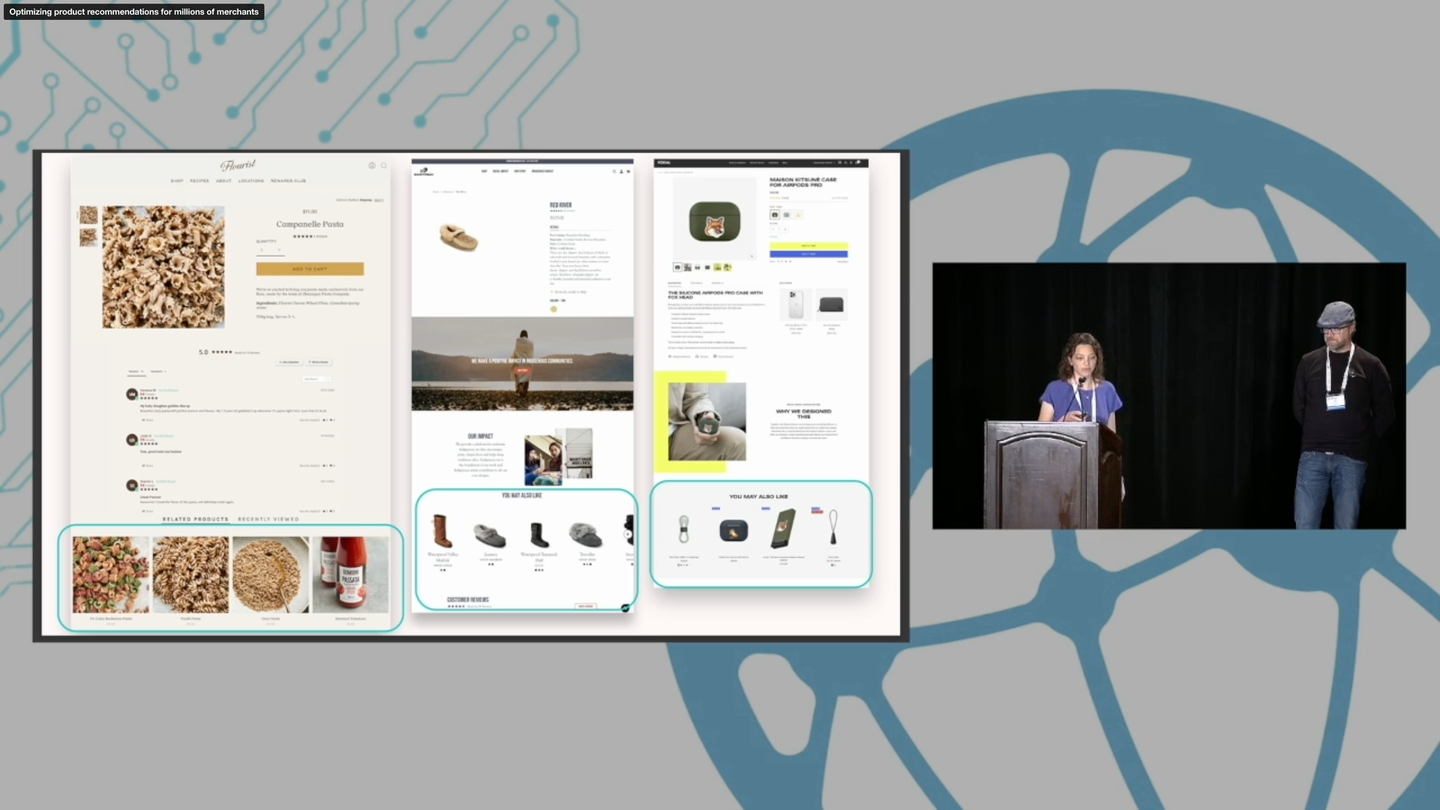
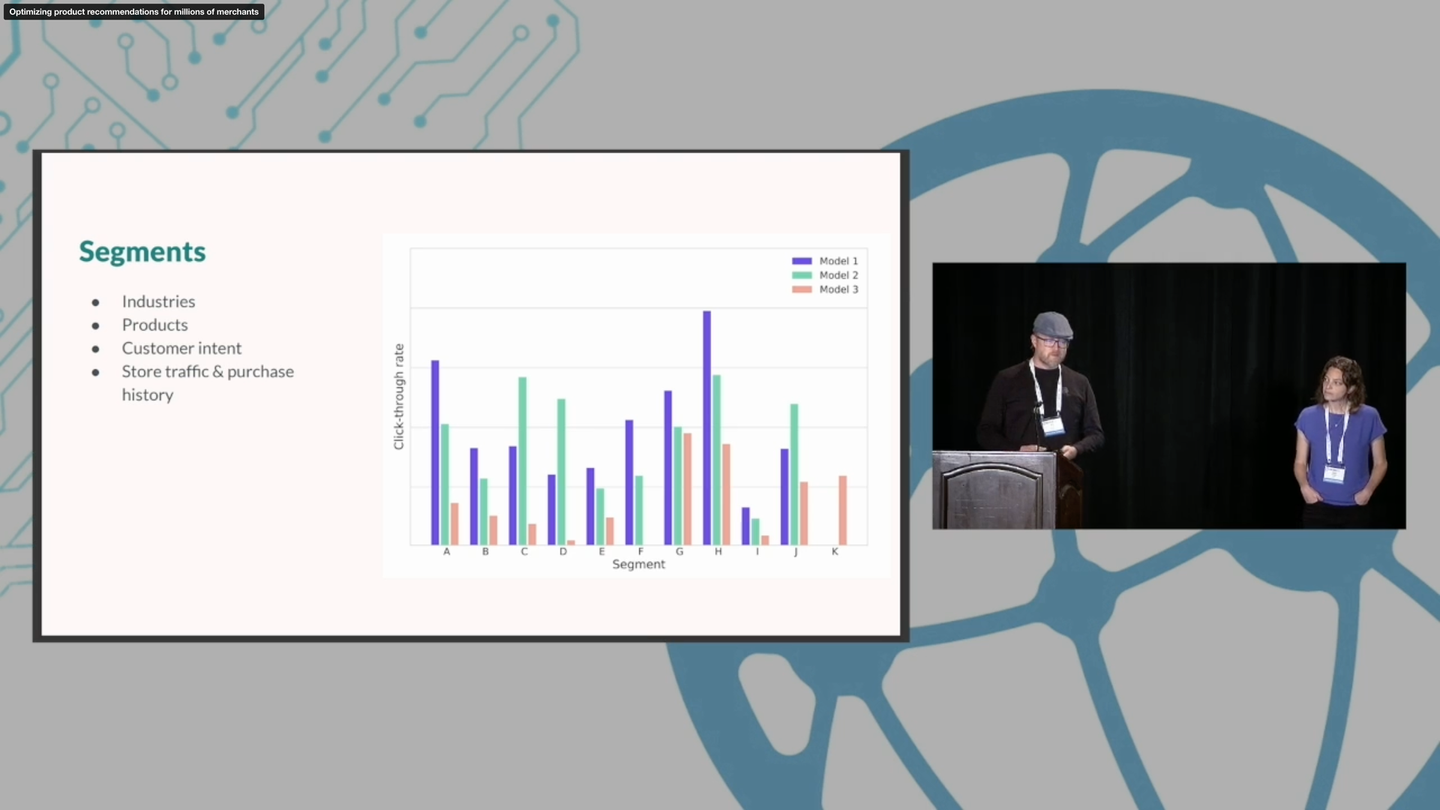
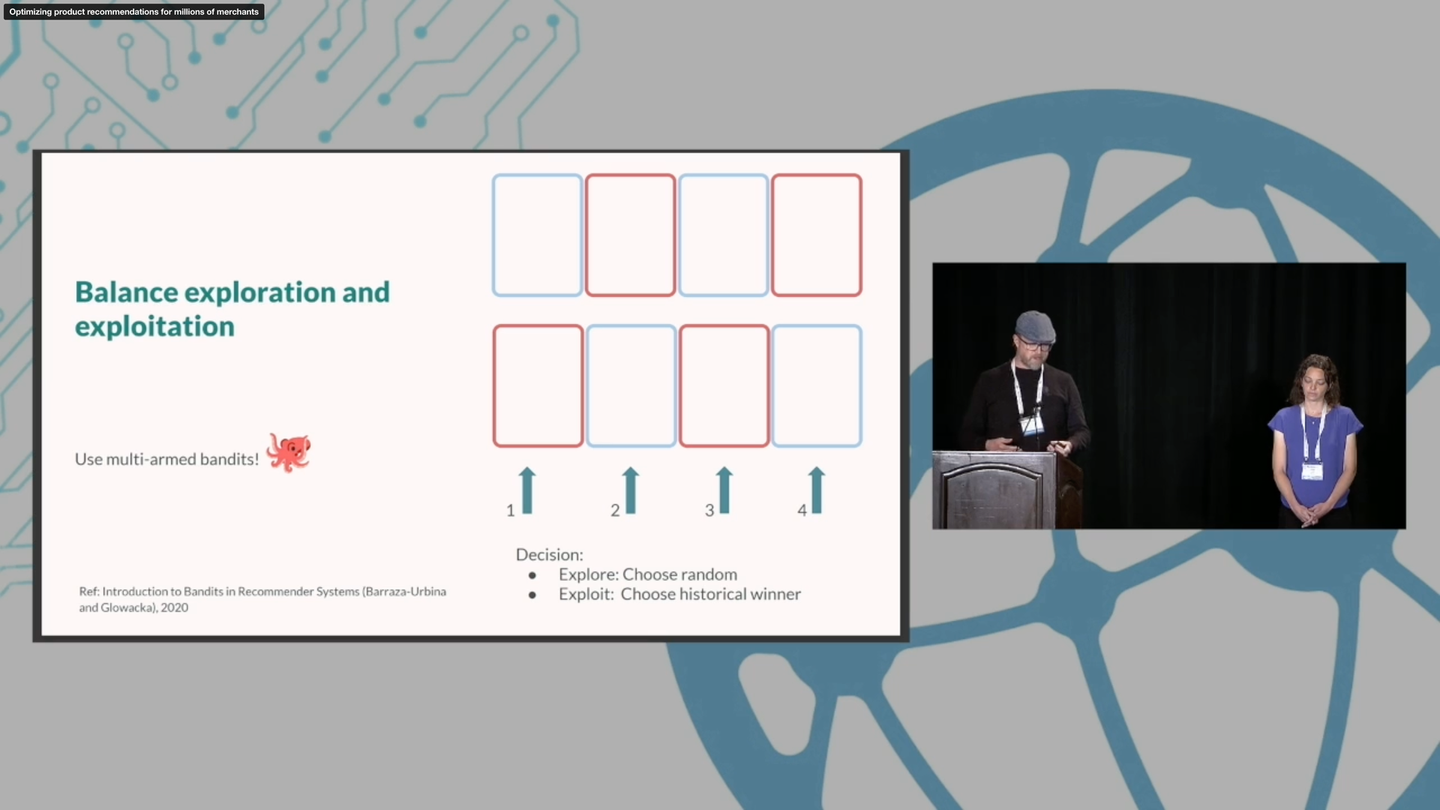
Kim Falk and Chen Karako. 2022. Optimizing product recommendations for millions of merchants. