こんにちは、Wantedly で技術基盤に関わる Developer Experience Squad で Engineer をしている大坪( @potsbo )です。
今日は、WANTEDLY TECH BOOK 7 から「Kubernetes クラスタの移行から学んだクラスタのポータビリティの重要性と条件」という章を抜粋し加筆修正を加えたものを Blog にします。
「WANTEDLY TECH BOOK 1-7を一挙大公開」でも書いた通り、Wantedly では WANTEDLY TECH BOOK のうち最新版を除いた電子版を無料で配布する事にしました。Wantedly Engineer Blogでも過去記事の内容を順次公開予定であり、この Blog もその一環となっています。
以下、「WANTEDLY TECH BOOK 7 - Kubernetes クラスタの移行から学んだクラスタのポータビリティの重要性と条件」の内容です。
はじめに この記事では主にインフラに関する業務を行っている大坪が、Kubernetes クラスタの運用に関する提案を行います。
Kubernetes は変化が早く、運用を行っているエンジニアには日々手探りの状態である方も多いかと思います。Wantedly も例外ではなく、検証段階からすべてのサービスを Kubernetes に載せ替えた現在の運用まで日々実験と試行錯誤の繰り返しを行っています。その中で私達がこれまでに陥ってきた数々の落とし穴から少しでも多くの人を救えたらと考えています。その一つ一つを紹介していくことも可能ですが、それよりも複数の問題を事前に同時に解決できる包括的な提案ができればより根本的に問題を解決できるのではないか、と考え念頭に置くべき8原則をまとめるに至りました。
本記事ではクラスタのポータビリティという概念と、それを考えるに至った経緯を紹介し、ポータビリティを守っていく上で重要だと考える8原則について紹介します。なお本章は CloudNative Days Tokyo 2019 で発表した『k8s - Kubernetes 8 Factors』の内容に加筆修正を加えたものです。
クラスタのポータビリティが重要だと強く認識した背景 Kubernetes は開発が非常に早い Kubernetes の開発は非常に早いことで知られています。2018年のリリースでは、1.13 は 12月3日、 1.12は9月27日、1.11は6月26日、1.10 は3月26日とおよそ三ヶ月に一度行われています。また、サポートは最新を含む3つのマイナーバージョンまでであるため、最新がリリースされてから9ヶ月間しかサポートされないことになります。
breaking change もそれなりに起こる Kubernetes におけるマイナーバージョンの変更は大きな breaking change が入ることも多く、3ヶ月に一度の更新を行うのは容易ではありません。Wantedly では Kubernetes を 1.1 から検証および運用を行ってきました。その結果 deprecated になったコンポーネントの移行が難しくなったり、初期のバージョンでは標準機能で実現できなかったことを自作の実装で解決したものが負債になったりと、さまざまな苦労を重ねてきました。最近の話では、Kubernetes v1.11 から deprecated となった etcd2 を etcd3 に upgrade する作業に大きな工数をさきました。
