
2/28に弊社オフィスでKaggle入門のための機械学習勉強会を行いました。
https://www.wantedly.com/projects/285523
勉強会でやったこと
今回の勉強会の題材はKaggleのタイタニックチュートリアルです。
https://www.kaggle.com/c/titanic
弊社のCTOである大岩が簡単にKaggleについて説明をした後に実際にタイタニックチュートリアルを解析から提出して順位表示まで30分程度で実況、実演しました。その後は約1時間半ほどフリーの時間で、各自がタイタニックチュートリアルにチャレンジして提出と順位表示まで行いました。

解析に集中している様子。機械学習アルゴリズムについてから、Pythonの基礎的な使い方まで質問も飛び交い、とてもリラックスした雰囲気でした。
勉強会で学んだこと
開発環境
タイタニックチュートリアルは乗客のデータなどから誰が助かるのか判定する課題です。今回の解析にはPythonを使用したのですが、特に開発環境等を準備する必要はなく、KaggleのKernelを使用しました。
画像右下のNew Kernelをクリックすると、
ScriptかNotebookかが聞かれるので、今回はここでNotebookを使いました。
解析方法
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)Pythonを使うので、numpyとpandasを使います。Pythonというよりこの2つの関数の知識とかが最初は重要になってきます。
raw_train = pd.read_csv("../input/train.csv")
raw_test = pd.read_csv("../input/test.csv")
raw_train.head()続いてトレーニング用とテスト用のデータを読み込んでおきます。head関数で読み込んだトレーニングデータの一部を表示してみると、
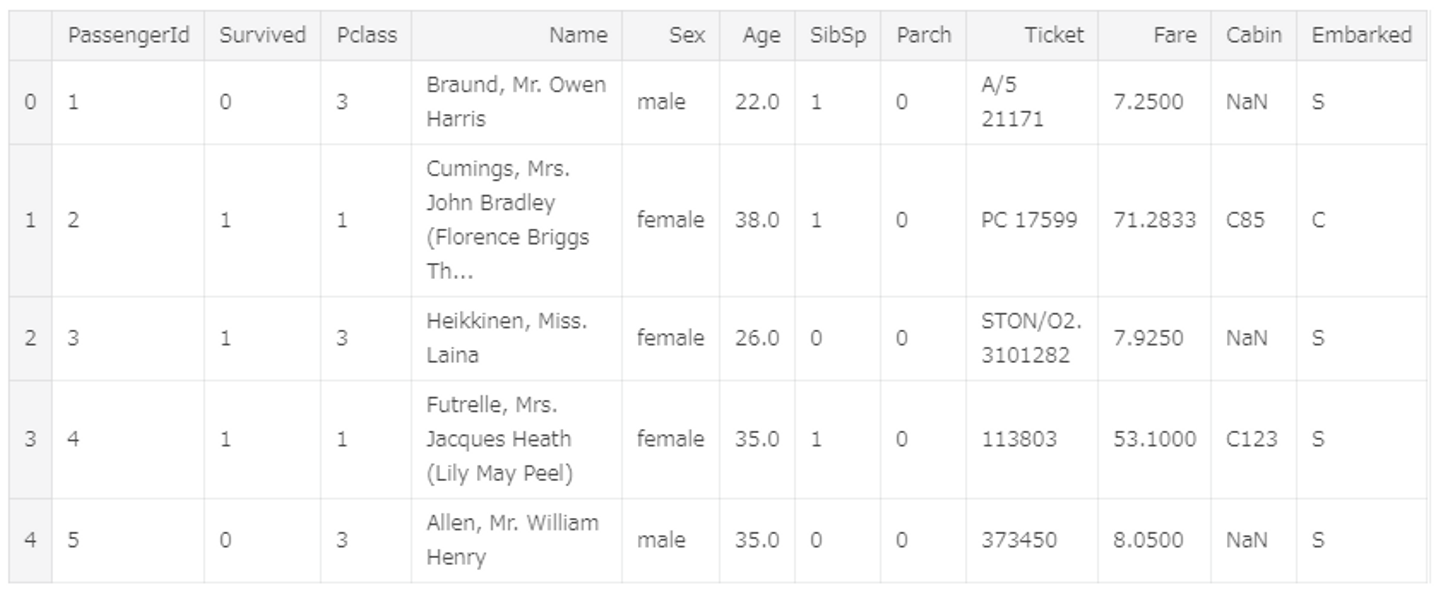
表示できました。読み込みに成功しているのが分かります。
ここからは割と泥臭い作業になります。
import seaborn as sns
%matplotlib inline
