推薦システムにおけるPost Processの取り組み | Wantedly Engineer Blog
こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。この記事は夏のアドベントカレンダー15日目の記事です。この記事ではWantedly Visi...
https://www.wantedly.com/companies/wantedly/post_articles/987473

こんにちは。ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。
会社訪問アプリ Wantedly の募集の一覧画面では、一人ひとりのユーザーに合わせたパーソナライズを行っています。推薦システムの本来の役割は、ユーザーが自分一人では辿り着けなかったような「魅力的な募集」との出会いを届けることです。しかし、推薦される内容が似たようなものばかりに偏ってしまうと、新しい発見という体験価値を損なってしまいます。
本記事では、ユーザーがまだ見ぬ魅力的な募集に自然と出会える状態を目指し、Two-Tower モデルを活用して候補生成ロジックを刷新した取り組みについて紹介します。
背景
ユーザーがまだ見たことがない募集を推薦することの価値
企業に対する推薦との違い
解決手法
解決の方針
Two-Tower モデル
技術的に工夫した点
結果
まとめ
会社訪問アプリ Wantedly では、ユーザーの嗜好に合わせたパーソナライズを行い、魅力的な募集を効率的に見つけられる体験を提供しています。ここで重要なのは、推薦リストが単に嗜好に合致しているだけでなく、「まだ出会ったことのない新しい募集を発見できる」という体験を両立させることです。
もし推薦される募集が毎回似たようなものばかりになってしまうと、プロダクトとして以下のような課題が生じます。
ユーザーに「使うたびに新しい発見がある」と感じてもらえる状態を維持することは、単なる機能改善に留まらず、プロダクトの長期的な信頼と成長を支える基盤となります。
