はじめに こんにちは,Wantedlyでエンジニアインターンをしている妹尾です.
大学では,「深層強化学習」を専門に研究しています.深層強化学習については,昨年の「全脳アーキテクチャ若手の会」で発表した資料がありますので,よろしければこちらも参照してみてください.
Wantedly では,「推薦」を主に扱うチームで,論文のサーベイやアルゴリズムの実装を行なっています.今回は,Wantedlyで 「ディープラーニングを用いた協調フィルタリングのアルゴリズム」 を実装した話とその経緯についてお話ししたいと思います.
背景: 機械学習を用いた推薦の導入 Wantedly のサービスには, 「高い推薦精度」 が必要とされる箇所が多数あります.例えば,ユーザーが「自分に合う募集や会社」を簡単に見つけられる様にする為には検索精度や推薦精度が重要ですし,「気になるフィード記事」を見つけやすくする為にもやはり推薦精度は重要です.また,企業が一緒に働きたいと思うユーザーを推薦によって簡単に見つけられるようになれば,「スカウト」が増えて企業とユーザーの出会いの数が増えていきます.さらに,名刺管理アプリの Wantedly People についても,最近は「話題」機能を提供していて適切な「話題」をユーザーへ推薦することが重要になっています.
この様に,Wantedly のサービスにとって推薦の精度を高める事は極めて重要で,最近ではその為のアプローチとして機械学習を導入しています.僕のいるチームでは,推薦手法の1つとして,ECサイトやNetflixなどのサービスで広く使われている 「協調フィルタリング」 を用いた推薦の導入に取り組みました.
協調フィルタリング(Matrix Factorization)を用いた推薦 協調フィルタリングはユーザーとアイテム間のインタラクションから,未知のユーザーとアイテムのインタラクションを推定するアルゴリズム全般を指します.特に有名なアルゴリズムとしてMatrix Factorization (MF)が挙げられます.仕組みについてはCourseraでAndrew Ngさんが丁寧に教えてくれています.
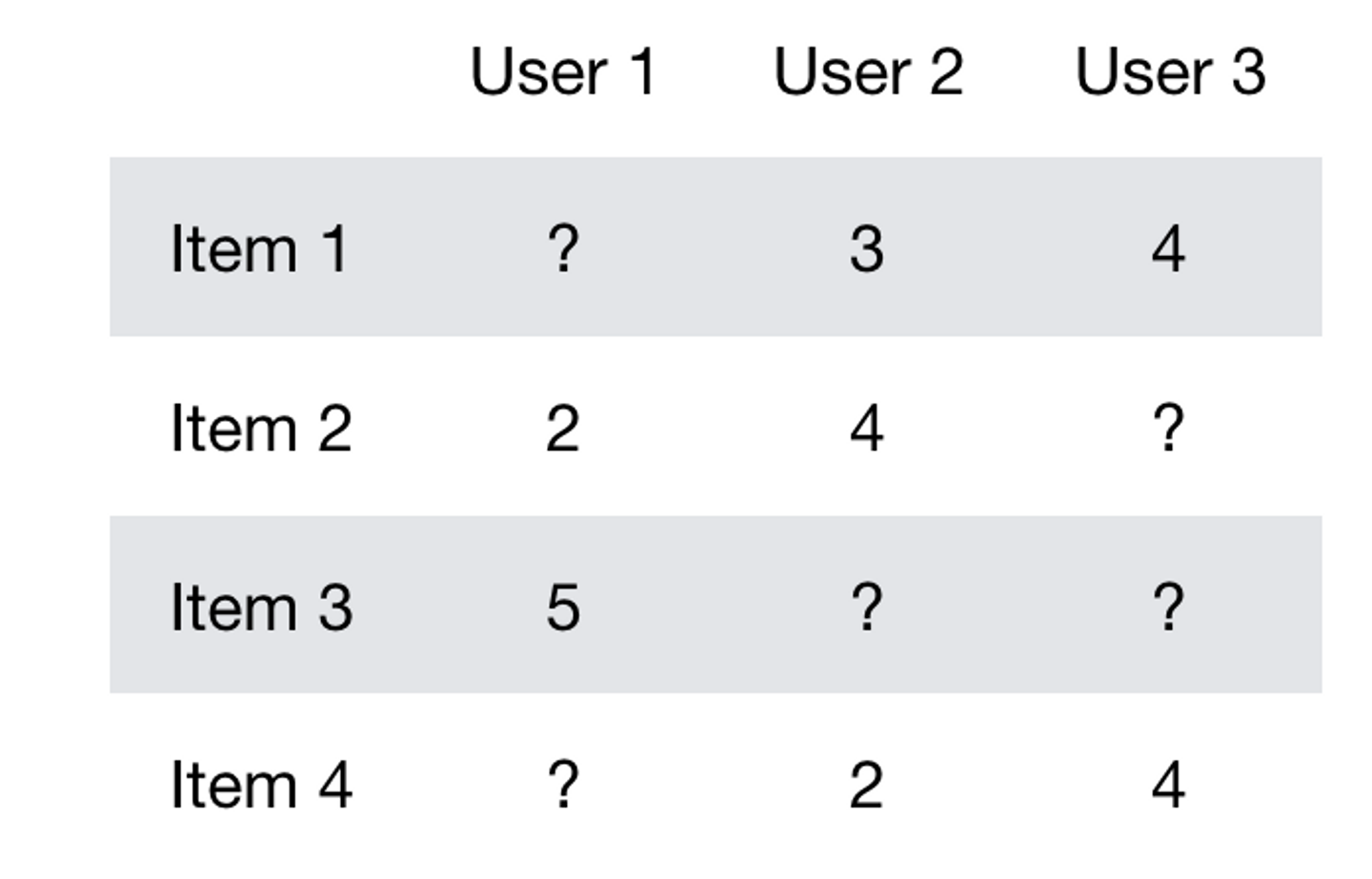
簡単に説明すると,ユーザーが各アイテムについて評価した値をマトリックスで表現します.この時未知の部分は?としておきます.
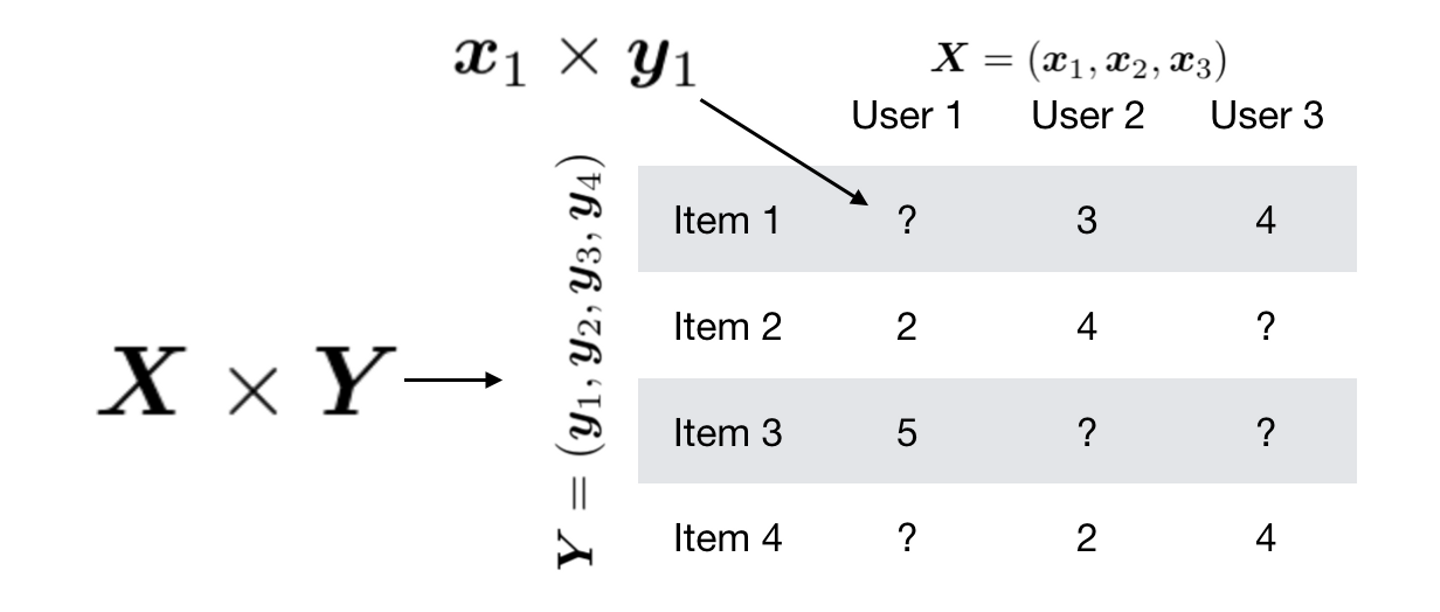
このテーブルがユーザーベクトルxとアイテムベクトルyの積であるとして,このテーブルの再構築誤差を縮めるようにベクトルの学習を行います.
