
2023夏インターンのMLOpsコースに参加した戸田です。今回私は推薦基盤チームに配属され、3週間を通して「リアルタイム推薦のための推薦基盤の改善」というテーマに取り組みました。この記事では、そもそもリアルタイム推薦とは何か・なぜ必要かといった背景から始めて具体的に行った内容を紹介し、最後にインターンで学んだことについて述べたいと思います。
TL;DR
ユーザが募集を検索したとき、ユーザの興味関心をリアルタイムに検索結果の並び順へ反映できるようにするために、推薦基盤の改良を行った。具体的には「ユーザが各募集にどのくらい興味があるか」の予測値であるランキングデータに対してバージョン情報を付与する仕組みを考え、既に古くなったランキングデータは使われなくなるようにした。実装した後に検証を行った結果、考案した仕組みは正常に動作しレスポンスタイムの悪化は50ms程度であることが明らかになった。本プロジェクトによって、検索機能におけるリアルタイムな推薦の実現が近づいた。
目次
- 背景
- 問題点
- 実際に行ったこと
- キャッシュの利用状況に関する調査
- 方針の決定とキーの設計
- ランキングのデータの読み出し・保存の設計
- 設計した機構の実装
- 検証と性能テスト
- ランキングのデータを扱う部分の設計の見直し
- 学んだこと
- 設計を考えるときの適切な思考の深さ
- 大規模なコードベースとの接し方
- 感想
背景
Wantedlyでは、募集のトップページの検索機能(下図)などにおいて、多数ある募集を条件に基づいてフィルタリングした上でさらに「ユーザへのおすすめ順」に並べ替えることがよくあります。言うまでもありませんが、上に表示されたものほどユーザの目に留まる可能性が高いため、その時々のユーザの興味関心に合った並び替えをすることは極めて重要です。
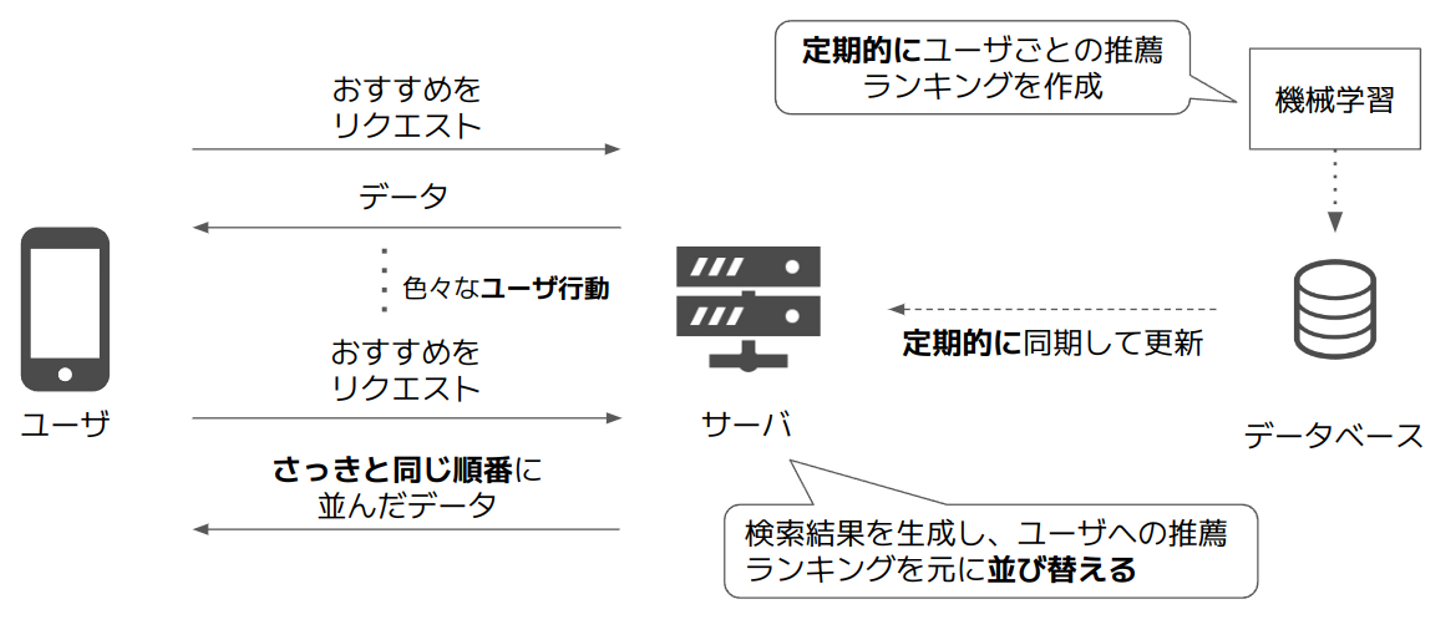
