【AIイノベーションブログ】AIはどのように『言葉』を理解するのか。最先端AIと社会実装との壁に迫る ~Part 3~


【目次】
Part 1
1. 『言葉って難しい』~言葉の処理を理解する為の前知識~ 2. そもそも言語処理タスクは、人間も間違えやすい 3. 難しい文も前提知識のある用語に置き換えてみると分かりやすくなる 4. 世間のAIに対する一般見解と最先端AI
Part 2
5. 自然言語処理とは? 6. 文書自動分類の主な活用場面 7. 機械学習の分類タスクは二種類ある(2クラス分類と多クラス分類) 8. AIで自動分類するときのコツ
Part 3
9. AIは、どのように文書を分類するのか _9.1 特徴的な単語を抽出するとは?~林檎と言語の特徴について~ _9.2 分類したい文書をアルゴリズムで推定 10. 平成の自然言語処理、令和の自然言語処理 11. 創造性の領域とデータセットの壁 12. AIと人類最後の砦。ビジネスで上手く活用できないAIについて
Part 4
13. アマチュアがプロ並みのスキルを持つ社会で 14.『表現のこだわり≒ブランディング』とAI、自然言語処理 15. おわりに。この仕事の難しさと楽しさについて
9. AIは、どのように文書を分類するのか
あるニュース記事Xをスポーツ、政治、エンタメのいずれかに分類するような場合を考えてみます。
大まかな流れ
- ニュースジャンルのようなラベルと紐づいたテキストを用意する(AIが訓練するデータ)
- スポーツ、政治、エンタメカテゴリに含まれるすべての文書から何らかの特徴を抽出
- 抽出した特徴を元に分類器を作成する
- 分類したいニュース記事を用意
- 予測したいニュース記事Xの特徴と似た特徴を持つカテゴリに分類する
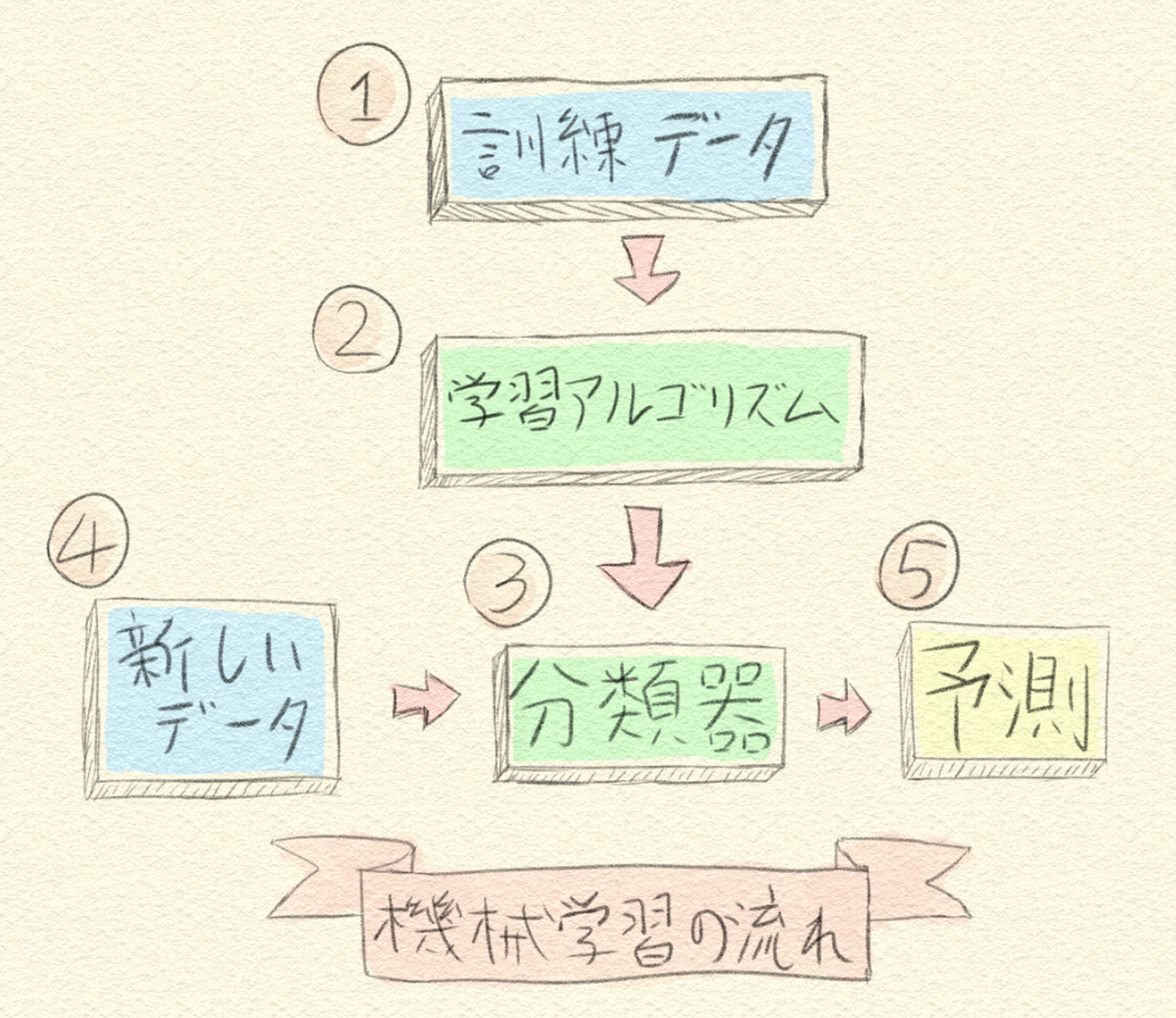