もともとインフラチームのメンバーが覚えていられる数の namespace しかなかった頃は、こういった大きな問題に対してはクラスタを作り直して、全サービスを移行するオペレーションを都度行うことができていました。しかし、現在 Wantedly では約40人のエンジニアで、100近くの namespace のあるクラスタを管理しているため、クラスタを全移行するオペレーションは簡単なものではなくなりました。Wantedly では 1 repository 1 namespace を convention としているため、100近くのマイクロサービスがあることになります。もともと手作業で行えていたものが100近くになるととたんに手に負えなくなります。ここで我々が管理するクラスタには簡単に引っ越しのできるポータビリティが充分でないことを強く認識しました。
クラスタのポータビリティとはなにか? では Kubernetes クラスタがもつべきポータビリティがどのようなものか議論してみたいと思います。
ざっくり考えるとポータビリティとは持ち運びの容易性のことですから、ひとつは「今と異なるインフラに簡単に乗せることができる」という性質でしょう。つまりは引越が簡単であるという性質が重要であるということです。クラスタを再作成しないといけないときに簡単にできたり、たとえ今オンプレミス上で構成していても、簡単に GKE や EKS に移動できたり、といった性質があるとポータビリティが高いと言って差し支えないでしょう。ここで言う引越のしやすさというのは、そのクラスタ上で運用されるアプリケーションの移動を含んでいます。
サービスが1個しかないクラスタと100個あるクラスタでは、仮に利用するコンポーネントの種類や node の数が同一でも後者のほうが基本的に難しくなります。エンジニアリングチームがスケールして大規模なクラスタ運用となったときにもクラスタの移動が容易になっている必要があります。そこで今回ポータビリティとは「クラスタの規模に対する異なるインフラへの移動の容易さ」と定義することにします。
12 factor app という存在 サーバーサイドアプリケーションにおいては 12 factor app のようなポータビリティを保つ上で手本とするべき設計の指針があります。
Wantedly では Kubernetes 導入にあたり、すべての既存サービスの載せ替えを行いましたが、もともとほとんどのサービスが 12 factor app の指針に従っていたため根本的な改修が必要なものは少なく、検証や計測の後に順次移行していくことができました。12 factor app を守ることが実際にアプリケーション単位でのポータビリティを向上させていた、と主張できるでしょう。
このようにアプリケーションを作成する際には手本となる指針があるのに対し、Kubernetes クラスタやより大きく捉えてインフラのようなものを設計/運用する際の指針としてまとめられたものがないという現状があると考えています。Infrastructure as Code, Immutable Infrastructure など時代の流れとともに様々な考えがインフラ界隈に広がっていますが、これだけ守っていればとりあえず良いという指針が存在していないわけです。少なくとも筆者の中では広く常識化されたものはないという認識があります。
Beyond the 12 Factor App のように Cloud Native 時代に合わせて 12 factor App に対する改良案もあります。しかしながら、これもアプリケーションレイヤーの規約の議論を行っているもので、インフラ自体の規約についてはやはりうまくまとめられていないというのが現状です。我々 Wantedly はこれがなかったために今回の etcd3 への移行で苦労を強いられたと考えました。