しかし、現状のWantedlyの推薦システムは必ずしもその時のユーザの興味を基にした並び替えが出来ているとは言えない状態になっています。その現状の推薦システムの概要を表したのが下の図です。図から分かるとおり、定期的に機械学習モデルによって「各募集がそれぞれのユーザに対してどれくらいおすすめか」を示すスコア(推薦ランキング)が計算され、それが定期的にサーバに同期されるようになっています。したがって、ユーザが最初におすすめの募集を見てからいろいろなユーザ行動(他業種の募集も見てみる、地方勤務の募集も見てみる等)をとったとしても、ある程度の時間が経つまでは毎回同じおすすめが表示されてしまいます。
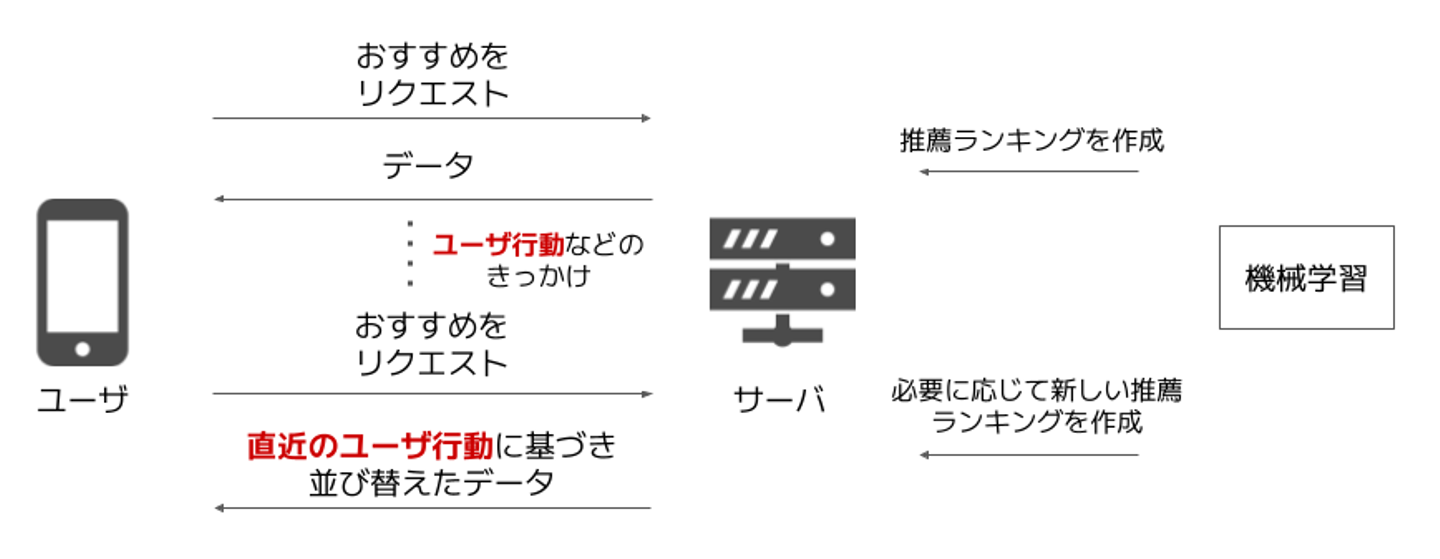
理想的には一定量のユーザ行動に応じてその場で機械学習モデルによるランキングの再計算が行われ、募集を直近のユーザ行動に基づいたおすすめ順に並び替えられる(すなわちリアルタイム推薦ができる)と嬉しいです。イメージとしては、動画配信サービスでいくつか動画を視聴するとそれらに類似した動画がおすすめ欄にすぐに現れるのに似ていますね。
そこで、今回のインターンシップでは上記のようにランキングをリアルタイムで生成し検索結果に反映することを妨げているある問題点について考え、それを修正することで推薦基盤の改良を行いました。
問題点
さてここからが本題です。実は、現行の推薦システムはそのままではリアルタイム推薦を導入することが出来ません。というのも、システム内部では随所で検索結果のキャッシュを生成する仕様となっているため、仮に機械学習モデルがリアルタイムでランキングを生成するようにしたとしても次のようなことが起きてしまうからです。
- ユーザサイドから何らかの検索リクエストが到着する(☆このタイミングで機械学習モデルによってランキングがリアルタイムに計算される)
- 検索結果(検索クエリに基づいて募集を絞り込み、ランキングに基づいてそれを並び替えたもの)が生成される
- 検索結果のキャッシュが生成される
- ユーザに検索結果のデータが送信される
- 少し経ってから、再びユーザサイドから同一の検索リクエストが到着する(★このタイミングで機械学習モデルによってランキングがリアルタイムに計算される)
- しかし、サーバは★のランキングを参照することはなく、前回生成したキャッシュを取り出して使う
- ユーザに前回と全く同じデータが送信される
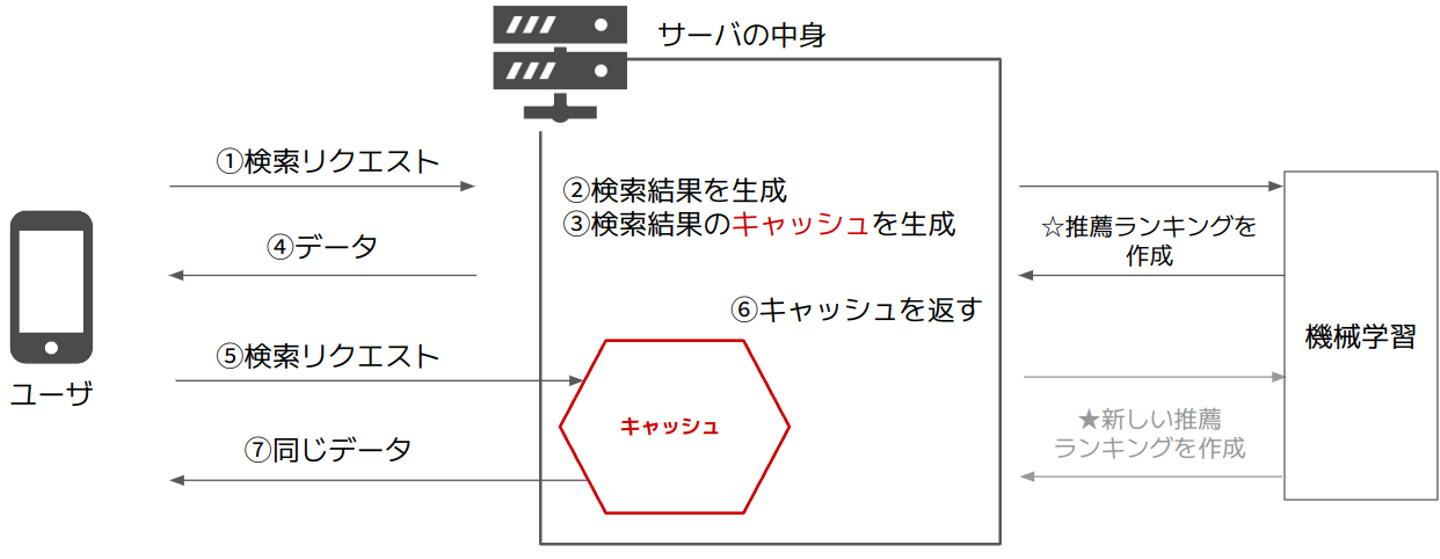