これによって得られたベクトルを用いて未知のアイテムに対するインタラクションを推定することで,ユーザーに対して評価値が高いであろうアイテムを推薦することができます.
Pythonのライブラリであるscikit-learnには,マトリックスの中身が非負値である場合,ベクトルの値も非負値であるという制約を加えて学習を行うNon-Negative Matrix Factorizationが提供されているため,気軽に実装することができます.
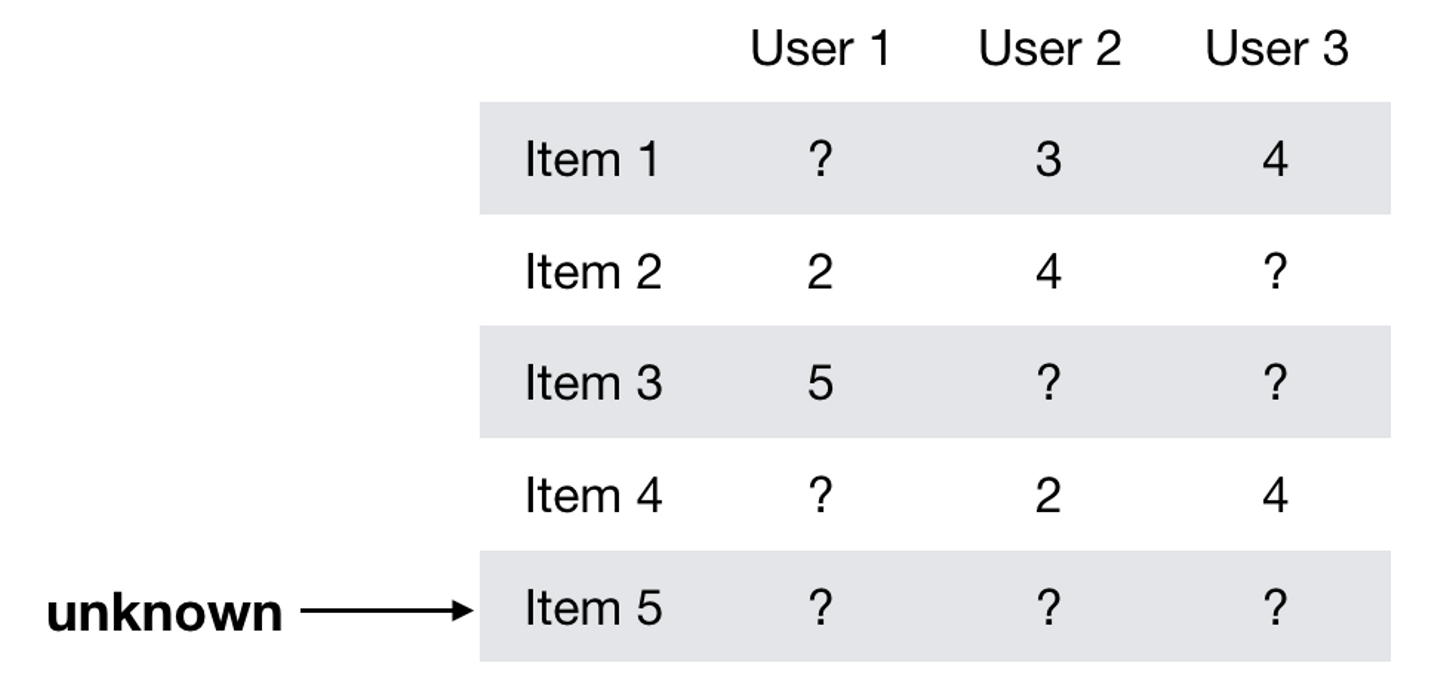
Cold Start問題 みなさんが見てくださっているWantedlyのサービスには部分的にこのアルゴリズムが導入されています.しかしながら,Matrix Factorizationでは一度もインタラクションを行ったことのないユーザーやアイテムに対して推薦を行うことができません.これは 「Cold Start問題」 と呼ばれています.
