/assets/images/4600195/original/a799e1b5-6ade-41f2-a1a2-c609142cc376?1581331391)
Wovn Technologies株式会社's job postings
誤訳ないWEBサイト翻訳の実現を目指し、機械翻訳と共存。~機械翻訳エンジンが苦手なこと~

on 2019-03-28
WEBサイト多言語化管理サービス「WOVN.io」のWovn Technologiesです。
機械翻訳の難しさが各メディアを通じ大きな注目を集めています。
「堺筋線」Google翻訳でも“筋肉線”、「堺筋」は“大腿筋” 機械翻訳の難しさ
様々な企業が外国人対応を本格化するためにサービスやWEBサイトのローカライズ・多言語化を進めている中で、翻訳自体を機械翻訳に任せている会社は少なくありません。年々進歩を遂げる機械翻訳のおかげで、あらゆるビジネスシーンやライフスタイルにおいて外国人との距離は日に日に近くなっております。
一方で、機械翻訳が現在、人力翻訳と同じだけのクオリティで翻訳ができるかというと、そこまでの進歩はまだありません。今回はそんな機械翻訳が、何が苦手なのかをご紹介したいと思います。
1. 固有名詞の誤訳
機械翻訳は、膨大なデータベースをもとに適切な翻訳文を提供するため、データベースにない文や名前を翻訳しようとすると、不適切な訳文が当てられることがあります。
具体的には、固有名詞や流行り言葉がまだまだ網羅できていないところが多く、駅名・地名であったり、人や会社の名前などが大きく誤訳されてしまうことは多々あります。
2. 予測できない「ニューラル翻訳」
2016年から、Googleの機械翻訳において、新しい翻訳システム「Google Neural Machine Translation(GNMT)」が採用されました。ニューラルネットワークを使用したAI翻訳です。これにより、従来のルールベース翻訳・統計ベース翻訳のような形式的な翻訳ではなく、文脈を機械が汲み取り、より自然な文章で翻訳をしたり、文章ごとに最適な訳語を選択できるようになりました。

【参考】固有名詞の「林」と、一般名詞の「林」を別の単語と認識して翻訳をしている
一方で、この新しい機械翻訳の登場によって、下記のような課題が新たに生まれました。
・訳文が急に抜けることがある
・原文にない単語を急に足すことがある
・重複して翻訳してしまうことがある
・誤訳が急に発生する

【参考】「12時00分」の部分が訳文では抜けている
3. 全体のレイアウトを加味した翻訳ができない(WEBサイト多言語化特有の課題)
たとえば、「 円」という文字を目にしたときに、通貨単位としての「円」であると推測することは難しくないですが、機械翻訳ではこうしたレイアウトを無視してしまうため、これを"circle"と翻訳してしまいます。
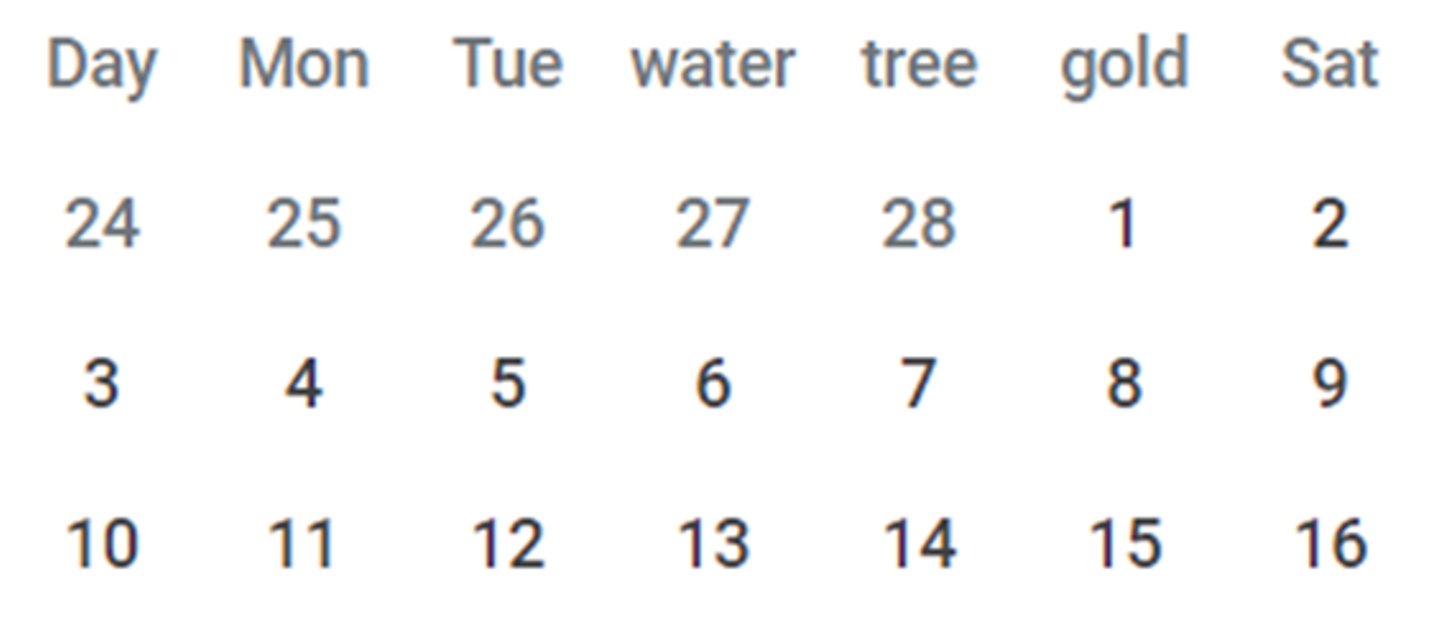
【参考】曜日がうまく翻訳されていない
これらの理由から、精度高く様々な情報を顧客に伝達する必要のある企業、団体においては、機械翻訳だけではどうしても不足があるというのが現状です。
実際に、我々Wovn Technologiesのお客様の中には、機械翻訳での翻訳運用のみをご利用いただいているお客様がいらっしゃいますが、
『機械翻訳には誤訳があることを理解いただくこと』
『誤訳があった場合のリスクを検討していただくこと』
この2点について、お客様に充分にご理解をいただいた上で、運用に入ることを、我々のルールとしております。
近年、多言語対応のニーズは高まるばかりです。
我々Wovn Technologiesは、より便利で付加価値の高いツール・サービスを提供するとともに、多言語対応の先にあるゴールを達成するためのパートナーとして、唯一無二の選択肢になれるよう努力を重ねてまいります。
/assets/images/4600195/original/a799e1b5-6ade-41f2-a1a2-c609142cc376?1581331391)

Invitation from Wovn Technologies株式会社
If this story triggered your interest, have a chat with the team?
誤訳ないWEBサイト翻訳の実現を目指し、機械翻訳と共存。~機械翻訳エンジンが苦手なこと~

/assets/images/4600195/original/a799e1b5-6ade-41f2-a1a2-c609142cc376?1581331391)
/assets/images/2113846/original/cce4de25-ced4-460c-9b7c-709dbd5bc969?1521098309)