次のクラスタ移行を行うのがいつになるのかはわかりませんが、確実に訪れるものだと思っています。我々は導入時の背景から EC2 上にKubernetesクラスタを構成していますが、EKSやGKEへの移行も都度検討しています。こういったマネージドのサービスに移行しようと思ったときに負債のために立ち止まりたくはありません。
機動力を持って変化に強いインフラを維持していくにはクラスタのポータビリティを保つ指針が必要です。そのときに困らないように、今回の移行で障壁となったものを洗い出し、そのような問題が入りにくいクラスタ運用指針を考えてみたいと思います。これはもともと社内で考えていましたが、より多くの人に知ってもらいフィードバックをもらうことでさらによいものにしたいという気持ちがあるためこの章でまとめようと思います。
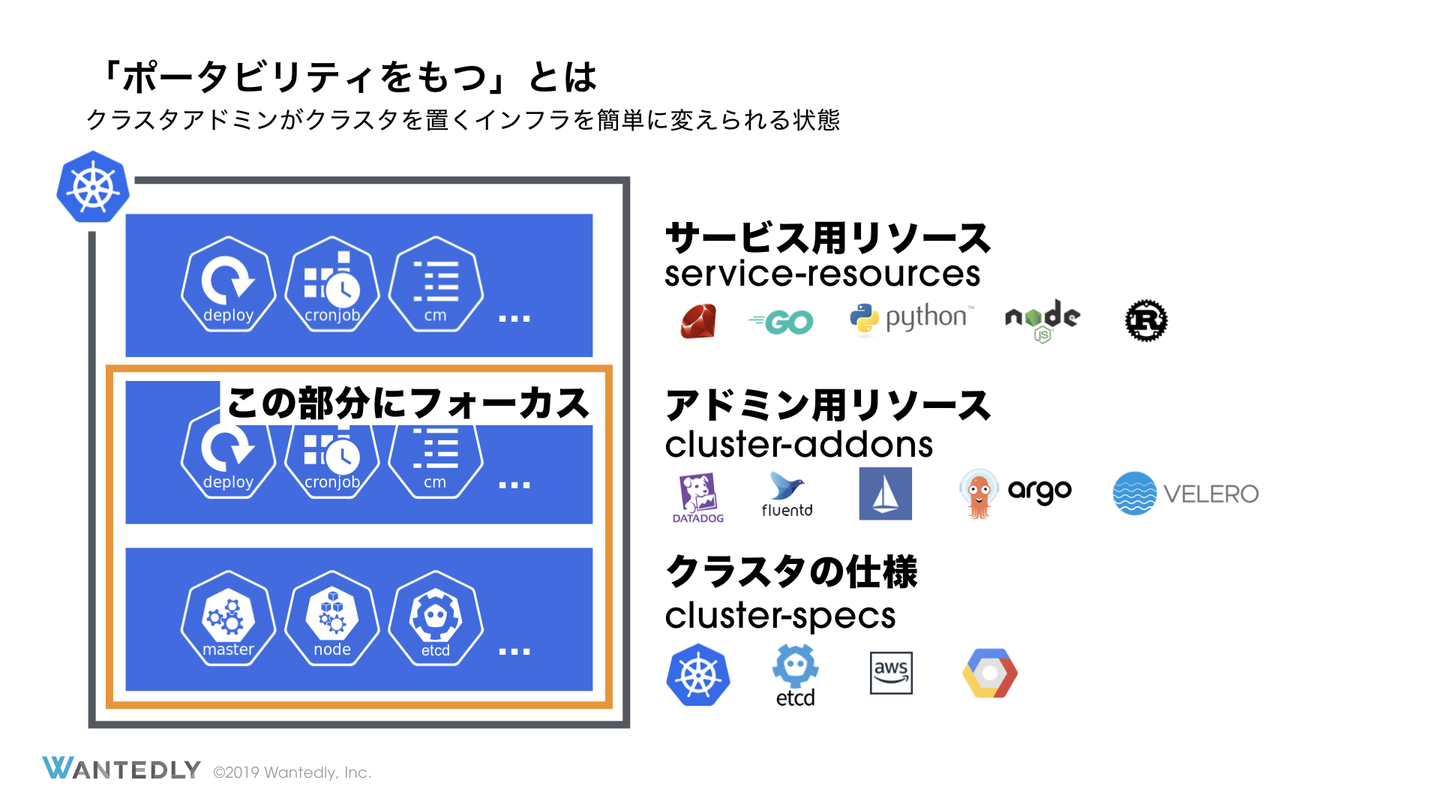
Kubernetes クラスタのスコープ 先ずは、今回ポータビリティを保つ対象を明らかにしたいと思います。
クラスターのスペック まず自明に管理対象になるのはクラスタのスペックです。具体的にはクラスタに用いるコンピュータリソースやその物理的な場所などがあります。また、利用する OS や Kubernetes のバージョン、ip レンジなども含まれるでしょう。クラスタを移行するという決断に至ったとき、多くの場合このスペックのほとんどが同一のものを作りたいと考えるでしょう。
アプリケーション用リソースの中身には基本的に関知しない 空っぽのクラスタのポータビリティが上がったからと言ってこれだけでよいわけではありません。素のクラスタの上に監視用のツールを導入したり、認証認可のための仕組みを管理したくなります。これらの多くは Kubernetes のリソースとして定義されるため、リソース管理にも踏み込む必要があります。しかしすべてのリソースの管理まで手を広げると、それは Kubernetes にデプロイする実際のアプリケーションの管理まで手を伸ばすことになり、管理は非常に大変になりポータビリティを保つという問題はまったく簡単になっていません。今回興味のあるポータビリティは Kubernetes というインフラ部分のみです。つまりアプリケーションエンジニアがどのような Web サーバー や Job のためにそのクラスタを利用しているのかには関知しないということです。
もちろん移行に際しては、アプリケーション用のリソースも移動させることになります。しかし、それは「Deployment や Service といった単なるリソースを移行させる」のであり「特定のアプリケーション x を移行させる」のではありません。もちろんアプリケーションの中身に関しても指針を示したり、一定のルールを設けたりすることは必要に応じて行うべきでしょう。しかしながら、アプリケーションの中身としてどんなものがあるかには基本的に知識を持たずにインフラ移行が行えると理想的です。
クラスタ維持のためのリソースに集中する アプリケーション用のリソースを除き、残ったアドミン用のリソースはクラスタの再作成時にも同一のものを利用したいという要求をもつことが多いため管理対象です。クラスタの利便性や安定性を保つためのリソースはサービス部分とは独立して存在し、またアプリケーションエンジニアの興味の範囲外になることがほとんどでしょう。具体的には Datadog, Fluentd, Argo, Istio などがあります。
背景にあるインフラの考え このように線引を行う背景には Wantedly のインフラについての根本的な考えがあります。
