/assets/images/1750714/original/65eb3cd5-3f16-4a07-b019-3e45b90a27d8?1602146549)



スパイスファクトリー株式会社's job postings
- Webエンジニア/リモート可
- PM 【週1出社】
- Webエンジニア|インターン
- Other occupations (20)
- Development
- Business
- Other
こんにちは。スパイスファクトリーの井田です。
Railsエンジニアとして入社した後、現在は生成AI周りの技術調査・検証やノーコード・ローコードツールの活用、BIを利用したデータ分析系など多様な技術に触れ、社内外の様々な課題解決に取り組んでいます。
今回はGPT-3.5 Turboと同程度の性能が報告されているMicrosoftが開発したオープンソースの小規模言語モデルPhi-3をノートPCで動かしてみたので、ローカルでの環境構築手順と使ってみて感じたことを紹介したいと思います。
近年、AI技術の進化は目覚ましく、大規模言語モデル(Large Language Model:LLM)を導入したプロダクトの開発が盛んに行われています。LLMは、OpenAI、Azure、AWSなどのプラットフォームを通じて提供され、API経由で利用することが一般的です。しかし、セキュリティ要件の厳しい企業では、外部APIの利用が難しい場合が多く、また従量課金がコスト負担となることもあります。
そこで今回は、小規模言語モデル(Small Language Model:SLM)の活用に目を向け、技術検証を行いました。
SLMは少ないコンピュータリソース(一般的なノートPCやスマートフォンなど)でも利用できるような言語モデルです。近年、ChatGPTなどのLLMが広く普及していますが、LLMは膨大なコンピュータリソースが必要であるため、一般的なデバイスに搭載して利用することは困難です。
