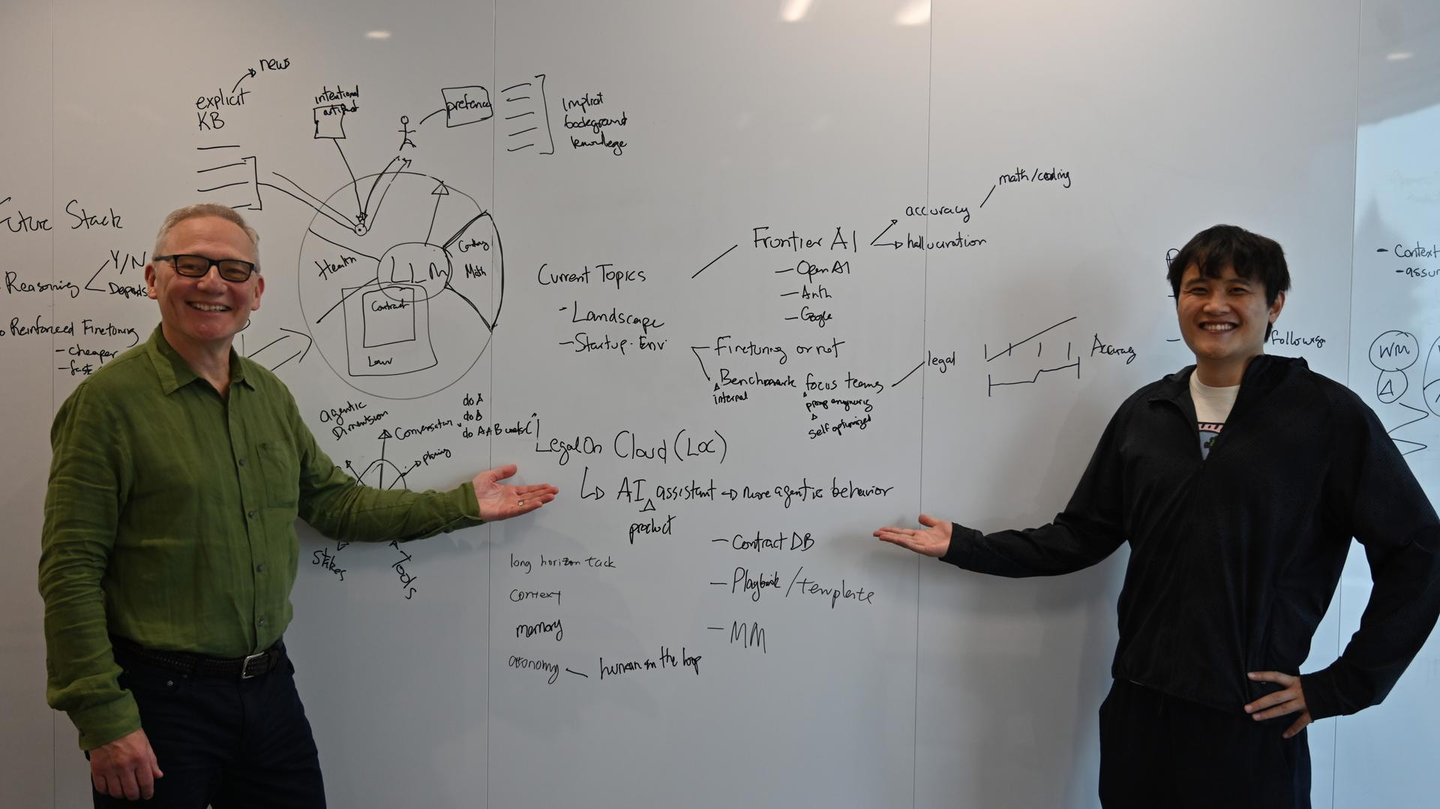
Tokyo meets San Francisco as Joe, Chief AI Officer for LegalOn Japan, and Gabor, Vice President of AI for LegalOn U.S., exchange notes on frontier-scale models, benchmark battles, and why accuracy rules in legal tech. Their vision: an autonomous, memory‑rich assistant that lets lawyers work at the speed of thought. Together, they reveal how Japan’s leading contract platform is evolving into an AI-driven leader in legal technology for the global stage.
