こんにちは、那須です。
2ヶ月ほど前にAWSからIncident Managerというサービスが登場しましたね。詳細は↓こちらのブログをご参照ください。運用担当の方にとっては最高のサービスが出てきたと思ってます。
記事にもあるように、障害は突然やってきます。だいたい今から飲みにいくぞー!って時に障害コールが来たりするんですよね。そんな時に限って簡単に解決できない内容だったりします。
私が所属するdotDではonedogというサービスを提供しています。AWSのサービスを活用して運用していて、障害発生時はインフラ担当である私がメインで動くことが多いです。そして先日までは障害対応を全て手作業で対応していました。普段の運用タスクもある中で障害対応で時間を取られるとかなりツライですよね。そこでIncident Managerに目をつけて実際にやってみた内容をご紹介します。
▼目次
- これまでの障害対応の問題点
- 描いていた障害対応自動化
- 実装概要
- 実際の実装内容
- インシデント発生テスト
- 実装後の運用上のメリット
- 別の実装案
- さいごに
これまでの障害対応の問題点
以下のような問題を抱えていました。
![]()
復旧まで1時間弱かかったり、復旧手順を知っている人しか対応しづらかったり、手作業なのでオペミスしてさらに別の問題が発生してしまう、などの問題は大なり小なりどこの運用業務でもあるんじゃないでしょうか?(最近はもしかしたら少ないのかもしれませんね)
これらの問題を解決すべく、真剣にどうすればいいか考えてみました。
描いていた障害対応自動化
障害対応の自動化と言っても様々です。何を、どういうタイミングで、どうやって自動化するのか、運用担当への連絡はどうするのか、連絡が必要なら手段はどうするか等々、考えることはたくさんありますね。今回はRDSインスタンスのCPU使用率が100%にはりついてしまった場合にスケールアップする内容を例にやったことをご紹介します。
では自動化の内容を考えてみましょう。RDSインスタンスのスケールアップをする場合、対象のRDSインスタンス名、今のインスタンスタイプ、スケールアップ後のインスタンスタイプが情報として必要です。タイミングはCloudWatchアラームで検知したタイミングでOKです。Incident ManagerはアクションとしてSystems Manager Automation(以降 SSM Automation)が使えるので、SSM Automationドキュメントにスケールアップ実行の流れを書いて対応しましょう。
