こんにちは!AndroidエンジニアのYukiです! プログリットにおけるAndroidアプリ開発は、全てKotlinを採用しています。 そこで、今回は、Effective Kotlinという書籍を読んで、学んだことをプログにまとめようと思います。
Kotlinってどんな言語なの? Kotlinは、2011年7月20日、JetBrains社によって開発されたオブジェクト指向プログラミング言語です。
余談ですが、Kotlinの開発拠点としていた、JetBrains社の研究所 (ロシアのサンクトペテルブルグ) 近くの コトリン島 にちなんで、命名されたそうです。
特徴1:Safety Kotlinは、null安全を取り入れています。例えば、Javaの場合、 NonNull と Nullable は区別されておりません。故に、適切にnullチェックを行わなければ、 NPE (Null Pointer Exception) が発生してしまい、アプリがクラッシュする原因になります。 では、実際にJavaとKotlinのコードを見てみましょう。
int a // OK
int a = 0 // OK var a: Int // Compile Error
var a: Int = null // Compile Error
var a: Int = 0 // OK もちろん、Kotlinでは、変数にnullを代入できないわけではありません。型パラメタの後ろに ? をつけてあげることで、nullの代入が可能です。
var a: Int? // OK
var a: Int? = null // OK ただし、 NonNull と Nullable の区別は、Kotlin初学者からすると、煩わしく感じてしまう可能性があります。 (僕がそうでした・・笑)
「この変数にはnullが入るかもしれないから、とりあえず、 Nullable で変数を定義しておこう」という思考停止はやめましょう。笑
常に「この変数にはnullが入る可能性があるのだろうか?どんな場合にnullが入り得るのか?」と吟味し、変数の定義を考えるべきですね。
以下、余談ですが、null参照の考案者、Charles Antony Richard Hoare(イギリスの計算機科学者)は、2009年のとあるカンファレンスにて、null参照を発明したことに対して、「被害額10億ドルにも相当する誤りだ」、と謝罪したそうです。以下、日本語訳を記載します。
私はそれを10億ドルの失敗と呼んでいます。その頃、私は、オブジェクト指向言語の参照に対する、 最初のわかりやすい型システムを設計していました。私の目標は、 どんな参照の使用も全て完全に安全であるべきことを、コンパイラにそのチェックを自動で行ってもらって保証することだったのです。 しかし、null参照を入れるという誘惑に打ち勝つことができませんでした。それは、単純に実装が非常に容易だったからです。 これが無数のエラーや脆弱性、システムクラッシュにつながり、過去40年で10億ドルの苦痛や損害を引き起こしたであろうということなのです。 特徴2:Simple Kotlinは、Javaと比べ、シンプルに記述することが可能です。特に、コレクション処理の機能が強力ですね。
map (コレクションの各要素について、加工した結果をListで返却する) filter (コレクションの各要素について、結果に合致する要素をListで返却する) distinct (コレクション内の重複された要素が削除されたListを返却する) Java8から、 Stream API が実装され、Javaも機能が充実してきました。しかし、JavaとKotlinのコードを比較しても、一目で何の処理をしているのかが分かりやすくなっています。 以下、年齢が30歳以上のユーザを抽出して、そのユーザのidをListにする実装を見てみましょう。
List<User> list = [ ... ];
List<Integer> idList = list.stream()
.filter(u -> u.getAge() >= 30)
.map(u -> u.getId())
.collect(Collectors.toList()); val list = listOf( ... )
val idList = list.asSequence()
// 年齢が30歳以上の要素を取得します
.filter { it.age >= 30 }
// UserクラスのListをidのListに変換します
.map { it.id }
// List型に変換します
.toList() 特徴3:Multiplatform Kotlinは、様々なプラットフォーム上で動作します。 例えば、スマートフォンアプリの開発では、 KMM (Kotlin Multiplatform Mobile) というSDKを使えば、iOSとAndoridOSのビジネスロジックを共通化することができます。 また、KotlinはJVM上で動作可能なプログラミング言語のため、バックエンド開発でも採用されています。 さらに、Kotlin/JSを使えば、Javascriptにトランスパイルできるため、フロントエンド開発でのDOM操作も可能になります。 つまり、Kotlinを習得すれば、様々なアプリケーション開発に対応可能なのです。
Effective Kotlinを読んで学んだこと 今回は、Effective Kotlin を読み、大切だなと思ったこと、面白いなと思ったことを抜粋して、共有しようと思います。
可変な値より、不変な値を使いなさい 可変 (mutable) な値と不変 (immutable) な値を見てみましょう。 変数を定義する際、 var を使えば、値の再代入は可能です。一方、 val を使えば、値の再代入はできません。
var a: Int = 10
a = 20 // OK
val b: Int = 10
b = 20 // Compile Error また、 List や Map などのコレクションにも、要素の変更が可能なオブジェクトと、そうでないものが区別されています。 MutableList を使えば、要素の変更が可能であるのに対して、 List を使うと、要素の変更はできません。
val mutableList: MutableList<Int> = mutableListOf(1, 2) // [1, 2]
mutableList[0] = 3 // OK
val immutableList: List<Int> = listOf(1, 2) // [1, 2]
immutableList[0] = 3 // Compile Error 一見すると、可変な値の方が取り扱いやすそうですね。しかし、可変な値を扱う場合、危険が伴います。
値が書き変わる箇所がたくさんあり、ロジックの理解がしづらい。 複数のスレッドから値が書き変わる場合、同期が難しくなる。 つまり、変数を定義する際は、できる限り、 val や MutableList などの、不変な値を使用しましょう。
ここからは、余談ですが、以下の組み合わせの場合、どちらが推奨されるのでしょうか??
