パフォーマンス分析プラットフォーム | New Relic(ニューレリック)
New Relicは、SaaS型の可観測性プラットフォームです。アプリケーション、ブラウザ、モバイル、インフラ、全てのパフォーマンスを収集・判定・通知・分析。顧客体験の向上とデジタルビジネスを成功へと導きます。
https://newrelic.com/jp

Photo by Aaron Burden on Unsplash
こんにちは。最近 Infrastructure チームから Matching チームへ異動した笠井(@unblee)です。
Matching チームは Wantedly Visit におけるユーザと企業の理想のマッチングを実現するために推薦システムの改良や、データサイエンスを活用したプロダクト開発に責任を持ち、現在 ML 基盤を作るサブチーム 2人(+内定インターン1人)、Data Scientist 4人が所属しています。
この記事は、チーム内の Data Scientist に対して社内で利用しているインフラ周りの知識、具体的には 利用している SaaS(具体的には New Relic と Honeybadger)の使い方と Kubernetes、Workflow Engine の基礎知識について速習会をしたときの資料を一般公開用に修正したものです。
社内で行われている取り組みについてオープンにすることで、社外のエンジニアや学生の方に Wantedly のエンジニアについて興味を持っていただけたら嬉しいです。
Wantedly では Infrastructure チームと Developer Experience(DX) チームが主導して、エンジニア自身がアプリケーションをデプロイ、モニタリングし継続的に生産性を高めていける社内インフラのプラットフォーム化を推進しています。しかしながら、そういった社内で作られた便利な仕組みやその使い方、あるいはエンジニアの間で流行っている便利ツールや技術、プロジェクト進行のベストプラクティスといった知見については全員が全ての情報をキャッチアップ出来るとは限らないため、以前は各個人が持っている知見がスケールしないという課題が開発チーム内にありました。
この課題を解決するために、8月ごろから「開発チーム全体としての技術力・課題解決能力が高められる & その状態が維持できる状態」を最終的なゴールとして、「知見が広がる、蓄積される」という状態を最初に実現するために、Tech Lunch というトピックを限定しない LT 大会のようなものを毎週開催するようになりました。こういった知見を共有する場を明示的に設けることによって以前より各人の知見を共有するハードルが低くなり、また、これに加えてより1つのトピックの掘り下げ、スコープの限定を前提にある程度の時間を確保して行う速習会というスタイルで知見を共有する機会も散発的に行われているため、徐々に全体の能力の底上げが実現されていると感じています。
