
はじめに
こんにちは。データ戦略部 Machine Learning Platformセクション セクション長の 高野 秀基 です。
2021年冬ごろにゼロからML組織を組成し、現在は組織長をしております。
今回のTech Blogは前後編でお送りいたします。
長文となりますので、ご興味おありの章から是非ご一読ください。
(以下、ML = Machine Learning = 機械学習となります)
・(前半:高野)バンダイナムコグループにおいてMLプロジェクトを推進することの意義
・(後半:秋山)MLプロジェクトのひとつである「パーソナライズ」を支えるML基盤をニアリアルタイム化した技術
Index
- (前半)バンダイナムコグループにおいてMLプロジェクトを推進することの意義
- 1. バンダイナムコグループの「IP軸戦略」とは
- 2. IP軸戦略に基づいた「機械学習を用いたDX」プロジェクトたち
- (ひと休み)DXに必ず機械学習の技術は必要なのか?
- Now Hiring!!
- (後半)パーソナライズを支えるML基盤をニアリアルタイム化した技術
- TL;DR
- 1. 前置き
- 2. 日次バッチ基盤の課題感
- 3. リアーキテクチャ
- 4. パイプライン内部実装におけるMLOpsエンジニアの手入れ
- 5. ML基盤のこれから
- Now Hiring!!(再)
(前半)バンダイナムコグループにおいてMLプロジェクトを推進することの意義
一言で述べると、
・「IP軸戦略」に基づいて実行される「機械学習を用いたDX」での価値創出の機会がまだまだ眠っていたこと
に尽きます。
まずは「IP軸戦略」について補足しつつ、どのような価値創出を行っているかご説明します。
(※IP = Intellectual Property = 知的財産)
1. バンダイナムコグループの「IP軸戦略」とは
「IPの世界観や特性を活かし、最適なタイミングで、最適な商品・サービスとして、最適な地域に向けて提供することにより、IP価値の最大化をはかること」