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys '22). Association for Computing Machinery, New York, NY, USA, 499–501. https://doi.org/10.1145/3523227.3547393
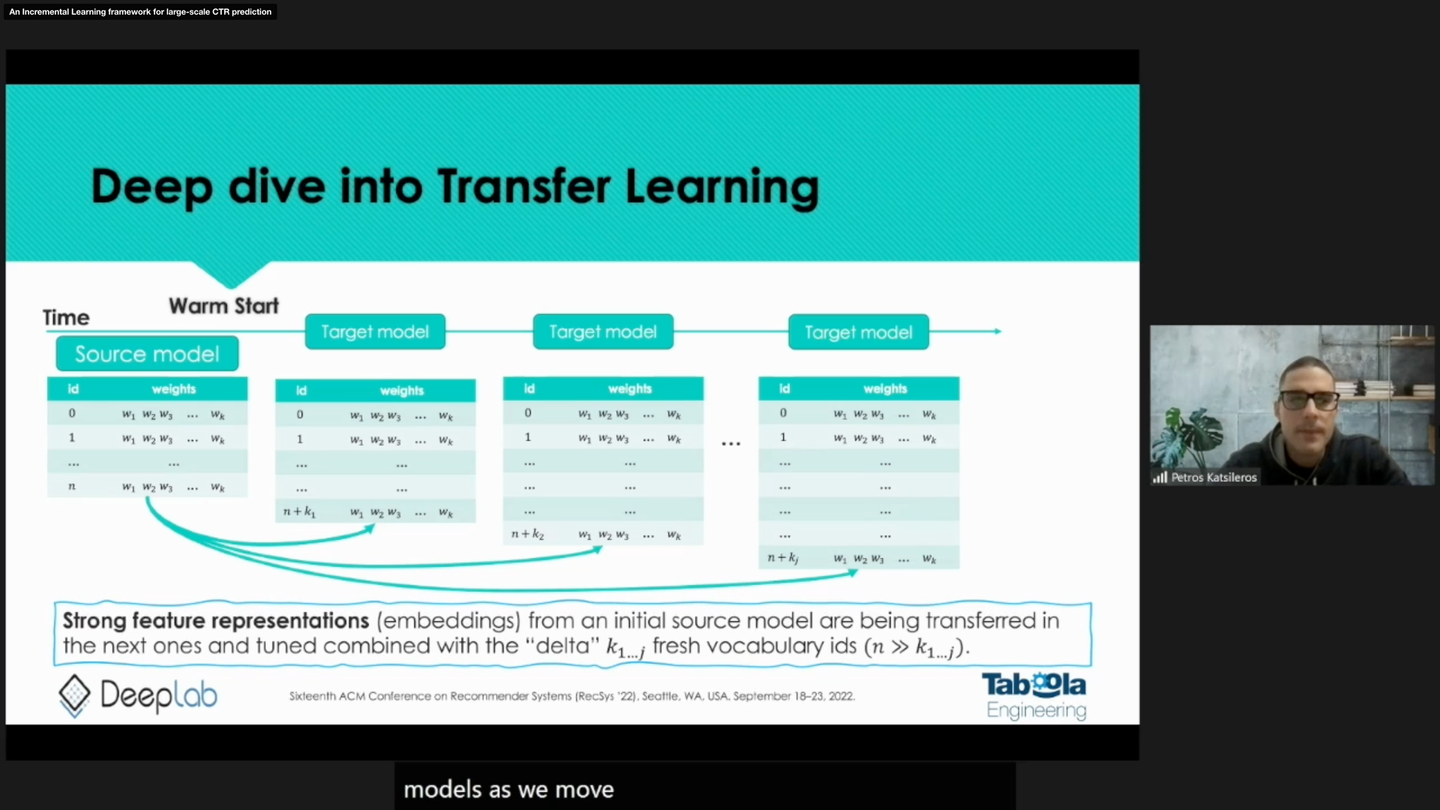
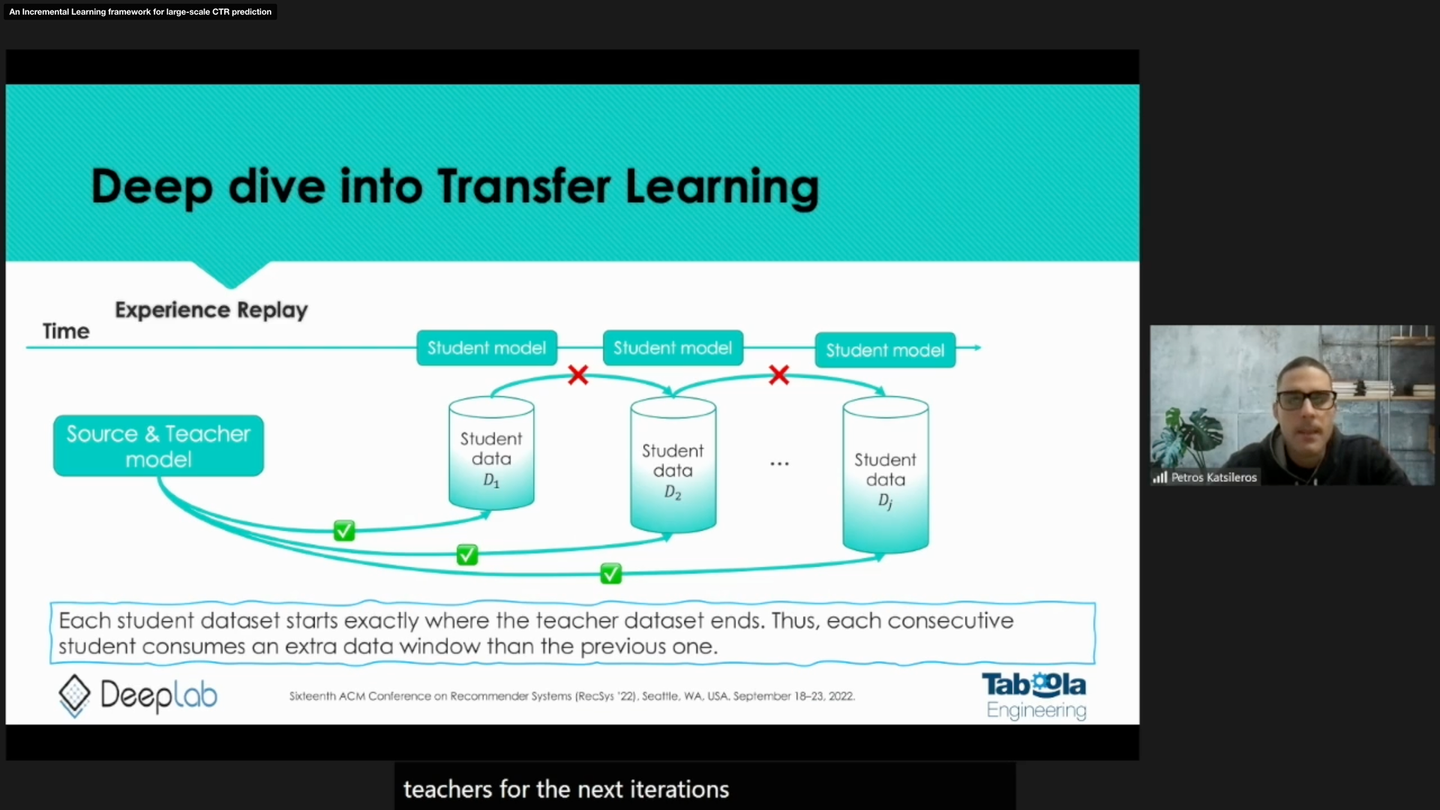
An Incremental Learning framework for large-scale CTR prediction