こういった最近の社内の動きとちょうど私が Infrastructure チームから異動してきたタイミングが合わさって、インフラ周りの知見が共有されにくくその周辺知見が欠落していることによって生産性を下げているのではないか、という課題が挙がっていた Data Scientist にスコープを絞り、社内のインフラ周りでどのようなツールが何のためにどうやって使われているのかという知見を共有するための速習会を行う機会が設けられました。
速習会の目的と期待値は以下の通りです。
ここからは実際に速習会で共有した資料を一般公開向けに修正したものを共有したいと思います。
主にアプリケーションレイヤのパフォーマンスを記録・観測するために使われています。このため New Relic には多くの機能がありますが、エンジニアが日常的に使っているのは APM(Application Performance Monitor)になります。他にもサービスの監視のために Synthetics を使ってパフォーマンスが事前に決められたしきい値を超過したことを検出してアラートを発火させるということもやっていますが、ここでは詳細は説明しません。
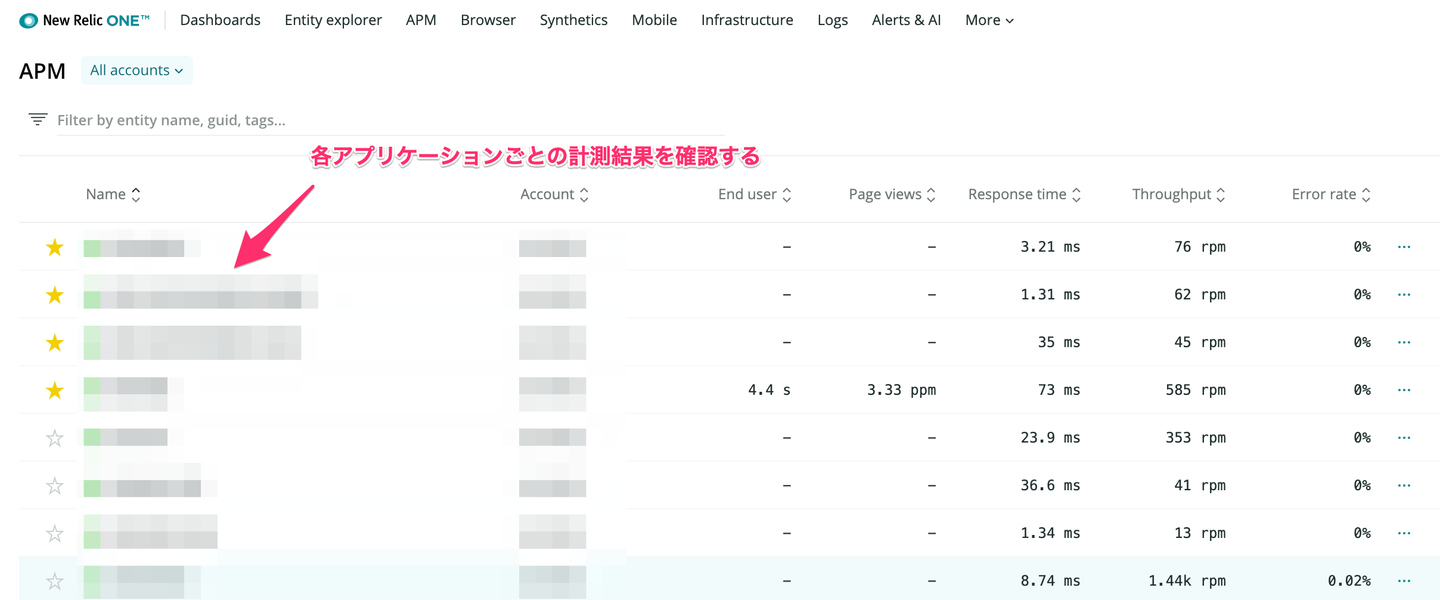
APM のトップページには New Relic での監視が有効になっているアプリケーション一覧が表示されているので、ここから観測したいアプリケーションを選択します。
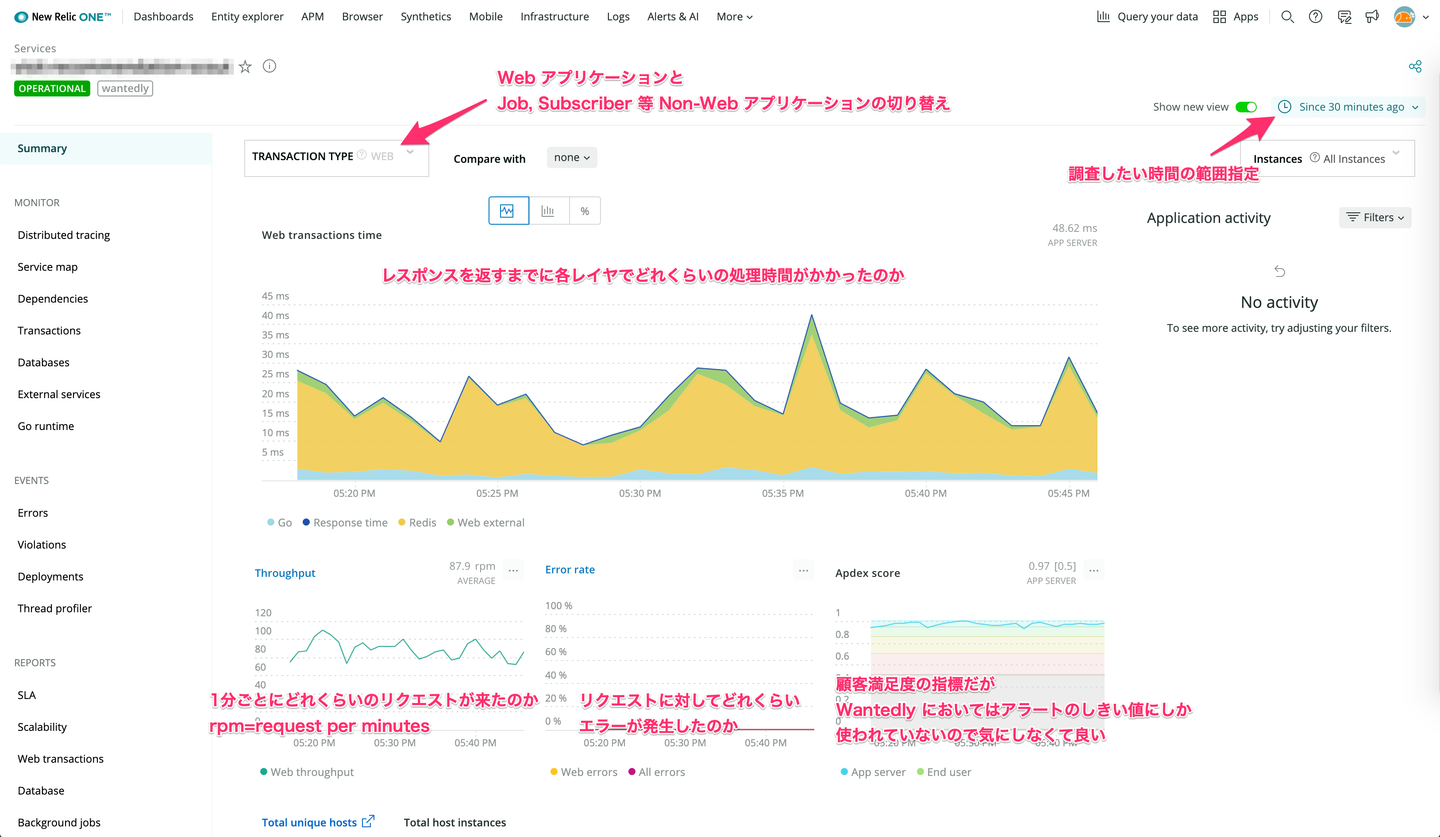
アプリケーションを選択すると以下のような Summary 画面に遷移します。基本的に調査はここを起点に行われます。例えば Web Transaction を見て全体のレスポンスタイムが遅くなっていないか、どのレイヤで遅くなっているのかを確認する。また、Error Rate が上がっているようであれば Error Rate を確認します。
