【AIイノベーションブログ】気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった

「そろそろあれ買わないとなぁ」
スマホチラッ
「絶妙なタイミングでアプリの通知が来てる……こわっ……でもポチッちゃう……」
ポチー
こういう経験をしたことがある人、最近増えてきていると思います。
この記事を見ているあなたはどうでしょうか?
もしかしたら、今、通知を見ることでこの経験をすることもあるかもしれませんね。
さてこの現象ですが、果たして偶然タイミングが合っただけでしょうか?
もちろんそのパターンが圧倒的に多いとは思います。しかし、本当に送り手が意図をもってあなたの欲望に先回りして、それが成功したとすればどうでしょう?
こういうことは今日では本当に行われていて、この記事はその裏側に焦点を当てます。
通知の送り手……彼らはマーケターと呼ばれる人たちです。
彼らの仕事はマーケティング。
- 自社製品をより多くの人々に届けたい
- 自社製品のリピーターを増やしたい
- 売上を上げたい
という思いを胸に秘め、そのためにできることがあればなんでもすることに定評があります。
意図をもってあなたの欲望に先回りして通知や配信を飛ばすのもその活動の一環です。
しかしマーケターも人間。仕事が終われば彼らも一人の消費者。なので「気味悪がられるかも」ということはもちろん気にはしています。
とはいえ、例え気味が悪くても「欲しい!」と思ったその瞬間にアピールできるということはマーケターにとってあまりにも魅力的で、わたしたち消費者も絶妙なタイミングで手軽に買えるのはなんだかんだでありがたかったりするのです。
※ 個人的には、面倒くさくて後回しにしてる買い物を、やる気があるタイミングを察してまとめて思い出させてくれると嬉しいです。ただ本当にその瞬間にまとめて通知が来ようものなら、あまりの不気味さに寒イボが止まらないのは必至ですね
ところで、マーケターはどうやって意図をもってあなたの欲望に先回りして通知や配信を飛ばすということを実践するのでしょうか?
アプローチは色々あり、その内の1つに、決定木という道具を用いる手法があります。
決定木を用いるものの中でも特に、GBDTと、ランダムフォレストというものがあり、これは決定木をたくさん使うような手法です。
もちろん、マーケターの仕事は意図をもってあなたの欲望に先回りして通知や配信を飛ばすだけではありません。マーケターの仕事は「いつ誰に何をどこでどうやって」施策を打つべきかをできる限り賢く決めることです。
そして実は、GBDTやランダムフォレストといった手法(場合によっては決定木を1本だけ使う手法も)は、マーケターの仕事全般で役に立ちうる道具なのです!
マーケターが上手に健気に決定木を植え続けると、その結果として彼らの会社の売上が上がり、わたしたち消費者もなんだかんだ便利になるのです。
図1: マーケターが木を植えた結果、色々上手くいく様子を表した図
この記事はそんな決定木について、「どこでどう使うのか」「結果はどう解釈できるのか」「実践的にはどう使われているのか」を紹介するもので、次の内容から構成されます。
- マーケターの仕事は「分類」が肝心で、それを楽にする手段の1つとして決定木を紹介(第1回)
- 決定木は機械学習モデルの1つ。よくわからないのでさらっと機械学習を紹介(第1回)
- 例を交えつつ、決定木とは実際に何をしてくれて、どうやって使うのかを紹介(第2回)