実は上記の問題は、Wantedly が企業側に提供している推薦でも存在しました。企業がスカウト送信の候補者を探すときに、過去に見たことがある候補者が推薦され続けてしまうという課題です。こちらについては、推薦結果に対して Post Process をかけて並び順を調整することで、まだ見たことがない候補者を見つけやすくするという対処をしていました。その施策の詳細については以下のストーリーをご覧ください。
この記事で注目しているユーザー側への募集の推薦でも、同様に Post Process によって課題を緩和することができる可能性はありました。しかし、ユーザー行動を少し分析してみると、ユーザーが直近で閲覧した募集に応募する確率は、閲覧回数が増えるにつれて低下はするものの、その減少ペースは非常に緩やかであることが分かりました。これは、ユーザーが「気になる募集」を見つけても、即座に応募を決断せず、複数回検討を重ねるケースが多いことを示唆しています。つまり、既読の募集を再提示することは、ユーザーの意思決定を促す重要な役割も果たしていると言えます。
このような分析から、募集の推薦ではルールベースによる手法よりも機械学習的に対処して、見たことがあっても嗜好に合致していそうな募集はそのままに、合致していないものを出さないようにするという対処が必要だと考えられます。
Wantedlyの募集推薦では、一般的な推薦システムと同様に、候補生成とリランキングの2ステージ構成を採用しています。従来の候補生成ロジックの一部には、ユーザーが過去にインタラクションした募集を抽出するルールベースの手法が含まれていました。この手法は「応募を迷っている募集」を再提示できるメリットがある一方で、既に目にした募集を再度推薦候補に含めるためにリランキング結果にも同様の募集が上位に多くなりやすくなります。結果としてユーザーの潜在的な嗜好を広げにくく、推薦結果が固定化されやすくなる要因にもなっていました。
今回の改善では、このルールベースアルゴリズムによる候補枠を一部見直し、ユーザーの多角的な嗜好を反映した上で「未見の募集」を提示できる新しいアルゴリズムを候補生成ステージに追加する方針をとりました。
