こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。
この記事では、Two-Towerモデルについて技術検証した話についてご紹介したいと思います。
目次
Two-Towerモデル
協調フィルタリングとコールドスタート問題
Two-Towerモデルによるコンテンツ特徴量の活用
準備
疑似データセット作成
行列分解によるベースライン
実装
特徴量とモデル定義
対称学習
実験
nDCGでの評価
コールドスタートユーザーに関する評価
まとめ
Two-Towerモデル
協調フィルタリングとコールドスタート問題
推薦の一般的なアルゴリズムには協調フィルタリングが挙げられます。これは既知の(ユーザー, アイテム)のペアの評価値をもとに未知の(ユーザー, アイテム) のペアに関する評価値を予測し、その予測値をもとに推薦をするアルゴリズムです。また、協調フィルタリングの計算コストを抑えた行列分解も広く知られています。
協調フィルタリングや行列分解のアプローチはシンプルながら比較的精度高くユーザーの嗜好に沿った推薦が可能です。一方、既知の評価値を全く持たないユーザー・アイテムについては推論することが出来ないコールドスタート問題も指摘されています。
新規登録したユーザーや、しばらくサービスを使っていなかったユーザーが復帰した際など、直近の(ユーザー, アイテム) の評価値が存在しないユーザーはどんなサービスであっても必ず発生しますが、こうしたユーザーには協調フィルタリングや行列分解を直接適用することは難しくなっています。
Two-Towerモデルによるコンテンツ特徴量の活用
Two-Towerモデルはユーザー、アイテム両方についてembeddingを作成し、それらの内積やコサイン類似度をスコアとして扱います。
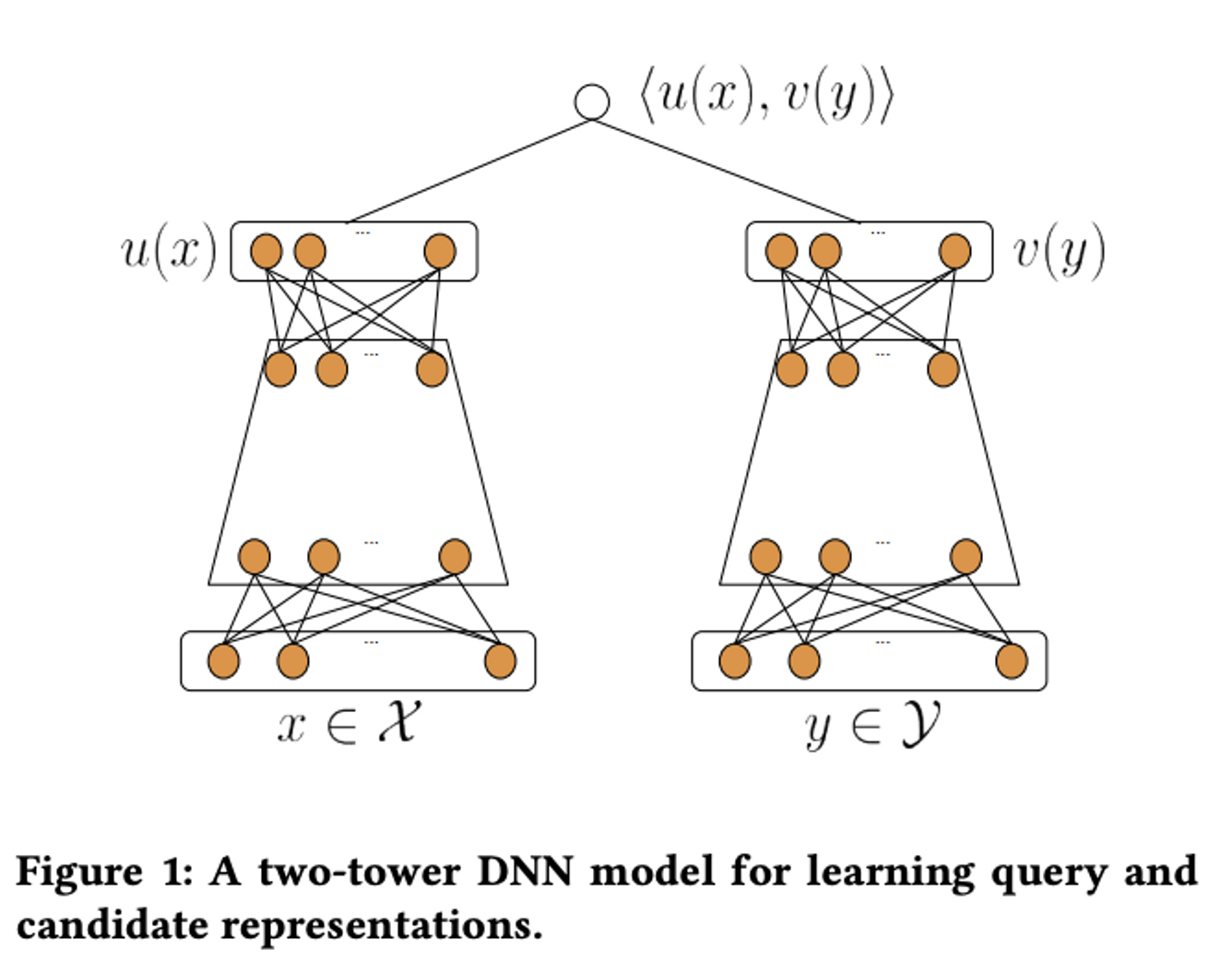
"Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations"より引用
このアルゴリズムの特徴の一つは、ユーザー・アイテムのembeddingを推論時に独立に計算できるため、ユーザーに対して推薦するアイテムを近似近傍探索によって高速に計算できる点にあると考えています。これにより、膨大な数のアイテムがある状況でもユーザーに対して推薦候補となるアイテムを非常に効率良く算出することが可能です。
また、ニューラルネットによってユーザー・アイテムのembeddingを計算することになりますが、その際協調フィルタリングや行列分解アプローチでは利用していないコンテンツ特徴量も利用することができるため、行動に関する特徴量がないようなコールドユーザー・アイテムに対しても適用可能な手法になっています。
準備
疑似データセット作成
推薦タスクを検証できるデータセットでユーザー・アイテム双方についてコンテンツ情報が充実しているデータセットを見つけられなかったので、今回は疑似データセットを作成して実験してみようと思います。
手順としては、
- ユーザーのプロフィール・アイテムの商品情報を生成AIで擬似的に作成
- ランダムに選んだユーザー・アイテムのペアについて、プロフィール・商品情報を踏まえて生成AIが評価値(rating)を作成
のようにしました。
これにより、ある程度プロフィール・商品情報を踏まえてある程度合理的に評価値が付与された擬似データセットになっています。
作成に使用したnotebookはこちらです。
行列分解によるベースライン
まずはTwo-Towerモデル以外のアプローチと比較するため、ベースラインとして行列分解を用いたアプローチを先に計算してみようと思います。今回は簡単のため、Surpriseを使用したSVD (行列分解手法の一つ) をベースラインとします。
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(train_df, reader)
trainset = data.build_full_trainset()
algo = SVD(n_factors=128)
algo.fit(trainset)上記で実装したnotebookはこちらです。
実装
次に実際に行動・コンテンツ特徴量の両方を利用したTwo-Towerモデルを作って試してみます。