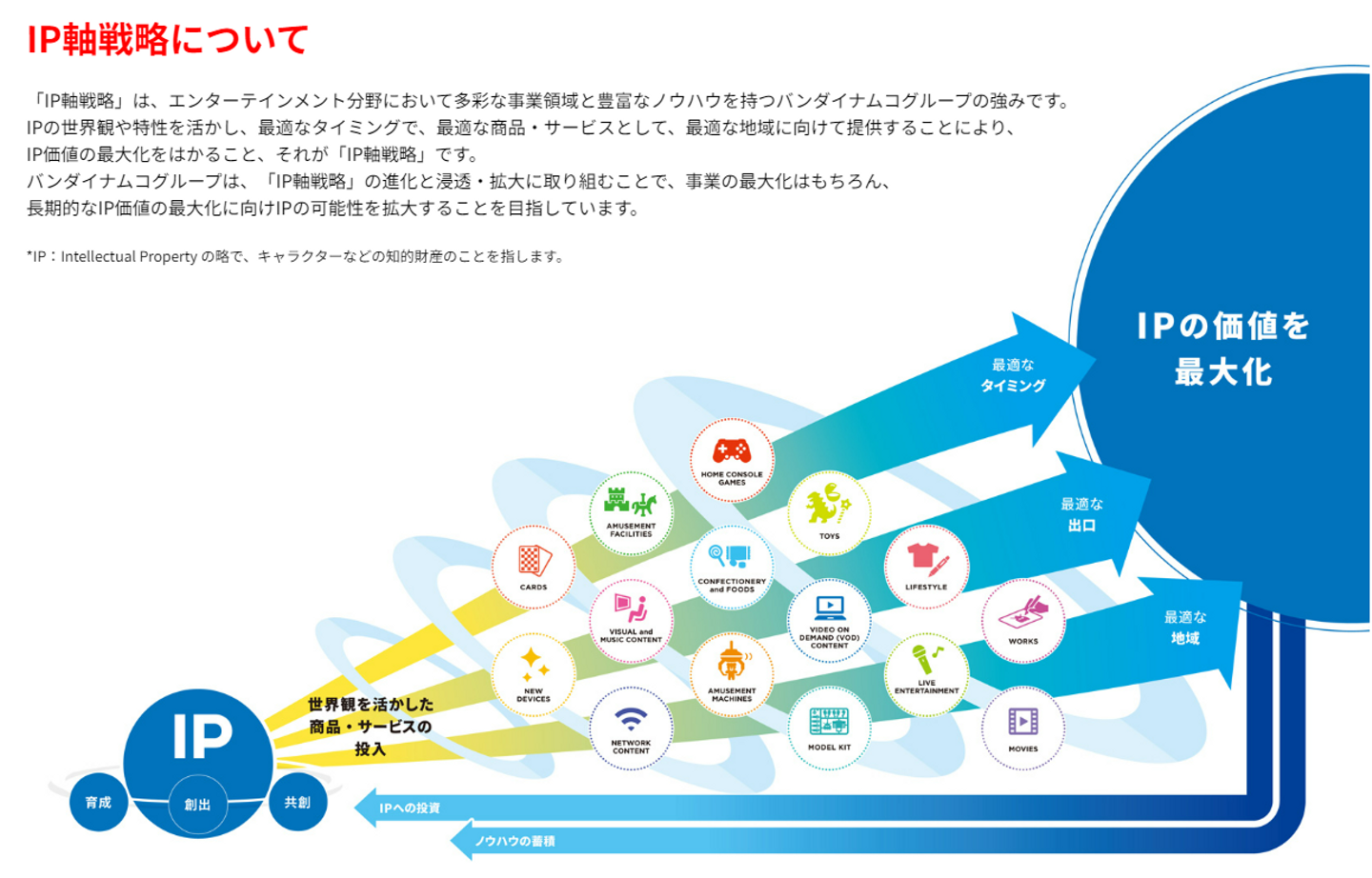
(引用:バンダイナムコホールディングス コーポレートサイトより)
2. IP軸戦略に基づいた「機械学習を用いたDX」プロジェクトたち
プロジェクトはこの2年間で下記のように複数、実行されました。
価値創出の機会がまだまだ眠っていたと言えます。
(他にも複数ありますが、代表的なものに留めています)
(1)
自社ECでのレコメンド:「パーソナライズ」技術(本記事の後半に記載)を用いたoutput = ユーザに最適な商品を1to1でデリバリーする、という価値創出
= IP軸戦略における「最適なタイミングで最適な商品を提供する」こと。
(2)
ゲーム領域での不正検知:ゲーム内の「チーター/通常ユーザ」の行動履歴をMLモデルが学習し、チーター疑いのユーザをモデルが検知することで、ゆくゆくはチーターのいないゲームを快適に楽しめるようになる、という価値創出
= そのゲームを長く楽しむためのモチベーションのひとつとなること = IP軸戦略における「IP価値の最大化をはかる」こと。
(3)
IPファンコミュニティに対する(CFMLを用いた)データ分析:IPのニュースサイトのような「IPファンコミュニティ」が、IP売上に間接的に与えた貢献金額を「反実仮想機械学習(CFML)」によって算出し、ファンコミュニティ開発の意義を再定義する、という価値創出
= この結果、IPファンコミュニティの役割である「IP価値の最大化をはかる」ための施策を強く推進できるようになること。
・(弊社におけるCFMLを用いた分析はこちらもご参考まで)
このほか、金額規模が数十億円になるMLプロジェクトも存在します。
前述した、
・「IP軸戦略」に基づいて実行される「機械学習を用いたDX」での価値創出の機会がまだまだ眠っていたこと
とは、これらの具体的なプロジェクトから抽象化された結論と言えるでしょう。
以上がこの記事の前半となります。後半では、
・MLプロジェクトのひとつである「パーソナライズ」を支えるML基盤を、どのようにニアリアルタイム基盤へと再構築したか?