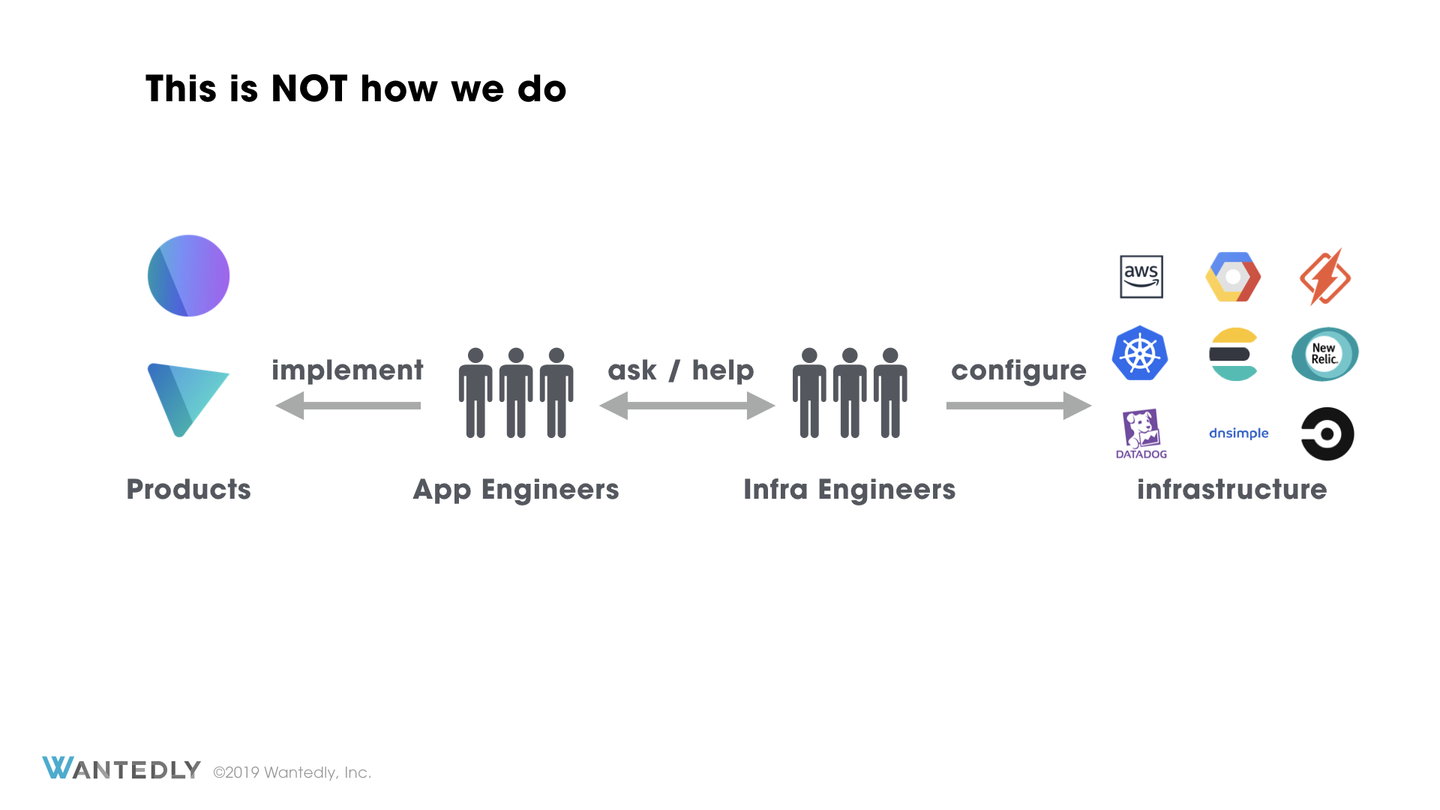
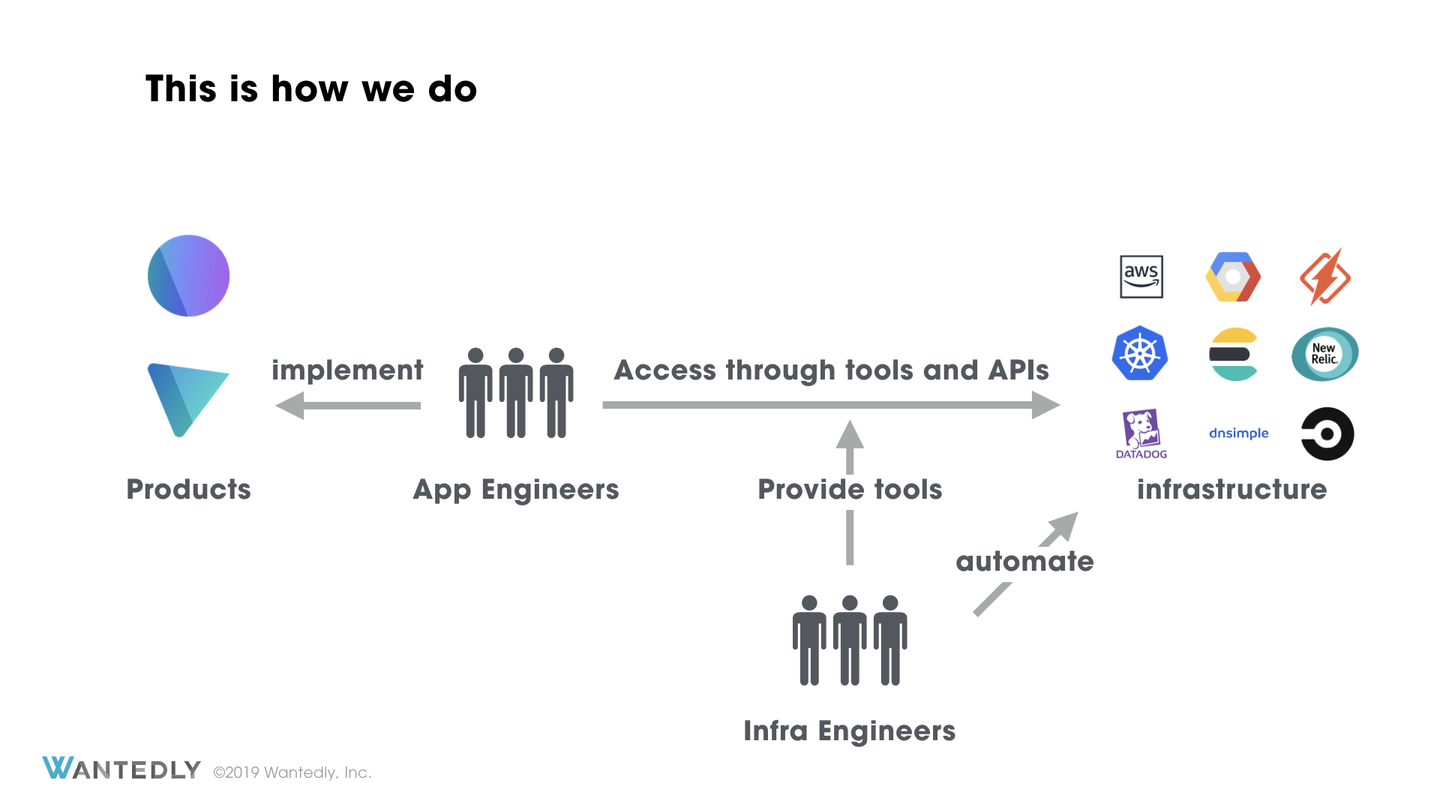
Wantedly ではインフラエンジニアとアプリケーションエンジニアの疎結合を目指しています。もちろん現時点の40人という規模では密なコミュニケーションはしばしば重要ですが、最終的にスケールしていくためにはインフラチームは基盤の作成及び運用に徹して、アプリケーションエンジニアがインフラエンジニアの存在を一切意識することなくプロダクトの開発を行えるようになるべきであるという考えを持っています。
このような理由からどのようなサービスがデプロイされているかどうかについては知らなくてよい状態を目指しています。サービスのための Deployment, Service, ConfigMap などはアプリケーションエンジニアの管理するものであり、インフラエンジニアが管理するものではないということです。したがって今回提案する原則ではこのようなサービス運用部分には踏み込まず管理外とします。
どのような要素をもつべきか
社内のクラスタ移行の経験と 12 Factor App から私達が考えた守るべき8要素は下のようにまとめられます。
コードベース: 設定はすべてコード化する 依存宣言: 依存するコンポーネントのversionは宣言する 設定: コードベース内外に保管して注入する 単一方向ビルド: コードベース -> クラスタの一方向にする 環境一致: コードベース -> クラスタの一方向で作成して際は設定に留める 非名前管理: ラベル / エイリアスを使う バックアップ: リソース定義を復元可能な状態で保管する 重複欠損管理: 重複と欠損のいずれかのみを守る 最初の5つは 12 Factor App と共通のエッセンスをもつもので 12 Factor App を大いに参考にしました。最後の3つはインフラ特有のもので新たに考案したものです。それでは実際に各項目の内容を詳しく説明していきます。
1. コードベース まずはクラスタの設定を宣言的に管理することです。アプリケーション開発においては自明のことであると捉えられていると思いますが、クラスタの設定も同様です。Infrastructure as Code の考えからしてもクラスタの設定を1つのコードベースで version 管理するのに違和感はないのではないでしょうか。
Wantedly で用いている Kubernetes クラスタのデプロイツールここでクラスタの設定と言っているのは kops における Cluster kind のリソースのようなクラスタのメタ情報のことを指しています。具体的には利用する EC2 インスタンスのタイプ、用いるベースイメージ、利用する Availability Zone などの設定が含まれるでしょう。各種 namespace で利用される Deployment, Service, Ingress などはまた別のその namespace の責務をもつべきであると考えています。これはクラスタの管理とそのクラスタを利用するリソースは疎結合であるべきであると考えているためです。
このことにより、クラスタ管理者の責務とサービス管理者の責務を明確に分離できます。もちろん、Dockerfile まで用意したサーバー管理者が Kubernetes におけるリソースの宣言をどこまで行うべきかという問題については議論の余地があると思います。ただ、クラスタ管理者が責務をもつ設定ファイルは1つの、それ専用のコードベースで管理されるべきであると考えています。