// (1)
// 不変 (immutable) + 可変 (mutable)
val mutableList = mutableListOf<Int>()
// (2)
// 可変 (mutable) + 不変 (immutable)
var list = listOf<Int>() Effective Kotlinでは、(2) を推奨しております。 (1)の場合、list内の各要素が個別に書き換え可能になってしまうのに対して、(2) の場合、オブジェクト自体の変更が可能になります。つまり、(2) の方が、リスト内の要素の管理がしやすくなります。
Nullを正しく扱いなさい Kotlinでは、null安全を取り入れています。つまり、 NonNull と Nullable が区別されています。 nullを許容する場合は、型パラメタの後ろに、 ? をつけます。 また、 NonNull のデータ型に、 Nullable のデータ型を代入したい場合は、 !! を変数の後ろにつけます。
var a: Int = 0
var b: Int? = 3
a = b!! // OK ただ、この強制アンラップは、非常に危険を孕んでおり、 NPE (Null Pointer Exception) により、アプリがクラッシュする起因となります。
ここで、大切なことは、そもそもnullが何を意味するものなのかを考える必要があります。
null = 値が設定されていない or 除去された と言う意味合いが強いです。
つまり、変数を定義する際、どんな値が入りうるのかを考える必要があります。 (Kotlinを初めて触った際、全ての変数を Nullable にして、面倒なことを考えないようにしてました。笑)
ここで、 Nullable な変数を定義する際、この変数の取り扱いはやや煩雑です。 Nullable の値は、 NonNull の値と同じように扱えず、コンパイルエラーが頻繁に発生します。 (これが非常にややこしいところですね。)
var str: String? = null
var length = srt.length // Compile Error
var length = str?.length // OK また、ライブラリなどを使っていると、プロパティに NonNull のデータを代入する必要があるのに、代入したい変数は Nullable で定義されているってことがよくあります。 この場合、 ?: (エルビス演算子) を使い、 NonNull のプロパティに、 Nullable で定義した変数を設定することができます。
var yourAge: Int? = null
val picker = findViewById<NumberPicker>(R.id.picker)
picker.displayedValues = yourAge // Compile Error
picker.displayedValues = yourAge ?: 20 しかし、エルビス演算子を使って、この状況を回避すればいい、ということでもありません。
処理内容を吟味し、例外をスローしたり、 return するなど、適切な処理内容を、場に応じて、使い分けていく必要があります。
// 例外をスローする場合
picker.displayedValues = yourAge ?: throw Exception("不正なデータです")
// 処理を中断する場合
picker.displayedValues = yourAge ?: return インライン関数 インライン関数とは、以下の通り、 fun の前に inline がつけられた関数を指します。よくライブラリ内の関数に使用されていますね。
public inline fun repeat(times: Int, action: (Int) -> Unit) {
for (index in 0 until times) {
action(index)
}
} インライン関数とはコンパイル時に、呼び出し元の関数内に、処理を展開してくれます。これにより、関数呼び出しに伴うオーバーヘッドを軽減してくれます。
// コンパイル前
fun main(args: Array<String>): Unit { hello() }
private fun hello() { print("Hello") }
// コンパイル後
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
// -------------------------------------------
// 関数呼び出さずに関数の内容をそのまま実行している
// -------------------------------------------
String var1 = "Hello";
System.out.print(var1);
// -------------------------------------------
}
private static final void hello() {
String var0 = "Hello";
System.out.print(var0);
} ただし、インライン関数は、コンパイル後のプログラムが肥大化し、ファイルサイズが大きくなる可能性もあるので、要注意です。
また、インライン関数の特徴として、 reified を一緒に使うことで、ジェネリクスを具象化できる、というメリットもあります。ジェネリクスは、コンパイル時に、型の情報が欠落してしまうため、関数内から、そのジェネクリクスにアクセスできません。しかし、インライン関数と reified を使うことで、コンパイル時に型情報が欠落せず、ジェネリクスにアクセスできます。
fun <T> printTypeName() {
// コンパイル時は型の情報が削除されるため
print(T::class.simpleName) // ERROR
}
inline fun <reified T> printTypeName() {
// T と言う値が削除されず、エラーにならない。
print(T::class.simpleName)
} 使い所として、例えば、 Retrofit でサーバから取得した結果 (Jsonデータ)を、 Moshi を使って、Kotlinオブジェクトにデコードする際の共通関数に使用できます。
inline fun <reified T> Response<*>.getErrorResponse(moshi: Moshi): T? {
val parsed = moshi.adapter(T::class.java)
val response = errorBody()?.string()
if (response != null) {
return parser.fromJson(response)
}
return null
}
// サーバから取得したレスポンス
val response: Response<SuccessEntity> = ...
