この記事はWantedly Advent Calendar 2023の16日目の記事です。前日は川辺さんの「Wantedly Webフロントエンド開発の壁」という記事でした。
ウォンテッドリーでデータサイエンティストをしている林(@python_walker)です。今年の9月にシンガポールで開催された推薦システムの国際学会 RecSys2023 にチームで聴講参加してきました。
このブログ記事では、実際に現地でカンファレンスに参加してみて面白いと感じた論文の紹介と、提案手法をWantedly Visitのデータに対して適用してみた結果について紹介したいと思います。RecSys2023 の参加レポートに関しては他のメンバーも投稿していますので、ぜひそちらも読んでみてください。
紹介論文
この記事で紹介するのは、"Augmented Negative Sampling for Collaborative Filtering" という論文です。この論文は協調フィルタリングを使った推薦システムをより高効率に、高精度に学習するためによりよい負例サンプリングの手法を提案したものになります。
協調フィルタリングというのは、ユーザーがあるアイテムにインタラクションしたか(e.g. 購入したか)を行列の形で持っておいて、それを使ってユーザーが好みそうなアイテムを予測する手法です。予測の手法は様々ありますが、元の行列をユーザー行列とアイテム行列の積の形に分解する手法が有名です。行列分解を学習する際に目的関数としてよく用いられるのがBPR(Bayesian Personalized Ranking)ロスと呼ばれるものです。BPRロスではユーザーと、そのユーザーがインタラクションしたアイテムとの類似度はより高く、ユーザーとインタラクションしなかったアイテムの類似度はより低くなるように学習を進める働きを持っていて、ランキングのようなアイテム間の順位が問題になるタスクに対して適しています。ここで「ユーザーがインタラクションしなかったアイテム」は負例と呼ばれます。推薦タスクの場合、通常は負例の数は正例と比べて圧倒的に多く、全てを学習に使うことは困難です。そのため、負例の集合から学習に使う分を一定数サンプリング(負例サンプリング)することが一般的です。しかし、サンプリングするときにどのような負例を取ってくれば効率的に学習を進めることができるか、という問に対しては長年の間研究が続けられてきました。
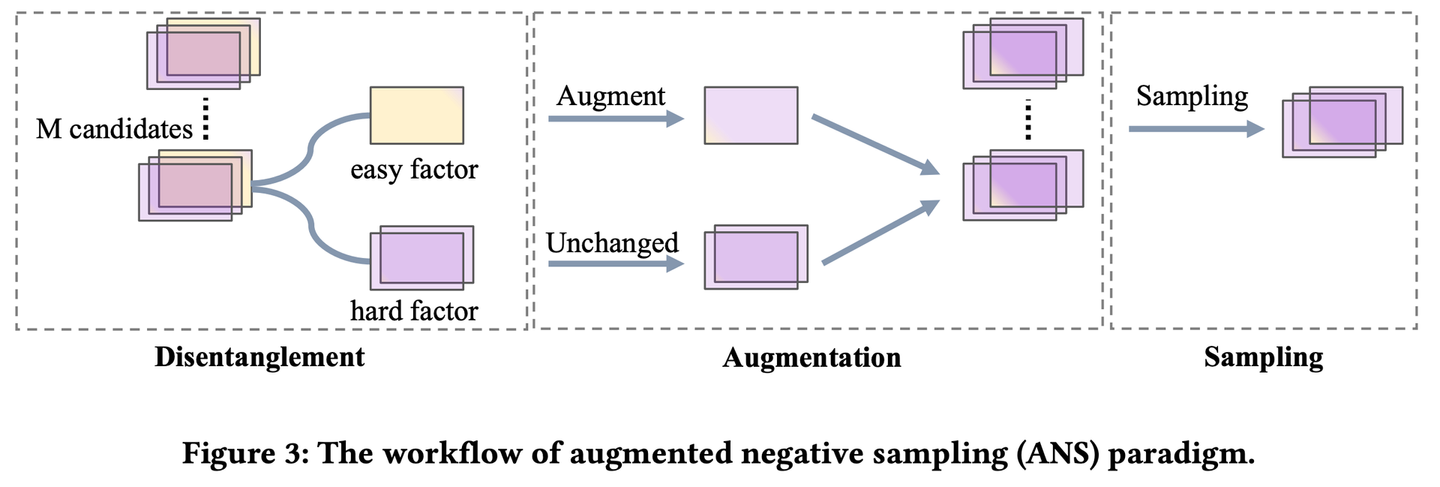
この論文ではデータセットからサンプリングしてきた「ユーザーがインタラクションしなかったアイテム」を使って、モデルにより効率的に情報を与えられるような負例を作り出す手法を提案しています。モデルの学習に意味のある負例というのは正例と区別がつきにくいものだと考えられるのが一般的ですが、筆者らは判別が簡単な負例にもモデルの学習に必要な情報が含まれているはずだと考えて、augumentationによって判別が簡単な負例の情報を保ったまま正例に寄せるということを行っています(下図は原著論文より引用)。
![]()
図でも示されているように、この手法は3つのステップから構成されています。
- Disentanglement: サンプリングしてきた負例をeasy factor(正例と大きく異なっており簡単に正例と区別できる要素)とhard factor (正例と似ていて区別が難しい要素)に分割するステップ。分解はアイテムのベクトルに対してゲートを掛けることによって行われており、ゲートは対照学習のときのようなロス関数を使って学習されます。
- Augmentation: easy factorに正例の要素を加えて、サンプルがより正例に近づくように合成するステップ。