について、MLOpsエンジニアの秋山よりご説明いただきます。
(余談ですが、commmuneさんがニアリアルタイム基盤を採択した理由(https://tech.commmune.jp/entry/2023/12/22/173000#課題)とほぼ同じ課題感から、弊社もニアリアルタイム基盤を開発しており、親近感を覚えております)
--------(ひと休み)DXに必ず機械学習の技術は必要なのか?--------
(注:ここでのDXは「データを活用したSystem of Engagementの開発」に限定しています)
結論から言うと短期的にNoであり、中期的にYesでしょう。
というのも、多くのDXプロジェクトは特定の技術にとらわれず、課題解決に向けた最適なアプローチを取る必要があります。
これが「短期的にNo」の理由です。
しかし反論もあります。
(a) まず、MLという手段は一連の開発の見積もり不確実性が高くなりがちです。(MLモデルのPoCが工程に必ず入ることが主な理由)
(b) また、MLモデルの挙動そのものが確率論的であり、ゆえに従来の決定論的なシステムと比べた不確実性もまた高いと言えます。
- bの解決方法はいくつかあり、
- MLの確率論を決定論に近づける技術がMLOpsとも呼べますし、
- 後述される「オニオンアーキテクチャの採用理由」も、(チーム内で不要に生まれる)不確実性を分離する活動 = ドメインモデル層にMLモデルを閉じ込め、ML/MLOpsの開発を分離する活動、とも言えます。
そして、aやbのように不確実性の高い「MLという手段」を「目的(=存在意義)」に設定した開発チームは、
そのデカめの不確実性を潰すために、
・ソフトウェア開発手法の継続的改善
・開発組織のメンタルモデル
・事業との接続性を泥臭く見出す戦術
が鍛えられます。(このあたり、詳細を言語化したいですが今回は割愛します)
つまり、
・MLの様々な不確実性から(逆説的に)開発チームが鍛えられるがゆえに
・MLを採択しないDXプロジェクトでも必ず実力を発揮するDX開発チームになれる
これが「中期的にYes」の理由です。
未来には、(費用対効果の意味でも)最適なアプローチを常に迫られるDXプロジェクトにおいて、
・ML技術を課題解決に使えるという点で競争優位性を保ちつつ
・開発チーム内で「MLをあえて使わない」意思決定も容易である(ときには、機械学習でなくルールベースを採択することがその最たる例)
という、柔軟性を持ったDX開発チームとして信頼されていくことでしょう。
----------------
Now Hiring!!
株式会社バンダイナムコネクサスでは一緒に働く仲間を募集しています!
グループ内への機械学習システムの民主化を担うMLプロダクトマネージャー募集!
