
ウォンテッドリーでバックエンドエンジニアをしている冨永(@kou_tominaga)です。Wantedly Visit では、スカウト機能を担当するマイクロサービス(以降「スカウトサービス」)を、主要機能を担う Rails ベースのモノリス(以降「本体サービス」)へ統合しました。
本記事は「【計画編】 スカウト機能のマイクロサービス化を辞める判断について」で紹介した統合プロジェクトの続編です。前編では、なぜマイクロサービスをモノリスへ戻す判断をしたのか、その背景や意思決定について紹介しました。本記事では、その後実際に行った統合作業について、具体的な移行方法や運用上の工夫を紹介します。まだ前編を読んでいない場合は、先にそちらを読むと背景が分かりやすいと思います。
目次
はじめに
gRPC メソッドを統合する 4 ステップ
Step 1. gRPC メソッドの呼び出し元を特定する
Step 2. 統合先に gRPC メソッドを実装する
Step 3. 呼び出し元の向き先を切り替える
Step 4. 旧サービス側に呼び出しが残っていないことを確認する
統合時の問題点と解決策
依存の多い gRPC メソッドでは、1 PR の差分が肥大化し、移行方法を都度検討する必要があった
統合先とクラス名・名前空間がコンフリクトした
統合の結果
まとめ
はじめに
なぜマイクロサービスをモノリスへ戻したのか、その背景や意思決定については前編記事で紹介しました。本記事では続編として、71 個の gRPC メソッドを停止や障害なく再統合するために実施した「4 ステップの移行戦略」と、発生した問題とその解決策を紹介します。
実際の移行では、単純にコードを移植するだけでは済まず、デプロイ中の互換性維持や巨大な PR、名前空間の衝突など、長期間運用されたマイクロサービス特有の課題にも向き合う必要がありました。本記事では、そうした課題に対して、どのような方針で安全に段階移行を進めたのかを実践ベースでまとめています。
gRPC メソッドを統合する 4 ステップ
gRPC メソッドごとに次の 4 ステップを繰り返しました。
- gRPC メソッドの呼び出し元を特定する
- 統合先に gRPC メソッドを実装する
- 呼び出し元の向き先を切り替える
- 旧サービス側に呼び出しが残っていないことを確認する
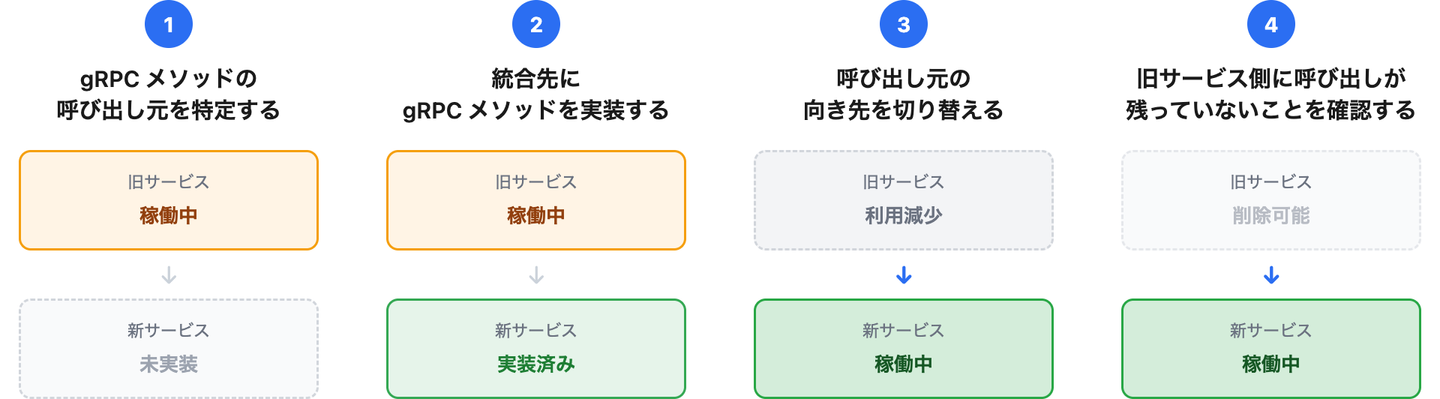
この順序で 4 ステップに分ける理由は、「新実装の公開」と「向き先の切り替え」を別々のリリースに分けるためです。これらを 1 つのリリースにまとめると、デプロイの過程で新旧サーバーが混在する瞬間に不整合が起きます。
Wantedly Visit では、本番リリース時にカナリアリリースとローリングデプロイを採用しています。カナリアリリースでは、一部のサーバーだけを先に新バージョンへ切り替え、問題がないことを確認しながら段階的に全体へ展開します。これにより、障害発生時の影響範囲を限定できます。また、各サーバーの入れ替えはローリングデプロイで行っており、既存サーバーを停止せず、新旧バージョンのサーバーを一定期間共存させながら順次置き換えています。これにより、サービス停止なしでリリースできます。
一方で、これらのデプロイ方式では「新旧サーバーが同時に存在する時間」が必ず発生します。そのため、gRPC メソッドの実装追加と呼び出し先切り替えを同時に行うと、バージョン差異による不整合が発生します。
たとえばスカウトサービスが自分自身の gRPC を呼んでいる API の場合、gRPC の実装と切り替えを同時にリリースしても一見問題ないように見えます。しかし、デプロイ中は新旧サーバーが同時に動くため、以下のようなケースで呼び出しが落ちます。
- カナリアリリース時:新バージョンのサーバーが統合済み gRPC メソッドを呼び出した際、ロードバランサによって旧バージョンのサーバーへルーティングされると、旧サーバーにはその gRPC メソッドが存在せずエラーになる
- ローリングデプロイ時:デプロイ中は新旧サーバーが混在するため、上と同じ理由でエラーになる