2. 依存宣言 こちらもアプリケーション開発においては当然のものとして行われていることであると思います。Kubernetes クラスタを作成する際の再現性を保つために依存するコンポーネントの version を固定することは非常に重要です。AWS の EC2 インスタンスでクラスタを構築する場合、cluster-autoscaler や alb-ingress-controller などのコンポーネントが必要になることがあるでしょう。このようなコンポーネントの version をコードベースに保管しておくことが重要です。
3. 設定 コードベースと設定の緩やかな疎結合が重要であると考えています。設定とはすでに述べたようなコンポーネントのバージョンやそれらが必要とするクレデンシャルのことを指します。
このような値を環境変数として保管するのがアプリケーションにおいては一般的であると思います。ここでは設定値を利用する際に最終的に環境変数として扱うのか、ファイルとして扱うのかは規定しません。あるコードベースから設定値を注入するというレイヤーを導入することが重要です。このことより、環境ごとの差異をコードベースの変更なく行うことができます。
Kubernetes クラスタを構築する場合多くの場合1つのクラスタのみの運用から始めることが多いのではないかと思います。ここで設定をすべてハードコードしてしまうことが多々ありますが、複数環境を用意することを想定して設定値を注入するレイヤを設けておくことで小さいコストで複数環境を構築することができます。設定値には概して秘匿するべき情報が入ることがあるでしょう。このことを想定した上でコードベースの外に設定値を保管する場所があると利便性が増すと考えています。
4. 単一方向ビルド ビルドではコードベースからクラスタのデプロイ/アップデートへの過程を規定します。重要なのはこれが1方向であるべきであるというものです。クラスタを新たに作成するときや既存のクラスタの変更を行うときは、コードベースに設定値を注入したもの(これをビルドと呼ぶことにします)によってクラスタを置き換えることで行います。具体的には node の入れ替えによって行う rolling update を行うことになるでしょう。
ただしこれについては、さまざまな議論があると思います。クラスタ内の変更をコードベースにフィードバックすることでコードベースとバックアップを兼ねるという手法も知られています。クラスタに問題が起こったときにの再作成はこのような手法のほうが早い一方意図しない変更がコードベースに入る可能性を許容する必要があります。
この点に関してはどちらの方法をとるかはクラスタ運営者に委ねるところかなと考えています。しかしもしどちらを取ればよいのか決めかねる場合は、コードベースからクラスタへの1方向のデプロイはシンプルな運用フローを提供できるため選択肢に入れてよいのではないかと考えています。
5. 環境一致 ここまでで設定分離とデプロイ1方向の性質を保てていれば、複数の環境を構築するコストが下がっているでしょう。クラスタを運用するにあたって検証環境が必要になったときに簡単に作れるようになっているはずです。新たな設定値セットを作成し、デプロイを行うだけで新たなクラスタを構築して検証が行える環境は本番環境の信頼性を保つために重要です。ここで本番環境と検証環境の差異をできる限り小さくしておくことで予期せぬ問題を生じる可能性を下げることができます。
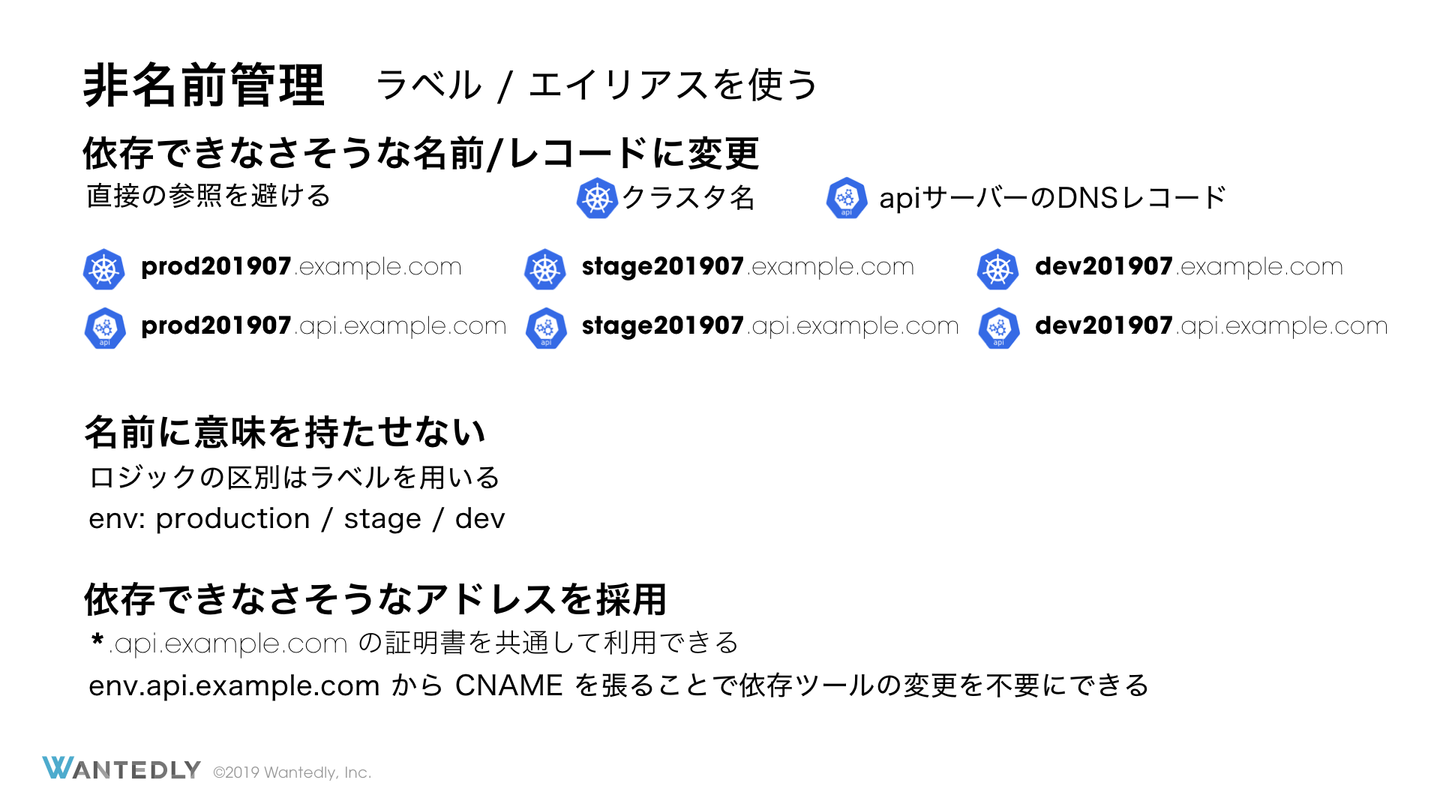