![]()
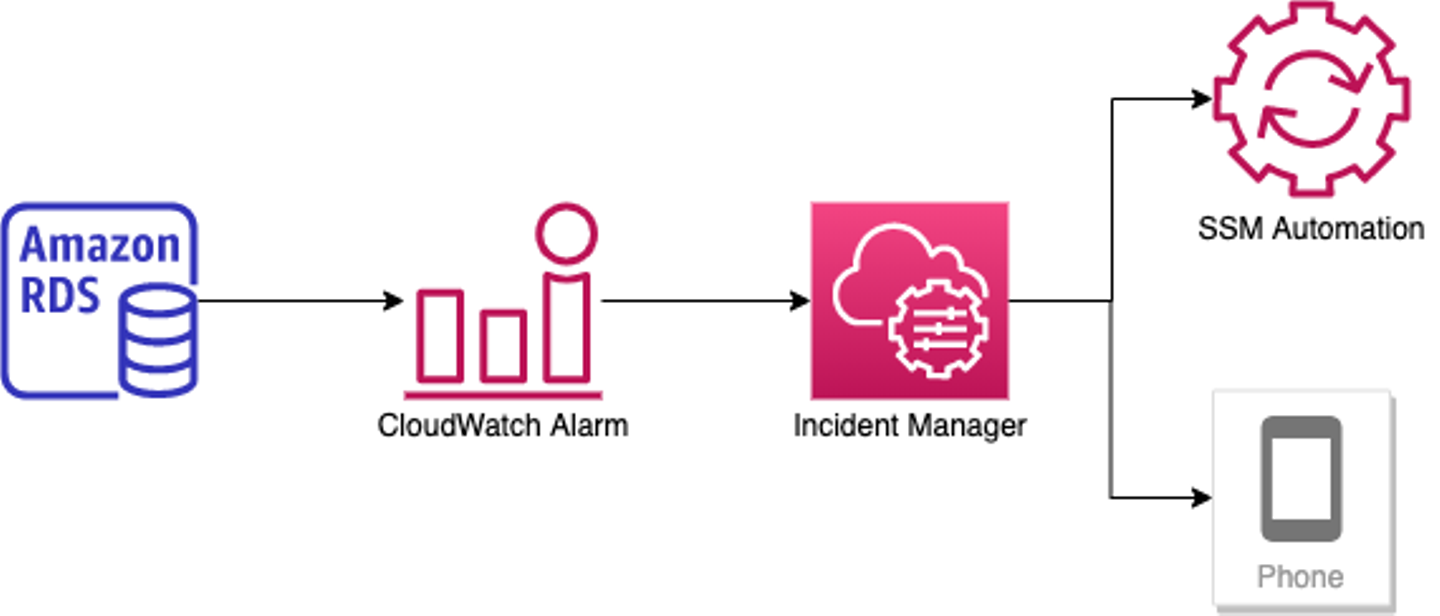
実装概要
図にするとこういう構成です。RDSのCPU使用率が100%近くになったら検知するCloudWatchアラームを設定して、アクションにIncident Managerのレスポンスプランを指定します。レスポンスプランは、チャットチャネルやエンゲージメントで通知するSlackチャンネルや電話番号を設定しておきましょう。あとはランブックで実行するSSM Automationドキュメントと実行に必要なIAMロールを指定すればOKです。たったこれだけで障害復旧作業を自動化できます。
![]()
実際の実装内容
SSM Automationドキュメント
まずはSSM Automationドキュメントから作成しましょう。コンテンツは以下のYAMLの通りです。Step1でaws:executeScriptアクションを指定してPythonスクリプトを実行する形にして、RDSインスタンス名やインスタンスタイプのリストを直書きして定義しておきます。SSM Automationでinputできるようにしていたとしても、レスポンスプランからinput情報を渡すことは現時点ではできません。
やってみてちゃんと動いてはいるものの、もうちょっといいやり方があるような気がしています。誰かこうすればいいよ!ってのがあれば教えてください。
description: null
schemaVersion: '0.3'
assumeRole: 'arn:aws:iam::111111111111:role/IAMロール名'
outputs:
- DefineRDSInstanceType.CurrentType
- DefineRDSInstanceType.TargetType
mainSteps:
- name: DefineRDSInstanceType
action: 'aws:executeScript'
inputs:
Runtime: python3.7
Handler: script_handler
Script: |-
