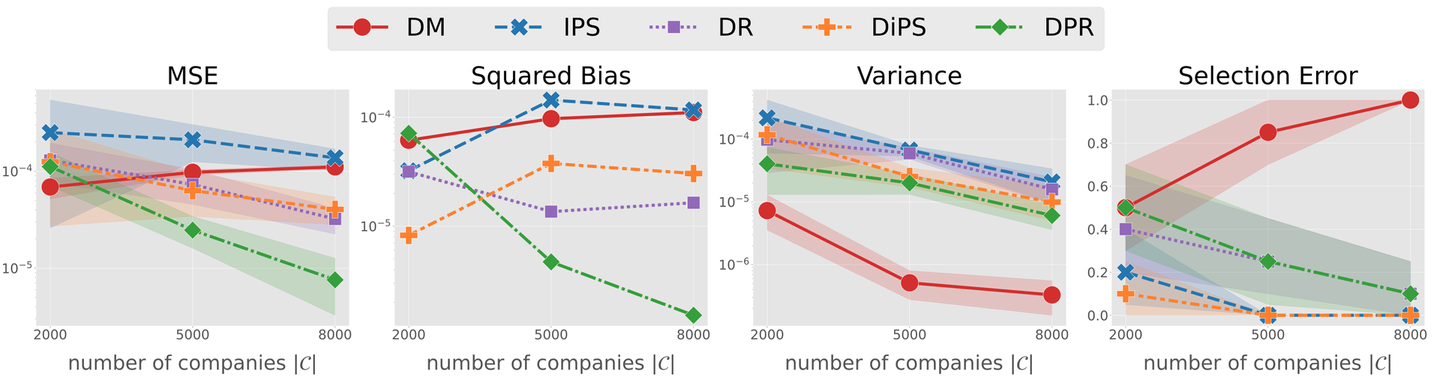
オンラインテストデータから一定数の "企業" を抽出して評価するということを、企業数を変えながら行った結果を以下に示します。
合成データを利用した実験と比較すると、同じ傾向を示している部分と、異なる傾向を示している部分が存在していることがわかります。すなわちバリアンスに関しては、提案手法が IPS や DR といった重要度重みに依存しているベースラインと比べて小さく抑えられています。これは合成データの結果と一貫しています。一方でバイアスについては、DiPS は IPS に対して、DPR は DR と比較してより小さな値を取っています。これは合成データでは見られなかった現象です。この現象は、方策πをモデルによって推定していることが原因であると考えられます。論文中では、πの推定のずれの方向と返信率予測モデルのずれの方向の間に正の相関があるときに、DiPS のバイアスが IPS に対して減少する可能性について理論的に示していますので、興味のある方は論文中Theorem 4.2など参照下さい。