文書分類に限らず教師ありタイプの機械学習は、このような流れになります。ここから文書分類の場合をもう少し具体的に考えてみましょう。AIは文書の特徴をどのように捉えているのでしょうか。
- ここでは、文書の特徴とは何か?
- どうやって予測したい文書と各カテゴリの特徴が似ていると判断するのか?
の 2 点のポイントについて検討します。
9-1. 特徴的な単語を抽出するとは?林檎と言語の特徴について

上のりんごの絵は僕が捉えた視覚的イメージです。視覚情報の特徴的な部分だけをクロッキーで描いたら、こんな絵になりました。この絵を一つ一つ分解した所で雑多な線の集まりでしかないです。
では、どの要素が人にりんごと認識させるのでしょうか。
輪郭?それとも影の濃淡?そのいくつかの特徴的な要素が合わさってりんごだと判別できます。同様に分類したい文書にも、そのカテゴリを示す特徴的な要素があるはずです。人間ならば文章の書き手が、どういう順番で話をすれば、読み手に内容を伝えられるかを考えながら言葉を一つ一つ選んで、それらを繋げて文章を書きます。読者は、その文章を最初の単語から順番に読み内容を理解します。しかし、コンピューターの分析技術を用いれば人間とは全く異なった方法で読む(解析する)ことができます。文章をその単位の最小の構成要素の単語に分解して、現れた単語の分布から定量的に文章の特徴を抽出する方法があります。文中の単語には、そのカテゴリを示す特徴単語があるはずなので、それら単語を確率統計に基づいたアルゴリズムやディープラーニング技術で抽出します。

例えばニュース記事がスポーツ、政治、科学、エンタメの中のどのカテゴリに分類されるかを判断する時、その記事にオリンピックや卓球と言った単語が含まれていればスポーツカテゴリに分類できそうです。スポーツカテゴリ中の文書には、他カテゴリの文書と比べると、サッカー、選手、野球などのスポーツに関する用語が相対的に数多く含まれるからです。このように収集した全体の文書と各カテゴリに出てくる統計的な分布の差から特徴的な単語にスコアをつけて分類する手法などがあります。