この方針を実現するため、新たに Two-Tower モデルを候補生成に採用しました。
Two-Tower モデルは、インタラクションデータ(行動履歴)に加えてコンテンツデータ(募集内容やユーザー属性)を特徴量として扱えるのが大きな特徴です。両者の情報を掛け合わせることで、過去に直接的な接点がなかった募集に対してもユーザーの嗜好との親和性を計算できるようになり、未知の募集に対する発見性の向上が期待できます。Two-Tower モデルの詳細については、以下の検証記事を参照ください。
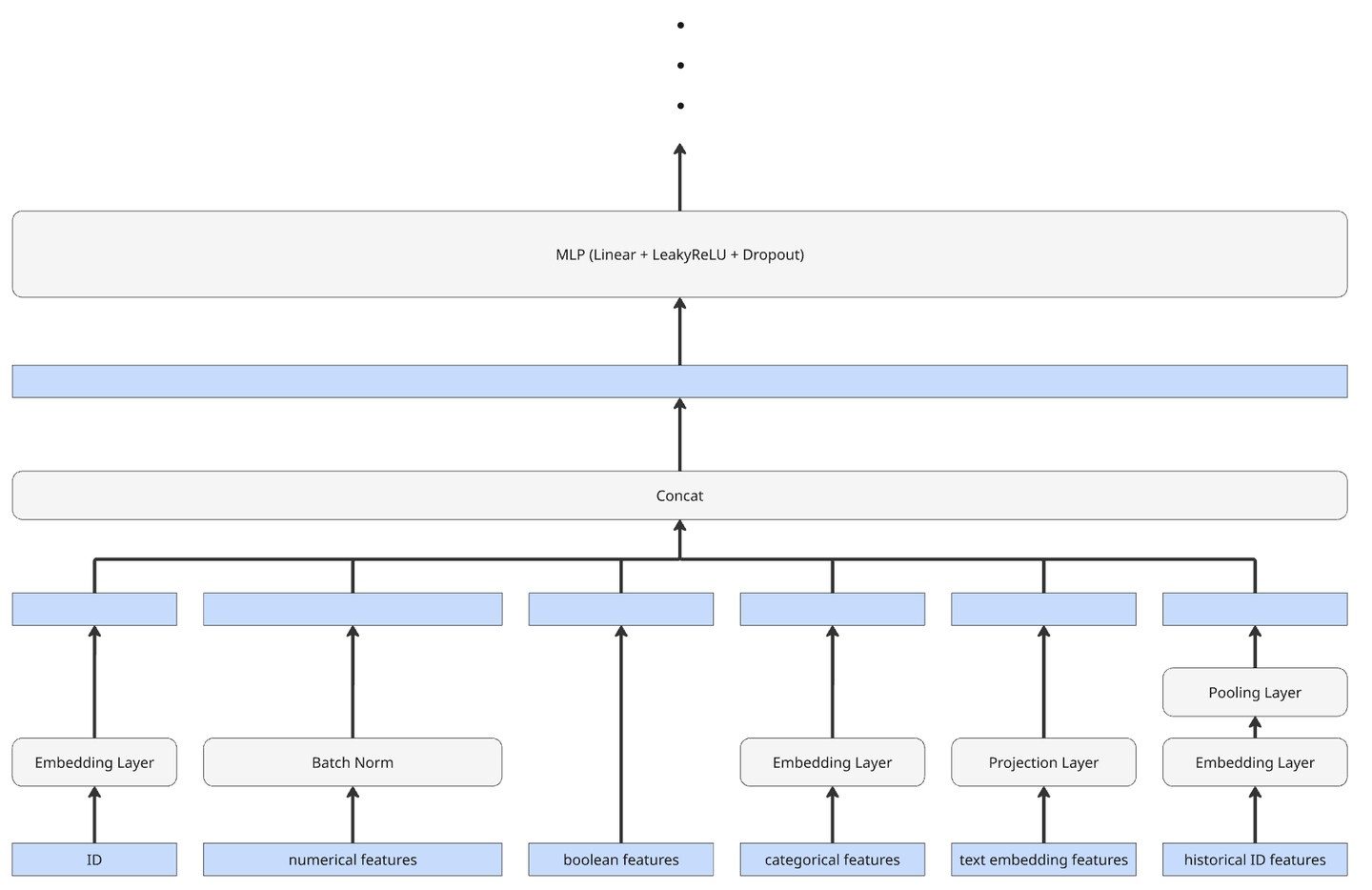
学習のアーキテクチャでは、ユーザー属性を扱う「ユーザータワー」と、募集情報を扱う「募集タワー」の2つからそれぞれの埋め込み(Embedding)を算出します。損失関数には InfoNCE Loss を採用し、対照学習によって最適化を行いました。
それぞれのタワーのアーキテクチャの概要は以下のようになっています。ユーザータワーも募集タワーも大枠の構造は同じなため、1タワー分のアーキテクチャだけを示しています。
このアーキテクチャは今回の施策で始めて組み込む形だったため、実用化にあたっては施策の中心的な目標である発見性の他にも、精度と計算コストのバランスを最適化する必要がありました。特に以下の3点に工夫を凝らしました。
損失の補正
Two-Tower モデルでは、出現頻度の高い「人気アイテム」が過剰に評価される傾向があります。これを防ぐため、以下の論文を参考にアイテムの出現頻度に基づいて損失を補正する手法を導入し、人気バイアスの低減と推薦精度の向上を両立させました。
具体的には、以下の式のように損失関数に対してアイテムの出現頻度 pj の対数を取って引くことにより補正を行っています。(下の数式は論文から引用)
負例サンプリングにおける「偽陰性」の許容
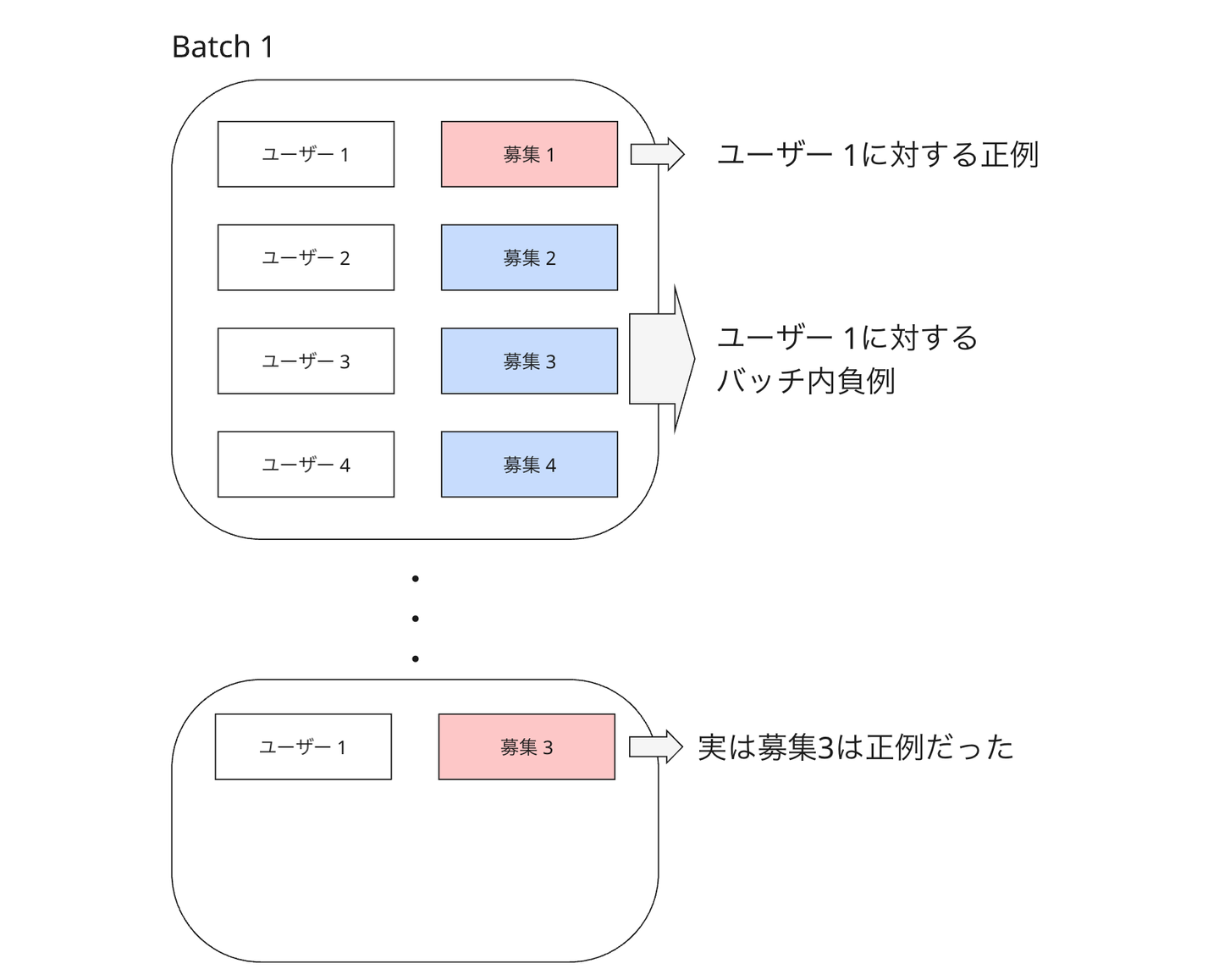