Gabor Melli – Vice President of AI, LegalOn Technologies US Gabor is a veteran AI leader with 20+ years in machine learning, data science, and product engineering. He has built consumer- and enterprise-scale AI at companies such as Sony PlayStation (game & content-recommendation engines), VigLink (intelligent in-text ad placement), and OpenGov. Alongside his industry work, Gabor has authored numerous academic papers on semi-supervised learning and natural-language processing. Gabor joined LegalOn Technologies in August 2023 and was appointed to his current position at the same time.
Yiqing Zhu (Joe) – Chief AI Officer, LegalOn Technologies JP Joe holds a B.S. in Software Engineering from Zhejiang University and an M.S. in Computer Science from University of Tsukuba. He began his career as a software engineer in Rakuten’s Search Group, then spent seven years at Indeed as a full-stack engineer, tech lead, and engineering manager, honing deep expertise in NLP and machine learning. Joe joined LegalOn Technologies in September 2023 and was appointed Chief AI Officer in April 2024.
Left: Gabor | Right: Joe “We use Gemini to record,” Joe smiles. Gabor laughs: “An artificial-intelligence instrument—very modern!”
Why This Matters Now
Recorded during Gabor's visit to Tokyo (JP), April 2025.
Frontier models are moving fast, but legal AI demands benchmark‑proven accuracy, self‑improving prompts, and privacy‑aware memory—making this moment pivotal.
Joe: Let’s start with the big picture—why is now such a pivotal moment for legal AI?
Gabor: Because we’re riding a wave of frontier models. Our focus is really on the frontier, because one of our main concerns in legal is accuracy. Lawyers expect factual answers, not marketing demos.
Joe: Accuracy, yes—but candidates keep asking about hallucinations too. I don’t see a benchmark that truly captures legal yet. Most public scores focus on math or coding; they miss the edge cases that attorneys care about. That gap is why we built “LegalRikai”, the first open benchmark dataset that checks whether large language models can actually process legal tasks under Japanese laws and regulations.
Gabor: Exactly. Every three months, we run our own contract‑centric benchmark. The results come in waves—slow gains, then a big jump when a new family of models drops. Each jump forces us to re‑evaluate prompts, latency, and cost.
Joe: So it’s not just which model, it’s how we drive it. Recently, we’ve been letting the LLM rewrite its own prompt—recursive prompting. That self‑improvement loop means fewer manual tweaks as models get smarter.
Gabor: And yet, even the most innovative model can’t read a lawyer’s mind. Self-service users still struggle to craft an effective prompt. That’s why memory matters: We’re now evolving a memory of our users—what they said two weeks ago, their focus on construction‑law clauses. If we remember that, we can bias the answer toward relevance without extra work on their side.
Joe: Which brings security to the front. We store preferences, not proprietary data; users will be able to flip the right‑to‑be‑forgotten switch at any time. No hidden fine‑print.
Gabor: Frontier‑grade accuracy, domain‑specific benchmarks, self‑improving prompts, and privacy‑respectful memory. That mix is why this moment matters—and why building here feels like working three years in one.
Frontier AI Landscape
What does “the frontier” look like when you’re living on it?
Labs release new model families every few months, agent-focused startups flourish, and legal’s accuracy-latency-cost trade-off opens up unique opportunities.
Joe: We’ve been meeting with all the big labs lately—OpenAI, Anthropic, Google and more. What’s your read on where each is heading?
Gabor: They’re sprinting in parallel. Whoever offers the cleanest factual output wins our business.
Joe: DeepMind just dropped Gemini‑Diffusion—a text‑diffusion model instead of the usual autoregressive stack. I’ve never seen that, but it makes sense., could be a new wave.
Gabor: True. Every six months, we see a step‑change family release—GPT‑4o, Claude 3, Gemini 1.5 Flash. Each jump resets the playing field for cost, latency, and accuracy.
Joe: And the startup vibe in San Francisco? You said even the coffee‑shop chatter is full of the word “agent.”