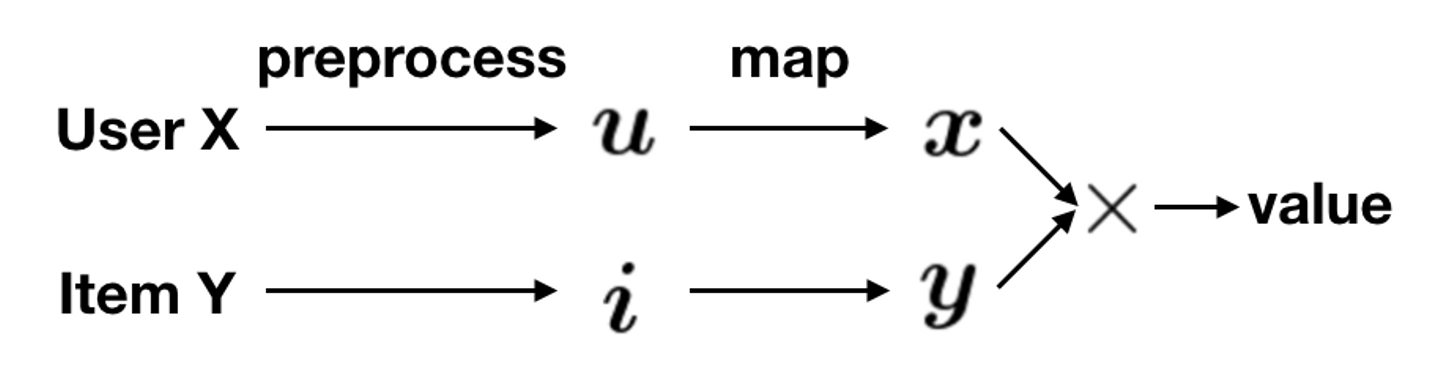
この問題に対しては,コンテンツの内容を用いることで解決するという手法が考えられます.アイテムやユーザーの情報を特徴量ベクトルで表現して,上で説明したユーザーベクトルやアイテムベクトルへの写像を求めることができれば,未知のアイテムに対して推薦を行うことができるはずです.
本題: ディープラーニング(Neural Matrix Factorization)を用いた推薦 ここが本題ですが,今回はCold Start問題を解決するために,ディープニューラルネットワークを用いて協調フィルタリングを行う Neural Matrix Factorization (NeuMF) を実装しました.これは,シンガポール国立大学の方が書いた以下の論文で提案されているモデルです.サーベイしている感覚だと,この大学から推薦アルゴリズムの論文が多く出ているなと感じました.
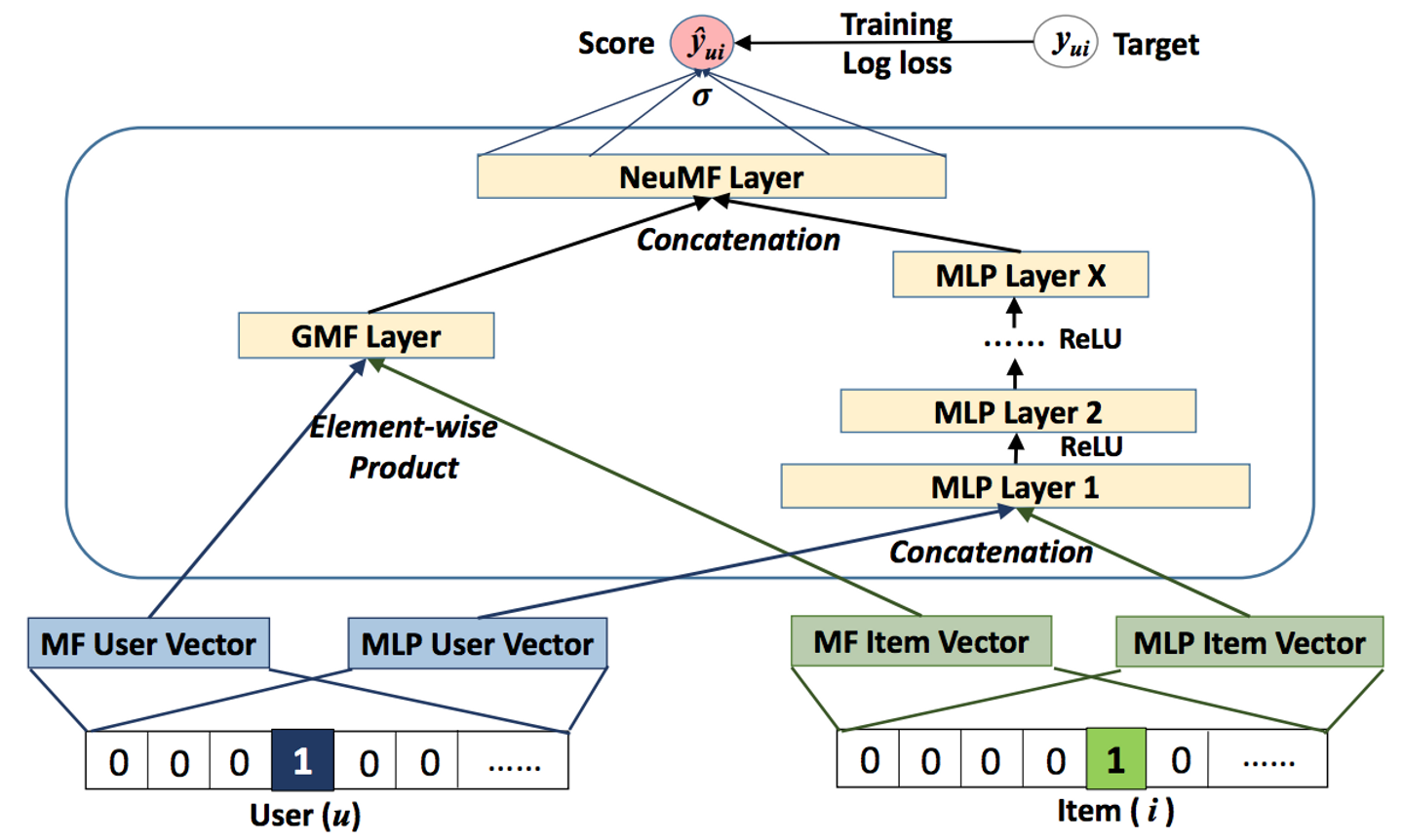
NeuMFはGeneralized Matrix Factorization (GMF)とMulti-Layer Perceptron (MLP)の2つのコンポーネントからなっています(下図は論文中Figure3より引用).
GMFはユーザーとアイテムのembeddingをelement-wiseにかけたものからマトリックスの中身を推定する線形モデルです.これは先ほど紹介したマトリックスの推定とほぼ同じと見なせます.MLPはユーザーとアイテムのembeddingを結合したものから多層パーセプトロンを用いてマトリックスの中身を推定します.