特徴量とモデル定義
今回作成したデータセットでは行動(クリックやいいねなど)に関する特徴量を生成しておらず、代わりに先程SVDで行列分解したユーザー・アイテムのlatent vectorを行動特徴量とみなして利用しようと思います。
テキストなどのコンテンツ特徴量は直接は利用することは出来ないので、テキスト埋め込みモデルを利用してembeddingに変換して利用します。カテゴリの特徴量に関してはone-hot encodingによってembeddingに変換して利用します。
class UserTower(nn.Module):
"""ユーザータワー"""
def __init__(self, user_emb_dim, intro_emb_dim, hidden_dims=[128, 64]):
super(UserTower, self).__init__()
# 入力次元: user_embedding + introduction_embedding + age_log
input_dim = user_emb_dim + intro_emb_dim + 1
# MLPレイヤーの構築
layers = []
prev_dim = input_dim
for hidden_dim in hidden_dims:
layers.extend([
nn.Linear(prev_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.LeakyReLU(),
nn.Dropout(0.2),
])
prev_dim = hidden_dim
self.mlp = nn.Sequential(*layers)
self.output_dim = hidden_dims[-1]
def forward(self, user_embedding, introduction_embedding, age_log):
# age_log: (batch,) → (batch, 1)
x = torch.cat([
user_embedding,
introduction_embedding,
age_log.unsqueeze(1)
], dim=1)
x = self.mlp(x)
x = F.normalize(x, p=2, dim=1) # L2正規化
return x
class ItemTower(nn.Module):
"""アイテムタワー"""
def __init__(self, item_emb_dim, n_genres, desc_emb_dim, hidden_dims=[128, 64]):
super(ItemTower, self).__init__()
# 入力次元: item_embedding + genres(one-hot) + description_embedding
input_dim = item_emb_dim + n_genres + desc_emb_dim
# MLPレイヤーの構築
layers = []
prev_dim = input_dim
for hidden_dim in hidden_dims:
layers.extend([
nn.Linear(prev_dim, hidden_dim),
nn.BatchNorm1d(hidden_dim),
nn.LeakyReLU(),
nn.Dropout(0.2),
])
prev_dim = hidden_dim
self.mlp = nn.Sequential(*layers)
self.output_dim = hidden_dims[-1]
def forward(self, item_embedding, genres, description_embedding):
x = torch.cat([
item_embedding,
genres,
description_embedding
], dim=1)
x = self.mlp(x)
x = F.normalize(x, p=2, dim=1) # L2正規化
return x
class TwoTowerModel(nn.Module):
"""Two-Towerモデル"""