学習効率を高めるため、負例はバッチ内からサンプリング(In-batch Sampling)しています。しかし、バッチ内からランダムに負例をサンプリングしてくると、以下の図に示すように、実は負例として選んできた募集は別のどこかでインタラクションしているログがあった(= 偽陰性サンプルだった)ということが発生しえます。
厳密には偽陰性サンプルはマスク処理で排除すべきですが、これは計算負荷を増大させることがわかっていました。事前検証の結果、マスク処理の有無が精度に与える影響は軽微であったため、システム負荷を優先してマスクを行わない判断をしました。
インタラクション履歴情報の活用による「浅いインタラクション」の反映
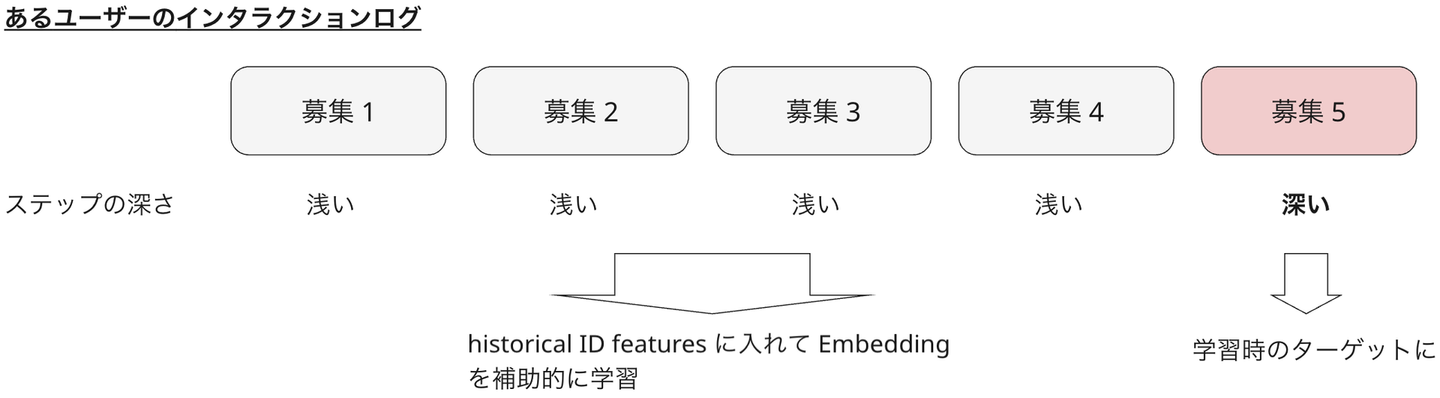
インタラクションデータにはいくつかのステップがあります。例えば Wantedly の場合には募集を一覧ページで目にする、クリックする、話を聞きにいきたいというボタンを押す、マッチングが成立する、などです。ステップが深いほどユーザーの嗜好を厳密に表現できるため、理想的には一定深いステップのインタラクションを学習時には利用すべきです。
一方で、深いインタラクションのみを利用すると学習データ量が少なくなるほか、一定の深さのステップのインタラクションを経験していない募集などでは ID Embedding が学習されないために適切なユーザーの推薦候補に入れられないという課題が生じます。
この問題を少しでも緩和するために、ユーザー側の履歴特徴量の中に浅いインタラクションの情報を加えるという工夫をしました (下図)。これによって浅いインタラクションしかない募集についても ID Embedding の学習を補助的に進めることが可能になります。実際検証してみた結果、この工夫によって性能を劣化させることなく候補に入れることができる募集数を大幅に増加させることができていました。
オフラインでの精度検証を経て、本施策のオンライン A/B テストを実施しました。その結果、主要な指標において非常に大きな改善が見られました。