これを解決するためには、状況に応じてキャッシュを使うか再計算するかをその場で判断させること(キャッシュコントロール)が必要になってきます。私はこのキャッシュコントロールに焦点を当て、効率的な実装を考えていくことにしました。
実際に行ったこと
本プロジェクトは次のように進めました。まず、現状の推薦基盤におけるキャッシュの利用状況を調べ、改良すべき箇所の特定とデータの取り扱いに関する設計を行いました。その後に実装を行い、設計した機構が正しく動作していることを検証してから性能の変化を計測しました。結果として設計通りに動作しており性能も問題ないことが分かりましたが、コードの複雑性が上がってしまったため設計の一部見直しを行い、新たな構造体を作ることでコードを分かりやすくしました。以下ではこれらの詳細を順に説明していきます。
キャッシュの利用状況に関する調査
まずは、ランキングに基づいて生成された計算結果のキャッシュを保存している箇所を全て洗い出す必要がありました。推薦基盤は比較的規模の大きなコードベースであり、解読にはドメイン知識が要求されるため、最初の数日間はメンターの方にひたすら質問しながら既存コードを理解することに努めました。
調査の結果、キャッシュを使っていることでリアルタイム推薦を妨げているのは1箇所のコンポーネントであることが分かりました。これは「インターリービング」という推薦アルゴリズムの性能比較手法を実現しているコンポーネントでした。
( インターリービングの詳細についてはこちらを参照してください: https://www.nogawanogawa.com/entry/interleaving )
対応を考える前に、そもそも推薦基盤に本当にキャッシュが必要なのか調べることにしました。すると、キャッシュを消した場合の悪影響として次のようなものが挙がりました。
- オンラインテストを行っている箇所では2つの推薦アルゴリズムに基づくランキングたちをランダムに混ぜ合わせている。この結果をキャッシュしないと、ユーザが検索結果画面において1ページ→2ページ→1ページというようなページ遷移を行った場合に最初に見たときの1ページ目とその後の1ページ目で表示されている募集が全然違うということが起きてしまい、ユーザ体験に悪影響を及ぼす。