6. 非名前管理 クラスタは廃棄が容易であるべきです。廃棄が容易でないクラスタはポータビリティが低く、クラウドベンダーへのロックインを生じてしまいます。また、今後破壊的な変更が Kubernetes に入ったときにクラスタの再作成が必須になった場合にクラスタ名を決め打ちしていると各種監視などの設定をすべてやり直すことになります。これを避けるためにラベルによる管理でクラスタの複製や再作成に耐えられる状態にしておくことが重要です。
ラベル管理ができないリソースを管理したい場合にはどうしたらよいでしょうか。たとえば AWS で構築している場合には alb-ingress-controller が作成した ALB を管理する必要があります。ここでどの FQDN にどのドメインをアサインするかを管理するときに FQDN などを設定ファイルにハードコードすると大規模なクラスタの成長したときに収集がつかなくなります。直接公開するDNSを自動で設定する設定にしておくとこの問題は減りますがこの対応が取れないこともしばしば発生します。
そこで、エイリアスとなるCNAMEを自動で作成しておき、そのエイリアスを通してクラスタにアクセスするようにすることでこの問題を回避できます。エイリアスが自動で設定され、もしクラスタがすべて破壊されて再作成されても通常のデプロイ方法を再試行するだけでクラスタ環境がすべてもとに戻る環境にしておくことが重要です。
6.1 Wantedly で生じた名前管理による問題 Wantedly では production, stage, dev の3つの環境があり、それぞれで差分の小さいクラスタが運用されています。それぞれ名前は <env>.cluster.example.com, API サーバーのエンドポイントは api.<env>.cluster.example.com としていました。たとえば stage 環境では stage.cluster.example.com, api.stage.cluster.example.com などとなっています。
この名前があまりに恒常的に使えそうな雰囲気を醸し出していたために Datadog や Pagerduty の分岐に「クラスタ名が 〜〜 の場合は 〜」といったような条件分岐が随所に使われていました。クラスタ移行のタイミングで一時的に同一設定のクラスタが2つ建てられることになりますが、名前は同一にできない制約がありました。この結果、新しいクラスタに同一の監視条件を適応するためにすべての監視条件を洗い出す作業を強いられました。
これを踏まえて今後は <env>-<date>.cluster.example.com という名前と <env>-<date>.api.cluster.example.com というエンドポイントを用いることにしました。まず名前にdateを入れたのは、名前に依存してはいけないことを暗に示すためです。これいこう監視はすべてラベルベースの物に変えました。api のエンドポイントには同様の変更に加えドメイン中の api 部分をより後ろに持ってくることにしました。これにより <env>.api.cluster.example.com から <env>-<date>.api.cluster.example.com への CNAME レコードを管理することで複数のクラスタのスイッチを同一のワイルドカード証明書で行えるようになりました。今一度「同一の環境のクラスタをそれぞれ複数用意しても壊れない状態であるか?」を確認するとよいでしょう。
7. バックアップ 今回スコープとしてははじめに述べたとおり、サービスとしてデプロイされているリソースの管理は範疇外です。しかしながら、サービス用のリソースもバックアップを一箇所に取っておくことをお勧めします。Wantedly では velero ^velero を使ってバックアップを取っています。他の手法としては、そもそもすべての yaml を1つの repository で管理させて、repository 自体をバックアップとして機能させるといった方法もあるでしょう。