グループ内への機械学習システムの基盤開発を担うMLOpsエンジニアを募集!
バンダイナムコグループのシステムに関わりたいML系職種の方、お話しませんか

(後半)パーソナライズを支えるML基盤をニアリアルタイム化した技術
TL;DR
・cloud workflows、datastream、cloud batch(spotVM)などを使って、旧バッチ基盤とコスト感とレイテンシを変えずにニアリアルタイム推論基盤を構築
・アーキテクチャ面だけでなく、パイプラインの内部実装面においても汎用的なものに置き換え、以降の案件やリファクタのニーズに対しても柔軟に対応できるようにした
1. 前置き
こんにちは。データ戦略部 Machine Learningシステムセクション MLOpsエンジニアの秋山です。
我々は、IPにまつわるニュースアプリにおいて、ユーザに最適なニュース記事を機械学習によって推薦するパーソナライズシステムを開発・運用してまいりました。
ただ、既存システムは日に1度のみ推薦を更新させる所謂日次バッチでの運用であったため、ユーザーに最新の記事を提供できずユーザー体験も抑えられておりました。
そこで、既存のバッチシステム基盤で担保できていたものを崩さず、リアルタイム性を重視した新しいパーソナライズシステムへ更改させましたので、本記事にまとめご紹介いたします。
2. 日次バッチ基盤の課題感
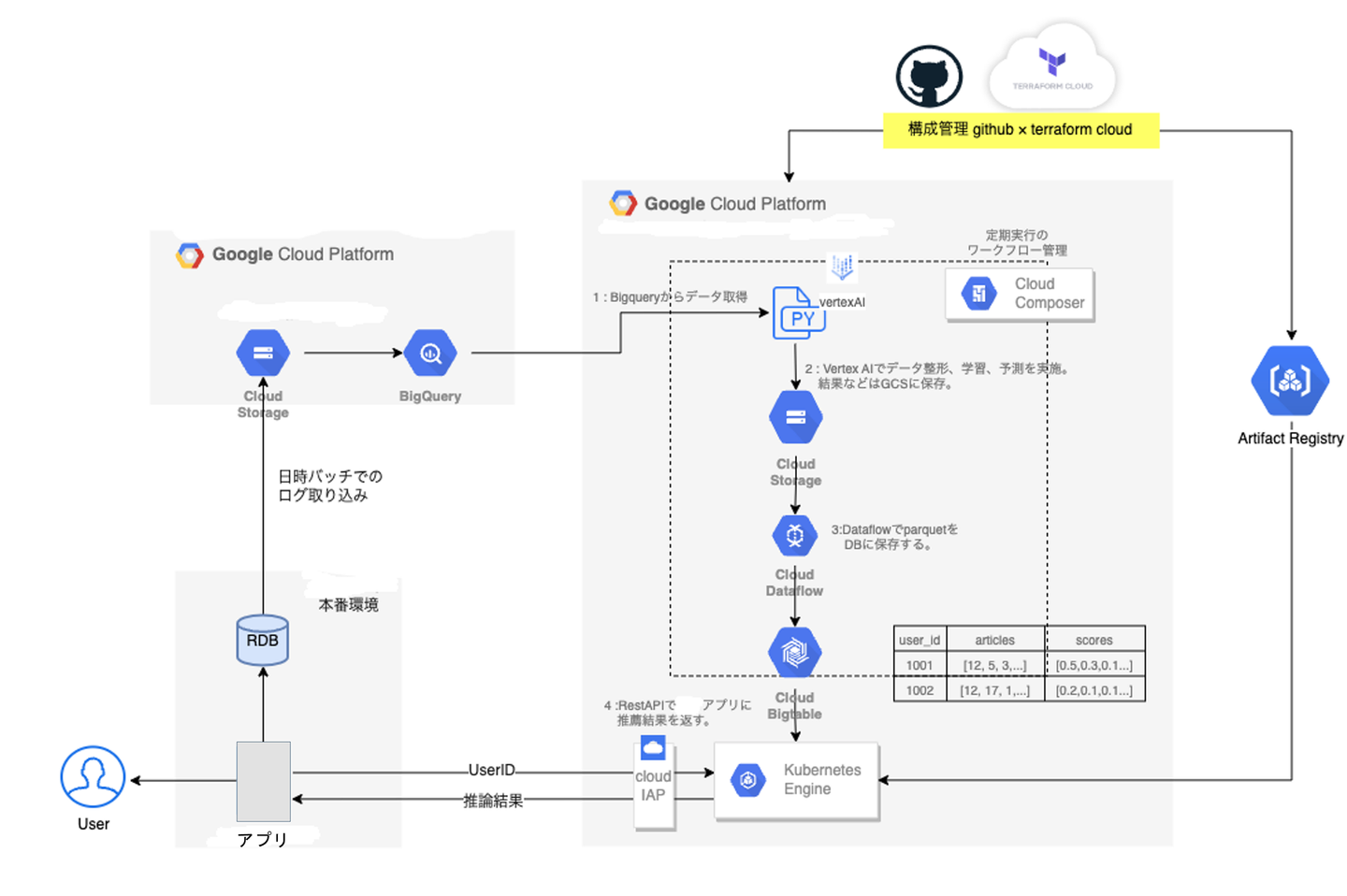
既存のバッチ基盤アーキテクチャでは、cloud composerと AI platform Jobを用いて、日に一度モデルの学習→推論を行なっていました。(LightGBMによる協調フィルタリング方式)
この場合、以下の課題があげられます。
・日に一度のみ、前日までの記事データをつかっての推薦なので当日に発行された記事を推薦できない
・ユーザとしては提供される記事が1日中変わらない
3. リアーキテクチャ
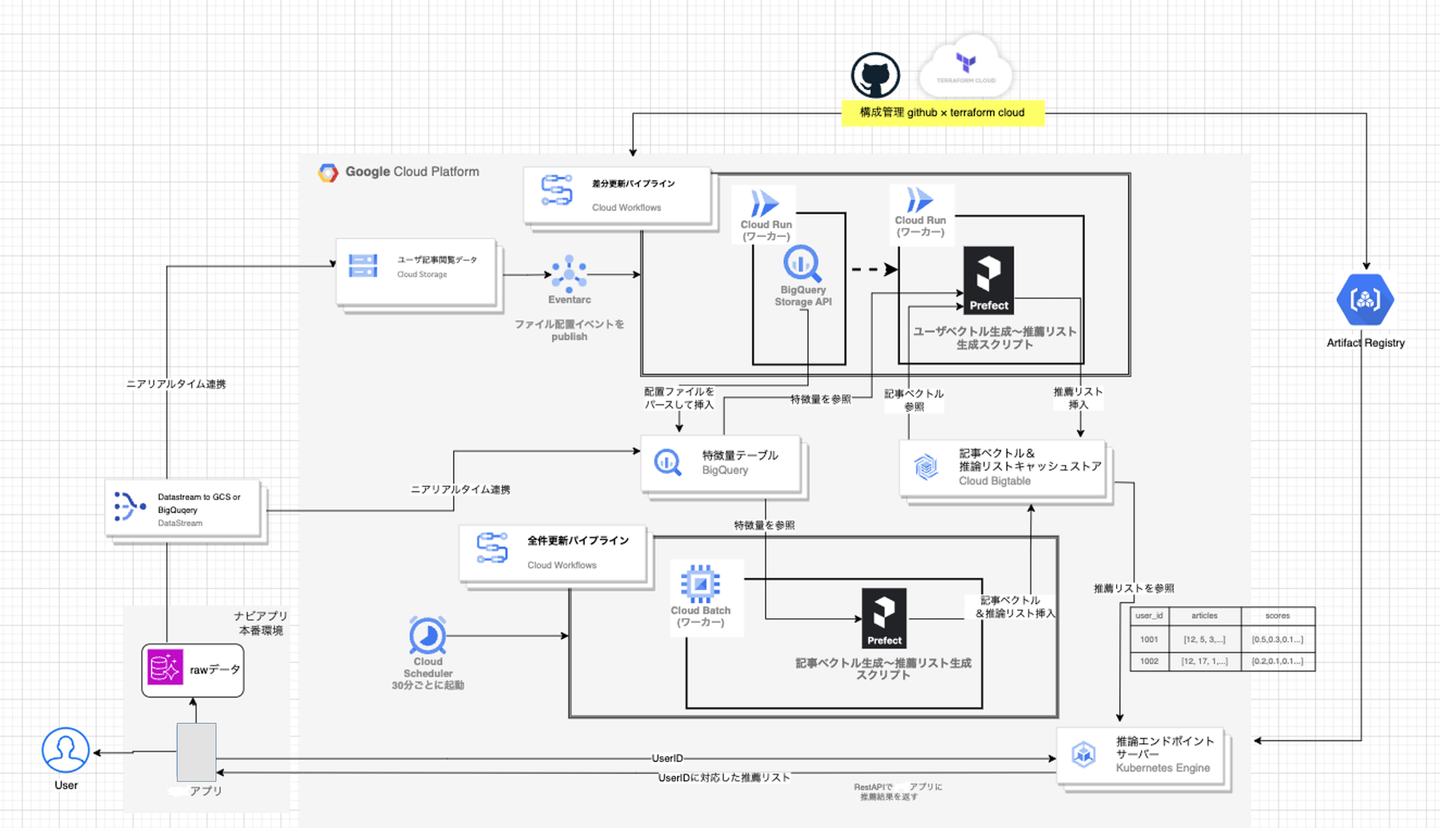
上記を踏まえて上図のようにリアーキテクチャを施しました。
今回は、推薦のロジックも協調フィルタリングから「embeddingを用いたニューラルネットによる推薦([1907.05576] Neural News Recommendation with Attentive Multi-View Learning (arxiv.org)」に切り替えたことにより、MLパイプラインの構造も大きく変更しました。
特徴を述べますと、
バッチレイヤー、スピードレイヤーに分けて網羅性と即時性を担保した
いわゆるラムダアーキテクチャです。レイヤーを複数実装するコストはあれど後述の技術によりある程度低減でき、今回の要件としても適っていたので採用しました。