ここで重要なのは観測対象の Time Range を広げて時系列における値の動きの傾向を把握することです。一見問題が起こっているように見えても、Time Range を広げると定期的に起きていること(e.g. いつも月曜日に起こってるとか、毎日09:00頃に起こってるとか)だったりして、問題ではあるが緊急性は低いみたいな状況はよくあるのでとりあえず Time Range を広げることは意識しておくと良いと思います。
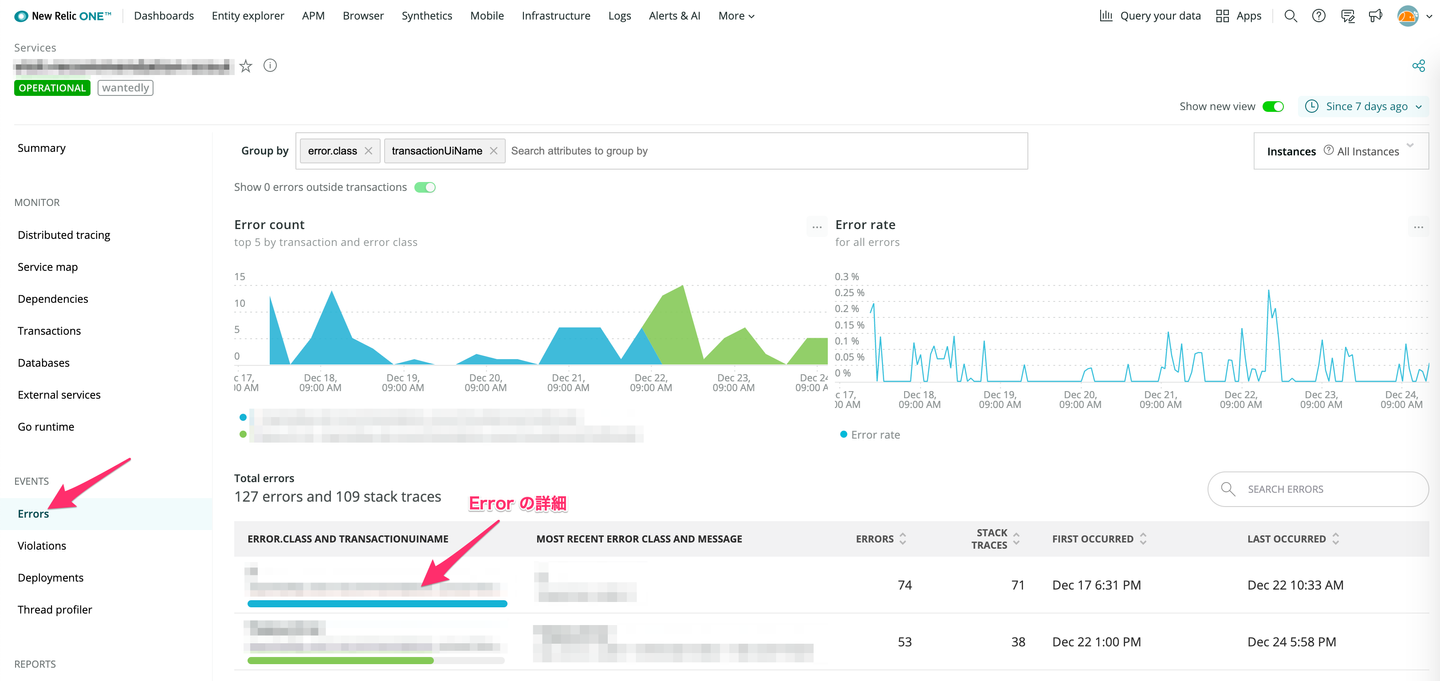
Summary ページ内の Error Rate もしくはサイドバーの Errors を選択すると以下のようなアプリケーションで発生した Error を確認するためのページに遷移します。何かしら障害が発生したときに確認するページですが、Wantedly においてエラーログのトラッキングには後述する Honeybadger を利用しているので社内で知見が溜まっている Honeybadger をメインで使って、こちらは補助的に使うのが良いかもしれません。
主にアプリケーションで発生したエラーを記録・観測するため、エラーによってアラートを発火させるために Honeybadger というエラートラッキングサービスを利用しています。
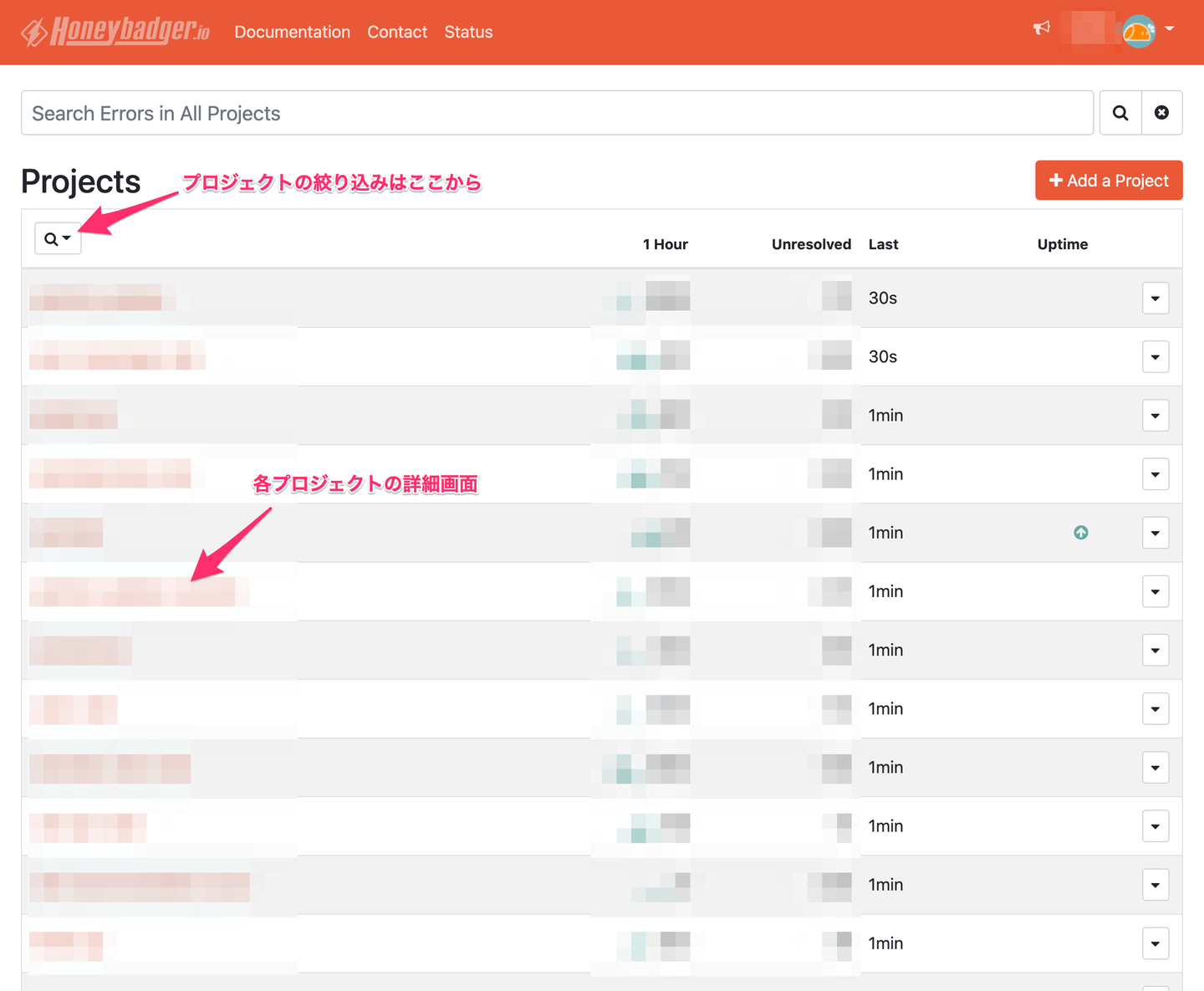