- 検索結果の初回生成時の負荷が予想以上に高く、キャッシュを一切使わない場合はユーザがページを移動するたびに長時間待たされることになってしまう。
よってキャッシュ機構自体を消すわけにはいかないということが分かり、キャッシュ機構を残しながらどのようにリアルタイム性を実現するか検討を始めました。
方針の決定とキーの設計
よく考えると、「キャッシュを使わないべき」なのはそのキャッシュが生成されたタイミング以降にランキングの更新が起こったときです。そこで、検索結果のキャッシュ機構に手を入れるのではなく検索結果の基となっているランキングのデータの方にバージョン情報を付与し、ランキングの更新が行われたらキャッシュが使われなくなるように実装することにしました。
上記の方針を採用したのは、ランキングのバージョン情報を更新すれば何もしなくてもそれに基づく全てのキャッシュがヒットしなくなるからでもあります。これがどういうことかを以下で説明します。現在の仕様では、例えば
rankingAという推薦アルゴリズムでユーザxyz向けに生成されたrankingA:xyzというランキングのデータrankingBという推薦アルゴリズムでユーザxyz向けに生成されたrankingB:xyzというランキングのデータ
があったとすると、これらをオンラインテストしている箇所における検索結果のキャッシュは onlinetest:rankingA:xyz:rankingB:xyz のようなキーで保存されるようになっています。すなわち、検索結果のキャッシュはそれを生成する際に利用したランキングのIDを含んでいるわけです。したがって、 rankingA:xyz-20230930102234 のように今までのランキングIDの末尾にそのランキングが機械学習モデルによって生成された日時を付与すると、検索結果のキャッシュのキーは onlinetest:rankingA:xyz-20230930102234:rankingB:xyz-20230930102683 のような形式になります。よって、この上で検索結果のキャッシュを利用する側が現在のランキングの最新バージョンを調べてからキャッシュのキーを構成してキャッシュを検索することで、キャッシュが現時点で最新のランキングに基づくものであった場合はキャッシュがヒットし、そうでない場合はキャッシュミスするようになります。よって、問題は、ランキングにバージョン情報を付与するとして最新のランキングの検索・保存をいかに効率よく行うかということになりました。