推薦システムで広く使用される、CTR (Click Through Rate) 予測モデルの学習には一般に長い学習時間が必要になり、頻繁にゼロからモデルを学習し直すということは難しくなっています。一方、学習や推論に使用するデータの分布は時間経過とともに変化していくため、一般にモデルを学習してから時間が経過するにつれて精度が劣化することが知られています。そのため、効果的な推薦を行うためになるべく新しいログを学習に使用したいというモチベーションがあります。
Petros Katsileros, Nikiforos Mandilaras, Dimitrios Mallis, Vassilis Pitsikalis, Stavros Theodorakis, and Gil Chamiel. 2022. An Incremental Learning framework for Large-scale CTR Prediction. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys '22). Association for Computing Machinery, New York, NY, USA, 490–493. https://doi.org/10.1145/3523227.3547390
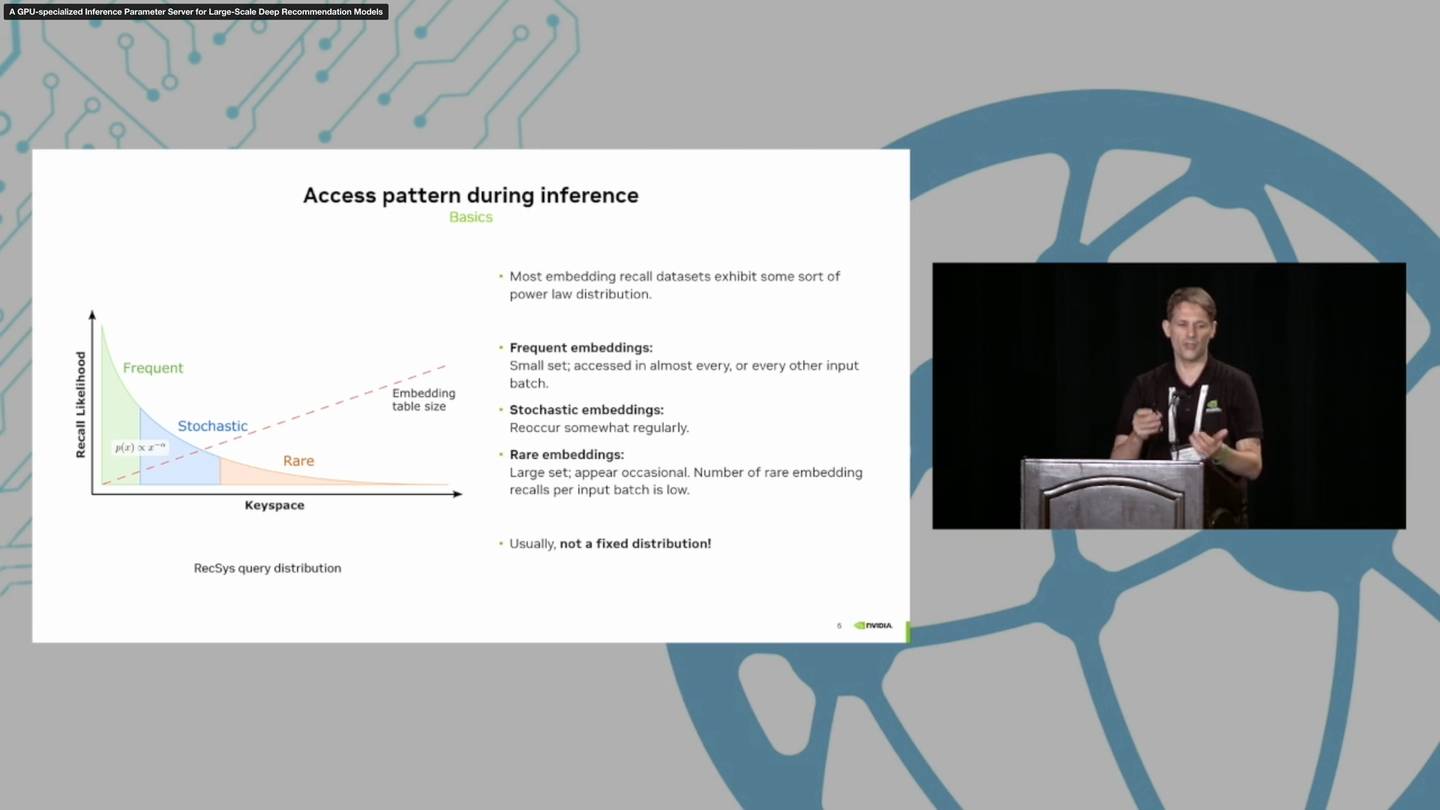
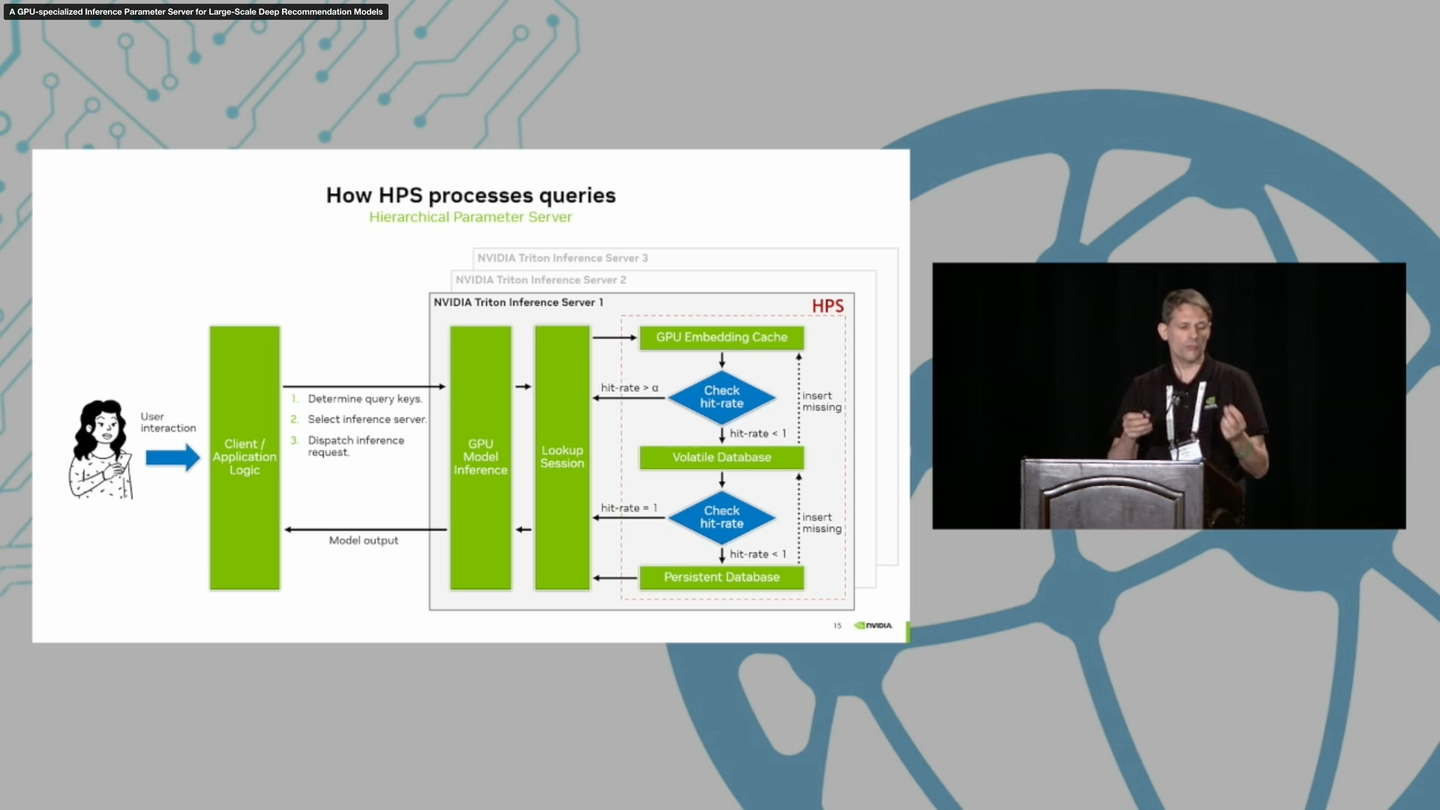
Yingcan Wei, Matthias Langer, Fan Yu, Minseok Lee, Jie