- Sampling: 合成した負例の集合から学習に使うサンプルを選び出すステップ。選び出す基準は2つあり、1つはどれくらい正例に近いか、もう一つは、合成前にどれくらい正例から遠かったか、です。前者は従来の負例サンプリングの考え方と同じもので、正例に近い(=決定境界と近いところにある)サンプルを取ってくることでより効率的にモデルを学習したいという意図から来ています。後者がこの論文独自のもので、正例からは遠いがより多様な情報を負例から取り込みたいという意図から来ています。この2つの基準のバランスはハイパーパラメータで調整されます。
この手法についてもっと知りたいという方は、原著論文を参照していただくか、私が過去に行った発表の際に作ったスライドもありますので参考にしてみてください。
実験
GitHub上にこの論文のコードが公開されているので、これをベースに実験を行います。ちなみにこのリポジトリではRecBoleというフレームワークの上に実装がされています。RecBoleには様々な推薦モデルの実装が用意されており、既存モデルの一部に対して改善を行いたい場合などに非常に低コストに実装・実験を行うことができます。
再現実験
まずは論文でも使われているGowallaデータセットを利用して手元での結果の再現を行います。実験のベースには行列分解(MF, Matrix Factorization)をBPRロスと組み合わせたものを用いています。その他、実験の際に用いたパラメータは以下のような config.yml を用意して設定しました。
epochs: 300
stopping_step: 10
embedding_size: 64
eps: 0.1
gamma: 0.1
reg_weight: 0.0001
require_pow: False
load_col:
inter: [user_id, item_id]
eval_args:
group_by: user
split: {'RS': [0.8, 0.1, 0.1]}
mode: full
learner: adam
learning_rate: 0.001
train_batch_size: 2048
valid_batch_size: 2048
eval_batch_size: 2048
train_neg_sample_args:
candidate_num: 32
metrics: ['Recall', 'MRR', 'NDCG', 'Hit', 'Precision']
topk: 20
valid_metric: Recall@20
実験で得られたRecall@20の値は以下のとおりです。
- MF-BPR:0.1614
- MF-BPR w/ ANS:0.1771
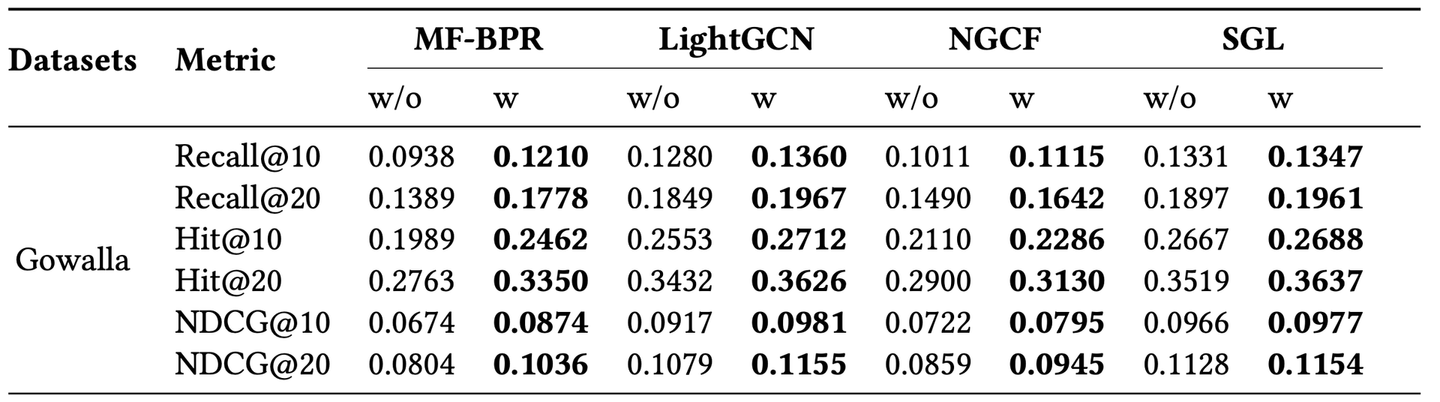
そして以下は、論文で報告されている結果の、今注目しているデータセットに関する部分のみの抜粋です。
![]()
提案手法を入れた場合に関しては、手元で行った実験は報告されている値と近いものになっています(手元:0.1771、論文:0.1778)。ただ、提案手法を入れなかった場合がずれていて手元で実験したときのほうが高い性能になっていました。
Wantedly Visitのデータを使った実験
今回の実験では、Wantedly Visit上でユーザーが募集のページ上で「話を聞きに行きたい」ボタンを押したログデータを使って実験します。RecBoleに用意されているモデルを自分たちのデータセットに用意する際には、RecSysDatasetsというリポジトリを利用してCSVを専用の形式に変換します。
以下のように conversion_tool/src/extended_dataset.py に記述してデータセットの変換を行います。