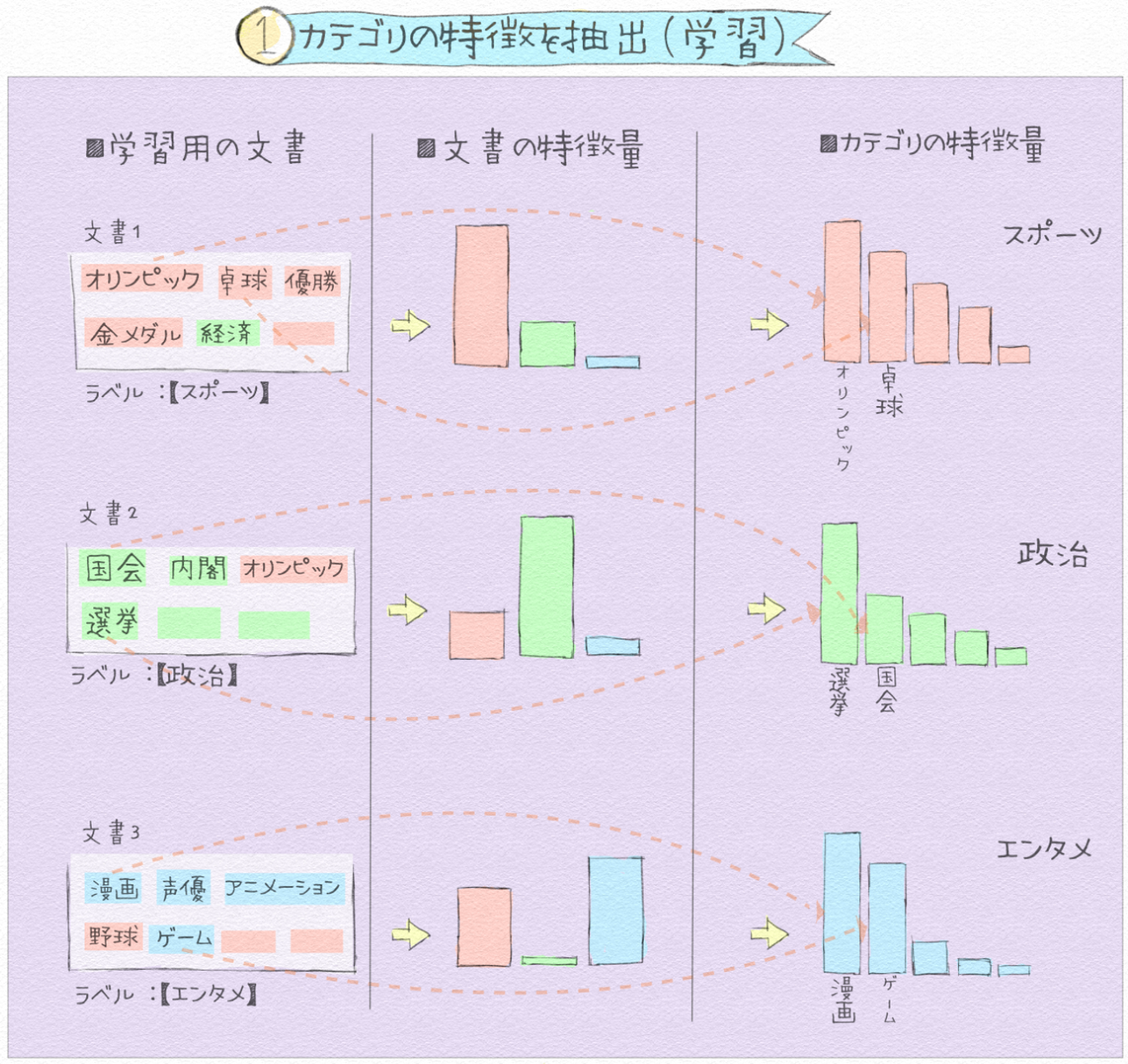
9-2. 分類したい文書をアルゴリズムで推定
続いて、ある文書 X から各カテゴリに分類するか予測する方法について考えます。事前に求めたある文書Xの文書の単語分布の特徴とそれぞれのカテゴリの単語分布の特徴の類似度を計算して、一番類似度が高いものをそのカテゴリの文書として予測します。このようにして人が事前に分類した教師データから個々の文書カテゴリの特徴単語を捉えることでAIが予測、分類することができます。
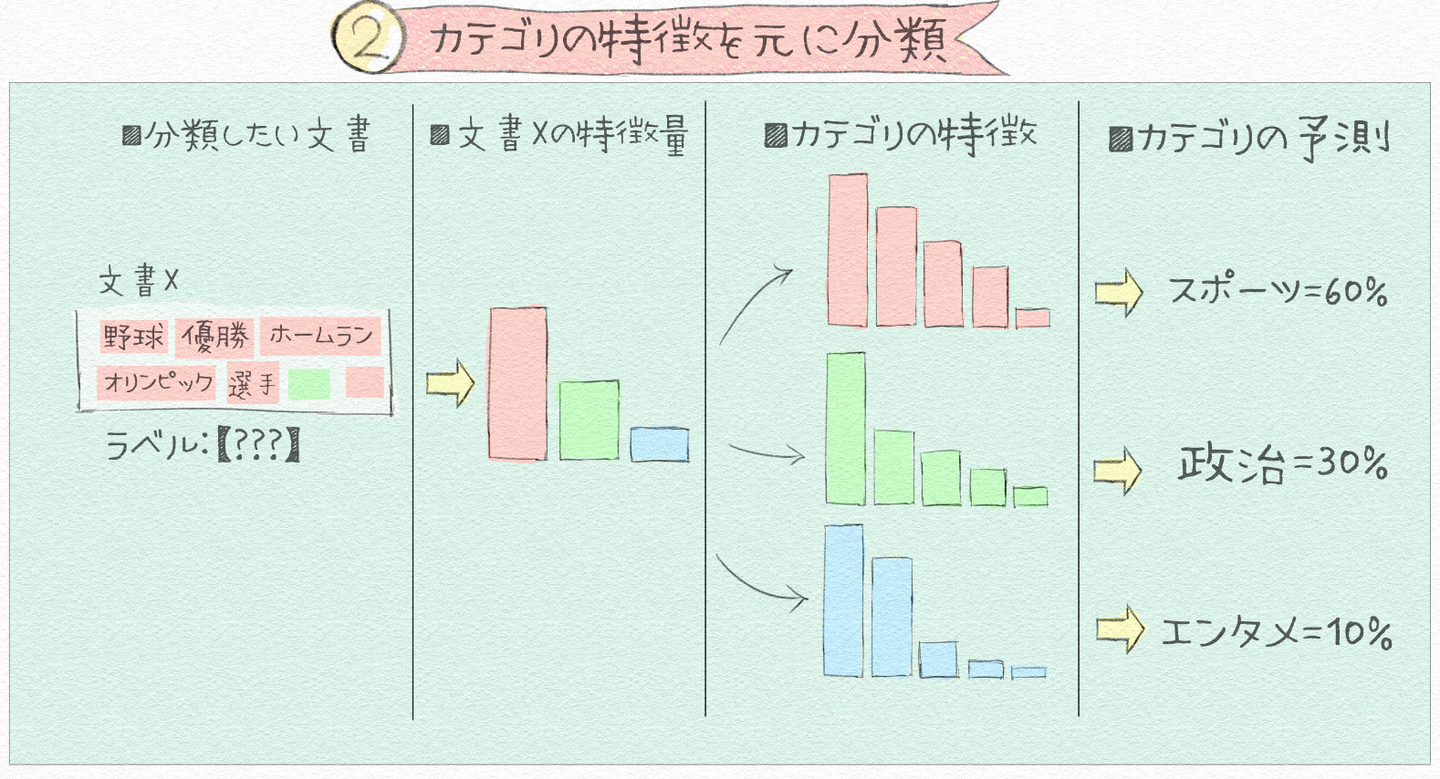
実際は、単語の出現頻度からレア度の高い単語に重み付けをする(TF-IDF)などのテクニックを使って精度を高めていきます。文書分類のモデル一つ考えても機械学習は様々なアルゴリズムが考案されており、ナイブベーズ、SVM、K近傍法などの手法や言語処理でも主流になりつつあるディープラーニングによる手法などがあります。
10. 平成の自然言語処理、令和の自然言語処理

最初(Part 1)に触れたアミラーゼ問題は前提知識の有無で難易度が大きく異なりました。
AIも同様に大量のデータで単語の特徴(意味)をたくさん知っていれば理解できる範囲は広がります。しかし、言語や絵などの難しいところは、単語や線というような部分の性質の単純な総和にとどまらない特徴が、全体としての特徴になっている場合が挙げられます。