def script_handler(events, context):
import boto3
client = boto3.client('rds')
current = client.describe_db_instances(
DBInstanceIdentifier='RDSインスタンス名'
)['DBInstances'][0]['DBInstanceClass']
type_list = ('db.m5.large', 'db.m5.xlarge', 'db.m5.2xlarge', 'db.m5.4xlarge', 'db.m5.8xlarge', 'db.m5.12xlarge', 'db.m5.16xlarge', 'db.m5.24xlarge')
for list in type_list:
if list == current:
target = type_list[type_list.index(list)+1]
break
return {'current': current, 'target': target}
isEnd: false
outputs:
- Selector: $.Payload.target
Type: String
Name: TargetType
- Selector: $.Payload.current
Type: String
Name: CurrentType
- name: ScaleupRDS
action: 'aws:executeAwsApi'
inputs:
Service: rds
Api: ModifyDBInstance
DBInstanceIdentifier: RDSインスタンス名
ApplyImmediately: true
DBInstanceClass: '{{ DefineRDSInstanceType.TargetType }}'
isEnd: falsedescription: null
schemaVersion: '0.3'
assumeRole: 'arn:aws:iam::111111111111:role/IAMロール名'
outputs:
- DefineRDSInstanceType.CurrentType
- DefineRDSInstanceType.TargetType