ここでいうバッチレイヤーは30分ごとに記事をベクトル化し、ユーザ全件に対して推薦リストを更新する処理のレイヤーを指し、スピードレイヤーはユーザーの記事閲覧イベントごとにそのユーザの推薦リストを更新する処理を指します。
- バッチレイヤーのスケジューリングについて、新着記事の公開のスケジュールにおおよそ合わせて実行しています。これによって行動していなかったユーザに対しても最新記事を推薦できると同時に、スピードレイヤーにおいてたとえ推論処理が失敗したとしてもバッチレイヤーの実行によってカバーできる仕組みにしました。
- 処理のワーカーについて、スピードレイヤーではcloud runサービスによる迅速な推薦処理をAPIでおこなっていますが、バッチレイヤーではcloud run ジョブではなくcloud batchを用いています。cloud batchはmachine typeがcloud run ジョブよりも幅広く選択でき、spotVMも使えるのでそちらを選びました。
datastreamを用いることで、リアルタイム性が高く安定したデータ連携を最小の工数で行えた
datastreamはニアリアルタイムで多様なデータストアのデータ変更を連携できるマネージドCDC、レプリケーションサービスです。(https://cloud.google.com/datastream?hl=ja)
上記では、datastreamの出力先はBigQueryとGCSに分けております。最終的にはどちらもBigQueryの特徴量データセットに保管されるのですが、(連携対象であるユーザ行動を保管したテーブルの特徴として)行動するたびに既存レコードに対してupdateが発生するため、単純にテーブル同期するだけでは全ての行動を拾えません。
そこで、行動ログにおいてはGCSへ出力して、Eventarc + BigqueryのStorageAPI(Insert)を使いupdateされたログをすべてinsertして保持するようにしました。
cloud composerからサーバレスのcloud workflowsに変えることで、運用費を抑えることができた
cloud composerは我々のプロジェクトにおいては月に数万円ほどのコストがかかっていたサービスでした。
ワークフロー管理をcloud workflowsに切り替えたことで、月に数千円以下の低コストにでき、初期段階ではcloud run、cloud batchの運用コストを合わせてもcloud composerでのコスト以下に抑えられておりました。(現在では、アルゴリズムの変更による実行時間増加に伴い月に数万円程度になっていますが、日次バッチ基盤から数万Xの処理頻度の増加に対して、同程度のコストで抑えられております)