達成するべき要件は、「クラスタの再作成が必要になった場合に全リソースを同一の状態に復元できる」で、これが達成されていればどのような手法でも構いません。これは 12 Factor App では扱わない領域であると考えます。Kubernetes におけるサービス用のリソースは一般的なアプリケーションにおいてデータベースの内容のようなものです。管理者は「何が許容されて何が許容されないのか」ということには関心を払うかもしれませんが、実際に使われているものや保存されている内容のひとつひとつには感知しません。
アプリケーションの設計論にバックアップは登場しませんが、クラスタのポータビリティを高める運用のためには必要な重要な要素です。アプリケーションにとってデータベースはアタッチされるリソースですが、Kubernetesの場合のデータはクラスタ内に保管されているため、ある意味ではそのデータベースも管理の対象内に入るためです。また、バックアップを取る場合、定期的に復元の試験を行うとよいでしょう。具体的には staging 環境は daily で本番のバックアップからのレストアで再作成するなどです。
もちろん最初はさまざまな課題のある手法ですが、「何かが壊れていたら絶対に気づく」という仕組みを構築するのは堅牢なシステムを運用するにあたって非常に効果的な手法であると思います。
8. 重複欠損管理 重複欠損管理とは重複と欠損のいずれかしか保証できないということを前提におき、どちらを守るのかを明確にするということを指します。ここで重複とは本来1つしかないことを前提にしているものが複数できること、欠損は特にダウンタイムというニュアンスです。
一般的な web サーバーや worker のようなステートレスなプロセスにおいては、クラスタの移行時に単純に2箇所にコピーすれば問題にならないでしょう。このようにステートレスなプレセスにおいては重複は問題になりませんが、欠損は問題になります。したがって重複のみを許容することになります。
次にステートフルなリソースについて考えてみます。Kubernetes クラスタにステートフルなものが置かれることをできる限り避けるべきです。redis や Elasticsearch を Kubernetes 上で管理することは短期的には魅力的ですが、長期的にはクラスタの移動を妨げます。もし同期的な書き込むが必要な PostgreSQL や Elasticsearch がクラスタで運用されていた場合、クラスタ移行は困難になります。クラスタを2つにコピーしてから古い方を消すという手法がとりづらくなってしまうためです。クラスタ移行の際にすべてのクラスタ内DBのリードレプリカを作成してマスター昇格を行うと言った操作はスケールしません。できる限りクラスタ外に出す努力をするべきでしょう。実際に Wantedly では StatefulSet の利用を基本的に禁止しています。
しかし、実際にステートフルなもの完全に排除するのはなかなか難しいものがあります。たとえば CronJob や Job といったリソースは実行されたか?というステータスをクラスタの中で管理しているためステートフルということができます。このステートはクラスタの中で閉じているため、クラスタを2つにコピーすると2重実行が生じます。これを避けるために CronJob や Job といったリソースの使用まで禁止するのはかなり本末転倒です。そこで多少なりともステートを持ったリソースの管理は必要になります。