mainSteps:
- name: DefineRDSInstanceType
action: 'aws:executeScript'
inputs:
Runtime: python3.7
Handler: script_handler
Script: |-
def script_handler(events, context):
import boto3
client = boto3.client('rds')
current = client.describe_db_instances(
DBInstanceIdentifier='RDSインスタンス名'
)['DBInstances'][0]['DBInstanceClass']
type_list = ('db.m5.large', 'db.m5.xlarge', 'db.m5.2xlarge', 'db.m5.4xlarge', 'db.m5.8xlarge', 'db.m5.12xlarge', 'db.m5.16xlarge', 'db.m5.24xlarge')
for list in type_list:
if list == current:
target = type_list[type_list.index(list)+1]
break
return {'current': current, 'target': target}
isEnd: false
outputs:
- Selector: $.Payload.target
Type: String
Name: TargetType
- Selector: $.Payload.current
Type: String
Name: CurrentType
- name: ScaleupRDS
action: 'aws:executeAwsApi'
inputs:
Service: rds
Api: ModifyDBInstance
DBInstanceIdentifier: RDSインスタンス名
ApplyImmediately: true
DBInstanceClass: '{{ DefineRDSInstanceType.TargetType }}'
isEnd: false
SSM Automationドキュメント実行用IAMロール