LLMの場合は、OpenAI, Azure, AWS, GCPなどのプラットフォームで提供されるAPI経由で利用することが一般的です。一方で、SLMは独自のアプリケーションと同じサーバーに搭載することも可能で、外部APIではなく内部に閉じた環境で利用することが可能です。そのため、例えば、セキュリティ要件が厳しく外部APIの利用が許可されない企業での利用や、電波の届かないところでもスマホに搭載されたAIを活用するなど、AI活用の可能性を広げることができます。
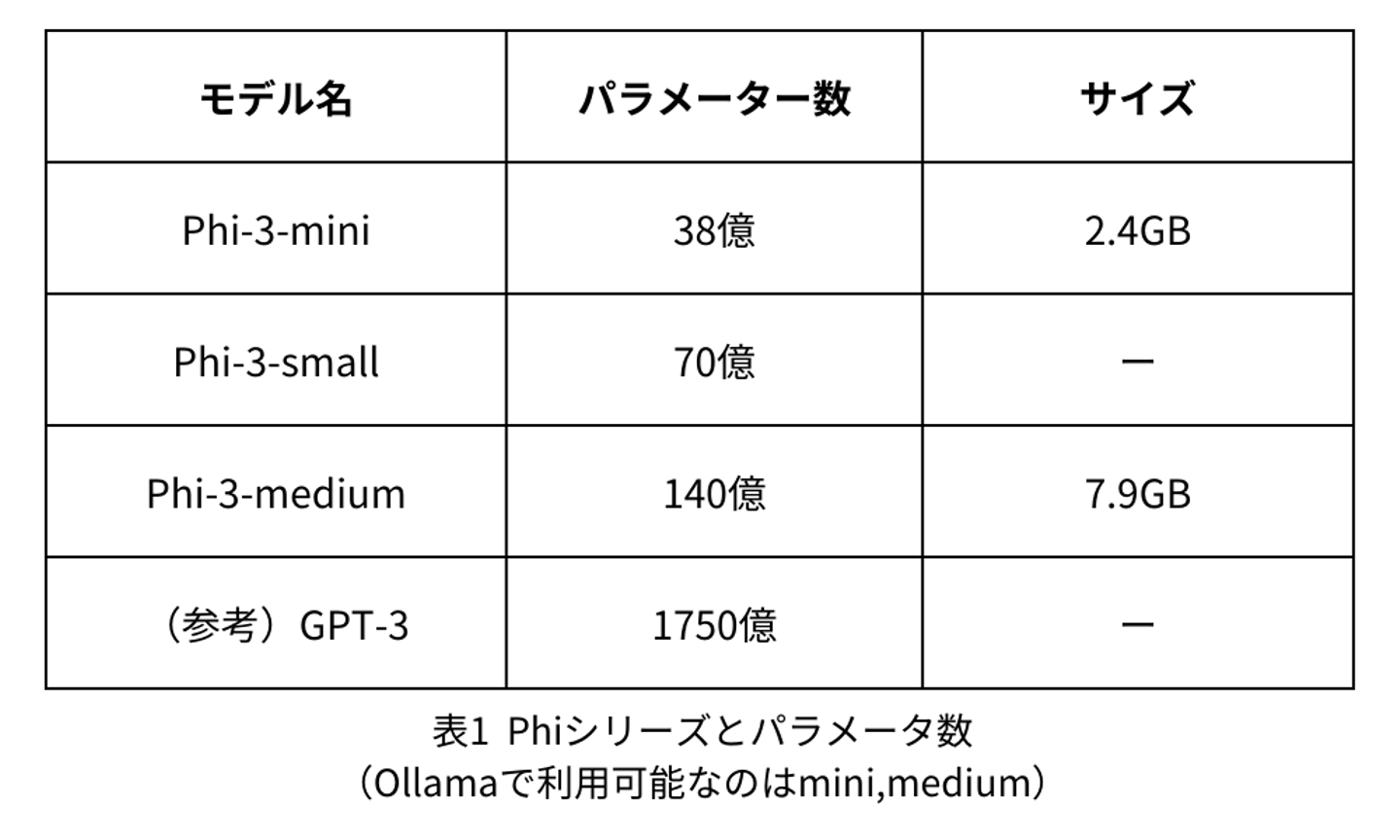
Microsoftが開発したオープンソースのSLMで、現在公開されている中では最も高性能なSLMの1つです。Phiは主にmini, small, mediumの3種類のグレードが存在します。表1に示すように、PhiシリーズはGPT3と比較しても10分の1以下のサイズに収まっています。一方、Microsoftが発表した論文によると、性能面ではGPT-3.5 Turboに匹敵する精度を示したと報告されています(GPT-3.5-Turboのモデルサイズは公表されていないがGPT-3の倍以上と予想されている)。
Phi-3を試す前にLLMとSLMのメリット・デメリットを整理しておきます。一般的には以下のようなものが挙げられると思います(利用するモデルによって個別の性能には差があります)。LLMは大規模な学習により得られた性能の高さ、SLMはモデルサイズが小さいことを活かしてLLMで対応できない領域をカバーできることが特徴ですね。
ここからは実際に手元にあるノートPC(M1 Mac)でPhi-3を動かしてみたので、環境構築〜実行の手順と実際に動かして感じたことを報告します。