sns.heatmap(raw_train[['Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare']].corr(), annot=True)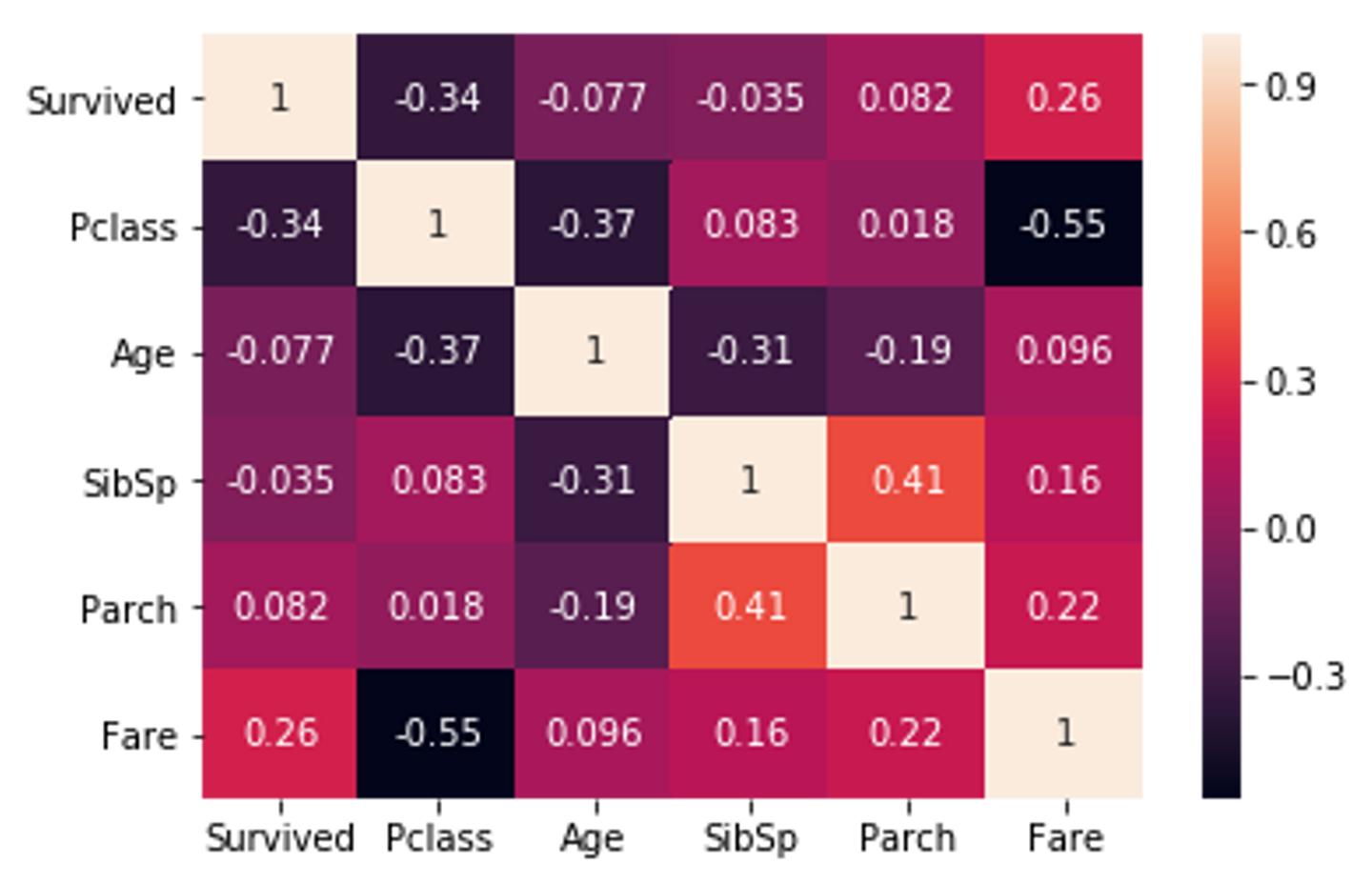
ヒートマップを作って相関がありそうなパラメーターを探してみたり、
sns.factorplot('Sex', 'Survived', data=raw_train)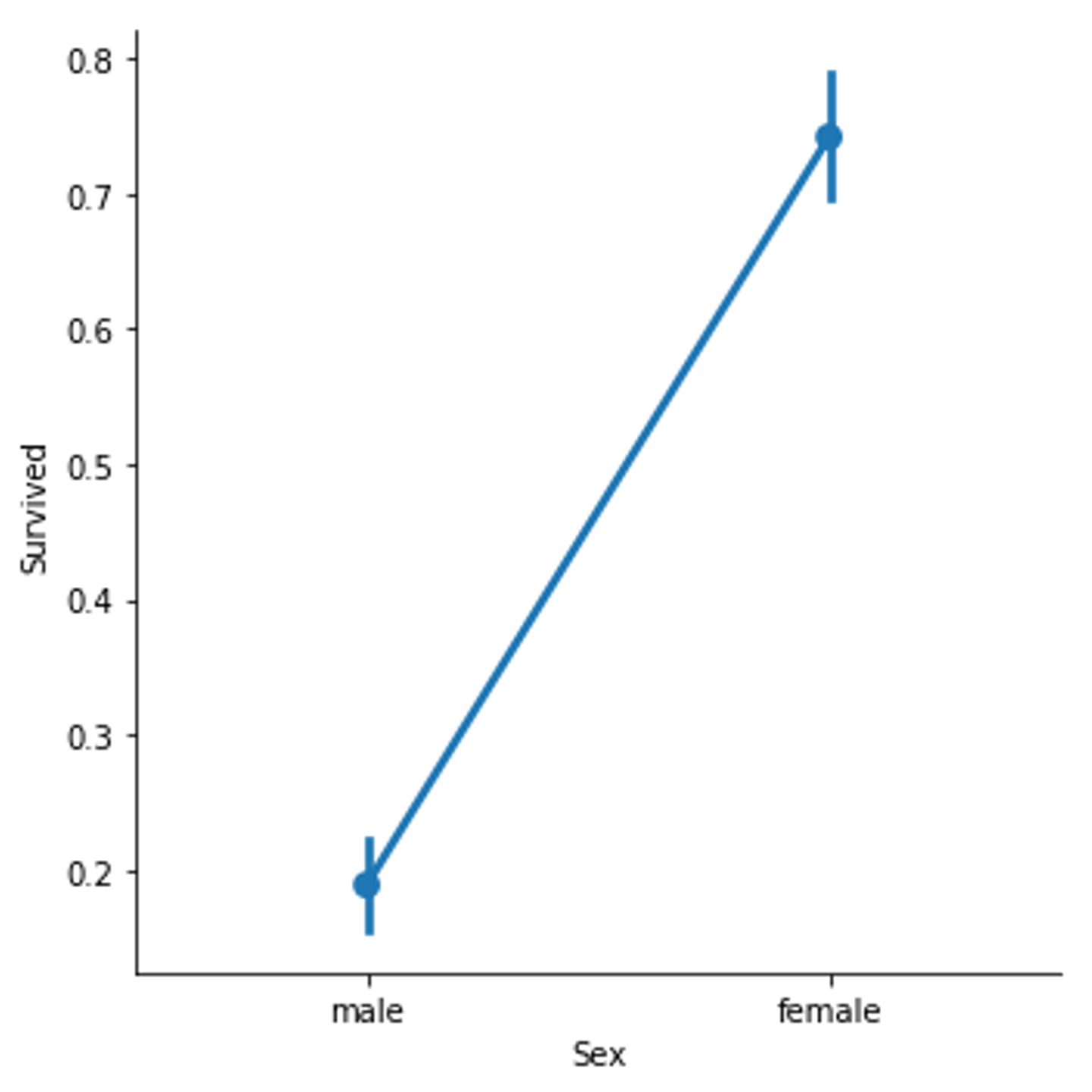
ただ単に女性であるだけで生存率がとても高いので、ここの条件は必須だよねという話をしてみたりしていました。パラメーターを絞ったり計算して作ったりできれば、あとは学習させてアルゴリズムごとの結果を見てみます。
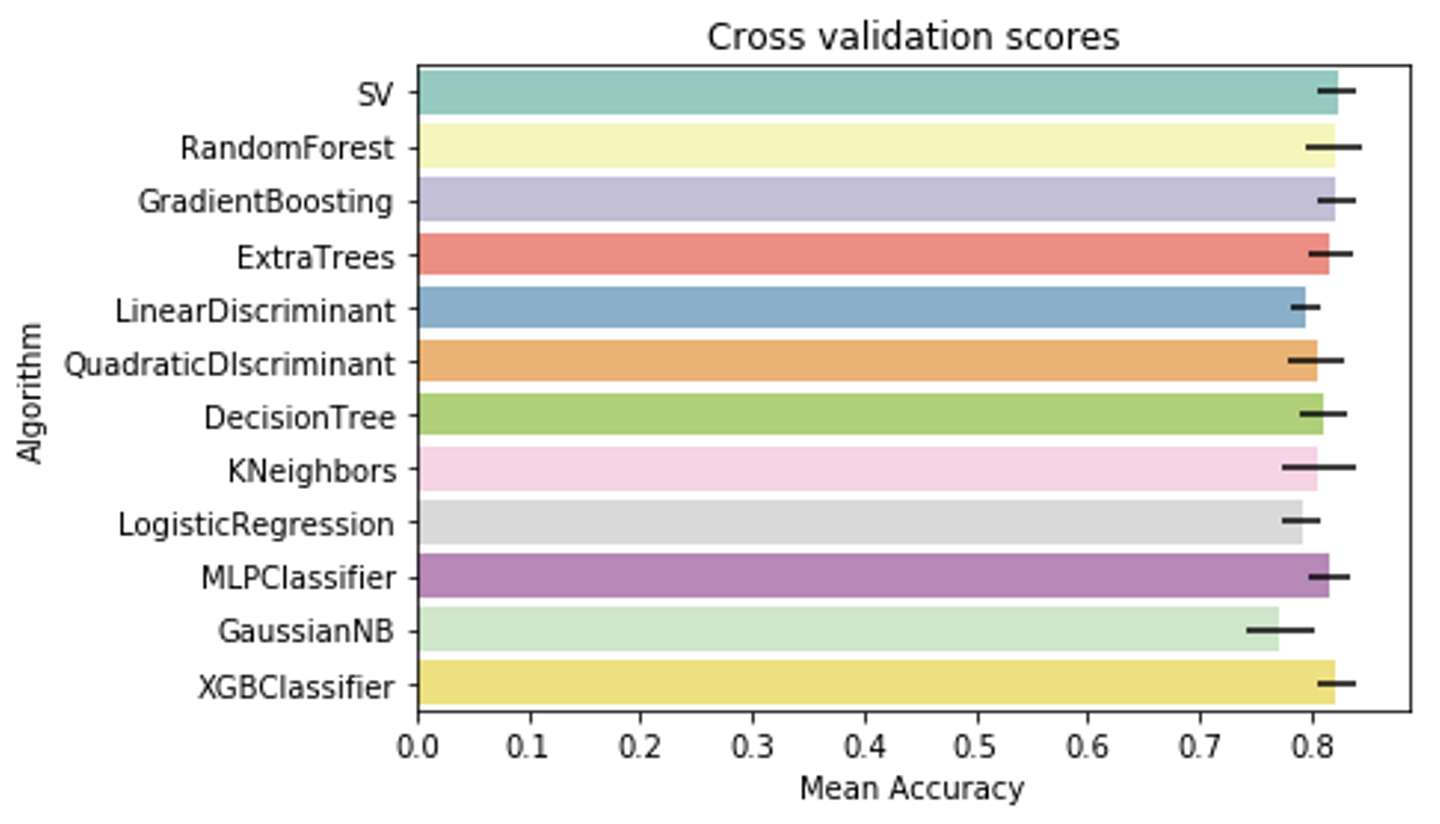
良さそうな結果が得られれば提出して順位が表示されます!ただ、ここで良い数字が出ていても提出時は当然手元にないデータを含む全データでスコアが計算されるので、「手元でやったときとスコアが全然ちがう…」と落胆することもありました。
その後のディスカッションでは、
- 女性・子供とそれ以外で生存率が大きく異なるため、それを分けて学習できないか
- 名前の名字から生存確率を出せるらしいぞ
等、アイデアを出し合ったり、他のkernelを見たりしていました。
次にやりたいこと
思いのほか機械学習は愚直な作業であることが参加者全員の感想だったようで、また、Pythonやそのライブラリの知識や使い方を勉強しないとスタート地点に立てないことも分かりました。次回はこちらにより焦点が当たるような題材を使って勉強会をやりたいなと思っています!
/assets/images/12987871/original/01cc56f2-80dd-4975-82f1-ec0577ef2f83?1681350777)


/assets/images/12987871/original/01cc56f2-80dd-4975-82f1-ec0577ef2f83?1681350777)




/assets/images/12987871/original/01cc56f2-80dd-4975-82f1-ec0577ef2f83?1681350777)