Liu, Ji Shi, and Zehuan Wang. 2022. A GPU-specialized Inference Parameter Server for Large-Scale Deep Recommendation Models. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys '22). Association for Computing Machinery, New York, NY, USA, 408–419. https://doi.org/10.1145/3523227.3546765
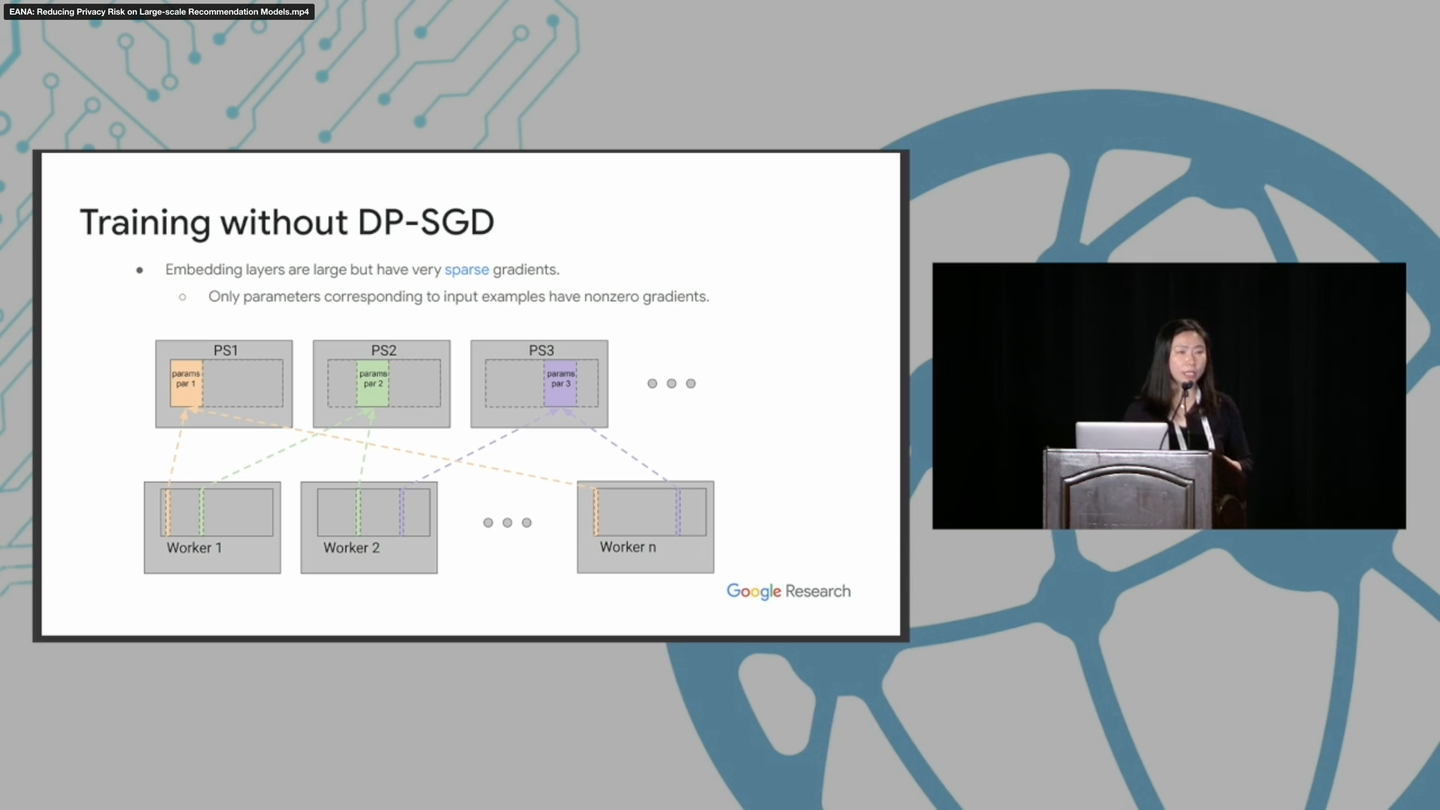
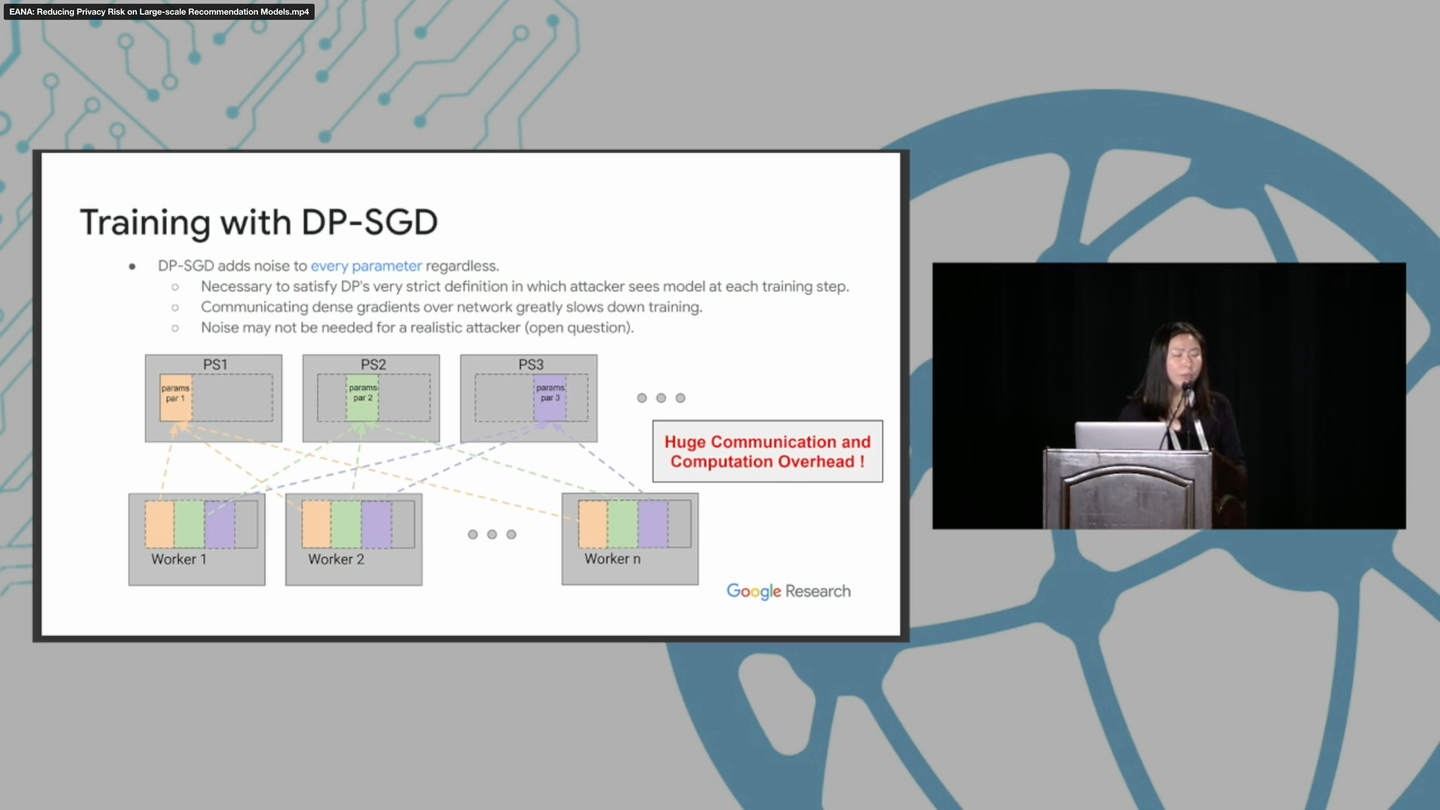
Lin Ning, Steve Chien, Shuang Song, Mei Chen, Yunqi Xue, and Devora Berlowitz. 2022. EANA: Reducing Privacy Risk on Large-scale Recommendation Models. In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys '22). Association for Computing Machinery, New York, NY, USA, 399–407. https://doi.org/10.1145/3523227.3546769


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