def __init__(self, user_emb_dim, intro_emb_dim, item_emb_dim, desc_emb_dim,
n_genres, hidden_dims=[128, 64], temperature=0.07):
super(TwoTowerModel, self).__init__()
# ユーザータワー
self.user_tower = UserTower(
user_emb_dim=user_emb_dim,
intro_emb_dim=intro_emb_dim,
hidden_dims=hidden_dims
)
# アイテムタワー
self.item_tower = ItemTower(
item_emb_dim=item_emb_dim,
n_genres=n_genres,
desc_emb_dim=desc_emb_dim,
hidden_dims=hidden_dims
)
# Temperatureパラメータ
self.temperature = nn.Parameter(torch.tensor(temperature))
def forward(self, user_features, item_features):
# ユーザー埋め込み
user_emb = self.user_tower(
user_features['user_embedding'],
user_features['introduction_embedding'],
user_features['age_log']
)
# アイテム埋め込み
item_emb = self.item_tower(
item_features['item_embedding'],
item_features['genres'],
item_features['description_embedding']
)
return user_emb, item_emb
def get_user_embedding(self, user_features):
"""ユーザー埋め込みを取得"""
return self.user_tower(
user_features['user_embedding'],
user_features['introduction_embedding'],
user_features['age_log']
)
def get_item_embedding(self, item_features):
"""アイテム埋め込みを取得"""
return self.item_tower(
item_features['item_embedding'],
item_features['genres'],
item_features['description_embedding']
)対称学習
元論文によれば、Two-Towerモデルでは対称学習(Contrastive learning)によって学習を行っています。今回はそれに習って対称学習で学習するようにしてみます。
def infonce_loss_with_in_batch_negatives(user_emb, item_emb, labels, temperature):
"""
InfoNCE Loss with in-batch negatives
バッチ内の全アイテムをnegativeサンプルとして使用する対照学習の損失関数。
Positive pair (label=1) のみがターゲットとなる。
Args:
user_emb: [batch_size, embedding_dim] - L2正規化済み
item_emb: [batch_size, embedding_dim] - L2正規化済み
labels: [batch_size] - 1 for positive, 0 for negative
temperature: スケーリングパラメータ
Returns:
loss: InfoNCE loss (positive samplesに対してのみ計算)
"""
batch_size = user_emb.shape[0]
# 全(user, item)ペアの類似度を計算: [batch_size, batch_size]
similarity_matrix = torch.matmul(user_emb, item_emb.T) / temperature