このため、新実装の公開 → 向き先切り替えの順に、それぞれを別リリースとして進める必要があります。Step を分けているのはこの制約に対応するためです。
以下、それぞれのステップを具体的に説明します。
Step 1. gRPC メソッドの呼び出し元を特定する

gRPC メソッドの実行ログをもとに、どの gRPC メソッドが実際に利用されており、どこから呼び出されているかを特定しました。長く運用されたマイクロサービスでは、gRPC メソッドの呼び出し元をコードベースだけで追跡するのが難しくなります。サービス間の依存関係が分散・複雑化し、複数のサービス・バッチ・運用ツールなどから呼び出されるためです。
また、静的解析ではデッドコードも対象に含まれるため、実際の利用状況との乖離が発生します。そのため、統合対象の gRPC メソッドを把握する際は、実行ログの確認が有効でした。
Step 2. 統合先に gRPC メソッドを実装する

呼び出し元を特定できたら、本体サービス側に同等の gRPC メソッドを実装します。ここで重要なのは、新しく書き直すのではなく、既存実装をできる限りそのまま移植することです。目的は、挙動を維持したままコードの配置先だけを移すことであり、設計改善やリファクタリングは移行後の別タスクとして切り出しました。
移植と書き直しを同時に行うと、不具合が発生したときに移植によるものか、仕様変更によるものかを切り分けにくくなります。また、コードレビューの負荷が高まり、統合期間の長期化につながります。統合の遅延は他の開発にも影響するため、まずは迅速かつ安全に移行を完了させることを優先しました。
Step 3. 呼び出し元の向き先を切り替える

gRPC メソッドの実装が完了したら、Step 1 で特定した呼び出し元を順に切り替えていきます。本体サービスから自身の gRPC メソッドを呼び出している箇所については、本来は gRPC エンドポイントを削除し、アプリケーションコードの直接呼び出しへ置き換える方が自然です。
しかし、実際にはその都度「ロジックをどこへ配置するか」「責務をどう整理するか」といった設計上の判断が発生します。Step 2 と同様に、ここでリファクタリングまで着手すると統合期間が長期化し、他の開発にも影響します。そのため、移行期間中は大きな設計変更を行わず、まずは向き先の切り替えを優先しました。設計改善については、移行後の backlog に切り出しています。
Step 4. 旧サービス側に呼び出しが残っていないことを確認する

切り替え後、一定期間経過したあとに再度アクセスログを確認し、旧サービス側への呼び出しが残っていないことを確認します。リリース直後だけを見て「すでに呼ばれていない」と判断すると、把握できていなかった経路からの呼び出しを見落とし、旧サービス停止時の障害につながります。
一定期間ログを監視し、呼び出し数が 0 になっていることを確認できたら、その gRPC メソッドの移行は完了です。
統合時の問題点と解決策
統合方法は 4 ステップとして整理できますが、実際の移行ではさまざまな問題が発生しました。ここでは、その中でも特に印象的だった 2 つを紹介します。
- 依存の多い gRPC メソッドでは、1 PR の差分が肥大化し、移行方法を都度検討する必要があった
- 統合先とクラス名・名前空間がコンフリクトした
依存の多い gRPC メソッドでは、1 PR の差分が肥大化し、移行方法を都度検討する必要があった
gRPC メソッドが依存するコード(モデル・Service・Job など)を 1 つの PR にまとめると、差分が 1 万行を超え、レビューや動作確認が現実的ではなくなりました。レビュアーが差分を把握しきれず、自分自身も「どこを変更すると何が壊れるのか」を把握しきれない状態に陥ります。
そのため、依存が多い gRPC メソッドについては、1 回で移植するのではなく、複数の PR に分割して段階的に統合しました。移行前には、ドメインに詳しい担当者が中心となり、移行順序・PR の分割単位・テスト方針を事前に整理しています。
具体的には、以下の単位で PR を分割しました。
- 依存している Service クラスの移植
- 依存している Job の移植
- gRPC エンドポイント本体の移植