ランキングのデータの読み出し・保存の設計
次に、データベース (Redis) から最新のランキングのデータを取ってくるための仕組みを3つ考えました。
1. ランキングのデータの読み出し時に最新のデータを検索する
最初に浮かんだのは、要求されたランキングのうち最新のものを検索して取り出す方法です。これには実装が容易というメリットがありました。
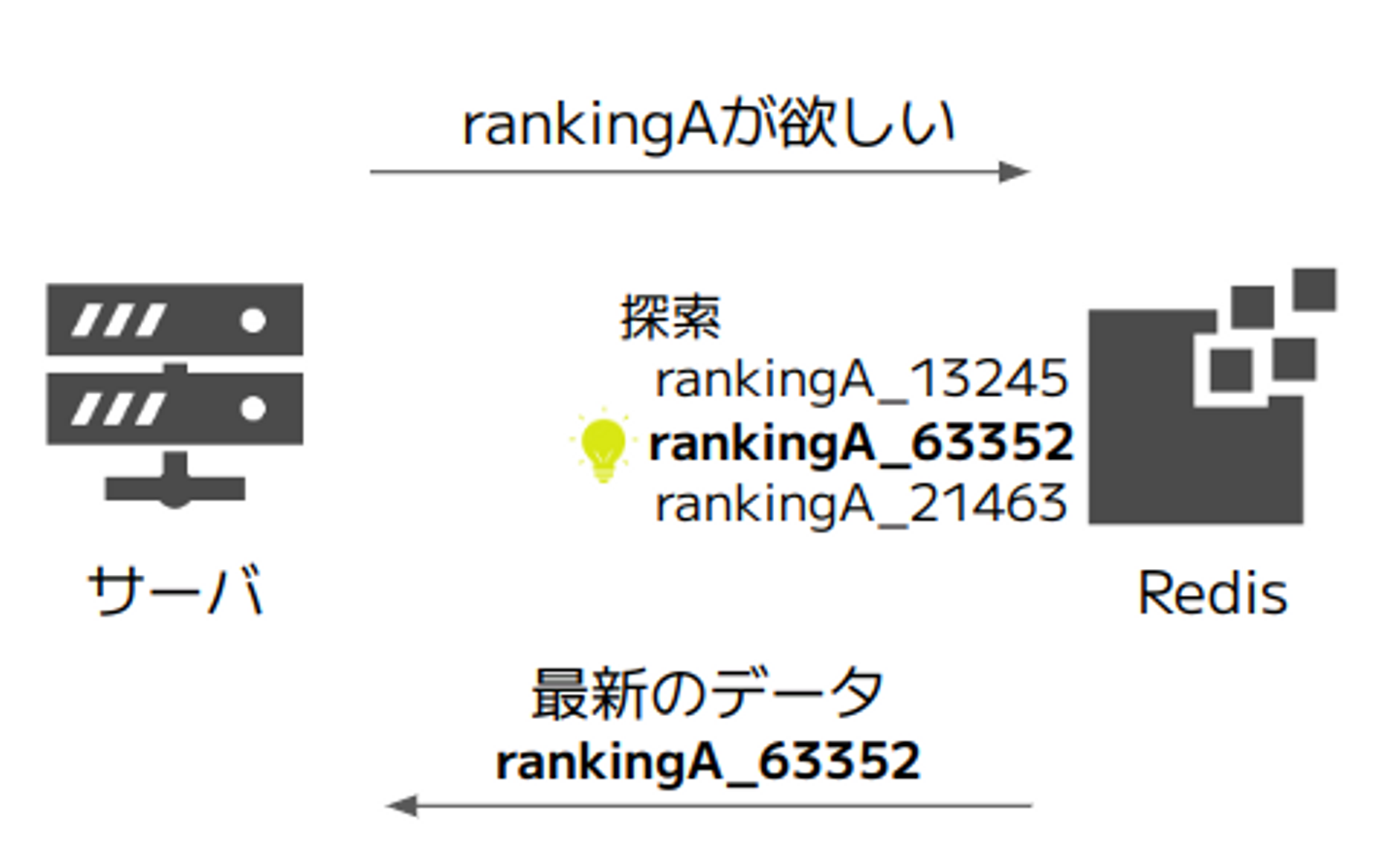
しかし、大量のランキングのデータがある中でこの処理を行うと数十秒レベルの時間がかかることが判明し、その間ユーザを待たせることになるため非現実的でした。
2. ランキングのデータの保存時に既存のキャッシュを全て探して削除する
最新のユーザ行動に基づいた新しいランキングのデータを生成し保存するときに、既存のキャッシュを消して回るという方法も考えました。しかし、やはり探索が必要となるため処理時間が現実的でなく採用できませんでした。

3. 【採用】ランキングのデータの読み出し時に最新バージョンのIDを構築してから取得する
最終的に採用したのは次のような設計です。
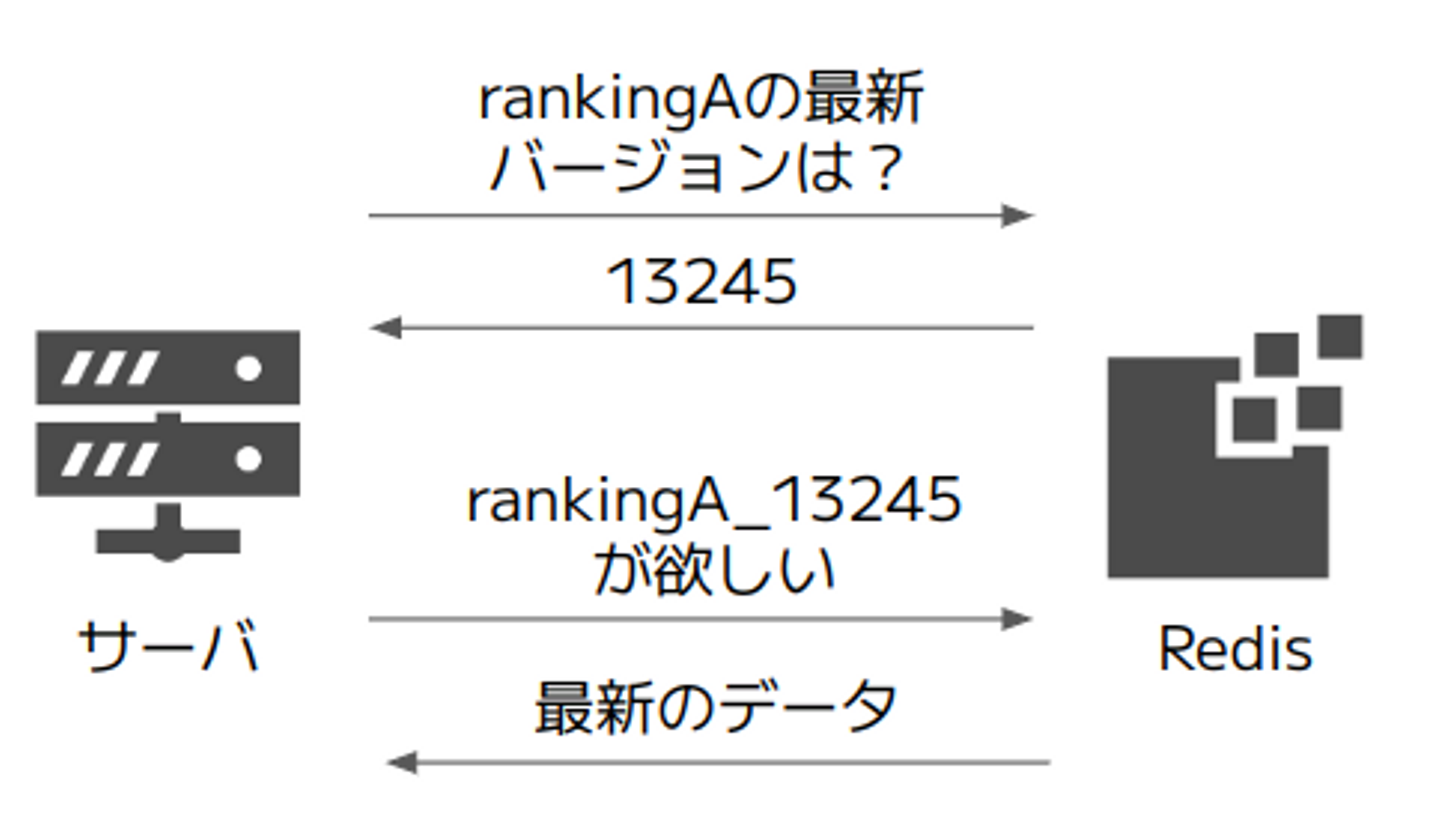
データベース (Redis) に保存する key:value の組として rankingName:latestVersion と rankingKey:rankingData の2種類を用意することによって、例えば rankingA の最新のデータが欲しいときにはまず rankingA でRedisを検索して最新バージョンを文字列として取得し、それを末尾に付与して構築したキー文字列 (rankingKey) で再びRedisを検索することでランキングのデータ本体を得るという2段階の構造になっています。この方式だとデータ取得が2段階になるためそれらの時間差に伴う不整合が起きないように注意する必要がありますが、全ての処理がO(1)であるという他にはない利点があるため、実行時間の観点からこの方式を採用することにしました。