- 悪い決定木の問題点を調べ、汎化性能という機械学習モデルの良し悪しを測るものさしを紹介(第3回)
- 決定木は1本単体で使うだけでは、その汎化性能に致命的な弱点があることを紹介(第4回)
- それを克服する、GBDTとランダムフォレストという決定木をたくさん用いる手法をさっと軽く紹介(第4回)
※ もちろん、賢いマーケティングのアプローチは木を植え続けることだけではありません。もしかしたら本当に脳を覗くようなことをしている企業もある……かもしれない?陰謀論めいてるのでこんなこと言うもんじゃないですね。
ということで今更ですが自己紹介します。カスタマーリングス事業部で開発をやっています。油山です。
この記事は、マーケティングの分析・予測の手法として、決定木とその派生手法について4回に渡って紹介する記事のその1です。
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ←イマココ
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~植えた木はどんな姿をしているか~
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~育った木の良し悪しを測ってみる~
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~精度を上げるには森を作るしかない~
弊社のカスタマーリングスでも実際に、メールなどの配信の際に最も開封・既読されやすいタイミングを顧客1人1人に対して予測して、この記事のタイトルのような気味悪いけれどなんだかんだ嬉しいことをする機能などに、決定木の派生手法であるGBDTが応用されています。
マーケターの仕事は「分類」が肝心
マーケターの仕事は「いつ誰に何をどこでどうやって」施策を打つべきかをできる限り賢く決めることです。
ということを上の文章で書きましたが、この仕事にはどんな施策であっても必ず「分類」という作業が伴います。
休眠掘り起こしから見る「分類」
一度登録したっきり全然利用していなかったサービスや店からいきなり、クーポンやキャンペーン、購入後の状況を確認したりするようなメールやLINEが届く。
こういう経験をしたことがある人は、この記事を読んでいる人でも結構いると思います。
これは、休眠掘り起こしと呼ばれるマーケティング施策の一つです。
※ ここで休眠と言うのは、休眠顧客(=しばらく購入などの反応がない顧客)を指します。
休眠掘り起こしは、
- 送る側の企業からすれば、新しい顧客を見つけるよりも、休眠顧客に戻ってきてもらう方が、コストを抑えて売上が伸ばせる。
- 受け取る側の休眠顧客からすれば、暫く記憶の彼方にあったとしても、きっかけがあることで改めて触れ、その良さに気づけるかもしれない。
という、マーケティング施策ではまず行われていると言っていい、基礎的なものです。
休眠掘り起こしでは、マーケターはまず何よりも「誰に送るべきか」の分類を決めなければなりません。
ざっと考えてみると、
- 暫く反応がない人に送りたいけど、いつから反応がない人に送るべきか
- さすがに5年以上も反応がないような人に送るのは無駄撃ちだろうな
- ずっとたくさん買ってくれてる顧客に、間違って送ったりしたら下手すりゃ離れるかも