トップページに行くと Honeybadger でエラーをトラッキングしているプロジェクト(アプリケーション)が一覧になっているので観測したいものを選択してください。
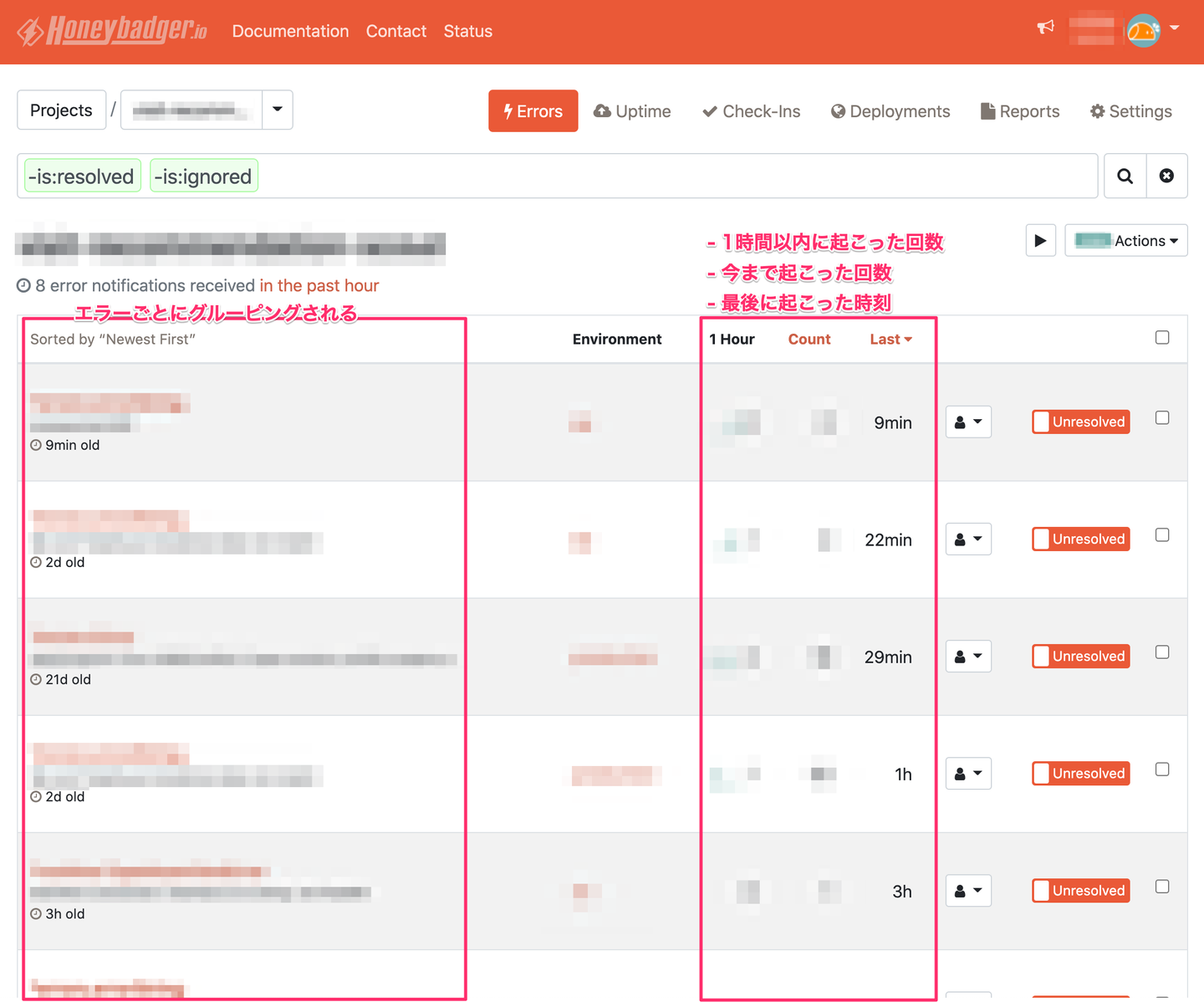
プロジェクトを選択すると以下のようなプロジェクト内で起こったエラー一覧が表示される画面に遷移します。ここでは同じ内容のエラーがグルーピングされて表示されるようになっていて、今までに起こった回数や1時間以内に起こった回数などをざっくり把握することが出来ます。この画面でよく見るのは1時間以内に大量にエラーが出ているかどうかで、もし大量に出ているエラーがあればそれを選択して詳細画面へ行きます。
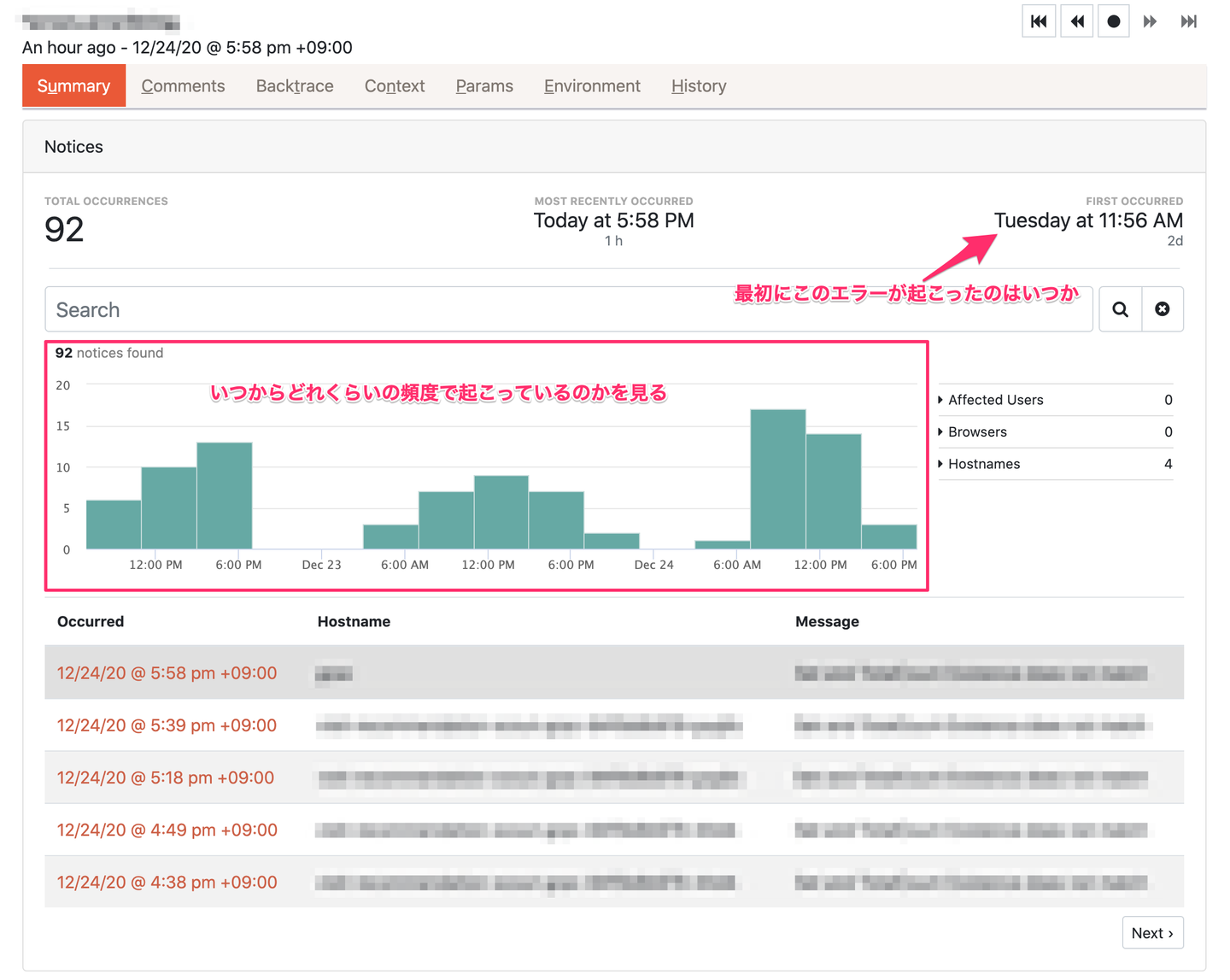
各エラーの詳細画面は以下のようになっています。例えばある特定の時刻からエラーが急増していることを発見し、その時刻付近に起こったイベント(e.g. デプロイ、DB の障害)を紐付けて仮説を立てていくようなことをよくやります。これは Honeybadger ではわからないので、Datadog、New Relic を見て調査する。障害の主な原因(トリガー)のひとつかつさっと確認出来ることとしてアプリケーションのデプロイが挙げられるので、とりあえず調査の初手はデプロイ履歴を確認するようなことをよくやります。
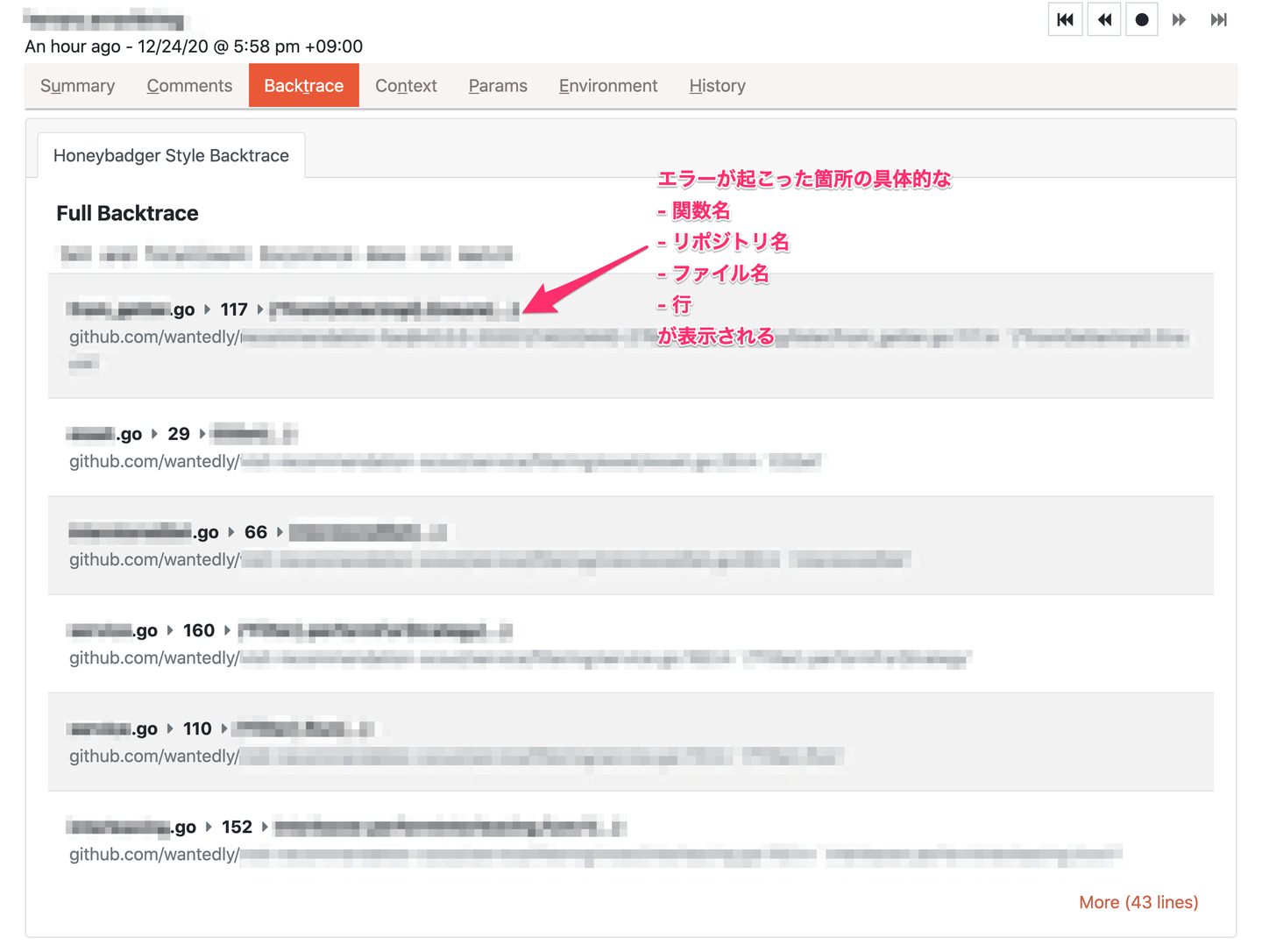
具体的にコード上のどこでエラーが発生したのかはバックトレースで確認します。