設計した機構の実装
Wantedly Visitで推薦システムを使っているサービスとしてはproject(ユーザは求職者で、いい感じの仕事を探している)とscout(ユーザは採用者で、いい感じの人材を探している)があります。今回はまずscoutに対してリアルタイム推薦の準備を整えることにしましたが、本プロジェクトで実装する基盤は両方のサービスに導入したかったため、容易に再利用可能なコードとするよう気をつけました。ランキングのデータのキーの仕様が変更されるため影響範囲が広く、テンプレートからコードを自動生成している箇所などにも修正が及びました。
検証と性能テスト
手を動かし始めてから1週間強で実装を完了し、正常に最新バージョンのランキングが取得できることと、キャッシュが現時点で最新バージョンのランキングに基づいて作成されたものである場合はキャッシュが使われ、そうでない場合には最新のバージョンのランキングに基づいて検索結果の再計算が行われることを検証しました。
次に性能テストを行いました。このとき偶然MLOpsのもう1人のインターン生がリクエスト再現ツール(本番環境に実際に来たユーザからのリクエストを任意の環境に向かって再生できるツール)を作成するプロジェクトに取り組んでおりそれが動作するところまで来ていたため、実際のリクエストを再現しながら性能テストをすることができました。実験結果として、キャッシュヒットとキャッシュミスが混在する状態でレスポンス時間の中央値が50msほど大きくなることが明らかになりました。50msという数字をどう捉えるかには様々な意見があると思いますが、ランキングのデータのバージョン解決でデータベースへアクセスする回数が増えたことを考えると許容範囲であると思います。これをさらに短く出来るか調べることは今後の課題としたいと思います。
ランキングのデータを扱う部分の設計の見直し
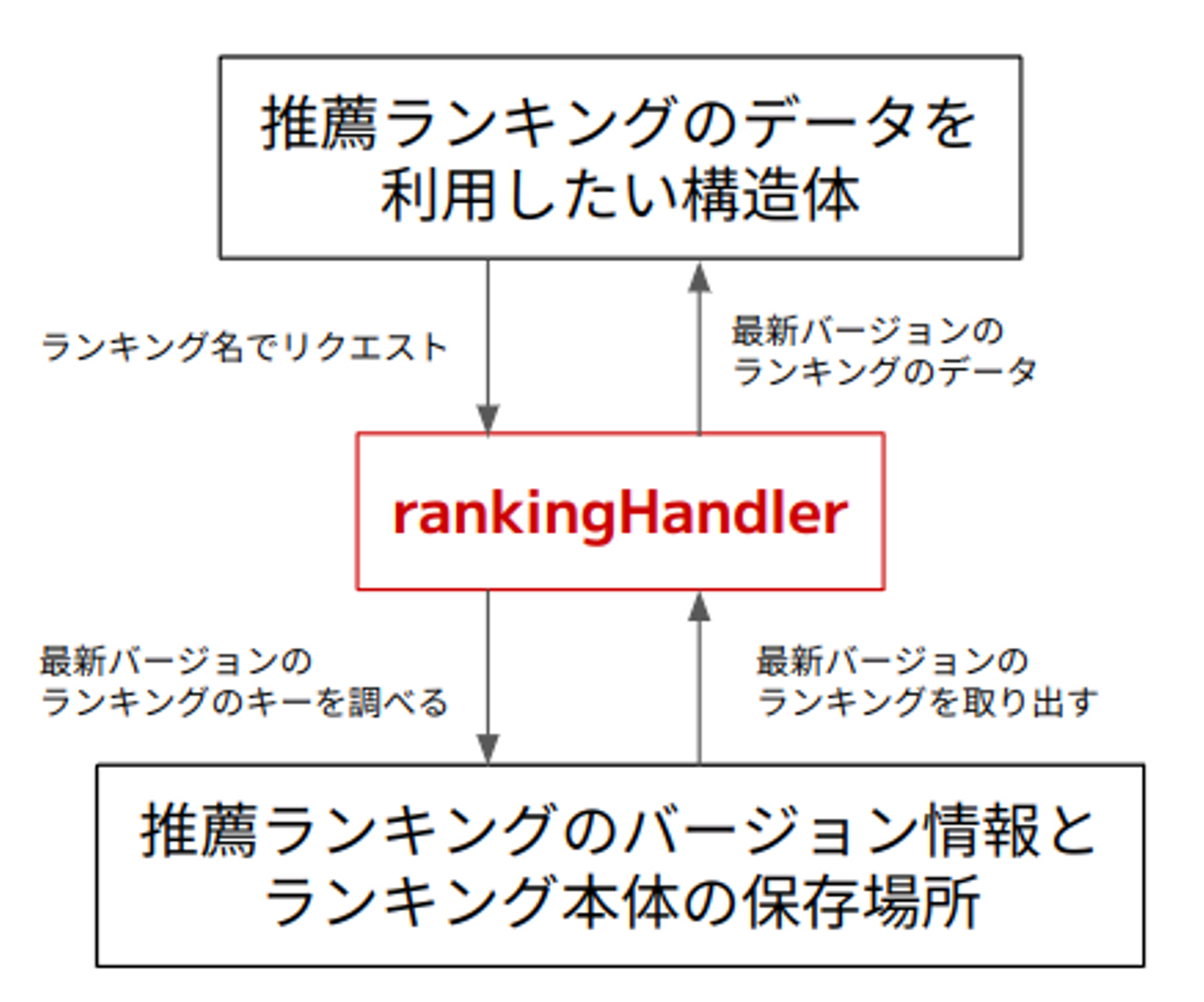