class WantedlyDataset(BaseDataset):
def __init__(self, input_path, output_path):
super(WantedlyDataset, self).__init__(input_path, output_path)
self.dataset_name = "wantedly"
self.interact_file = os.path.join(self.input_path, "interact.csv")
self.sep = ","
output_files = self.get_output_files()
self.output_inter_file = output_files[0]
self.inter_fields = {
0: "user_id:token",
1: "item_id:token",
2: "timestamp:float",
}
def load_inter_data(self):
return pd.read_csv(self.interact_file, delimiter=self.sep, engine="python")
python run.py --dataset wantedly --input_path ./wantedly-dataset --output_path ./dataset/wantedly --convert_inter
比較するモデルは上と同様MF-BPRを用いており、提案手法を取り入れた場合と取り入れなかった場合でRecall@20を計算します。また、論文中でGowallaデータセットを利用した実験をしていたときには、時系列による学習データとバリデーションデータの分割は行っていないと書いてあったのですが、Wantedly Visitのデータに対しては時系列順に並べてデータを切ります。それ以外については基本的にGowallaで実験したときのパラメータをそのまま使いました。
- MF-BPR:0.1724
- MF-BPR w/ ANS:0.1912
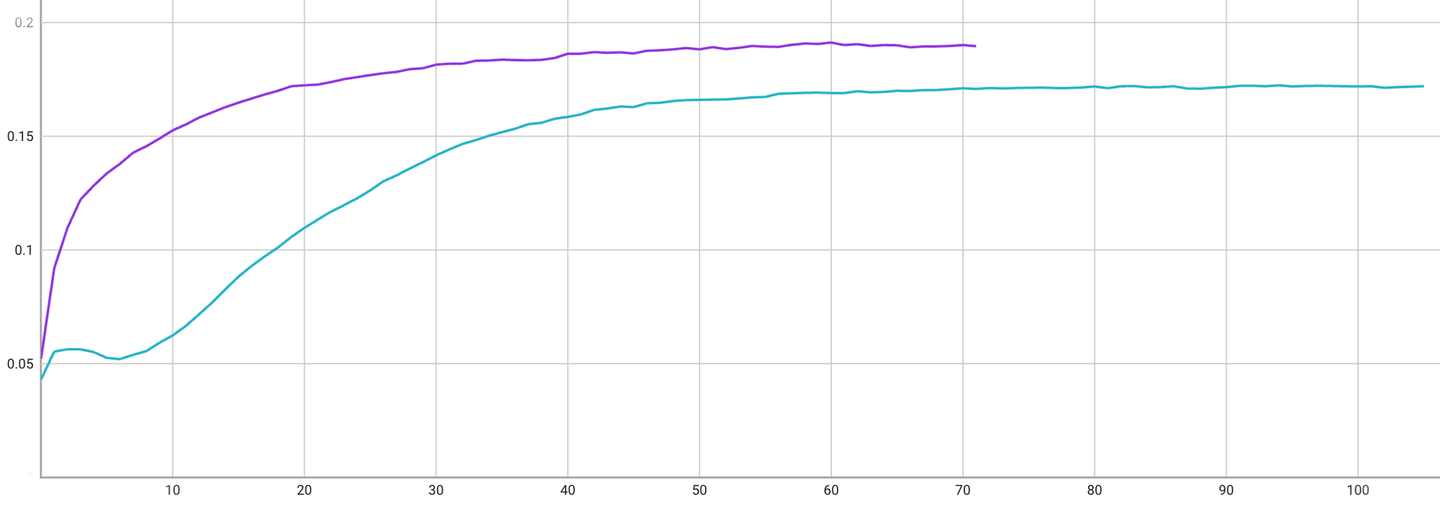
提案手法を取り入れたほうがRecall@20の値が10 %程度改善していることがわかります。学習曲線は以下のようになっています。横軸がEpoch数、縦軸がRecall@20の値になっており、紫が提案手法あり、緑がなしのものです。最終的な性能が優れているのは上に示したとおりですが、学習が収束する速さに関しても提案手法のほうが優れています。
![]()
学習はノートPCのCPU上で行ったのですが、ANSを使わないケースで1-epoch 3分程度、ANSを入れたときに4分程度だったので、収束の速さを加味すればANSのほうが学習にかかるトータルの時間は短く性能も高いということがわかりました。
まとめ
この記事では、私がRecSys2023に現地参加して面白いと感じた論文の紹介と、Wantedly Visitの実際のデータを利用した簡単な実験を紹介しました。行列分解は推薦モデルとしては古典的な部類に属するものではありますが、提案されている手法自体は負例サンプリングを利用していれば拡張可能であるので、我々の推薦システムに対してどれほど効果があるのかというのは非常に興味深いことでした。そして実際試してみて、我々のデータに対しても負例サンプリングの工夫がかなり効くとわかったのは大きな収穫でした。今後も最新の知見を貪欲に学んでいって、プロダクトをより良いものにしていきたいです。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