数年前の自然言語処理のAIは、単語の出現頻度から確率・統計を取って予測するような手法が主流でした。ディープラーニングによる手法も研究はたくさんされていたのですが、確率統計の手法に取って変わるほど劇的な精度が出ていなかったのです。しかし、単語の意味や文脈を考慮せず単語の出現頻度だけで予測するような統計的な機械学習のモデルには限界があり、人間のような高度な言語処理は絶対にできませんでした。
――例えば商品評価に関するレビューの分類について考えてみます。
評価の高い文には『美味しい、キレイ、速い、良い』のようなポジティブな単語が含まれていることが推測できますし、反対に低評価の文には『不味い、汚い、遅い、悪い』などのネガティブな単語がありそうです。しかし、実際のレビューには「パッケージは良かったです。香りも良く、見た感じ美味しそうでしたが、実際に食べてみたら味が最悪でした。」のように最初はポジティブな意見が書かれていて、後半で評価に直結している本音の部分が書かれるようなケースがあります。日本語の評価レビューは、後半に行くほど評価に直結する可能性が高いので、文の前半にある単語はスコアを低く設定して、後半に出てくる単語はスコアを高く設定するなどの工夫が必要そうです。
このように言葉の特徴を正確に捉えるには『文脈においてどこが重要な箇所なのか』などの語順による意味の変化を考慮する必要がありました。
最初から人間の経験や前提知識に基づいた何かしらの共通項が分かっているなら、ルールベースによる対応は可能です。しかし、Part 1に書いてある『言いたいこと』『伝えたいこと』のニュアンスの話を思い出してください。このような、ほんの少しの文脈によって変わる言葉の複雑怪奇な特徴を純粋な計算アルゴリズムだけを用いてコンピューターに理解させるのは大変難しいことでした。
最近の自然言語処理が飛躍的に向上した主な理由は何でしょうか。