上記のSSM Automationドキュメントを実行するためのロールを作成します。信頼されたエンティティはssm.amazonaws.comとしましょう。ポリシーは以下の通りです。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"rds:ModifyDBInstance",
"rds:DescribeDBInstances"
],
"Resource": "arn:aws:rds:ap-northeast-1:111111111111:db:RDSインスタンス名",
"Effect": "Allow"
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"rds:ModifyDBInstance",
"rds:DescribeDBInstances"
],
"Resource": "arn:aws:rds:ap-northeast-1:111111111111:db:RDSインスタンス名",
"Effect": "Allow"
}
]
}
Incident ManagerレスポンスプランからSSM Automationドキュメントを実行するためのIAMロール
SSM AutomationドキュメントはIncident Managerから実行されます。信頼されたエンティティはssm-incidents.amazonaws.comとして、ポリシーは以下でIAMロールを作成しましょう。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Resource": "arn:aws:ssm:*:111111111111:automation-definition/SSM Automationドキュメント名:*",
"Action": "ssm:StartAutomationExecution"
},
{
"Effect": "Allow",
"Resource": "arn:aws:iam::111111111111:role/実行用IAMロール名",
"Action": "sts:AssumeRole"
}
]
}{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Resource": "arn:aws:ssm:*:111111111111:automation-definition/SSM Automationドキュメント名:*",
"Action": "ssm:StartAutomationExecution"
},
{
"Effect": "Allow",
"Resource": "arn:aws:iam::111111111111:role/実行用IAMロール名",
"Action": "sts:AssumeRole"
}
]
}
Incident Managetレスポンスプラン
以下のAWSドキュメントに従ってAWS Chatbotや連絡先を設定しましょう。ランブックのところで、上記で作成したSSM Automationドキュメントとそれを実行するためのIAMロールを指定すれば設定完了です。設定は大して難しくないのとあまりいい絵ではないので、画面キャプチャは省略します。
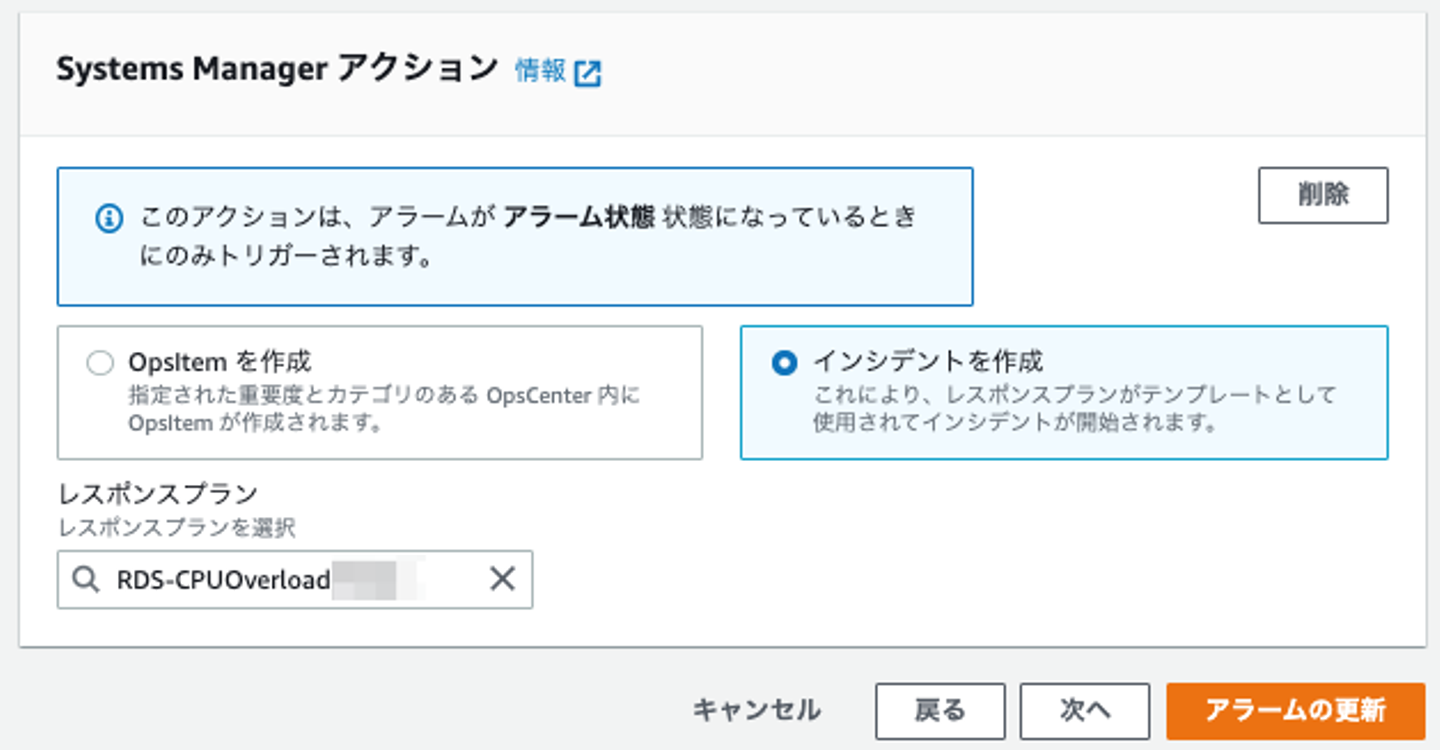
CloudWatchアラーム
最後にCloudWatchアラームからIncident Managerを呼び出す設定をしましょう。ステップ2のアクションの設定画面の一番下にSystems Managerアクションという設定箇所があります。そこで インシデントを作成 を選択して、先ほど作成したレスポンスプラン名を選択するだけです。これでALARM状態になったらIncident Managerで設定したレスポンスプランが呼び出されるようになりました。
![]()
以上で設定は完了です。ではテストしてみましょう。
インシデント発生テスト
IAMロールのポリシーを本当に必要なもののみに絞って設定したので、AWSマネジメントコンソールから先ほど作成したSSM Automationドキュメントを直接実行してテストすることができません。ですので実際の障害発生を想定してテストしてみましょう。以下のAWS CLIコマンドで指定したアラームをALARM状態にすることができますので、実行して擬似的に障害検知させてみます。
aws cloudwatch set-alarm-state --alarm-name アラーム名 --state-value ALARM --state-reason "test"