- 呼び出し元(複数リポジトリ)の向き先切り替え
特に依存の多い gRPC メソッドでは、 Service / Job 単位で依存グラフを整理しておくと進めやすいです。そのうえで、他の gRPC メソッドからも利用される共通部分(共通 Service や Job)を先に移植することで、後続の移行では必要なコードがすでに本体サービス側に存在する状態になります。結果として、移行時の重複作業や並行作業時のコンフリクトを減らせました。
また、PR を機能単位で小さく分割したことで、レビューや動作確認も進めやすくなっています。
統合先とクラス名・名前空間がコンフリクトした
スカウトサービスと本体サービスは独立して発展してきたため、同名のクラスや類似した名前空間が両方に存在していました。移植のたびに「既存の名前空間へ統合するか」「別名の名前空間として配置するか」、「リネームするか」「そのまま維持するか」といった判断が必要になり、意思決定コストが大きくなっていました。
そこで、統合専用の名前空間(例: Scout:: のような接頭辞)を用意し、移植したコードはまずそこへ配置するルールを定めました。名前空間の整理は移植完了後にまとめて行う方針とし、移植中には設計判断を極力持ち込まないようにしています。
このルールにより、移植のたびに「どこへ何を配置するか」を検討する必要がなくなり、移植 PR を機械的に進められるようになりました。
並行作業では、このような「迷いやすいポイント」を都度議論するのではなく、先にルール化しておく方が効率的です。多少不格好でも一旦配置場所を固定してしまえば、判断コストを大きく減らせます。整理はあとからまとめて行う方が、結果として短期間で安定した移行につながりました。
また、統合では紹介した 2 点以外にも、細かな課題が数多く発生しました。それでも統合を完遂できたのは、チーム内で「定期的にコミュニケーションを取ること」と、「小さなことでも積極的に情報共有すること」を継続して意識できていたことが大きかったと感じています。
困ったときに相談・共有することはもちろん重要ですが、それ以上に「他の人も同じ問題に遭遇しそうだ」と感じた時点で先回りして共有することが効果的でした。並行作業では同じ問題が再発しやすく、早めに共有しておくことで手戻りや調査コストを減らせたためです。
統合の結果
統合によって、スカウト機能の開発が本体サービス内で完結するようになり、機能追加や改修のたびに複数サービスを横断して変更する必要がなくなりました。その結果、変更影響の把握やデプロイが容易になり、スカウト機能まわりの開発・運用コストを下げられています。
今回の再統合は、スカウト機能の大きな改善が一段落したタイミングで着手しており、並行する大規模な機能開発が少ない時期を選べたことで、開発チーム全体への影響も最小限に抑えられました。
一方で、再統合を後ろ倒しにしていれば、移植対象の gRPC メソッドや依存関係はさらに増え、移行コストも大きくなっていたはずです。技術的負債を抱えたまま機能追加を続けていた状態だったため、このタイミングで再統合に踏み切れたのは結果的に良い判断でした。
まとめ
今回の再統合では、「理想的な再設計」よりも、「安全に素早く段階移行できること」を優先しました。移植時のリファクタリングや設計改善を極力後回しにし、「まずは互換性を維持したまま移行を完了させる」という方針を徹底したことで、大きな障害なく 71 個の gRPC メソッドを統合できています。
また、移行を進める中では、技術的な難しさだけでなく、「どこまでを今回やるか」をチーム内で揃え続けることも重要でした。判断コストを減らすためにルールを固定し、細かな課題も積極的に共有したことで、並行作業でも大きく停滞せず進められています。
本記事が、同じようにマイクロサービスの再統合やサービス境界の見直しを検討している方の参考になれば幸いです。
/assets/images/16907545/original/ec791cd3-ea53-45e2-bc6f-a1262b413594?1753696883)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