それは、世の中にある全ての膨大な文書を学習させることで言葉の意味や文脈の理解を高めることが可能になったからです。ネットの膨大な情報を用いて『単語の意味を定量化する手法(Word2Vec)』や『文脈のどこに注意を向けるべきか考慮する手法(Attention機構)』などの処理が確立された結果、一昔前ではAIには『無理だ』と言われていた読解力の部分も考慮して推定できるようになりました。このようにアルゴリズムによる計算方法が確立されたことで、ビックデータと高い演算能力をもとに自然言語処理技術は飛躍的に向上していきました。
11. 創造性の領域とデータセットの壁
そして、今現在の自然言語処理ではディープラーニング技術が使われることが非常に多くなっています。自然言語処理分野の論文等を見ていても、ディープラーニングを用いた精度向上に関する発表が次々にされています。以前に比べて少ない教師データで高い精度を出したというエビデンスがいくつもあります。また精度と言う枠組みに留まらず、創造性がないと難しいタスクも解けるようになりつつあります。例えば先端研究では『抽象的な文から言葉を理解して、画像を生成する』というような研究もされています。
以下が、入力したテキストから画像を自動生成したサンプルになるので見てください。
紹介サイト:https://openai.com/blog/dall-e/ 論文:https://arxiv.org/abs/2102.12092 ソースコード:https://github.com/openai/dall-e
入力テキスト
an illustration of a baby daikon radish in a tutu walking a dog
生成された画像(出力結果)

(↑これは、上の英文からAIが生成した画像です。)
入力テキスト
an armchair in the shape of an avocado. . . .