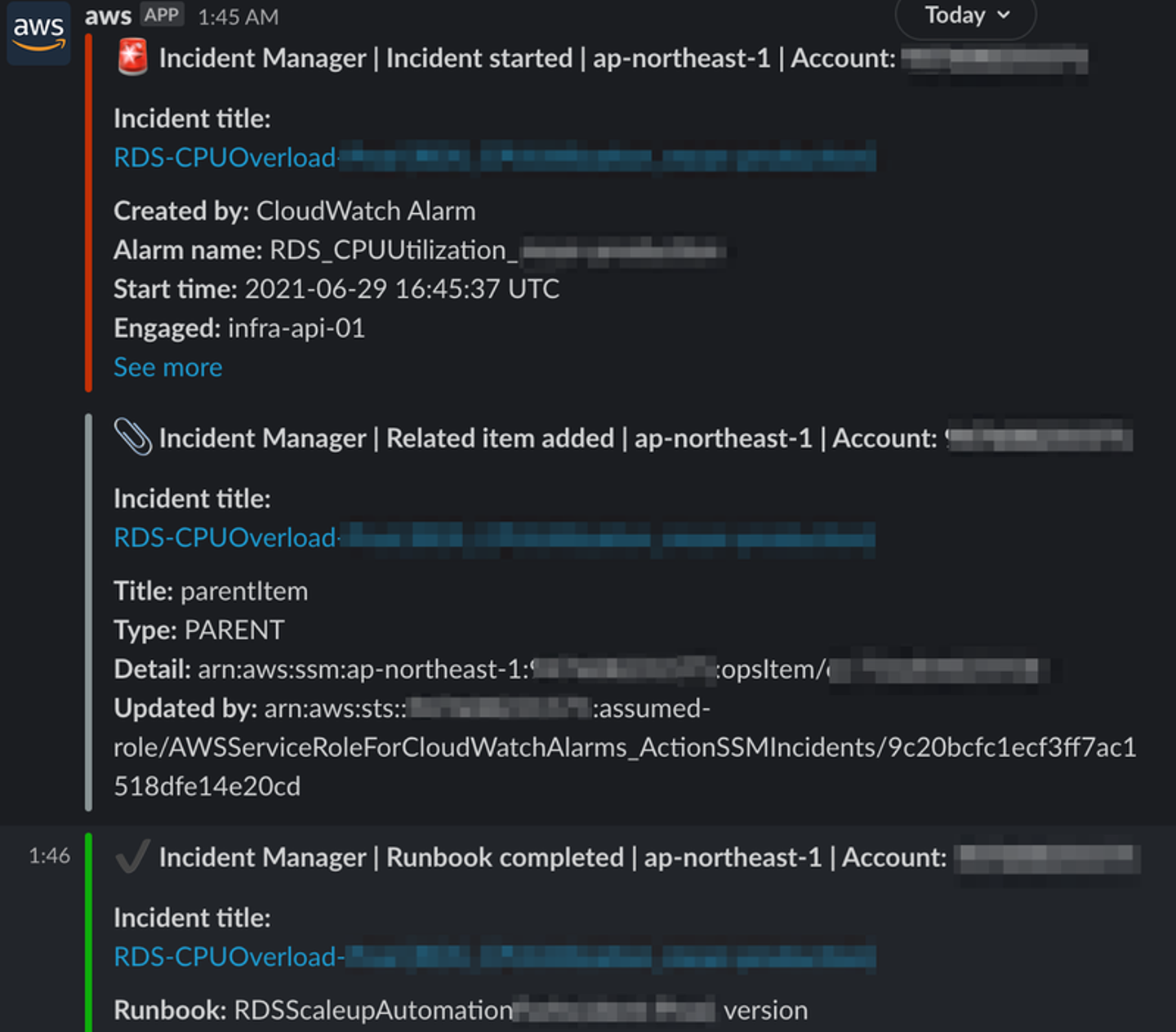
CloudWatchアラームで障害検知直後にSlackに通知が以下の画像のように来ました。インシデントが開始されたこと、OpsItemが作成されたこと、1分後にランブックが実行完了したことが通知されていますね。また、インシデント発生と同時に自動音声で電話がかかってきました。インシデント名をそのまま読み上げたりしてくれるので、レスポンスプランの名前は自動音声が読みやすい名前にしておくと電話でもある程度何が起こっているのかを知ることができます。
![]()
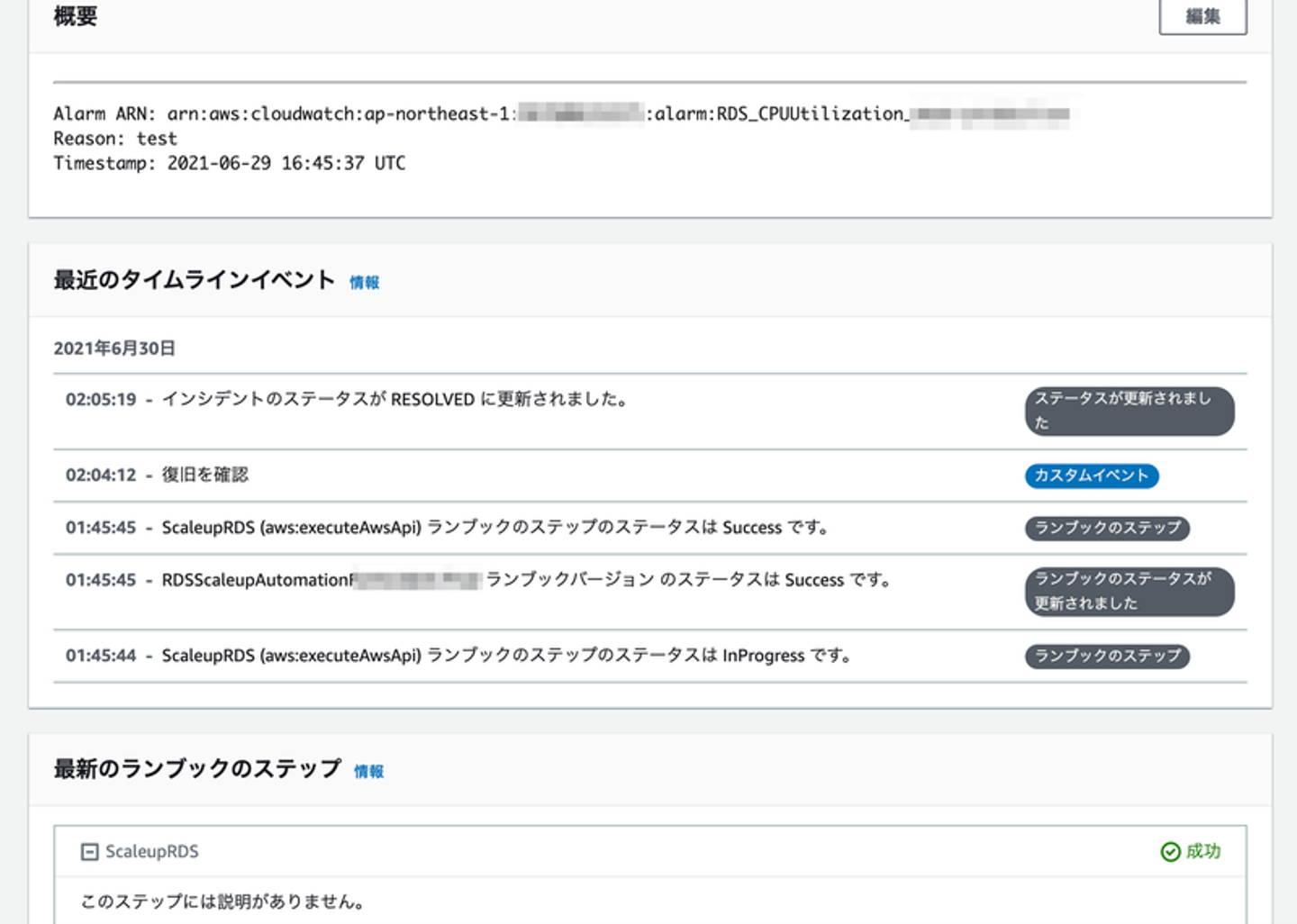
Incident Managerの画面では、タイムラインとランブックの状態を確認できます。タイムラインにはカスタムイベントとして自由に時系列で対応内容を追記することができますので、インシデントに関する情報はインシデントのタイムラインにまとめておくのもいいかもしれませんね。
![]()
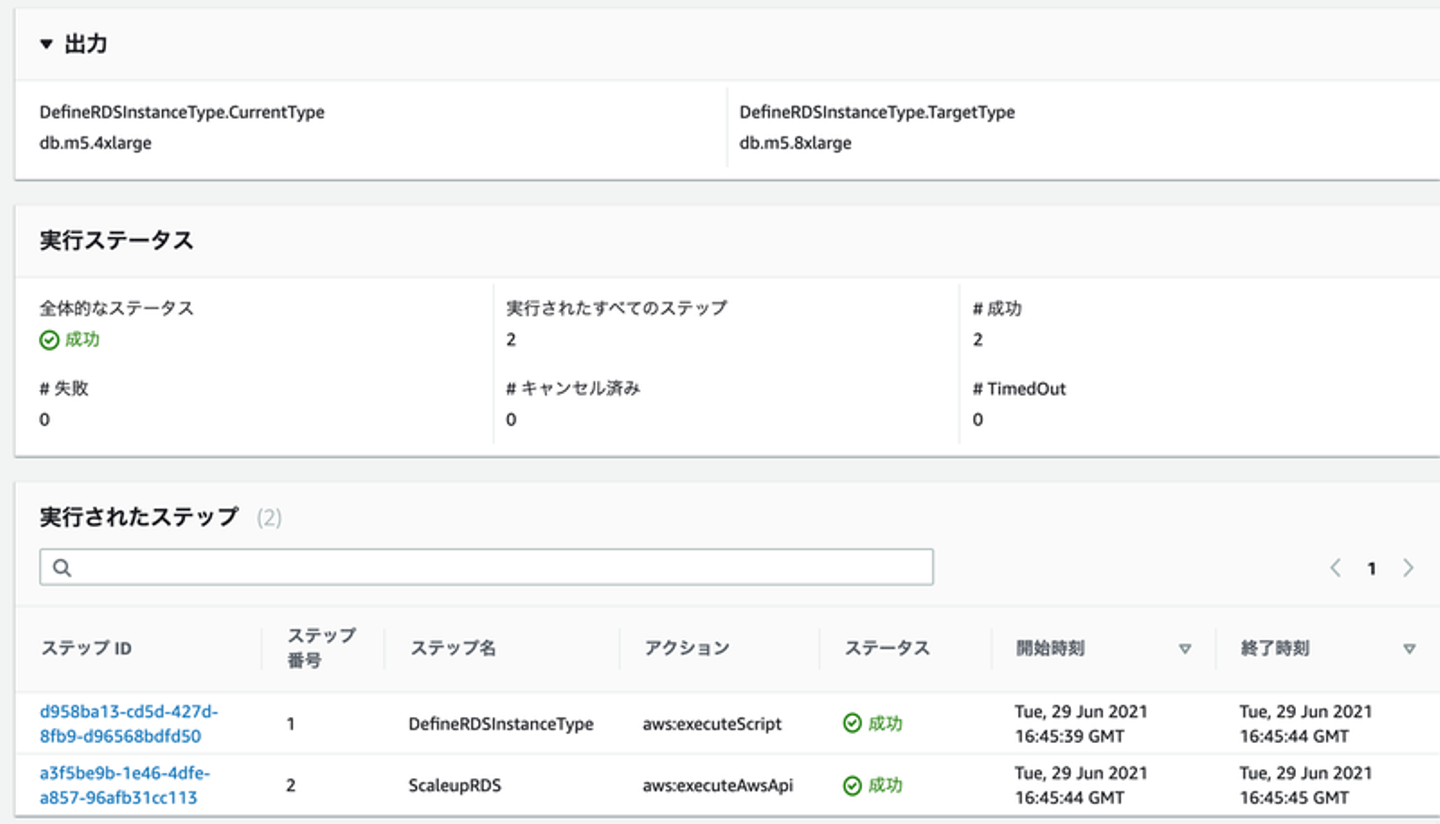
SSM Automationのステータスも確認しました。出力にスケールアップの前後のインスタンスタイプが表示されているので、このタイミングで何から何に変更したのかがわかるようになっています。
![]()
実際に対象のRDSインスタンスを確認すると、インスタンスタイプがdb.m5.8xlargeになっていました。RDSコンソールで最近のイベントをお見せして同じ日時に変更がかかっているのを紹介したかったんですが、画像を撮り忘れました…
実装後の運用上のメリット
実際に実装してみて、かなり障害対応の負荷が時間的にも体力的にも精神的にも下がったように思います。手順が決まっている復旧作業はこのような形で自動化しておくと、サービスを利用されているユーザの皆様にもご迷惑をおかけしてしまう時間をかなり短縮できますね。
![]()
別の実装案
上記の実装内容でこのように書きました。
![]()
これは、複数のリソースをSSM Automationの対象としても、リソースごとにSSM Automationドキュメントを作成しないといけない、ということになります。大規模なシステムを運用されている場合だと、この制約はかなりつらいのではないでしょうか?