最後に実データ実験におけるSelection Error の比較を見ると、IPS と DiPS において DR や DPR よりも低い Selection Error が出ています。興味深いことに、これは MSE の場合と大小関係が逆転しています。
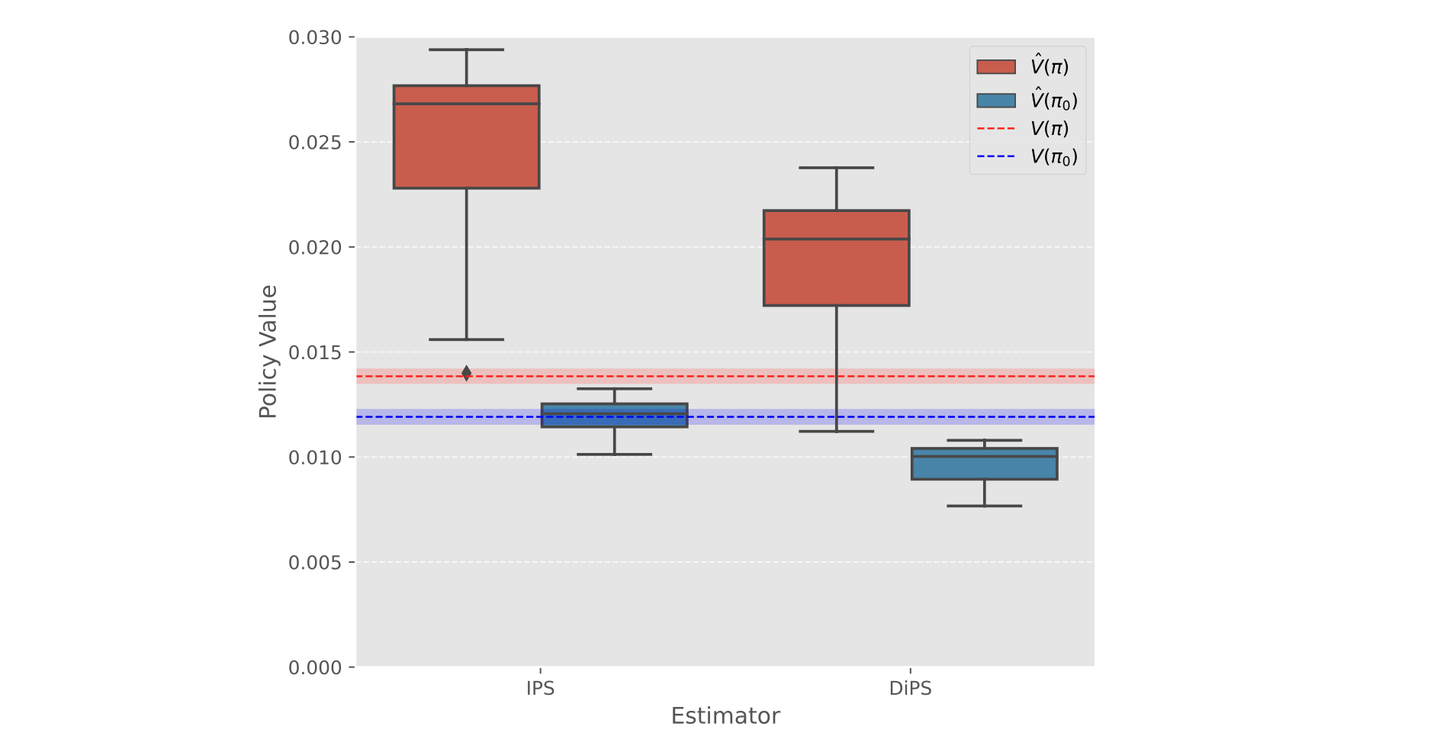
IPS と DiPS について、既存方策 π0 と新方策 π に対する推定値の分布をプロットすると上のようになります。赤で示されているπに対する推定値が、実際の値 (図の赤の点線) よりも大きな位置にあり、新方策の性能を過大評価していることがわかります。これにより MSEの大小との Selection Error の大小に一見矛盾が生じるという興味深い現象に説明がつきます。DiPS でも同様の傾向はありますが、バイアスとバリアンスが減少したことにより、IPS よりは過大評価が抑えられていることが見てとれます。
まとめ 本研究において我々は、マッチングサービス上での信頼性の高いオフライン評価を実現するために、マッチング特有の構造を活用するオフ方策評価・学習の手法を提案しました。これらの手法は従来手法に対してバリアンスを大きく減少することで、より精度の高いアルゴリズムの性能評価を可能にすることを、理論・実験の両面から示しました。さらには、これらの手法は複数の方策の中からより求める性能の高いものを選択する場面でも有用性が高く、実用的な観点からも優れた手法であると言えます。