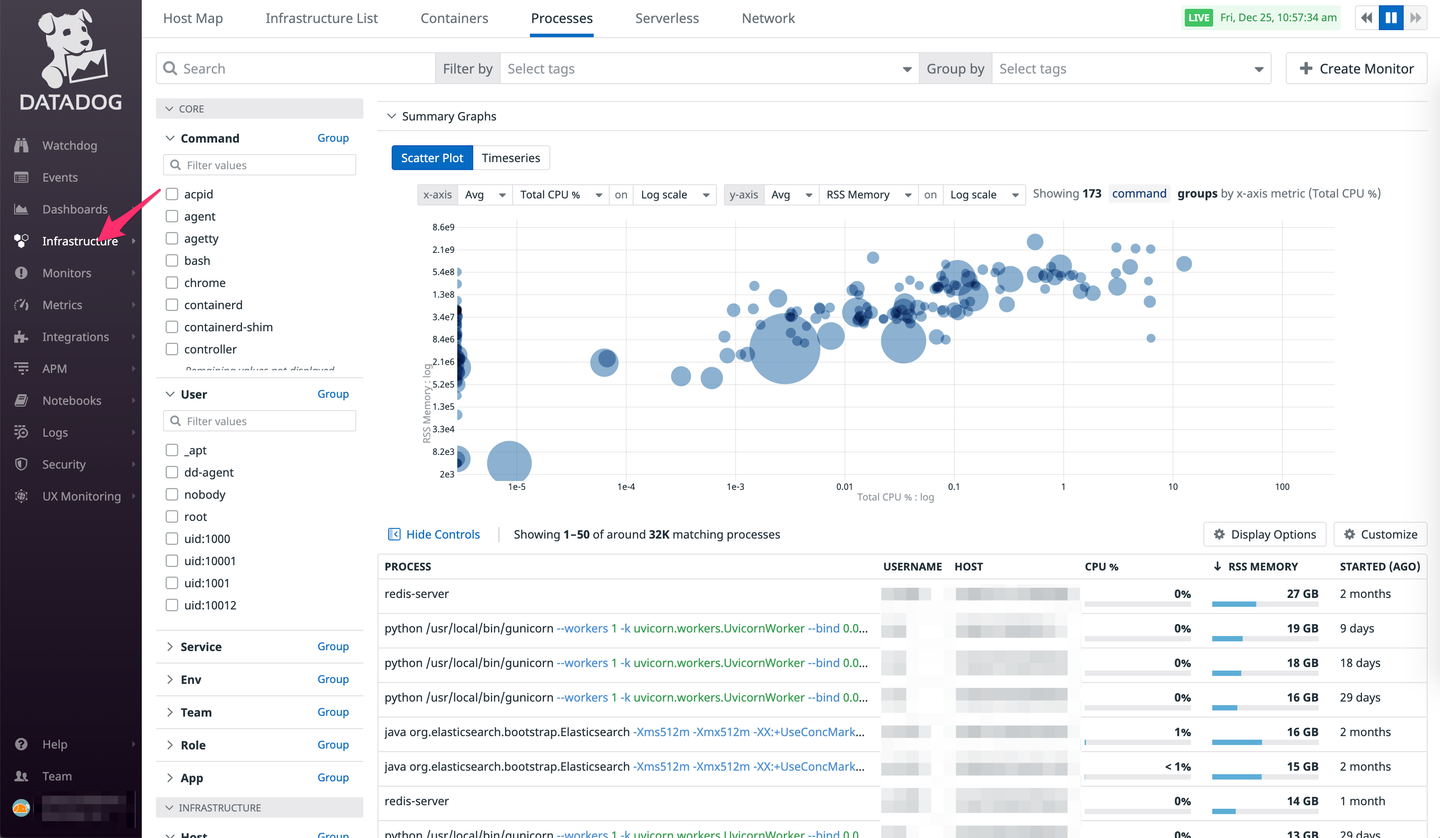
主にインフラレイヤのミドルウェア(or 任意)のメトリクスを記録・観測するために使われています。また、メトリクスの変化を元に事前に決められたしきい値を超えたことを検出してアラートを発火させることも行っています。
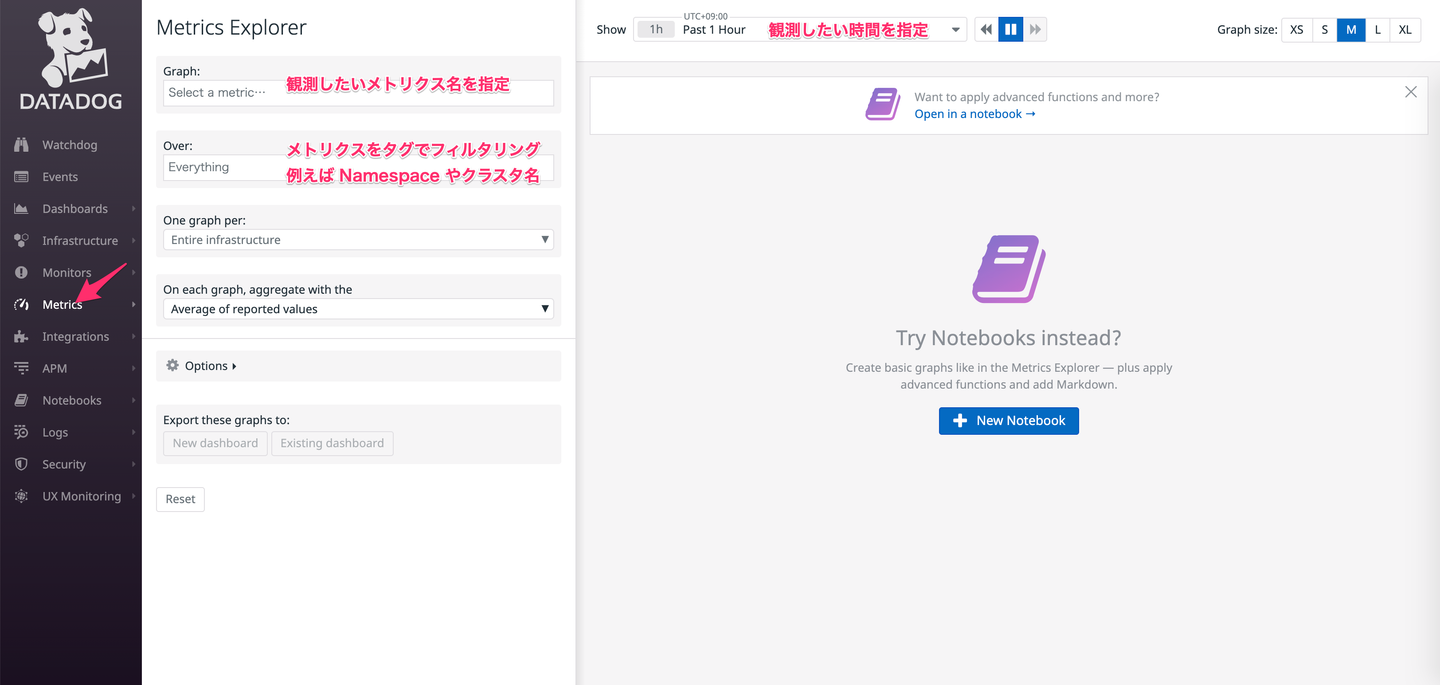
以下にいくつかよく使う機能について書いていますが、どの画面でも選択したパラメータが URL に追加されていくようになっているので実質パーマリンクとして機能します。このため、障害対応時に何かしらのメトリクスを観測したとき自分の考察・解釈とは別に観測した事実として Datadog のスクショと URL を Slack や GitHub の Issue に貼り付けるということを意識してやっています。
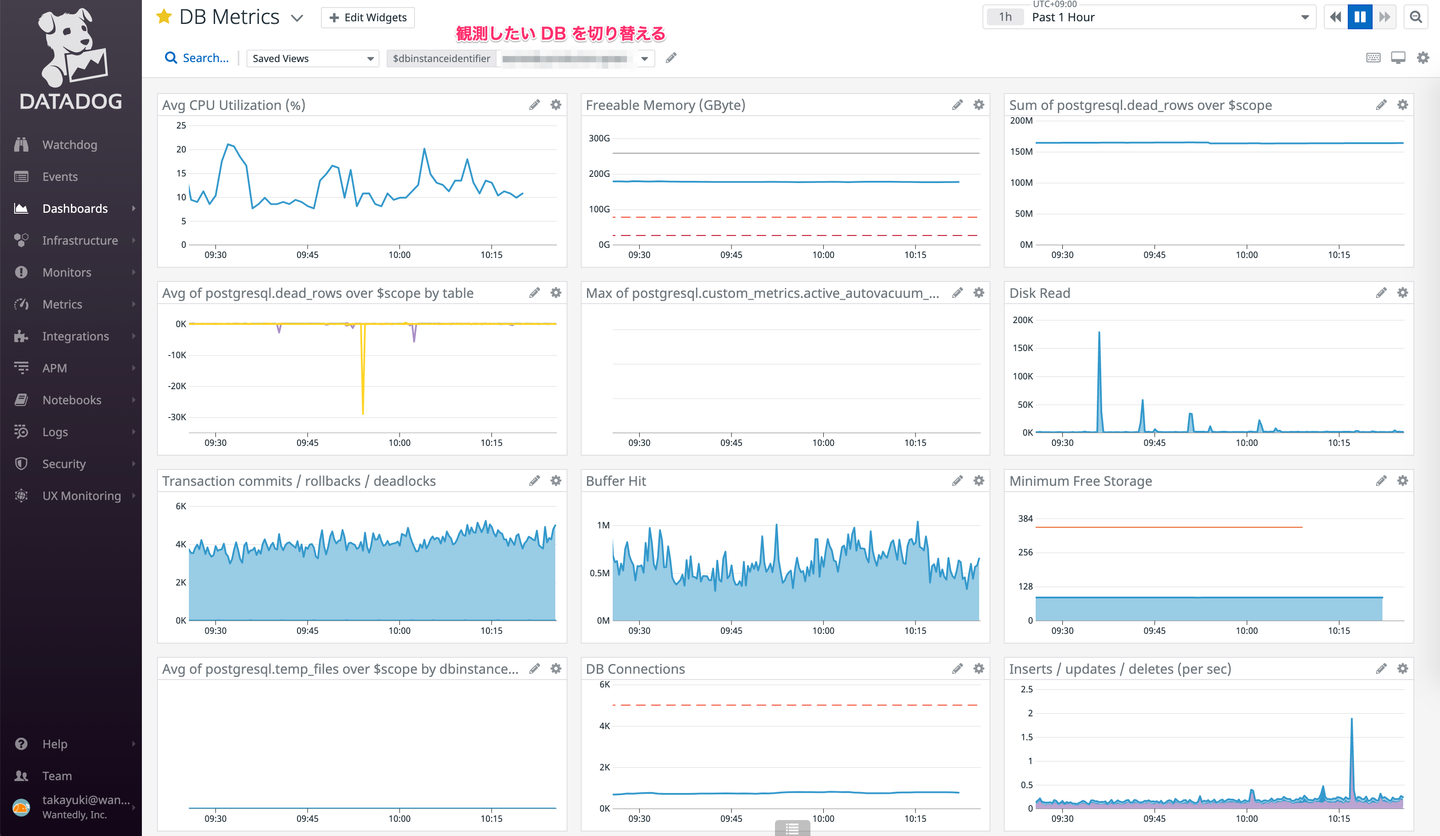
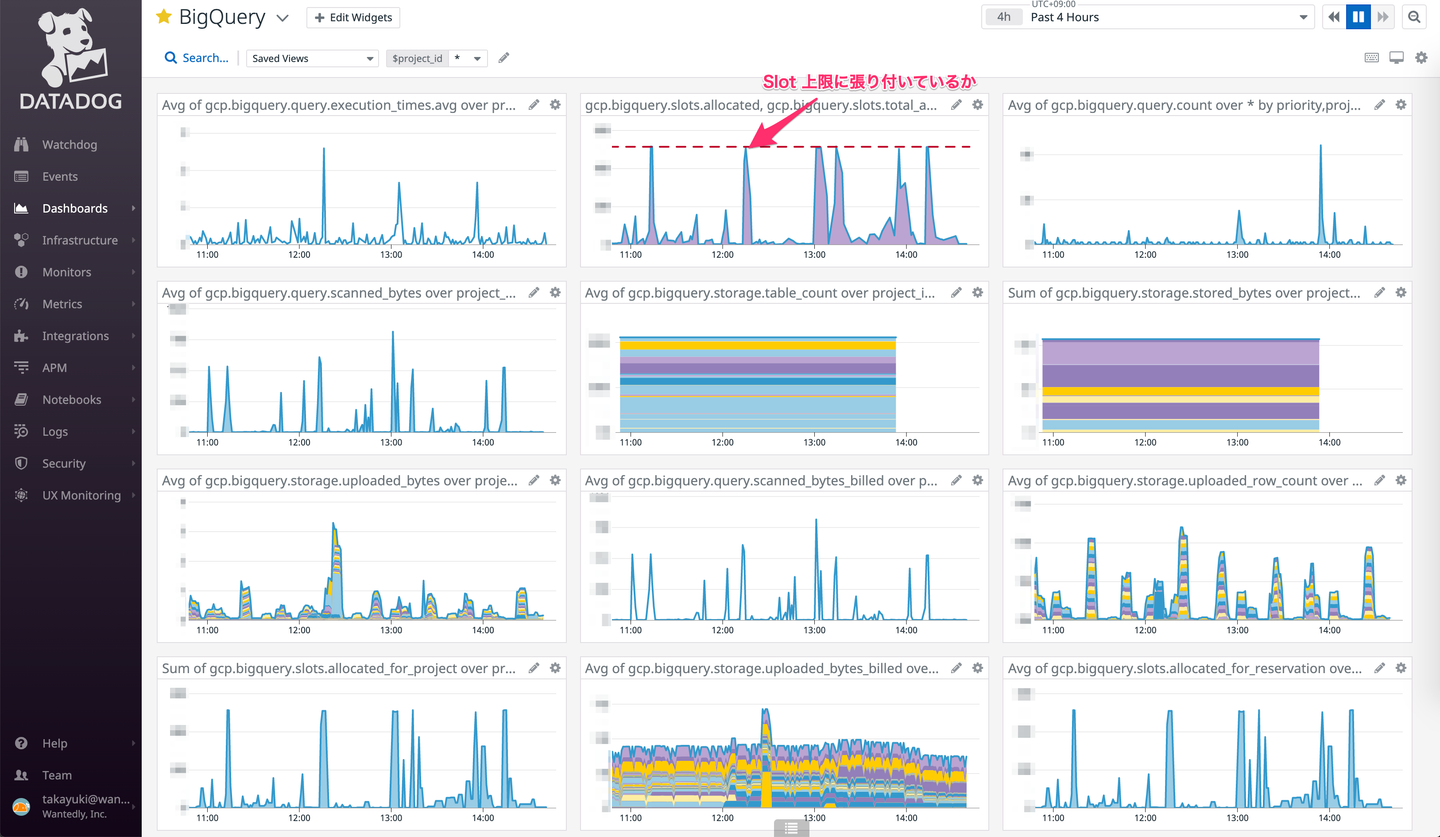
エンジニアは主に Dashboard 単位でメトリクスを観測する。以下はよく見る Dashboard
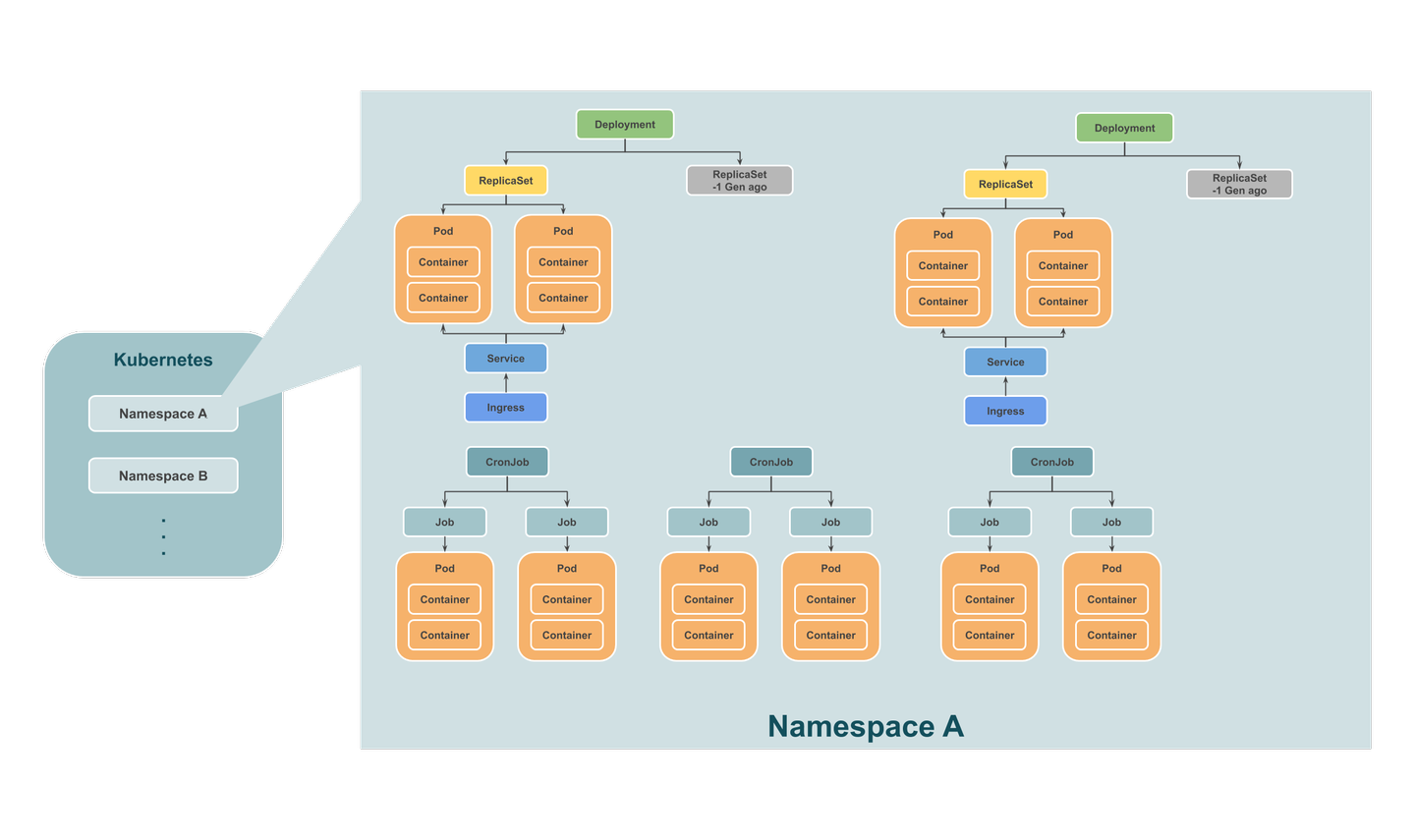
個人的な考えだとインフラエンジニア以外が知っておくと便利なのは Kubernetes における代表的な Object の階層構造と役割(機能)だと思ってます。