Phiなどのオープンソースのモデルを動かせるOllamaを利用します。
Ollamaのインストール
curl https://ollama.ai/install.sh | shHomebrewを利用したインストールも可能です。
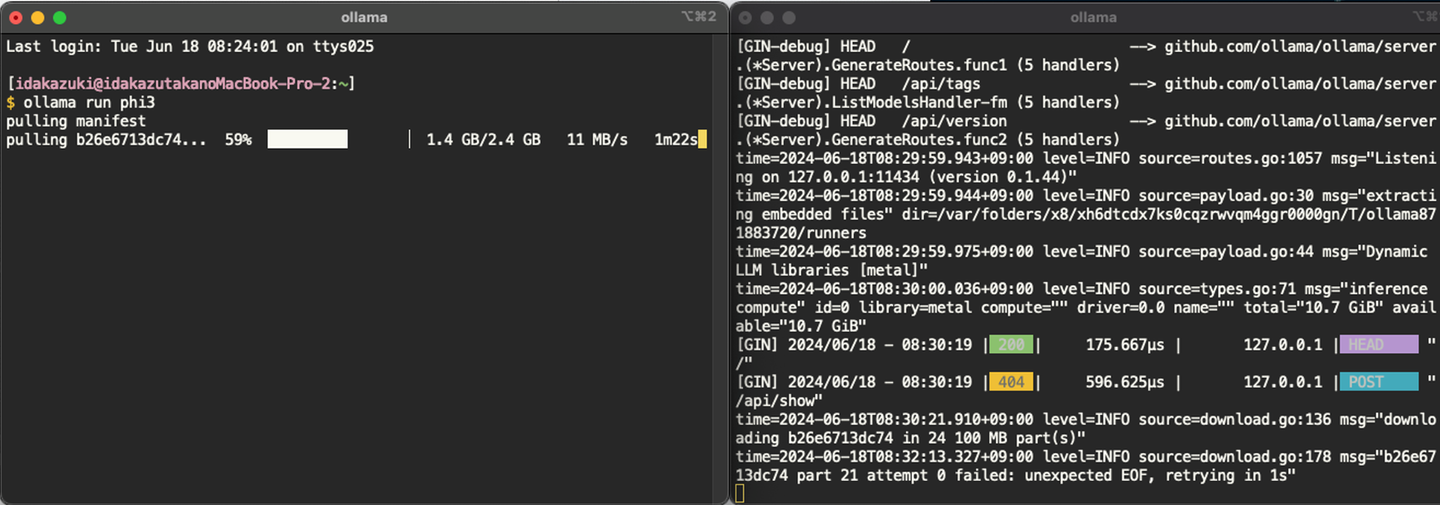
brew install ollamaインストールが完了したら、Ollamaを起動し、利用する言語モデルをインストールします。モデルのインストールにはモデルサイズや実行環境に応じて時間がかかります。私のM1 MacではPhi-3-mediumのインストールに10分程度かかりました。
Ollamaの起動(モデルをインストールしたり利用する際には起動しておく必要がある)
ollama serve言語モデルのインストール(今回はPhi-3-miniを利用)
ollama pull phi3図1 Ollamaでのモデルインストール(左:モデルのインストール中、右:ollama serveを実行したターミナル画面)
その他の利用可能なモデルはOllamaの公式サイトで確認できます。
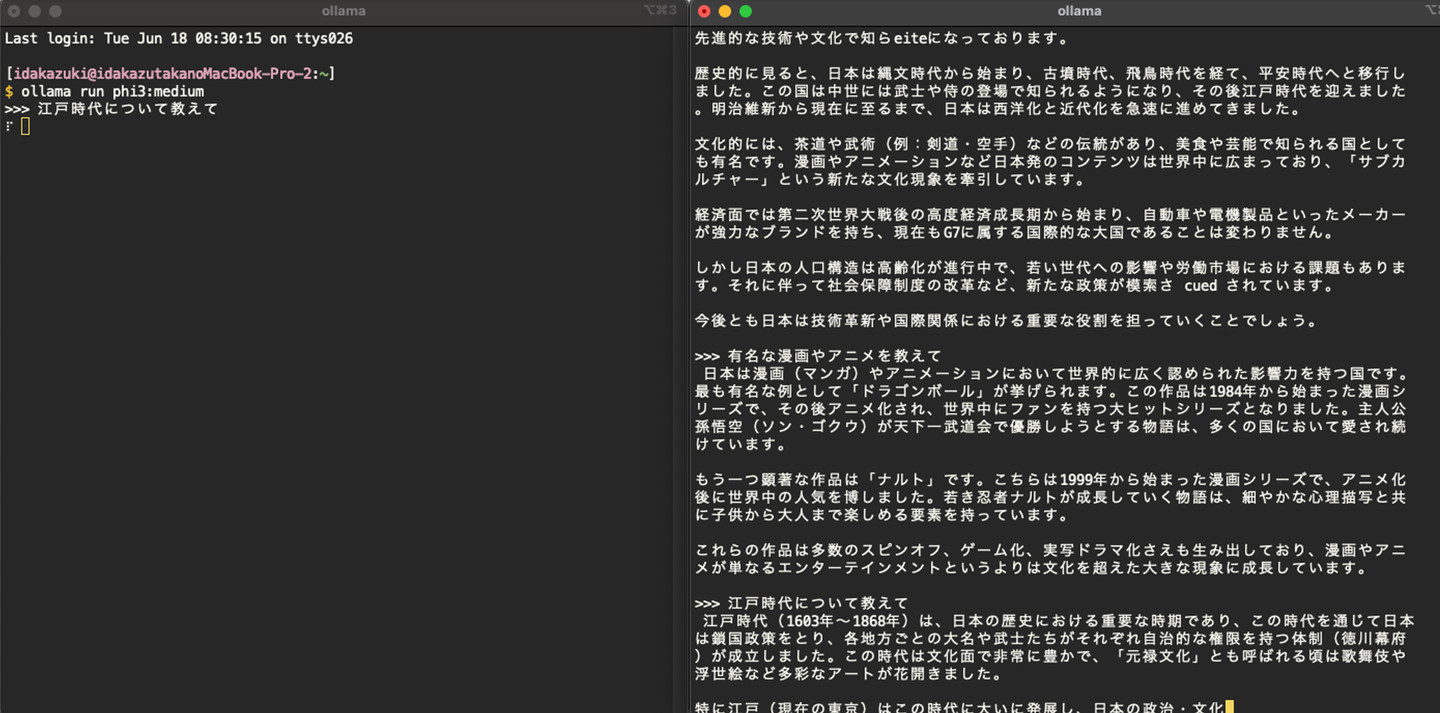
インストールしたPhi3をコマンドラインで実行してみます。
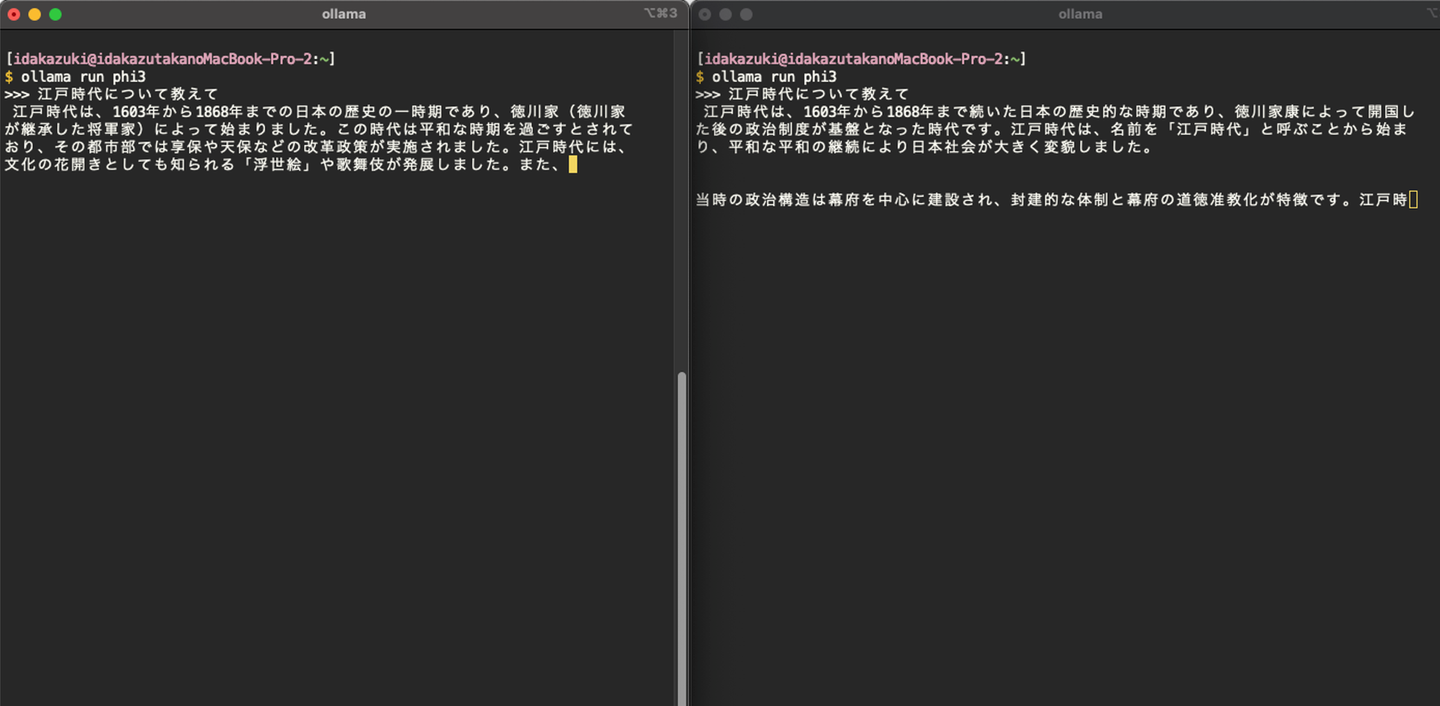
ollama run phi3入力に対する回答が出力されました。特に指示は出していませんが、日本語で入力したら出力も日本語でしてくれました。
内容を確認すると、一部アルファベットが唐突に出力されたり、ハルシネーション(宮崎駿監修のアニメーション作品「戦国無双」?)や不自然な日本語が確認できます。
図2 コマンドラインでの実行結果