生成された画像(出力結果)

(↑これは、上の英文からAIが生成した画像です。)
凄い結果ですよね。一つ目の大根のイラストの例ですが、この文を読んでも『tutu』が何であるかすらも知りませんでした。検索して初めて僕は『tutu』が何であるか知りました。

(↑これは、tutuです。)
このような研究がいくつも報告されています。他にもMicrosoftやGithubなど海外のメガベンチャーでは、人のつけた関数名を入力データとしてソースコードを自動生成する研究をしていて、数年後までに実用化されていても不思議でない段階まで進んでいます。数年前までの一般常識、AIの苦手分野と言われていた言葉などの抽象的な理解や創造性の求められる部分も当初想定されていた以上に進化しています。
このように技術革新の目覚ましいAI、自然言語処理。
ところが、いざ、自然言語処理技術を用いたAIを日本語に対して適応しようとすると、途端にデータセットの壁に当たることが殆どです。実際に日本の現場では、まだまだルールベースの処理や辞書の整備といった機械学習以外の作業も多く残されているのが実情です。
12. AIと人類最後の砦。ビジネスで上手く活用できないAIについて
ここまで聞くと、『AIはやがて現代の神となり、世の中すべての諸問題が解決されていくのか?』とか『最早、人類はAIに敗北していたのか?』と落ち込む人もでてきそうですが、それが実は実用的なビジネスやマーケティングに取り入れようとすると上手くいかない場合が多いんです。
その理由について、最後に説明しようと思います。
具体的にAIの企画やプロジェクトを成功させるにあたって、どのような障壁が立ちはだかるのでしょうか。主な理由は3つ考えられます。
AIに仕事を奪われることを気にしている人には朗報です。『人類を仕事から救済し補完するのだ』とか考えているAI推進派の悪いやつらは、この3つの壁を突破できずに駆逐されます。経験談(笑)
まず、1つ目は先に挙げたように大量かつ質の高いデータを用意できないという問題があります。これが実用的なものを作ろうとしたときの第一の壁です。概ねここでAIプロジェクトの多くが躓き、プロジェクトは頓挫します。

