はじめに
インフラチームの @koudaiii です。
ウォンテッドリーでは、「知見として溜まったものを、学びの機会として共有するため」に毎週 SRE の役割持つメンバーを集めて review 会をしています。その中で学びが多かったポストモーテムを一つ紹介いたします。
このポストモーテムは非常に学びが多いものでした。一次対策から再発防止までよくまとめられた良いポストモーテムのため、紹介させていだきます。このポストモーテムは、先日開催された CNDT2020 Rejekts で紹介した実際のポストモーテムです。
ポストモーテムについては弊社の研修「失敗から学ぶ - ポストモーテム」をご参考ください。
※このポストモーテムについて、直接プロダクトに紐づく内容や個人を特定する情報ならびにリンク先を確認できないものについて、編集してあります。
用語集
ご紹介するポストモーテムでは、いくつか利用しているサービス名などの用語が多く含まれているため、用語集として参考リンクをまとめました。
[YYYY/MM/DD 13:29 - 14:45] Wantedly のマイクロサービス間通信全体のうち約5% が失敗し、 不安定になった
Incident Issues
<GitHub の issue リンク>
Authors
<当時の関係者>
TODO
- Node の台数を増やし、Node あたりの Pod 数を減らす
- Node のインスタンスタイプを m5.12xlarge から m5.4xlarge に変える
- Node の台数を障害発生前と同じ水準に戻す
- “kernel: Neighbour table overflow.” の発生を検知できるようにする
Long-term Action
- arp table cache の作成上限を見直す
- arp table entry 数を監視する
- metrics として取得出来る様にする
- 適切な alert を設定する
- cluster 内部の状態の急激な変化に気づける様にする
- 「特定の Node に問題が集中して発生していること」を客観的に分かるようにしたい
- (今回の問題に限らないけど)インフラチームへのエスカレーションポリシーが分からなくて判断に迷う状況を解消したい
Summary
YYYY/MM/DD 13:29 - 14:45 に Kubernetes の Node あたりの Pod 数の増加を起因とし、マイクロサービスで行っているサービス間通信の約5%でネットワークエラー (DNS の名前解決の失敗) が発生した。
Impact
障害発生中あらゆるマイクロサービスが不安定になり、機能を正常に提供できていなかったため、正確なインパクトについては算出できていない。障害対応時に報告されていた影響のみ記載する。
Root Causes
Node あたりの Pod 数の増加によって ARP table のエントリが増え、ARP table のエントリの上限値である 1024 に達し neighbour: arp_cache: neighbor table overflow!
が発生するようになったことが原因だと考えられる。
Trigger
障害が発生する直前に Kubernetes の Node のスケールダウンが発生していたことから、スケールダウンに伴う Node の台数の削減及び Pod の移動に伴う Node あたりの Pod の数 (≠ CPU / memory あたりの Pod の数) の増加がトリガーになった可能性が高い。
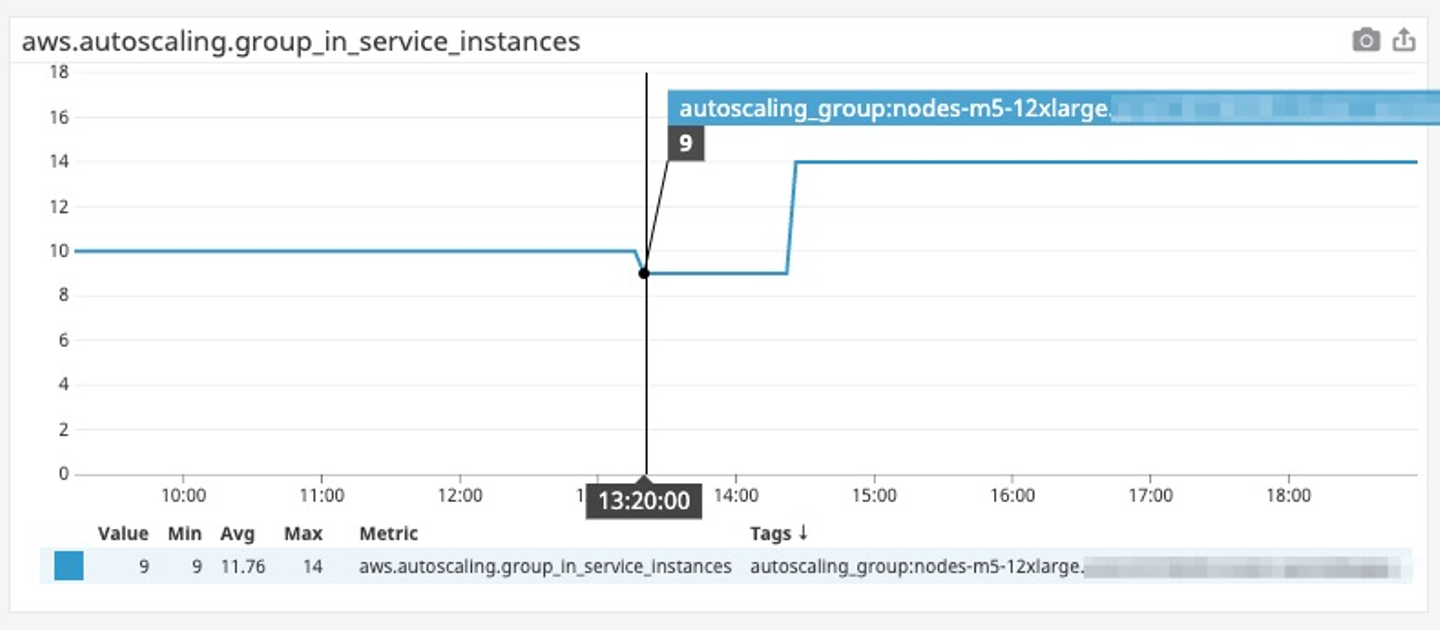
以下は障害発生前後の本番環境の Kubernetes の Node の数を表したメトリクスで、障害が発生する10分ほど前にスケールダウンが発生していることがわかる。
![]()
また前々日に Vertical Pod Autoscaler の導入を行っており、この作業によって Node あたりの Pod 数は増加している。(障害前日に Honeybadger で名前解決の失敗がいつもより多く発生していたとのこと)
Resolution
Node 数の増加と Pod の再配置を行い、Node あたりの Pod 数を減らしたところ問題が収束した。
Detection
Honeybadger のエラー増加をトリガーとした PagerDuty の通知により検知。
Lessons Learned
What went well