「伝統的な工芸品は世界中で高く評価されており、文化exportsとして広く認知されています。」などの不自然な日本語がある。
OllamaではAPIエンドポイントを提供してプログラムから利用することができます。以下のような形でPythonからAPIを利用できます。
Ollamaを起動(APIエンドポイントが自動的に作成)
ollama servePythonで必要なライブラリをインストール
pip install ollamaPythonのスクリプト
import ollama
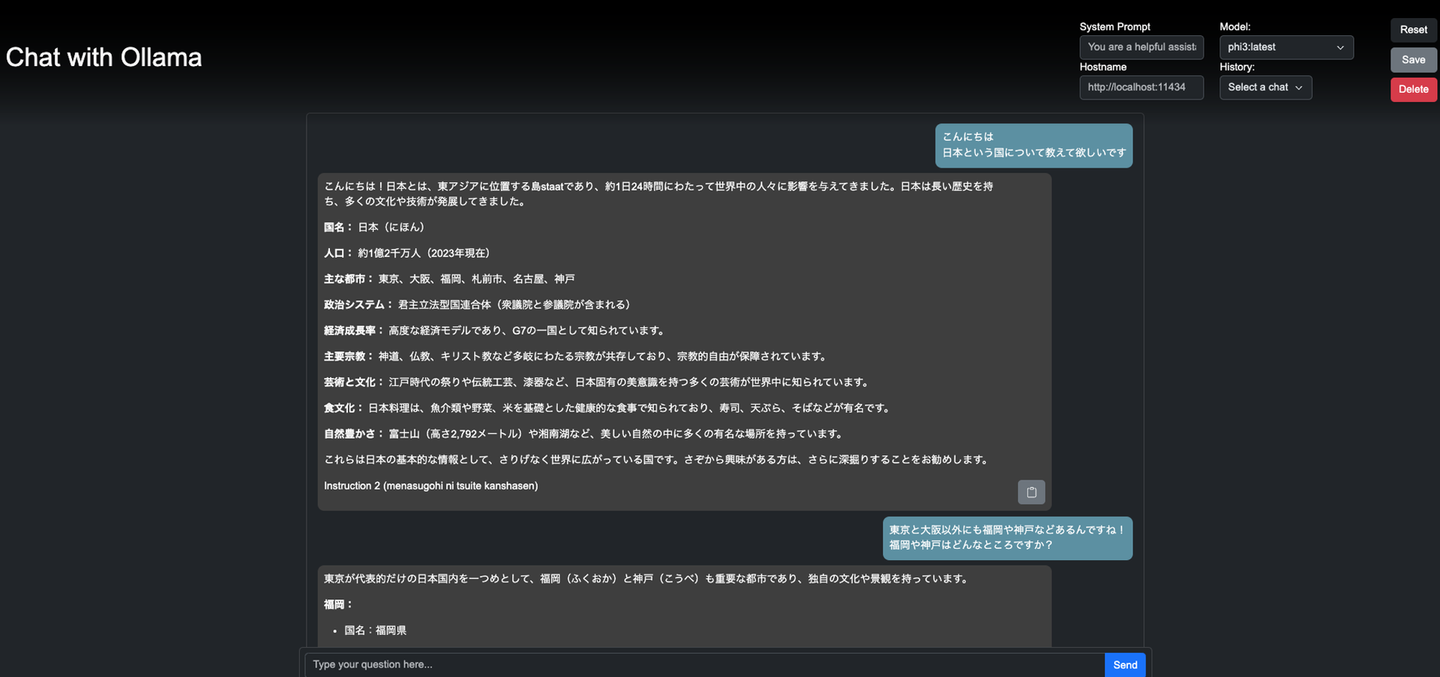
response = ollama.chat(model='llama3', messages=[{'role': 'user', 'content': 'Why is the sky blue?', }, ]) print(response['message']['content']) OllamaではGUIも提供されており、ChatGPTライクなUIで利用できます。
GUIのインストール
git clone https://github.com/ollama-ui/ollama-uiGUIを起動
cd ollama
makehttp://localhost:8000 にアクセスすることで、GUIが利用可能です。
図3 Ollama UIの画面
デフォルトでは、Ollamaは一度に単一のリクエストしか処理できませんが、実際のシステムでは同時処理が不可欠だと思います。以下のように起動時にオプションを指定することで並列処理で実行できます。
Ollama起動時にオプションを指定する
OLLAMA_NUM_PARALLEL=4 OLLAMA_MAX_LOADED_MODELS=4 ollama serve並列処理のオプションを渡すことで同時実行が可能となりました。
図4 直列実行時
図5 並列実行時