数値が示す通り、施策の最大の狙いであった「ユーザーがまだ見たことがない募集」の提示数を大幅に増やしつつ、プロダクトの根幹となる重要 KPI においても二桁改善という極めて高い改善を実現できていることがわかります。この改善幅は当初目標としていた数値を大幅に上回るもので、プロダクト全体に対しても非常に大きなインパクトがある施策となりました。
冒頭に、募集推薦においてはユーザーは興味を持った募集にすぐに応募するとは限らず、じっくり考えてから応募する傾向があるため、直近で見たことがあっても嗜好が合致していそうな募集は再度推薦できるようにすることが重要であるということを書きました。今回の施策で、直近でユーザーが目にしたことがある募集の推薦傾向に変化があったかを追加で分析しました。
分析の結果、新しい推薦のもとで表示されていた「ユーザーが直近で見たことがある募集」に対する応募率が既存の推薦よりも大幅に向上していることがわかりました。この結果は、施策によって「直近で目にした & 嗜好が合致している(= 応募を迷っている)」募集の表示はあまり減らさずに、「直近で目にした & 嗜好が合致していない (= 応募する気がない)」募集の表示をより大きく減らせたことを示唆しています。機械学習的な解決策を取ることによって、期待通り柔軟な変化を起こせていたことがわかりました。
本記事では、ユーザーの潜在的な嗜好を捉え、まだ出会っていない魅力的な募集を推薦するために、Two-Tower モデルを用いた候補生成ロジックの改善事例を紹介しました。多様なデータを扱えるモデルを組み込んだことにより、ユーザーの興味をより多角的に捉えられたことで、プロダクトの課題を上手く解消できたと思っています。
ウォンテッドリーでは、これからも引き続きユーザー・企業のより良い体験を作っていくために推薦の改善を行っていきたいと考えています。

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
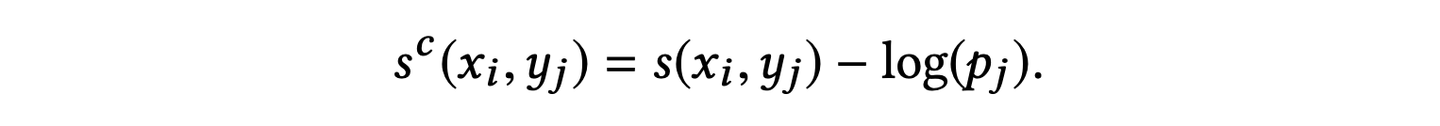
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