NeuMFではGMFとMLPの出力を結合してマトリックスの中身の推定を行います.線形モデルと非線形モデルの組み合わせはResidualブロックのskip connectionに似ている気もします.また,他に似ているものとしては,論文中でも触れられていますが,GoogleがGoogle Play Storeの推薦アルゴリズムに線形モデルと非線形モデルを組み合わせたモデルを使っていると発表しています.そのモデルはTensorFlowにも組み込まれています.
NeuMFの論文では入力はユーザーIDとアイテムIDのone-hotベクトルで,それに対するembeddingを学習しています.しかし,入力をコンテンツの特徴ベクトルとしても学習できると直感的に判断した(論文中でもできるだろうと言っている)ので,アイテムを特徴量ベクトルで表現したものから直接推定するように実装を行いました.特徴量ベクトルにはプロフィール情報の出現単語をベクトルで表したものや要素をone-hotベクトルで表したものなどを使用しました.
結果としてはL2正則化やパラメータの調整を行うことで,テスト誤差やtop-kで評価を行って精度が出る事が確認できました.これによって Cold Start問題を解決し , 新規のアイテムの推薦を行う事ができるようになりました .
その後の改善 現在も精度の改善を行っています.例えば出現単語をTF-IDFで選択したり,単語をWord2Vecのモデルを使って表現したりなどがあります.学習するときの特徴量が性能に与える影響は,実験した結果やはり大きいなと感じました.
おわりに この推薦機構を入れるために,RDBからデータを持ってくるジョブを実装したり,新規のサーバーを立てたりしました.特にメンターの南さんには学習データの作成フロー周りでとてもお世話になったので謝辞を送らさせていただきます.



/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