しかし、実データ実験の章で簡単に述べたように、我々の定式化や手法はランキング形式でのより現実的な推薦形式までは考慮できていません。マッチングサービスにおけるランキング推薦の性能評価にも提案手法を拡張することで、我々のプロダクトへさらにフィットさせることが今後の課題の1つと言えます。
論文執筆の背景と採択後の反響 最後に、今回の論文執筆の背景と採択後にどのような反響があったかについて軽く触れさせていただこうと思います。ウォンテッドリーでは、データサイエンティストは主にプロダクト改善に従事しており、研究開発には時間を割いてきませんでした。しかし、我々が目指す理想のマッチングを実現するためには、 自らが最先端の機械学習技術を研究開発してプロダクトに取り入れていくということが必要不可欠 であると考え、「技術によって出せる価値を最大化する」ということを目標として掲げて昨年から研究開発に取り組んでいます。
昨年の研究成果は残念ながら RecSys には採択とはなりませんでしたが、今年念願の採択となり、非常に嬉しく思っています。採択が決まったときには社内でも反響が大きく、当社からプレスリリースも発表しました。
また、社外の方からも論文採択や Best Paper Candidates の1本に選出されたときにはお祝いの言葉を多数いただき、改めて RecSys の影響力の大きさも実感しました。今回の成果は非常に大きなものではありますが、「技術によって出せる価値を最大化する」ためにはまだまだ出来ることがたくさんありますので、これからも精進していきたいと思っています。


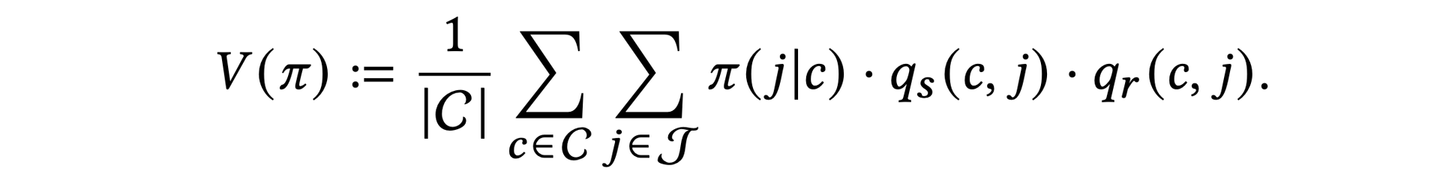
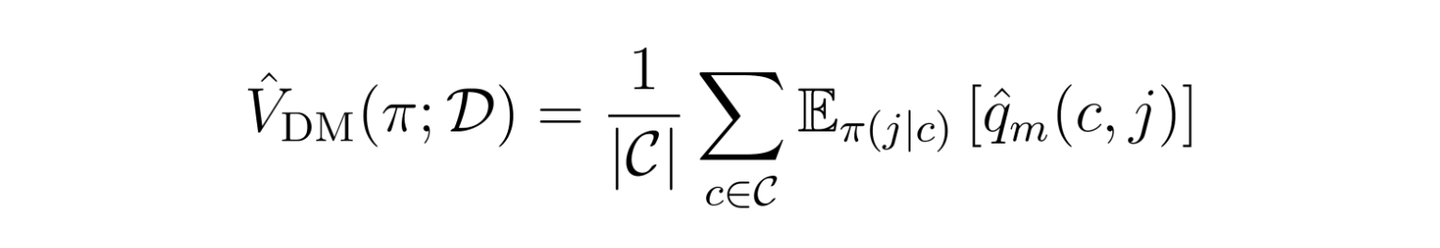
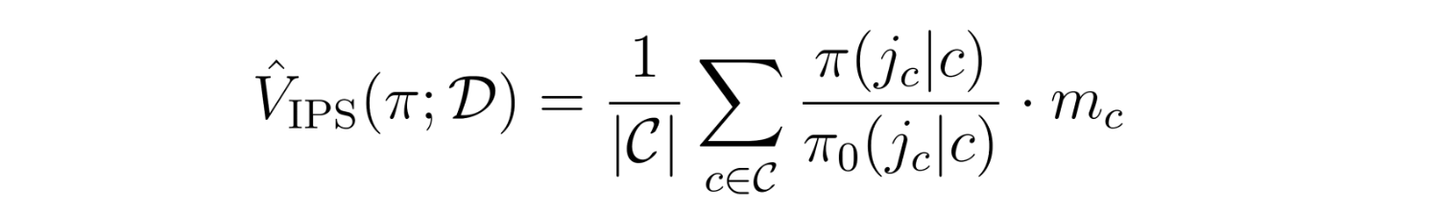
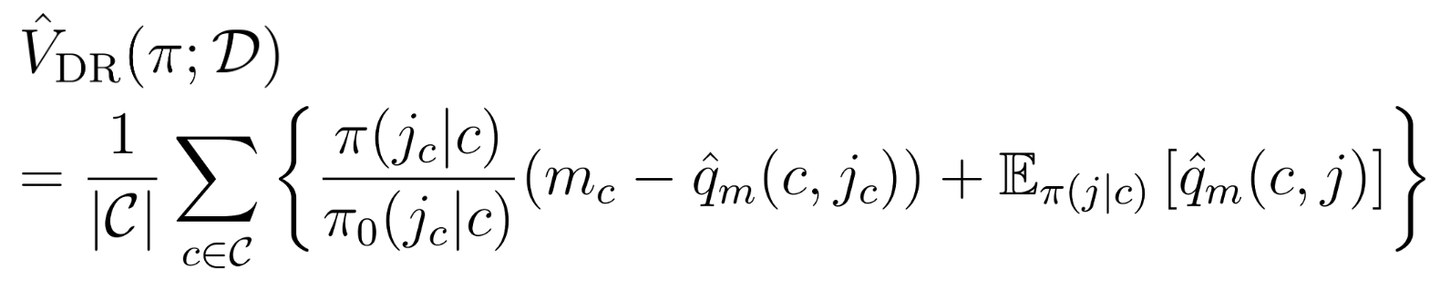
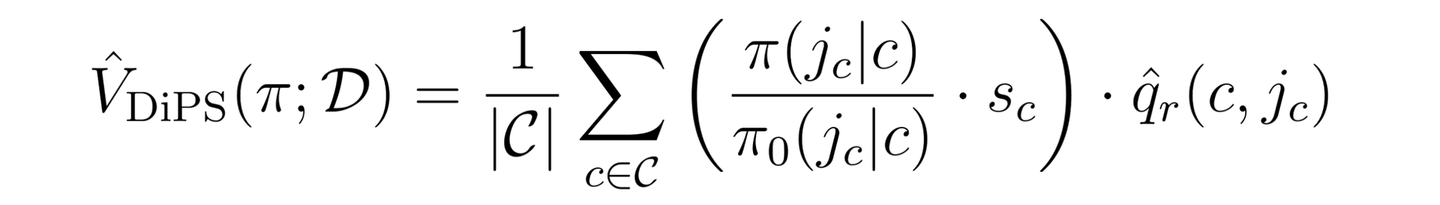
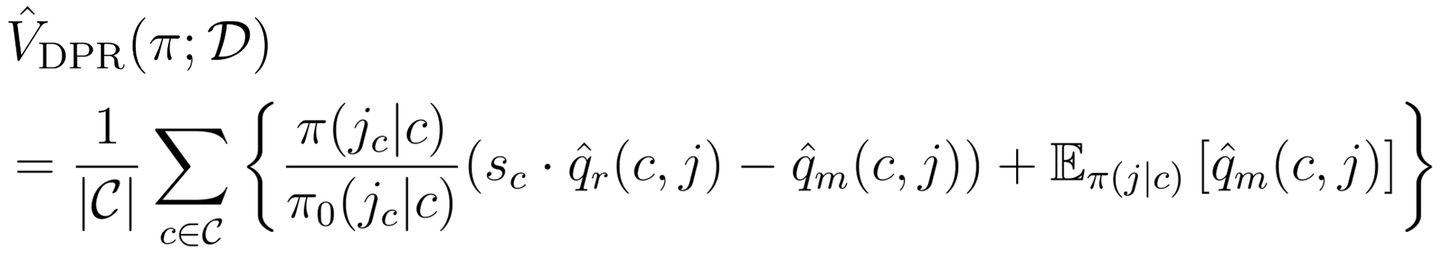
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