第二の壁は、実用的なマーケティング領域などで応用を考えた場合の問題です。
AIで相関関係は見つけられても因果関係までの判別が難しいことが挙げられます。どいうことかと言うとAIは、似たもの同士の抽出は大得意です。なので、AIは同じ曲線になっているグラフなどの類似するものの抽出は易々できます。しかし、それが本当に影響を与えているかの判断、つまり因果関係があるのかを判断させるのは至難の業です。マーケティングで売上を上げたくて、その改善点をAIに命令したとしても、売り上げと似た曲線のグラフを持ってくるのが精一杯です。例えば、『あるCDの売り上げ』と『ある魚の漁獲量』の時系列グラフが似ているからと言って、漁獲量を増やしてもCDの売り上げは伸びないのは容易に想像がつきますよね。しかし、AIはその判断ができません。

第三の壁は、AIのブラックボックス化問題です。
よくAI業界では『ブラックボックス化』という問題が話題に上がります。ブラックボックス化とは何かと言うとAIの予測結果などのアウトプットのみが提示されて『その結論に至ったプロセスが見えないこと』を指します。
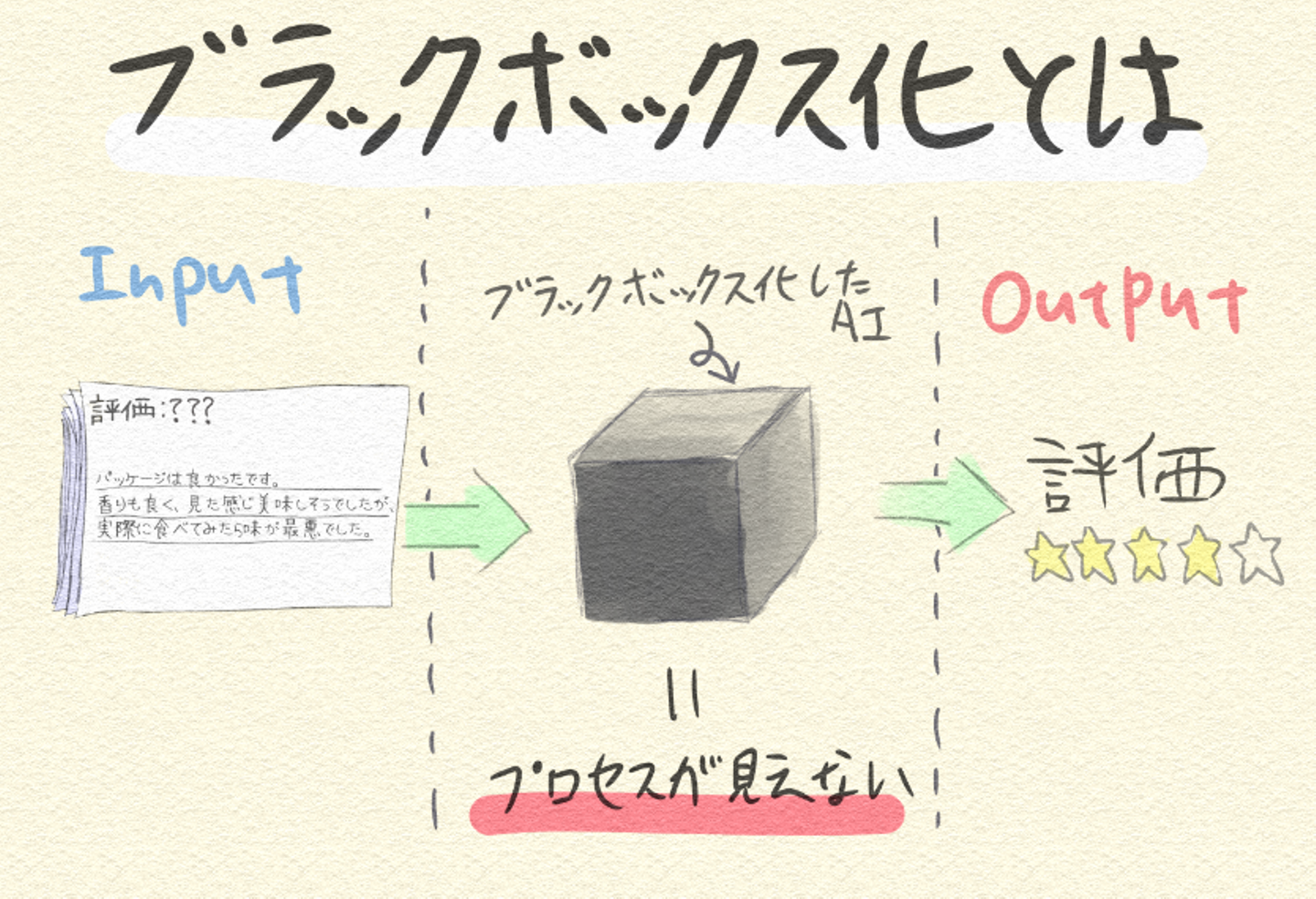
――結論までの過程、判断基準が見えないと何が問題になるのでしょうか。
ブラックボックス化したシステムでアクションを自動化してしまうと、結果に至った過程が不透明になります。不透明になったことによりノウハウが蓄積されず『結果の振り返り』と『次のアクション』が難しくなります。もちろん、AIの活用には判断基準を明確に把握する必要がない分野もあります。
例えば、画像解析でそこに何が映っているかを判定したい場合は、AIの判断した過程が不透明でも問題にはなりません。この場合、人的作業をAIに置き換えたときの効率性、生産性のみが求められます。しかし、業務の課題解決では、AIのブラックボックス化が問題になるケースもあります。機械学習・深層学習による判別・分類、予測は、それだけでは必ずしもリアルの問題を解決するとは限りません。