ステートフルなものも重複してよいケースがあります。たとえばキャッシュの場合は2箇所に分散しても大きな不整合は起きにくく、検索エンジンのインデックスは多少の遅延が許容されるため一時的に書き込みを止めてもよいでしょう。このようなものも欠損を避け、重複を許容することになります。対してプロダクト全体として1回しか動かしたくない ETL や通知などの Job については重複を許容したくありません。このようなステートレスの管理が求められる場合にはダウンタイムという欠損を許容し、重複を避けることになります。これについては、もし可能であればすべてのリソースが重複可能になっていると非常に考えやすくなるため、すべての Job を冪等に作るなどの試みが可能であれば取り組むとよいでしょう。
Wantedly ではすべてのリソースで 重複と欠損のどちらを守るかをラベルで明確に指定する 運用を開始しました。これによりクラスタの再作成時には、欠損が許されないものをまず最初にコピーして、重複が許されないものをコピー元から削除、最後にコピー先で再作成とすることでこの重複と欠損の問題に対応しています。この手法でスケールするのはマスター昇格のような特殊な操作を要求するリソースがクラスタ内に存在しないということが社内ルールから言えるためです。このようなフローを実現するもステートの排除は検討に値する選択肢であると考えます。
8.1ステートを諦めるのが正しい道か? Wantedly ではステートをできる限りクラスタ内に持たないことを選択しましたが、これは世の中の最新の常識と照らし合わせても正しい道といえるでしょうか。実のところ Kubernetes でステートを持ったリソースを管理する試みはさまざまな場所で行われており、うまく運用すれば現時点で Kubernetes とステートの相性は決して悪いものではありません。
しかし、データベースのようなステートを持ったリソースの管理は我々の興味の範疇外であることがほとんどです。クラウドプロバイダーに管理のほとんどを任せて、自分たちはそれらのアクセスできさえすればよいという状態になっています。ステートがないほうが楽であることには間違いないので、もし Kubernetes の中でステートを管理したくなったら「他の方法は本当にないのか」を今一度検討してみることをお勧めします。また、仮にデータベースをデプロイする対象として Kubernetes を選ぶ場合、他のアプリケーション用のクラスタと分離しておくことが懸命かと思います。
おわりに 今回紹介した8原則は、必ずしもすべての Kubernetes 管理者が守るべきである完成されたものではなく、あくまで Wantedly に似た状況に置かれた管理者に対する提案という比較的弱い主張です。しかしながら、ここで守っていきたい「いつでも今使っているクラスタと同一仕様の別の場所に移ることができるか?」ということを考えていく上で一つのたたき台になりうるものだと考えています。少なくともこの8原則から逸脱する場合、逸脱する理由を明確にしておくべきだと考えます。
よりこの提案を一般に通用にするものにしていくべく、様々な方からフィードバックや議論の機会が与えられると非常に嬉しく思います。発展の止まらない情報技術の世界で、より良い知見が広く共有されることに少しでも協力できたらと期待しています。
より詳しい説明については下のリンクから発表動画を参照できるので更に詳しく知りたい方はぜひご覧ください。



/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