Kubernetes 以下のレイヤのリソース(Container, Network, Storage, etc…)を抽象化したものを指します。詳細は以下のドキュメントを参照してください。
もしくは少し古いですが(約2年前)以下の記事群も図解多めでわかりやすいです。全て読んだというわけではないですが、基本的な概念を解説しているだけなので内容的に deprecated なものはあまりないという認識です。
また、Object には spec(仕様)と state(状態)が存在しています。Kubernetes の根本的なコンセプトとして Reconciliation Loop によって Object で宣言された spec(desired state) に操作対象リソースの state を近づけるというものがあり、例えば Pod を2つ立てておいてくださいと spec に書いている状態で Pod が1つになってしまった(state)ら自動的にもう一台 Pod を立てるということを勝手にやってくれます。この辺りに興味があればKubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー(読むならp21までで良い)を参照すると良いと思います。
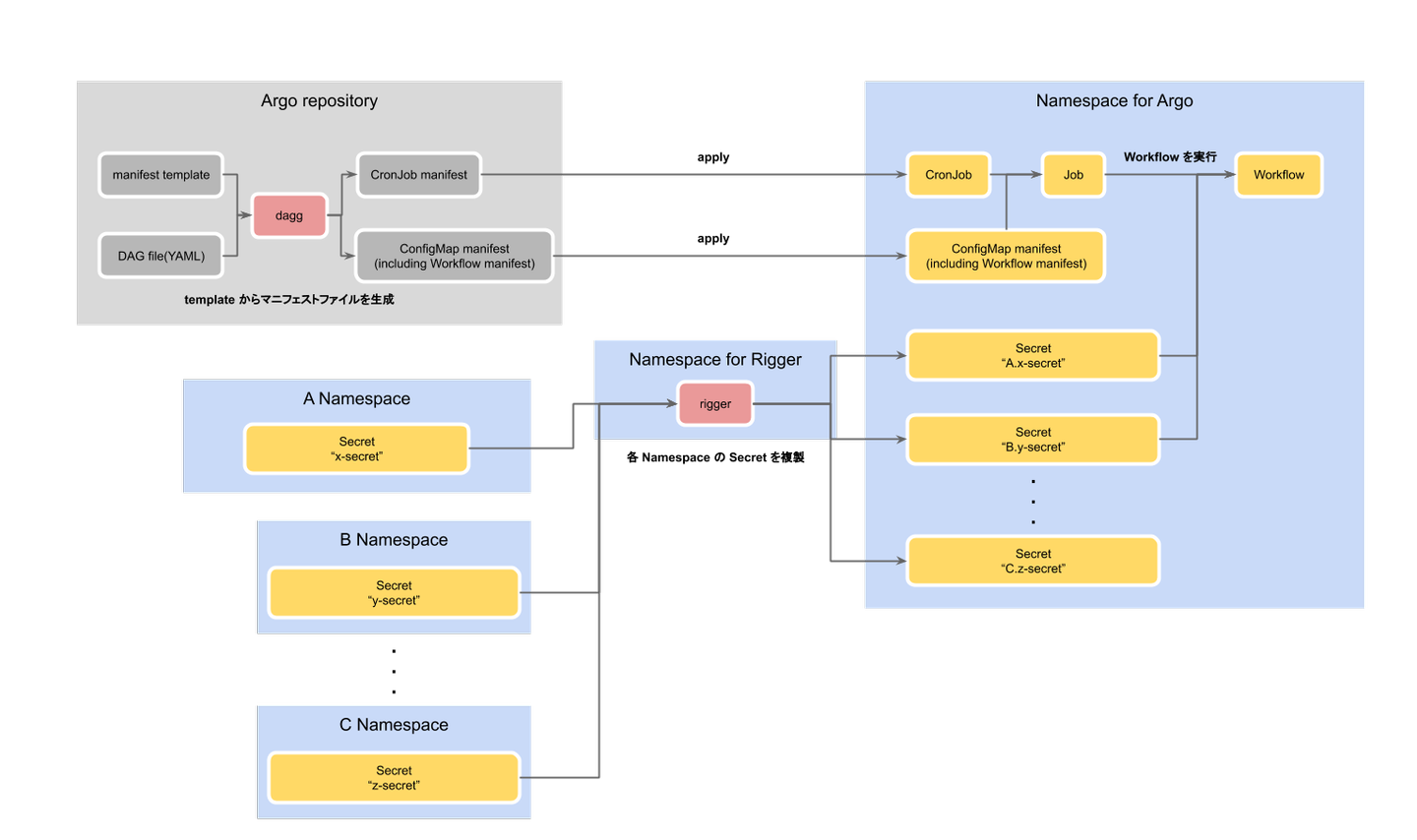
複数の Job の依存関係を上手く解決・実行してくれる Workflow Engine の1つです。他にも有名どころだと Airflow や Luigi, Digdag などがあります。Argo Workflow の特徴的な点としては、Job の依存関係(DAG)を Python や DSL ではなく、Kubernetes の Custom Resource として YAML 形式のマニフェストファイルで表現するというものがあります。
昨年、推薦周りのフローを実行時刻の前後で表現していた CronJob の依存関係が複雑になりすぎた頃に以下の問題を解決するために導入しました。
社内環境とユースケースにフィットさせるために小さなツールを自作しつつ、以下のようなフローで Workflow を実行しています。
作ったツール
Workflow を実行するまでの流れ
この記事では、チームの Data Scientist 向けにインフラ速習会を行った背景・モチベーション、実際に話した内容について書きました。後日参加していた Data Scientist が共有した知識を実際に使っていたり、社内の他チームからもポジティブなリアクションがあったことを観測していて、自分の持っている知見を共有することで多少なりとも社内の能力向上に貢献出来たと私自身のモチベーションアップにもつながりました。
最後に、このような社内で行われている取り組みについてオープンにすることで、社外のエンジニアや学生の方に Wantedly のエンジニアについて興味を持っていただけたら嬉しいです。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()

/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