- そもそもメールとかLINEには配信コストがあるから、例えばメールに反応しないような人たちにはLINEでアプローチするみたいに、媒体によって送るべき人も変わりそうだな
といったことが想像できそうです。
マーケティング施策は、「特定の誰かにしか打ちたくない」、あるいは「特定の誰かには別の手段でアプローチしたい」といったものがほとんどなので、分類は絶対に必要な作業であると同時に、何よりも肝心な作業でもあるのです。
休眠掘り起こしは、「いつから購入がない人を休眠顧客とみなすか」という期間さえ決めてしまえば、休眠顧客かどうかという分類は、とりあえずは簡単にできます。
しかし、分類というものは基本的には難しいのです。
この休眠掘り起こしの例でも、休眠かつ「施策を打ったら復活してくれそうな人」だけを対象にしたいとなると、その分類は一気に簡単ではなくなるはずです。
「その難しい分類というのはどうするのか?」
イマドキの企業であれば、顧客のデータと購入のデータを必ず持っています。いわゆるビッグデータというヤツです。答えはここにあります。
このデータは大量にあってかつ複雑です。マーケターは、様々な切り口からこのデータを分析し、その結果得られた知見を基にして分類を行います。
しかしこの作業は時間と頭を使いますし、結局勘で決めてしまうマーケターも多いと耳にします。
「もし、データを用意するだけで、自動でこの分類作業を行えるとしたら……」
そうなればマーケターはハッピーです。もし完全に自動分類までいかないにしても、データを用意するだけである程度整理してくれるならそれでも十分嬉しいはずです。
それを実現するためには、今までやっていた人が分析して知見を得るという作業を自動でさせる必要があります。これはいわゆる機械学習というヤツです。
人が得た知見は脳や文書に記憶されます。機械学習では、あらかじめモデル(あるい学習器、予測器とか)と呼ばれる雛形を決め、そこに学習の結果として得られた知見を注入します。
自動分類は、この学習済みのモデルに、分類したい顧客のデータを入力して得られる結果を基に行われます。
ここで「モデルに何を使うか」ということで決定木が出てきます。決定木というのは機械学習のためのモデルの1つ、要は雛形というわけです。
この記事のタイトルにある木を植えるという言葉は、決定木というモデルを手元のデータを使って学習させることを表現したものです。(念の為ですが木を植えるは一般的な用語ではありません。)
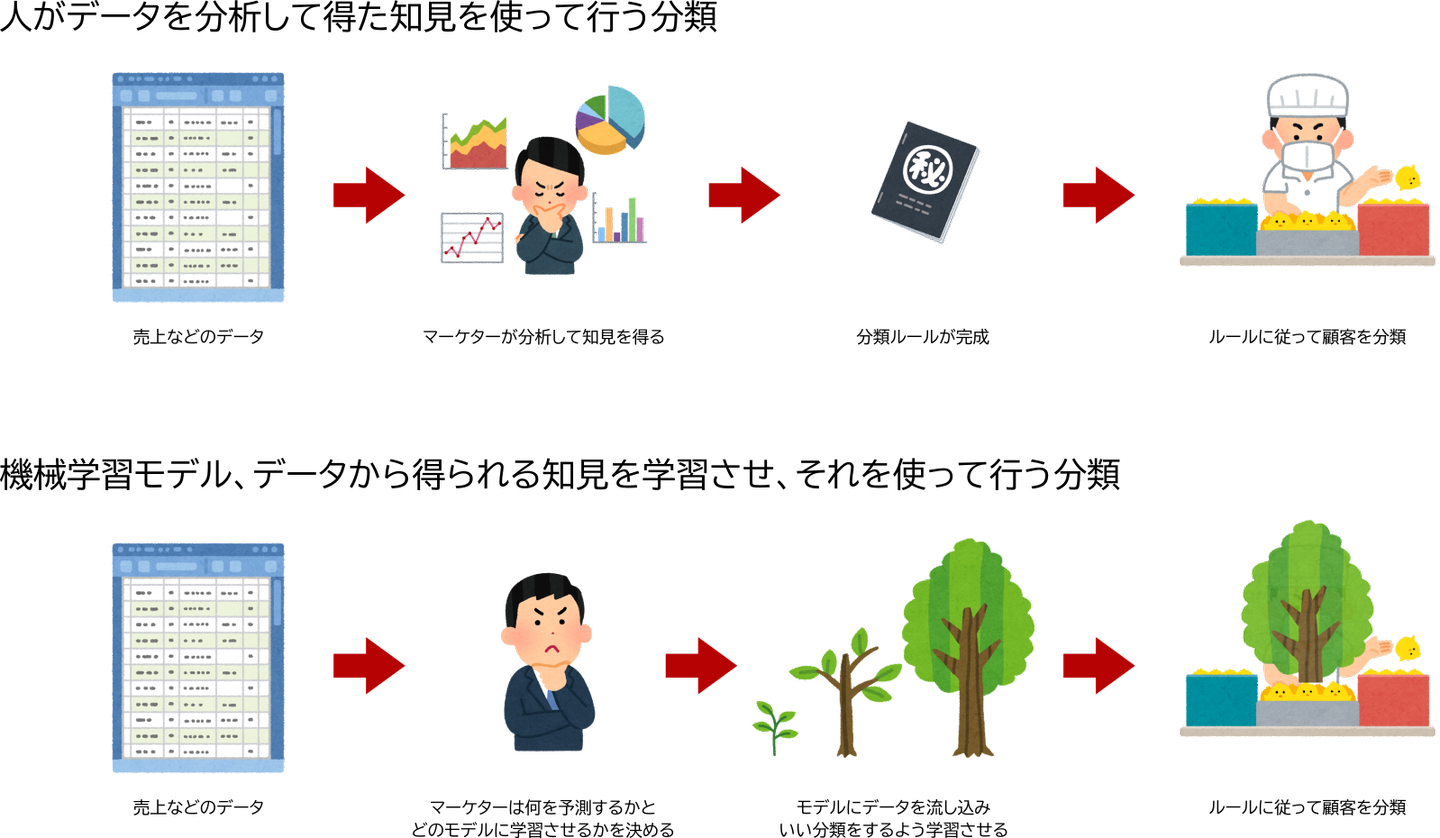
図2: 自動分類は、どういう知見が欲しいのかと、それを溜めるモデルを決めて、そのモデルを学習させ、学習が終わったモデルを用いることで行われる。
機械学習というと、ブラックボックスでよくわからない規則で動くイメージがあるかもしれませんが、これはどういうモデルを用いるかで変わってきます。
決定木は、「分析の結果、どういう規則で分類されるべきか」ということが人の目にも解釈しやすいという特徴を持っており、決定木を学習させるということは、ある種の分析として見ることも可能です。
※ ニューラルネットワークというモデルを用いたものが、いわゆる典型的なブラックボックスです。
上手に木を植えるためには、まず全体の工程を知らなければなりません。
次の節では、機械学習の大雑把な枠組みを眺めてみます。
機械学習の枠組み
その予測、必要ですか?良し悪し測れますか?データありますか?