// response を SuccessEntity にデコードする
val decoded: SuccessEntity = response.getErrorResponse(moshi = moshi) コレクション処理 今回は、Kotlin の標準ライブラリにある、 Iterable と Sequence を取り扱って、ご説明します。 Iterable と Sequence は非常に似ており、同じようなメソッドも用意されています。 ※) Iterable の例として、 List を取り上げます。
// ["four", "three", "two", "one"]
val sequence = sequenceOf("four", "three", "two", "one")
// ["four", "three", "two", "one"]
val list = listOf("four", "three", "two", "one") この2つのAPIの違いは何なのでしょうか?
処理の流れが異なり、場合によって、 Sequence を使う方が、処理速度が早くなります。
では、 Sequence を使うと、速度が早くなるユースケースを考えてみましょう。
// Sequence
sequenceOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
// Prints: F1, M1, E2, F2, F3, M3, E6,
// List(Iterable)
listOf(1, 2, 3)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.forEach { print("E$it, ") }
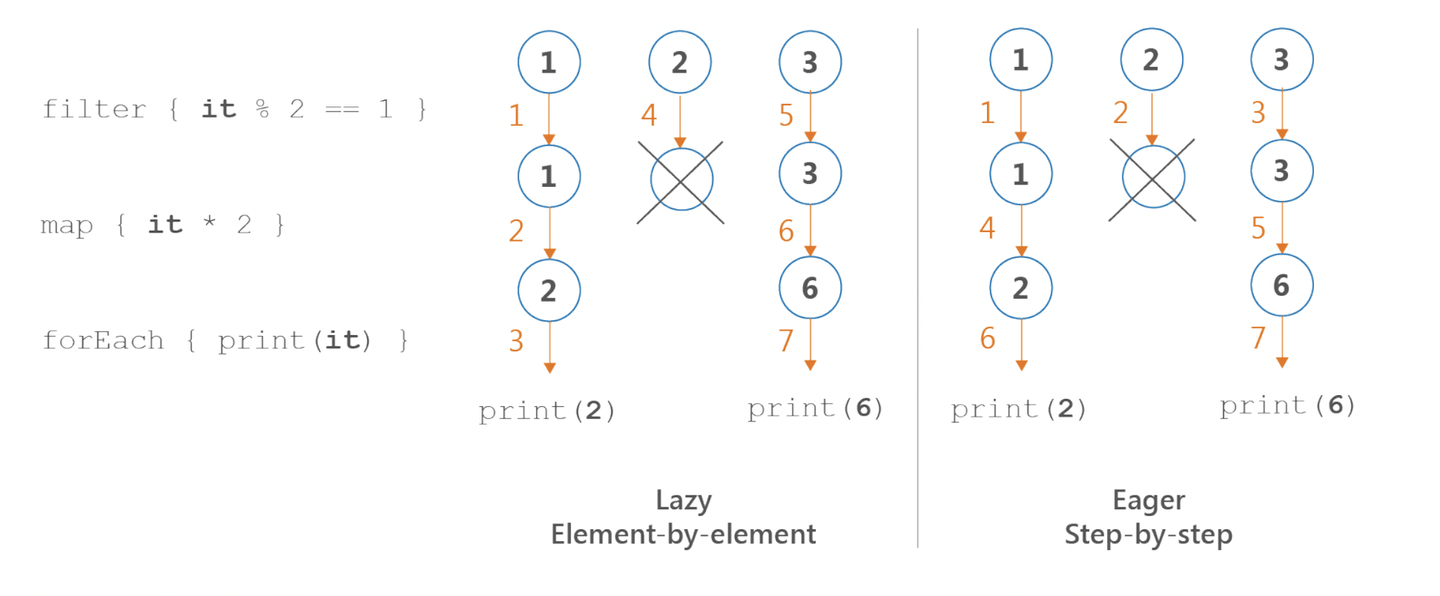
// Prints: F1, F2, F3, M1, M3, E2, E6, この処理をビジュアル化したものが以下の図です。 (左が Sequence 、右が Iterable です。)
この処理は計算量が同じですが、処理の流れが違うことがわかると思います。 上記の例は、どちらも同じ計算量ですが、別の処理を例に見てみましょう。
// Sequence
(1..10).asSequence()
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.find { it > 5 }
// Prints: F1, M1, F2, F3, M3,
// Iterable(List)
(1..10)
.filter { print("F$it, "); it % 2 == 1 }
.map { print("M$it, "); it * 2 }
.find { it > 5 }
// Prints: F1, F2, F3, F4, F5, F6, F7, F8, F9, F10, M1, M3, M5, M7, M9,
計算量が違うことがわかります。
find 関数は、条件を満たす最初の値を返却する関数です。 List を使用すると、 filter 関数が全要素に対して適用した後、 map 関数が実行され、最後に find 関数が実行されます。一方、 Sequece は要素ごとに filter 関数、 map 関数、 find 関数を実行するため、 List に比べて計算量を削減できます。
また、 Sequence を使用すると、無駄なコレクション (オブジェクト) が生成されないので、メモリの節約ができます。
val numbers = listOf(1,2,3,4,.......)
// Iterable(List)
numbers
.filter { it % 10 == 0 } // 1 collection here
.map { it * 2 } // 1 collection here
.sum()