# Positive samplesのマスク
positive_mask = labels == 1
# Positive samplesが存在しない場合は0を返す
if positive_mask.sum() == 0:
return torch.tensor(0.0, device=user_emb.device)
# Positive pairの類似度 (対角成分)
positive_scores = torch.diagonal(similarity_matrix)
# InfoNCE loss: -log(exp(positive) / sum(exp(all)))
losses = []
for i in range(batch_size):
if positive_mask[i]:
all_scores = similarity_matrix[i]
loss_i = -positive_scores[i] + torch.logsumexp(all_scores, dim=0)
losses.append(loss_i)
# Positive samplesのlossの平均
loss = torch.stack(losses).mean()
return loss最終的に作成したnotebookはこちらに公開しています。
実験
nDCGでの評価
今回疑似データセットでは(ユーザー, アイテム)の評価値を1~5の間で設定していますが簡単のため
- 1~3: negative
- 4~5: positive
とみなしてnDCG@kで評価を行いたいと思います。データセットの (ユーザー, アイテム)の評価値データの一部を評価用として分離し、評価用データセットでユーザーごとのnDCGで推薦モデルの精度を確認してみます。
疑似データセットを用いたベースライン (SVD) とTwo-Towerモデルを用いたnDCG@kは下記のような結果となりました。
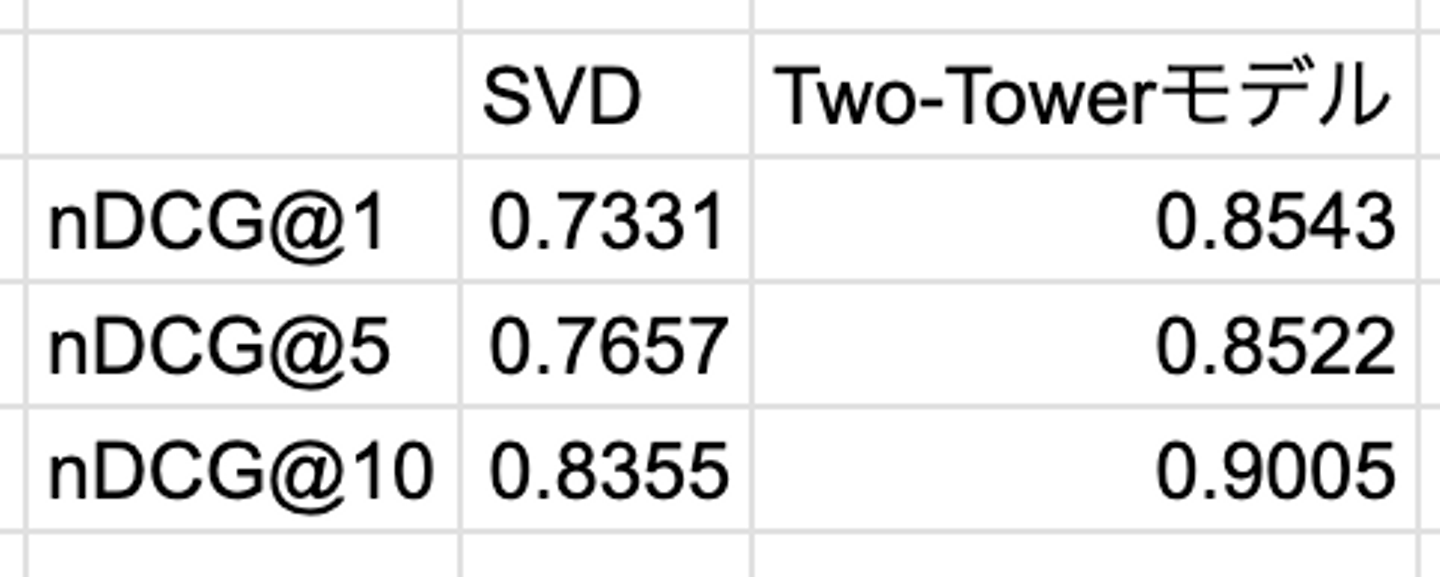
もちろん、今回使用していないテクニックを駆使したりハイパーパラメータの調整をすることで評価結果は変化するとは思いますが、少なくとも単純なSVDと比較して決して悪くないモデルになっていると思います。
コールドスタートユーザーに関する評価
上記で通常の行列分解アプローチと比べて遜色ない精度が出ていそうなことができました。今回はさらにコールドスタート問題に対しても有効であることを確認すべく、意図的にコールドスタートユーザーを作って再度検証してみます。コールドスタートユーザーは行動のEmbeddingを持たないので、その他のEmbeddingの平均値を代用して推論するようにしています。
結果としては下記のようになりました。(SVDは学習時に登場していないユーザーは推論できないので評価対象外としています)

今回は疑似データセットをコンテンツ情報から逆算してratingを生成しているからか、コンテンツ特徴量しかないようなコールドスタートユーザーであっても遜色ない精度という結果になりました。実データでは生成過程はこのようなことはないので、精度はもっと落ちると考えられます。
とはいえ、コンテンツ特徴量しかないような状況であっても、Two-Towerモデルによってある程度推薦が出来ていることがわかりました。
使用したnotebookはこちらに公開しています。
まとめ
今回はTwo-Towerモデルを用いた推薦手法についてご紹介しました。通常の条件下での推薦だけでなく、コールドスタート問題に対してもある程度対応することができることが確認できました。
今回は疑似データセットを使ってかなり簡略化して実装しているので、実データに適用させるには課題は多々あるとは思いますが、方針はそこまで悪くなさそうだと考えています。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。ユーザーファーストの推薦システムを作ることに興味があるという方は、下の募集の「話を聞きに行きたい」ボタンから気軽に話を聞きに来ていただけるとうれしいです!
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