マーケティング施策や業務改善では、予測精度が高くても結果に至った過程を分析していかないと具体的な次のアクションや改善につながらない場合が多いです。AIの判断に誤りがあれば、誤りを起こした理由を探り出し改善する必要がでてきます。しかし、AIが判断した根拠が分からなければ改善の方向性を定められなくなります。例えば、評価レビューの予測をした場合、精度が高くても文章のどのポイントが評価に影響しているか把握しないと、実際に取り組むべき改善点が分かりません。予測だけが上手くいっても『なぜ高評価なのか、あるいは低評価なのか』といった評価観点や評価した理由が見えてこないと具体的に取り組むべき次のアクションに活かせません。そして、ブラックボックス化したシステムにより人や組織にノウハウが蓄積されず、本来の目的だった次へのアクションが定まらなくなってしまうケースも起こり得ます。
このように社会実装で求められるシステム、特に、意思決定につなげるシステムとなるまでには、まだまだ高いハードルが立ちはだかっています。
そのため、ブラックボックスにならない範囲で自動的する仕組みやAIの利用目的をよく理解したうえで判断する必要があり、社内のAI人材の育成も重要になってきます。また、何故そのような判断をしたのかを説明する、経過途中を示せるという『説明可能なAI』の研究が推進されています。
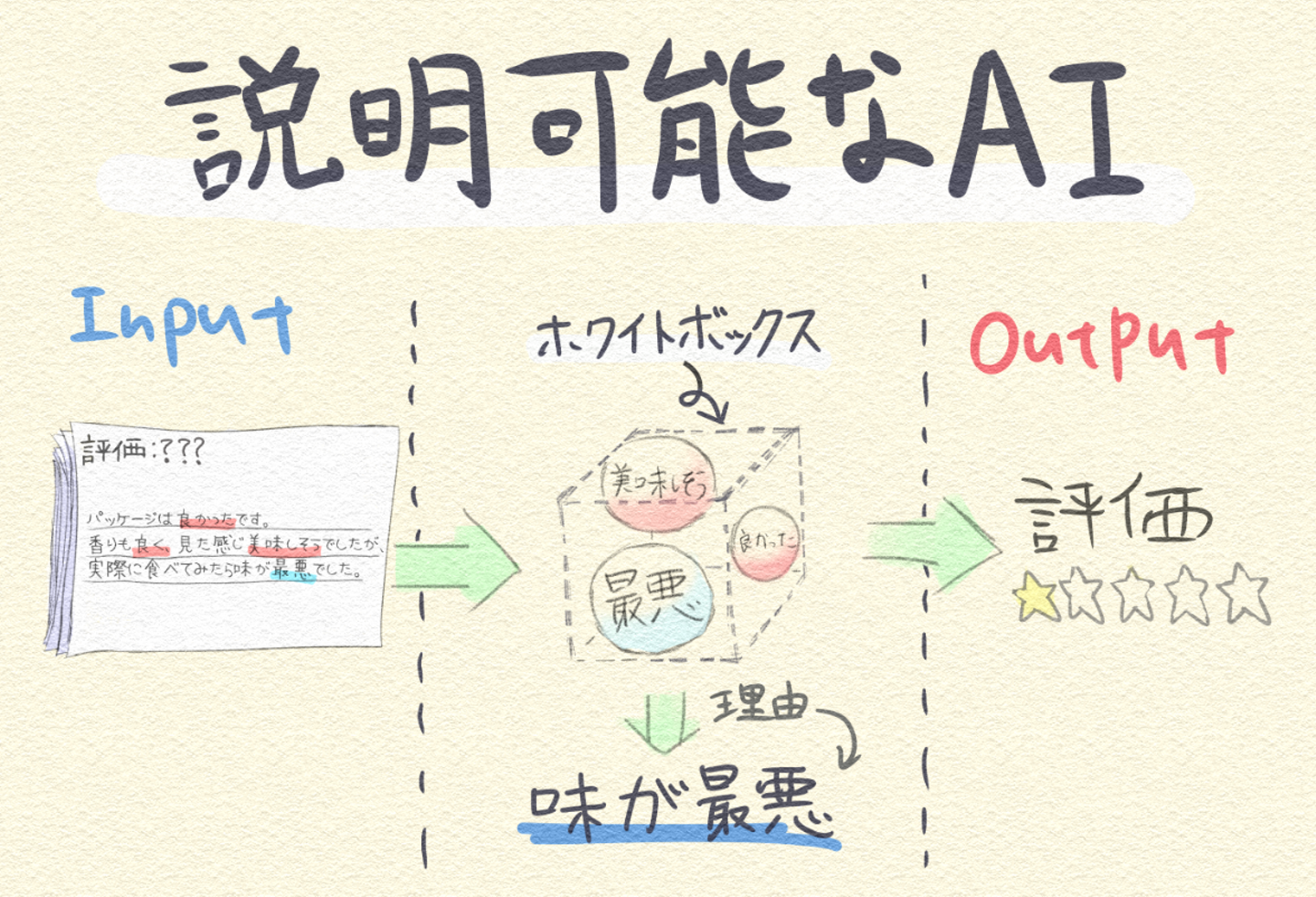
説明可能なAIは、ブラックボックス問題を解決しAIの普及拡大を支える重要な技術であり今後もさまざまな要素技術の開発やサービスへの実装が期待されています。

→ 注目されるAI技術と『自然言語処理の魅力』
/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)


/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)



/assets/images/7996434/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1635406102)