でも大丈夫です! 複数リソースに対応して、かつIncident Managerを使って(手作業にはなりますが)タイムラインを残したり自動電話連絡をかけたりすることはできます。
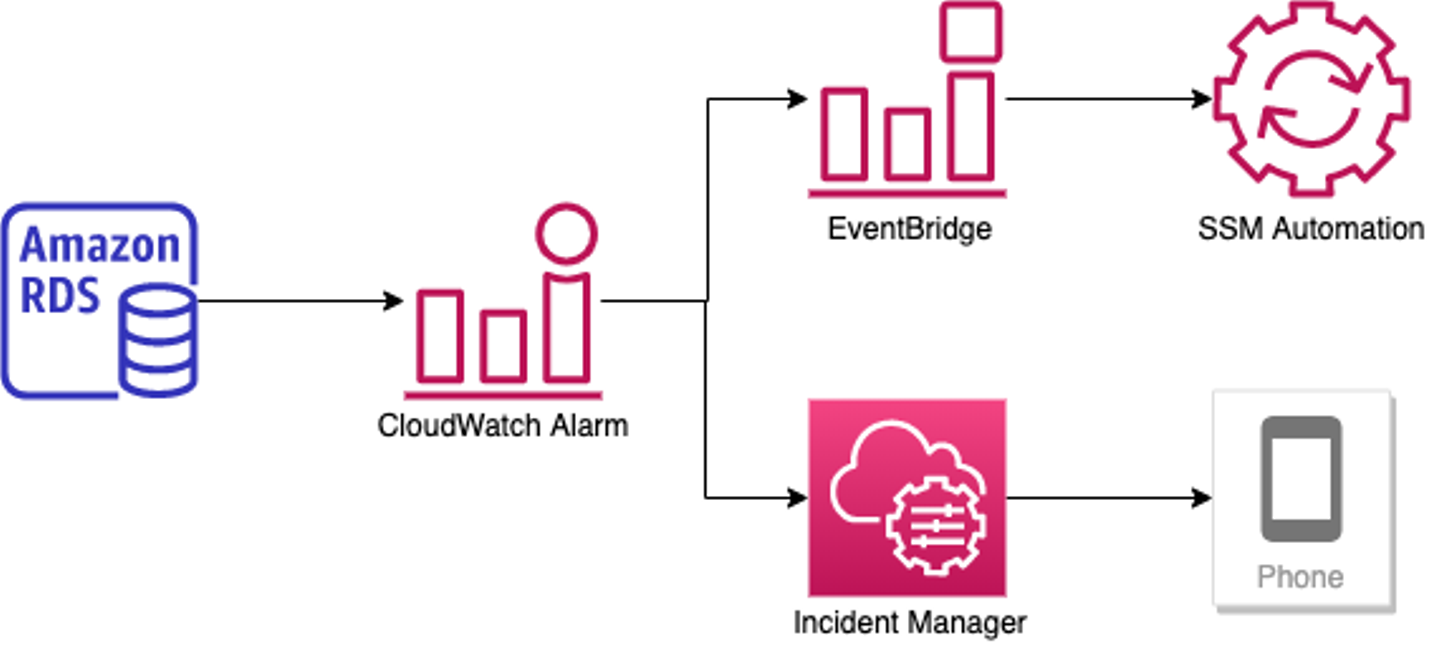
図で示すとこのような構成にして複数リソースに対応できます。やってることは単純で、EventBridgeでCloudWatchアラームのALARM状態をトリガーにして、動的にinputを定義できるSSM Automationドキュメントを実行するだけです。一方でIncident Managerから実行するSSM Automationは説明や確認手順を記載しただけのものを定義して自動電話連絡するようにしておけば、どのリソースで障害発生していて何を確認すればいいのかがわかります。他にもやり方はあると思いますが、このようなシンプルな形で始めるのもいいと思います。
![]()
さいごに
今回は障害対応の自動化について実際に実装した内容をご紹介しました。これでElasticsearchのEBSサイズ拡張とRDSスケールアップとAPIのデプロイ作業が自動化された環境になりました。他にもやりたいことはたくさんありますが、少しずつ自動化タスクも進めていきたいと思います。
今回は障害対応の自動化を例に書きましたが、他にも運用タスクで自動化したり開発がスムーズになるような仕組みを整えたりしています。このような自動化の仕組みを作ったり運用したりしていくメンバーがまだまだ必要です。規模に関係なく何かしらの自動化に興味がある方がいれば是非一緒にやっていきましょう!





/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)


/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)
/assets/images/8864511/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1644990968)