ランキングのデータに正しくバージョンを付与し、最新バージョンの取得も出来るようになったことで一応のプロジェクト目標は達成されましたが、「まず最新バージョンを取得し、次にキーを構築してランキングのデータ本体を取得する」というロジックはコードを一見しただけでは理解しにくいということが課題に感じました。そこで、推薦基盤に新しく rankingHandler という構造体を導入し、これに最新のランキングを解決するメソッドを実装することで、ランキングのデータを利用する側はランキング名だけ指定すれば自動的に最新バージョンが得られるようにしました。これによって、ランキングのデータにはバージョン情報が付与されており最新版を取ってくる必要があることや、ランキングのデータが実際に保存されている場所などの詳細を隠蔽することができ、誤った扱い方をしてしまうリスクが低くなりました。
学んだこと
インターンシップ中にはとても多くのことを学びましたが、その中でも敢えて技術関係以外でメンターの方の指摘で気付かされたことを2つピックアップして述べたいと思います。
設計を考えるときの適切な思考の深さ
今回のプロジェクトでは自分で設計から考えたため、まずはアイデア出しが必要でした。その中で、例えばある案Aが浮かんだときに「案Aのためには○○や××の変更が必要で、それによって△△のような影響がある。いや、でもそこはこうすれば...」という具合に1つの案について延々と深堀りしていってしまう思考の癖(深さ優先思考、とでも呼べるかもしれません)があることが分かりました。アイデア出しの段階では実装がどうなるかを深追いせずに水平方向に広く考える、つまり幅優先で考えることを意識したことで、短時間でいろいろなアイデアを出すことが出来るようになりました。
大規模なコードベースとの接し方
今まで自分が読んできた・書いてきたソースコードというのは、その気になれば全てを読み切れる量のものでした。しかし、実際の業務で接するコードについてはその全てを数日で把握することはほぼ不可能です。したがって読み方を工夫する必要があるのですが、はじめの自分はそれに気づかずトップの呼び出し元からひたすらVSCodeの定義ジャンプを使ってコードを静的解析的に読もうとしており、それで堂々巡りになって混乱していました。また、実装時にも設計の綺麗さを気にしすぎるあまりなかなか手が動かないということが多くありました。それをメンターの方に相談したところ、