Gabor: Definitely. Step into any downtown cafe and you’ll hear people swapping tips on “agent stacks” and “autonomous workflows.” Founders pitch tools that can plan, reason, and act for hours—or days—without a human touch. That autonomy is priceless—provided you can prove it’s safe.
Joe: That fixation on autonomy ties into another debate I keep hearing in ML circles: classic supervised fine-tuning versus reinforcement fine-tuning (RFT). Classic fine-tuning nudges a model with labeled examples, while RFT adds a second pass where the model gets rewarded for answers judged better by a custom scorer. Some friends swear RFT is more accurate, yet they still choose classic fine‑tuning because it’s cheaper.
Gabor: In legal AI, cost never trumps accuracy. Today’s RFT reward signals come from math and coding tasks, so they don’t capture legal nuance. Until we can reward “cites the right statute” or “matches contract-law precedent,” classic fine-tuning plus careful prompting wins on both accuracy and budget.
Joe: Until then, mixture‑of‑experts models will pour talent into easy‑reward areas, leaving niches like statute interpretation wide open for us. That could be our opportunity.
Gabor: Exactly. The giants race on general reasoning; we specialise where “it depends” is the default answer. That’s a moat (a defensible advantage).
Joe: Frontier AI isn’t a single model—it’s a moving stack of models, tuning methods, and agent frameworks. You’ll see the whole stack here, not just the glossy demo.
Gabor: And you’ll ship it to production, with real lawyers validating every release.
LegalOn’s Technical North Star
From benchmarks to memory: how do we decide what to build next?
Accuracy sits at the top; we push it via quarterly LegalRikai benchmarks, self‑tuning prompts, secure preference memory, and specialised legal tools.
Joe: Let’s pin down our North Star. What’s the one metric we refuse to compromise on?
Gabor: Accuracy—full stop. Our customers have a high bar of expectation for factual answers. In-house, we call it “contract‑safe output.”
Joe: And “LegalRikai” gives us the scoreboard. We open‑sourced it so anyone can see if an LLM really understands Japanese statutes.
Gabor: We re‑run that suite every quarter on each frontier model, plus our own pipelines. When we see a jump, we migrate fast.
Joe: But the metric alone isn’t enough; we need levers to move it. First lever: self‑improving prompts.
Gabor: Right. We let the LLM critique and rewrite its own prompt—recursive prompting. That shave‑off delivered a 10‑point gain on confidentiality‑clause accuracy.
Joe: Second lever: domain memory. We separate knowledge (public law) from preference (a client’s playbook: “30‑day payment terms only”).
Gabor: Preferences live in a private vector store under the customer’s tenancy. If they request a wipe, we can erase it in seconds.
Joe: Third lever: specialised tools—redlining, clause extraction, playbook lookup. Each gets its own unit test inside LegalRikai‑Plus so a regression shows up before a lawyer ever sees it.
Gabor: Stack those levers and the pyramid looks like this: Benchmark → Prompt Self‑Tuning → Memory → Tools → Security.
Joe: Or, in one sentence: Ship the most accurate answer possible, at human speed, without leaking a byte.
From Tools to Agents
Turning point: when single‑function tools learn to think, remember, and act.
By adding perception, memory, planning, and autonomy to single‑turn tools, we’re evolving them into multi‑step legal agents.
Joe: Last week I asked, What even counts as an agent? I sketched a framework with five dimensions—horizon length, context understanding, tool use, memory, and autonomy.
Gabor: I like that, though I slice it slightly differently: conversation, perception, action, planning, and memory. The more boxes you tick, the more agentic the system feels.
Joe: Today our redlining tool is single‑turn—“do A, then B.” But the moment it can plan a 20‑step review, that’s a long‑horizon agent.
Gabor: Planning needs language. “Do A and B unless C; escalate if D.” The agent must parse that and build a plan.
Joe: And to execute, it needs perception—events like “new file uploaded” or “deadline hits.” That’s coming with "Matter Management" module.
Gabor: Memory is the linchpin. “Lawyers expect the assistant to recall what they decided two days ago.” Short‑term session memory plus long‑term playbook memories.