また、後述するパイプライン内部のフレームワーク、prefectとも相性がよいと考えます。
推論エンドポイントに関しては既存のSLOを崩さないことができた
リアルタイム推論といえばエンドポイントに推論機能を持たせ、リクエスト時に推論処理を施すアーキテクチャを想起しやすいですが、今回のリアーキテクチャでは推薦結果はキャッシュテーブルに保存→エンドポイントが参照して推薦結果を返すという機構は既存のまま変えませんでした。
これは既存のSLO要求がある程度高めであり、MLモデルのサーブに頭を悩ませる工数を最小にしたかったためでもあります。
今回再構築したこのアーキテクチャにおいては、2つのレイヤーをそれぞれ使い回すことや、完全にサーバレスにすることもできるので今後のML基盤構築にも展開しやすいと考えております。
4. パイプライン内部実装におけるMLOpsエンジニアの手入れ
今回はアーキテクチャやMLモデルの再構築だけではなく、パイプラインの内部も抜本的に改修しております。
大きなポイントとしては2つで、これは特にMLOpsエンジニアとMLエンジニアが協業してパイプラインを作ることを意識していました。
prefectの導入
prefectは軽量で使いやすいタスクオーケストレーションツールです。MLモデルのコア実装をパイプラインとして乗せる際に役に立つと考え導入しました。
特長としては以下が挙げられます。
- パイプラインを記述する際に独特な記述方法によらず、通常のpythonライクな形で処理を記述できる
- 具体的にはデコレータとして@flowや、@taskといった記述を施すだけでprefectのパイプラインとして表現できます。
- その上で、rayやdaskを用いた並列分散処理の記述も容易に可能(別途ライブラリが必要)で、かなり使いやすいと感じました。
- 特別なインフラリソースを用意する必要がなく、notebookからでもパイプラインを実行できるため、PoCの段階からでも実運用を見据えた検証が行える
- (よく比較される)Airflowと異なり、パイプラインを実行する主体(agent)とパイプラインを管理する主体を完全に分離して設計できる
- 実行管理の主体として挙げられるのはPrefect CloudというSaaSがありますが、今回はCloud workflowsで代用しました。
- この理由は、動かすパイプライン自体はタスクも少なく短い実行時間を前提に設計しているため実行が成功or失敗しただけを管理できればよく、コストのかかるPrefect Cloudを使うまでには至らないかなと感じたためです。
オニオンアーキテクチャの導入
オニオンアーキテクチャ(https://little-hands.hatenablog.com/entry/2017/10/11/075634)は、ドメイン駆動設計の中でも、比較的わかりやすく層化されたアーキテクチャです。