// In total, 2 collections
// Sequence (ListをSequenceに変換してから処理をしている)
numbers
.asSequence()
.filter { it % 10 == 0 }
.map { it * 2 }
.sum()
// No collections created ただし、 Sequence を使うと、かえって処理が遅くなってしまう場合もあります。また、 Sequence に変換してから処理開始して、処理終了後に、 List に変換する、となった場合、可読性が落ちてしまう可能性もあります。
Sequence と Iterable のどちらを使うべきか、に関して、パフォーマンスを優先したいのか?可読性を担保したいのか?など、何が大切なのかを考えて、使用してください。
バリュークラス バリュークラスとは、以下の通り、 class の前に、 value をつけたクラスを指します。 注)引数は1つに限ります。
@JvmInline
value class Name(private val value: String) {
// ...
fun greet() {
print("Hello, I am $value")
}
} バリュークラスを使うことで、メモリ使用を抑えることができます。 なぜなら、バリュークラスで定義した場合、オブジェクトとしてラップされず、引数に指定した型でコンパイルされるからです。
@JvmInline
value class Name(private val value: String) {
// ...
fun greet() {
print("Hello, I am $value")
}
}
// Codeを書く際は以下のように使用する
val name: Name = Name("Marcin")
name.greet()
// コンパイル後
val name: String = "Marcin" // Nameオブジェクトではなく、Stringオブジェクトとして生成される。
Name.`greet-impl`(name) //static関数としてコンパイルされる。 バリュークラスの使い所としては、単位などを型として扱いたいときに役立ちます!
では、タイマーを実装するクラスを考えましょう。
interface Timer {
fun callAfter(timeMillis: Int, callback: () -> Unit)
}
@JvmInline
value class Millis(val milliseconds: Int) {
// ...
}
interface Timer {
fun callAfter(timeMillis: Millis, callback: () -> Unit)
}
callAfter 関数の timeMillis はミリ秒で指定する必要があると仮定します。 しかし、型は Int 型のため、開発者が、秒で指定してしまい、バグを生んでしまう可能性があります。
一方、バリュークラスを引数の型に指定することで、開発者は単位を意識しながら、引数を設定するため、開発者のケアレスを防ぐことができます。
このように、適切にバリュークラスを使うことで、プログラムの誤りを防ぐことができます。
まとめ 記事をご覧いただき、ありがとうございました。今回、紹介した話は、Kotlin の基礎的な内容でしたが、エンジニアたるもの、一度根本に立ちかえり、学び直すことは非常に大切だと感じました。


/assets/images/4144660/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1569914911)


/assets/images/6571325/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1618570231)