- Node あたりの Pod の数が原因ではないかという仮説から、方針とアクションの決定を行い、開発エンジニアと連携を取りながら行うことで、障害復旧までの時間を短くすることができた
- 二次対応 (再発防止) のプランの決定とアクションを素早く行うことができた
What went wrong
- Node レベルで起きた問題にしばらく気がつくことができなかったこと
- 予兆は見えていたがアクションに繋がらなかった
Where we got lucky
- Node あたりの Pod の数がネットワークエラーの発生の原因の可能性にあることに気がつけたこと
- Kubernetes の Node の
/var/log/messages
から、ネットワークエラーの発生と関連のありそうなエラーメッセージを見つけられたこと * 特定の Node かも?という仮説から「uncordon しまくる + kube-dns 増やす」をする * なぜか kube-dns が再起動繰り返していることに気づいた => その Node を調査開始した中で、気づいた
What we learned
- Node のレイヤで発生した問題の検知の重要性
- Node あたりの Pod 数が増えるとネットワークコールに失敗するという事実
Timeline
- 13:16 cluster-autoscaler によるスケールダウンにより Kubernetes の Node の台数が 10 -> 9 になる
- 13:29 Honeybadger のエラー数の増加をトリガーに PagerDuty が発火する、調査を開始する
- 13:41 Honeybadger のデータから、DNS の名前解決の失敗を起因としたネットワークエラーがアプリケーション全体で発生していることを確認する
- 13:47 kube-dns のいくつかの Pod で再起動が繰り返して行われていることを確認する、該当する kube-dns の Pod を delete する
- 13:56 DNS の名前解決の失敗の原因は kube-dns の Pod の数が足りないことではないかとの推測を立てる、kube-dns の Pod の台数を 40 -> 70 にする
- 14:01 kube-dns の Pod の restart は特定の Node でのみ発生していることに気が付く、不調だと思われる Node を cordon し Pod がスケジュールされないようにする
- 14:18 Node 数が足りないこと (≒ Node あたりの Pod 数の増加) が障害の原因だとの推測を立てる、cluster-autoscaler の設定を変更し Kubernetes の Node の最小台数を 7 -> 14 に変更する
- 14:24 Kubernetes の Node を管理している AWS の Autoscaling Group の最小台数のパラメータの値が 7 -> 14に変わる、これをトリガーに Node の台数が増え始める
- 14:28 Kubernetes の Node の台数が 9 -> 14 になったことを確認する
- 14:29 新しく増えた Node に Pod を配置させるようにするために、各マイクロサービスで Pod の再配置を実行する
- 14:38 Node の
/var/log/messages
に記録されているログから neighbour: arp_cache: neighbor table overflow!
の発生に気がつく - 14:41 アプリケーション全体で発生していたネットワークエラーの件数が下がり始めたことを確認する
- 14:44 アプリケーション全体で発生していたネットワークエラーの発生件数が障害発生前と同じ水準になる、障害が収束する
さいごに
ウォンテッドリーでは、この取り組みを 2017 年から続けています。この取り組みが続けられているということは、私たちのサービスやシステムが常に変化を続けている確かな証拠です。ウォンテッドリーで働く一人ひとりが、ユーザにとってより価値のあるプロダクトを提供するために日々挑戦し続けています。もっと話を聞いてみたいと思った方は、弊社のプロダクトから是非「話を聞きに行きたい」ボタンを押してみてください。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)






/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)