MLエンジニアとMLOpsエンジニアが協業的にパイプラインの実装をする際、以下の理由で役に立つと考え導入しました。
- ドメインエキスパートと設定されたMLエンジニアはドメイン層まわりを、それを補佐するMLOpsエンジニアはそれより外界を分担することで、お互いを邪魔せず協業して実装可能
- 特に、prefectの実装部分をアプリケーション層(我々ではユースケース層と呼称していました)に設定することでパイプラインとしての方向性は失わせずにすみました。
- PoC段階→運用段階へ進むにつれて、データの保管・参照先が変更することは避けられないため、依存性逆転を意識した設計が必要
- クリーンアーキテクチャまでいくと細分化が進みすぎて逆にわかりづらく、学習や導入コストも高くなる印象を受けたので導入は見送り
5. ML基盤のこれから
以下は、コストダウンの観点で改修の余地があると考えております。
- 記事をembedding化するモジュールでは、BERTによる対照学習させたモデルを用いてベクトルにしているが、これを直接、Embeddingを返す外部APIに置き換えられないか
- パイプライン内部のアルゴリズムを最適化し、処理時間低下、コストダウンを図れないか
そして今後、我々がML基盤の構築を進めていく際に常に考えたいことは以下が挙げられます。
- MLコア部分をレイテンシの問題からなるべく遠ざける
- マルチテナント性や横展開の可能性を考慮して、n倍に案件が増えても開発・運用コストをn倍以下に抑える
- 少数精鋭、コミュニケーションを重視した体制づくり
そして今回は、チームの方々の綿密な協力があってこその達成だったと思います。
この場ではありますが誠に感謝いたします。
Now Hiring!!(再)
株式会社バンダイナムコネクサスでは一緒に働く仲間を募集しています!
グループ内への機械学習システムの民主化を担うMLプロダクトマネージャー募集!
グループ内への機械学習システムの基盤開発を担うMLOpsエンジニアを募集!
バンダイナムコグループのシステムに関わりたいML系職種の方、お話しませんか

/assets/images/21398270/original/3d6bad77-a316-4188-9b42-9cc30fa12eb8?1750395813)


/assets/images/21398270/original/3d6bad77-a316-4188-9b42-9cc30fa12eb8?1750395813)




/assets/images/13122158/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1682487997)