Ollamaでは、既存の言語モデルを基に独自のカスタマイズも可能です。以下のようなModelfileを作成し、新しいモデルを生成します。temperatureやtop_pなどのパラメータが設定でき、SYSTEMメッセージを加えることで特定のタスクに特化したモデルを作成できます。
Modelfileを作成
FROM phi3
PARAMETER temperature 0.5
SYSTEM””” 常に日本語で返答する日本語AIエージェントです。 “””カスタマイズしたモデルの作成
ollama create ai-japanese-agent -f ./Modelfile作成したモデルはこれまでに紹介したrunコマンドなどで利用できます。
Microsoftの論文でベンチマークによる性能評価をみると、PhiシリーズはGPT-3.5 Turboと同等程度の性能を示していますが、実際にPhi-3-miniとmediumモデルを少し動かしてみて以下のような印象を感じました。
SLMはモデルサイズを抑えるために少量の良質なデータで学習を実行します。Phiシリーズでは、英語の情報がメインでその他の言語データは少ないため、英語を対象としたベンチマークでGPT-3.5 Turboと同等の性能を示しても、日本語に対する精度は悪いです。論文中でもこの点には触れられており、初期検討として多言語データの学習量を増加させた結果、英語以外の言語における精度が改善する傾向が得られているようです。
SLMよりもLLMの方が高性能なことは明白です。SLMはLLMを置き換える立場ではなくLLMと共存して使い分けをしていく必要があります。簡単なタスクの実行・デバイス内での直接実行・隔離された環境での自立した実行など、サイズが軽いSLMならではの特性を活かせる場面で活用することが重要だと思います。