機械学習が必要とされる場面は、基本的には何かを予測しようというときです。
前節では、「休眠掘り起こし施策が有効そうな顧客」か「そうでない顧客」かを分類したかったわけですが、これは顧客が「休眠掘り起こし施策を打ったときに有効」かどうかを予測すれば実現できます。
予測には、4つの登場人物がいます。
- 予測対象に関するデータ(特徴量)
- 予測する方法
- 予測した結果
- その予測はいい予測か
例えば…
ある顧客のユーザー情報と購入履歴を基に (1)、分析して得られた知見を使って (2)、休眠掘り起こしが有効であると予測する (3)。この予測を1ヶ月使ってみたが、なかなか的中率が高いのでこれはいい予測と見てよさそうだ(4)。
ということです。
この4つの優先順位はどうなるでしょうか。機械学習と言うと、真っ先に(2)のところに目が行きがちですが、実はそうではありません。
- 予測したいもの(3)がなければ、そもそも予測は必要ありません。「予測するべきものは何か」ということは人が考えます。
- 「いい予測とは何か?」(4)がなければ、予測の価値を測ることができません。
- データ(1)がなければ、過去の知見を活かした予測はできません。
(4)があって、初めて予測に必要なデータが何かということがわかります。その上でデータがなければ集めなければいけません。
このステップを乗り越えて初めて、どうやって予測するか(2)を考える意義が生まれるのです。
モデルを決めてチューニングする
どうやって予測するかですが、これは次のような手順で作られます。
- 学習に使うモデル(学習した結果を注入する雛形)を選ぶ
- 「いい予測とは何か?」を基に、モデルをチューニング(学習や訓練とも。後述)する
このときのモデルのチューニングの仕方によって、機械学習は次の3つに大別されます。
- 教師あり学習
- 教師なし学習
- 強化学習
この記事で扱う内容は全て教師あり学習です。
教師あり学習というのは、
- 「休眠状態」「20代」「女性」「平均購入単価が5,000円」の顧客は施策によって商品を「購入した」
- 「休眠状態」「40代」「男性」「平均購入単価が3,000円」の顧客は商品を「購入しなかった」
といったデータがあらかじめ大量に用意されているのが前提のもので、これらの正解がわかっているデータ(教師データや訓練データと言う)を用いて、予測精度が上がるようチューニングを行うことです。
さて、モデルのチューニングとは何でしょうか。
決定木をモデルとした場合を例にして解説してみます。
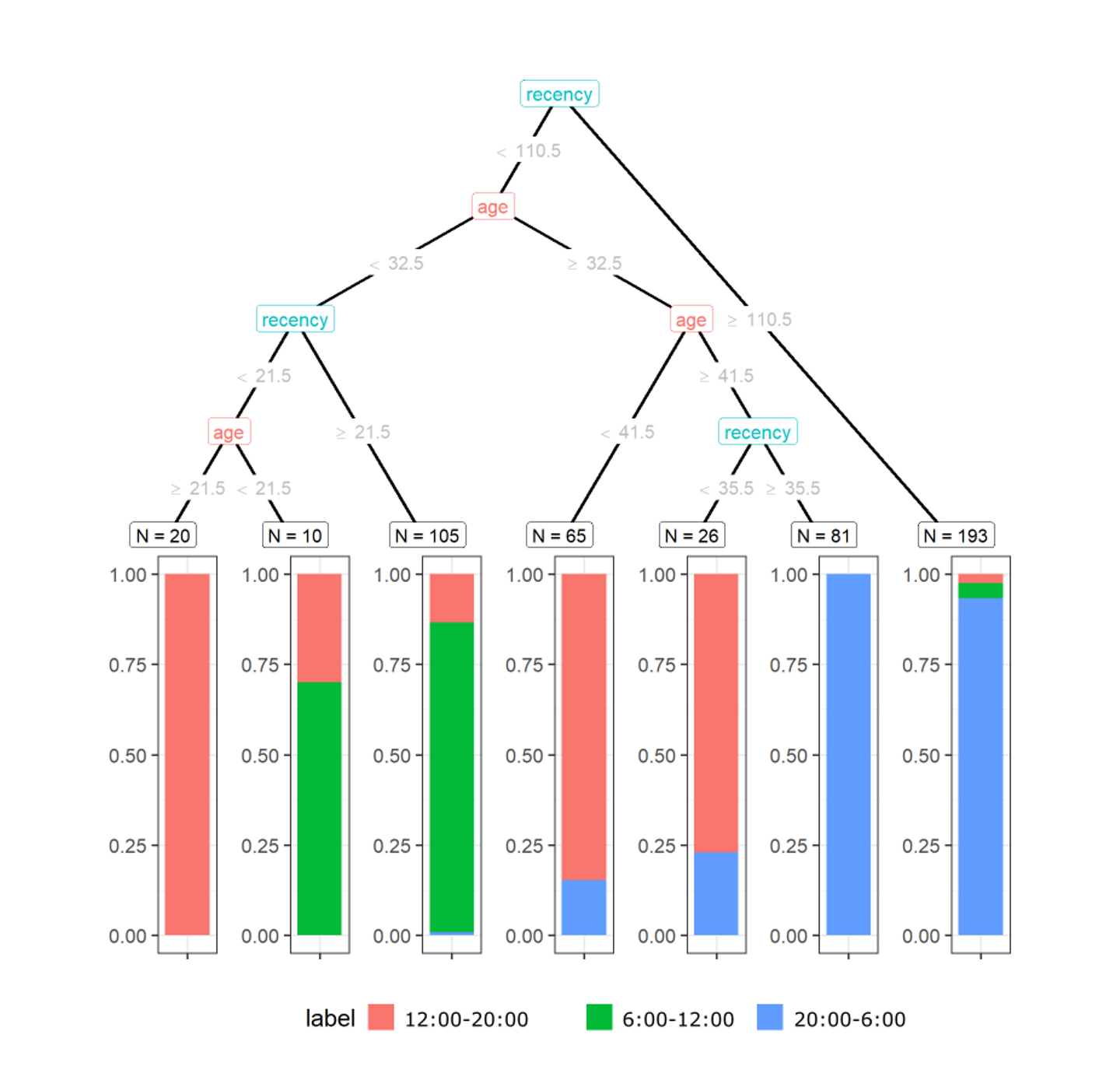
図3: 決定木の例。決定木のチューニングでは、いい予測を実現するために枝分かれの位置や条件を変えて試行錯誤する
図3の上半分(N=○○と書いてあるところより上)が決定木です。(この図は次回にも登場します。下半分についてはそのとき説明します)
この木では、1人1人の顧客を、recency(最後に購入してからの経過日数)とage(年齢)を使って分類します。
例えば、recency=30でage=25の顧客であれば、