- コードを読んでもよく分からなかったらとりあえず動かしてみる。printデバッグしてみる。
- 何か変更を加えた場合の影響を知りたければ、とりあえず変更してみて壊れるかどうか見てみる。
- 少し汚くてもいいからとりあえず実装してみて、後からリファクタリングする。
といったアドバイスを受けました。自分がすっかりトップダウン的な考え方に慣れていたことにここで初めて気づいたのもあり簡単には考え方を切り替えられなかったのですが、とにかく最初はとりあえず動かすという方針を取り入れてからはとりあえずざっと実装→それを改良という流れを徐々に確立することができ、開発速度が数倍になりました。上記のように動的解析的な開発方法の有効性を実践の場で実感したことは、間違いなく今後にも活きていくと思っています。
感想
自分にとって初めてのエンジニアインターンシップだったこともあり、自身の力量は十分なのか、まともな成果を出せるのかといった不安を抱えながらのスタートでした。また、はじめの1, 2日はコードベースの大きさに圧倒され、何もわからないまま時間が過ぎていき途方に暮れるといったこともありました。しかし、メンターの方に質問したりアドバイスを頂きながら進めるうちにだんだんと全体像が見えてきて、数日経って自身で設計→実装→改善のサイクルを回せるようになってからは仕事がとても楽しくなりました。時間的な制約から、最終的にプロジェクトの全てを完了することは出来ませんでしたが、scoutについては十分に実用的な機構を実装することができました。開発の過程で実用的な技術知識から設計時の考え方に至るまで多くのことを学ぶことができ、実りの多いインターンシップになりました。
また、自分がすぐにWantedlyの環境に慣れて楽しく仕事が出来るようになったのは、メンターの方に親身にサポートして頂いたのはもちろん、エンジニアランチ交流会などの機会を設けていただいたことで他のSquadのエンジニアの方やインターン生と関わりを持つことが出来たからだと思います。インターンシップ中に直接的であれ間接的であれお世話になった全ての方に感謝しています。本当にありがとうございました!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