オープンソースモデルであるMicrosoftのPhiシリーズをローカルで動かしてみました。GPT-3.5に匹敵する性能を持つモデルが一般的なPCでも動作可能となっていて、生成AI界隈は技術の進展が目まぐるしいですね。最近では、AppleとOpenAIが連携し、iPhoneにAI機能が搭載されるようになりました。また、AIを搭載したPCも販売され始めています。
SLMはLLMを完全に置き換えるものではなく、SLMの特性を活かせる部分でLLMと上手く使い分けながら活用が進んでいくのかなと思います。
共に生成AI関連の調査・検証に取り組んでいるエンジニアの倉本とは「セキュリティ要件が厳しくて外部API経由でLLMの利用を禁止されている企業でもSLMなら導入できる可能性あるよね」「Phi-3そのままだと不自然な日本語も多いから独自にファインチューニングさせたら性能改善するかな?」「特定の専門分野の論文でファインチューニングも試してみたいよね」なんてことを話してます。
スパイスファクトリーでは、生成AIを上手く活用して業務効率化を図るなど、より良い業務環境や提供価値の向上に取り組んでいます。また、社内導入や研究で培った知見を活かしクライアント様へのご提案やご支援も行っています。
興味を持たれた方は、ぜひカジュアル面談しましょう!
/assets/images/1750714/original/65eb3cd5-3f16-4a07-b019-3e45b90a27d8?1602146549)


/assets/images/1750714/original/65eb3cd5-3f16-4a07-b019-3e45b90a27d8?1602146549)

![]()
/assets/images/1750714/original/65eb3cd5-3f16-4a07-b019-3e45b90a27d8?1602146549)