- 一番上の2択では、recency(=R値)が110.5以下なので、<110.5とある左側に落ちる。
- 次の2択では、age(=年齢)が32.5以下なので、<32.5とある左側に落ちる。
- 次の2択では、recencyが21.5以上なので、≧21.5とある右側に落ちる。
- 結果、左から3番目のN=105とあるグループに落ちる。
という感じです。
図3の決定木にはいくつか枝分かれがありますが、どこでどんな条件で枝分かれするかという情報が、この決定木がどんな予測をする決定木なのかを特徴づけます。こういったものをモデルのパラメータと言います。
教師あり学習では、あらかじめ手元にある教師データに対して、一番いい予測を実現するようなパラメータを見つけ出します。このことをチューニング(学習や訓練とも)と言います。
この結果、モデルは、手元の教師データに対していい予測をするにはどうすればいいかということを学習したことになります。
※ 決定木は決定木でも5個以上は枝分かれしないような制限をつけたいようなことがあったりします。こういったモデルに対してあらかじめ決めておく設定をハイパーパラメータと言います。
ざっくりとした機械学習を用いた分類の流れ
ここまでの内容をまとめると、機械学習による分類は以下の手順に沿って行うことになります。
- 何を分類したいか。そのためには何を予測するべきかを決める。
- 「いい予測」とは何かを判断する基準を決める。
- (教師あり学習であれば)教師データを用意する。
- モデルを決める。
- 入力する特徴量を決める。(何を軸とするかを決める)
- 教師データを用いてモデルのパラメータをチューニングする。
- 学習済みのモデルに、予測したいものの情報を入力し、予測結果の出力を得る。
- その結果を用いて分類する。
ということで長くなりましたが、第1回はここで終わりです。この記事はこんな内容でした。
- 通知の裏側に潜むマーケター
- マーケターは分類を頑張りたいけど結構大変
- 機械学習を使うと分類を自動化できる
- 決定木は機械学習のモデルの1つで、解釈がしやすい
- 機械学習はまず「何を予測してどう良し悪しを測るか」ありき
- モデルは雛形。教師データを食わせてチューニングすることで使える
- この記事のタイトルは、「顧客にとっての通知タイミングの精度をより上げるため、決定木ベースのモデルを応用してみた」という風に言い換えられる
次回以降は、チューニング済みの決定木を眺めることで、決定木というのがどんなモデルなのかということを紹介します。上の手順で言えば(4, 5,) 6, 7に対応します。(実際は1, 2, 3がもっと重要で大変です)
/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)


/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)




/assets/images/7996434/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1635406102)