Joe: Tool use is where legal gets tricky. Playbooks and Templates—both now available in LegalOn Cloud—act as specialised tools: review pulls Playbooks, drafting taps Templates. The agent must select the right asset at each step. Drafting involves pulling Templates; review involves pulling Playbooks; negotiation may require calling external search APIs. The agent must select the appropriate tool at each step.
Gabor: And autonomy lives on a slider: the less human in the loop, the higher the stakes. For contract drafting, we’ll start with human-approved, then graduate to auto‑draft simple NDAs.
Joe: So, where are we on that slider?
Gabor: We already have the conversational interface running in production. The next milestones are event awareness—so the assistant notices new files or looming deadlines—and a smarter memory that recalls past sessions and playbooks automatically. Deep planning and fully automated actions will follow, one careful step at a time.
Joe: In other words, from helpful tools to trusted agents—still lawyer‑in‑the‑loop, but doing 80 % of the grunt work.
Gabor: And every new dimension we unlock becomes a moat: few vendors can combine legal accuracy and multi-step agency without incurring significant risk.
Joe: That’s the fun part—we get to define what “legal agent” means before the industry catches up.
Beyond the Horizon
A candid glance twelve months out.
Within a year, longer-running agents and AI-accelerated coding will enable small teams to execute at an enterprise scale, while lawyers focus on edge cases.
Joe: Let’s jump ahead a year—how different will our tech stack feel?
Gabor: Reasoning windows will explode. One lab has just shown agents thinking for hours; some teams are already discussing research runs that last days or even weeks.
Joe: Longer runs demand more autonomy. If an assistant can keep that much context, it could shepherd a contract almost end‑to‑end before a lawyer ever steps in.
Gabor: But that autonomy only matters if we can ship faster. The frontier labs are already using their own models to write code; we have to do the same.
Gabor: Exactly. We’re not short of work; we’re short of time. Agents that can draft code, generate tests, and triage bugs will let a ten‑person team move like fifty.
Joe: And that keeps our lead in the legal domain, where “it depends” is the default answer.
Gabor: Twelve months from now, I expect our assistant to plan, draft, redline, and file simple agreements with almost no hand‑holding, while lawyers focus on the edge cases.
Joe: A good year to be building—on both sides of the Pacific.
Note — Speed Beyond Code
Speed matters across the entire delivery chain — from idea to launch.
LLMs already trim coding and unit-test time, but coding accounts for only ~20 % of a typical release. Requirements, design, peer review, documentation, help pages, and launch assets still consume most of the calendar. Even if we make coding one-third faster, the whole timeline shrinks by barely ~13 %. That’s why our AI-powered Development Center of Excellence (AID CoE) is widening its scope — piloting copilots for user stories, test cases, release notes, and more. The goal: end-to-end AI support that lets product-centric teams cycle faster with fewer context switches.
Joe: Hard to believe our whole conversation took only thirty minutes.
Gabor: Frontier years feel like dog years—so much shifts in a quarter.
Joe: One constant: lawyers need answers they can trust.
Gabor: And we’re determined to give them an assistant that’s both fearlessly fast and painstakingly accurate.
LegalOn’s north star is clear: pair frontier‑grade AI reasoning with tight, lawyer‑in‑the‑loop safeguards, so every contract is drafted, reviewed, and filed faster and more accurately than ever before. Stay tuned to LegalOn Now for deeper dives and the next wave of product launches.
We are hiring!
LegalOn's development team is actively recruiting engineers!If you are interested, please feel free to contact our recruitment team or apply via the link below!
/assets/images/11353072/original/3249ddc5-f9fd-4bb5-aa42-2739aadf09b0?1669821384)






/assets/images/11353072/original/3249ddc5-f9fd-4bb5-aa42-2739aadf09b0?1669821384)


/assets/images/11353072/original/3249ddc5-f9fd-4bb5-aa42-2739aadf09b0?1669821384)
/assets/images/11353072/original/3249ddc5-f9fd-4bb5-aa42-2739aadf09b0?1669821384)