
こんにちは。ウォンテッドリーでデータサイエンティストをしている林(@python_walker)です。
今回、推薦システムの国際会議であるRecSysにオンラインで聴講参加してきたので、その参加報告をしたいと思います。ウォンテッドリーでは2020年からデータサイエンティストがRecSysに参加してきており、今年で通算5回目になります。過去の参加報告は2020年、2021年、2022年、2023年で見ることができますので、興味のある方はリンク先の記事を是非読んでみて下さい。
目次
RecSysとは
大会の概要
基調講演
なぜ RecSys に参加したのか
印象に残った論文
Pseudo-online Measurement of Retrieval Recall for JobRecommendations - A case study at Indeed
Revisiting BPR: A Replicability Study of a Common Recommender System Baseline
Fair Reciprocal Recommendation in Matching Markets
Utilizing Non-click Samples via Semi-supervised Learning for Conversion Rate Prediction
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Models
共により良い推薦システムを突き詰めていく人 Wanted
RecSysとは
RecSys は The ACM Conference Series on Recommender Systems の略称で、ACM(計算機学会)が主催する推薦システムに関する主要な国際会議の1つです。この会議には、推薦システムの研究を行う研究者や、Eコマースやメディア、HR など多様な領域で活躍するデータサイエンティスト・MLエンジニアが集まり、推薦システムに関する最新の学術研究成果や産業界での応用など、幅広い内容に関する発表や議論が行われます。
今年はイタリアのバーリで開催され、メインカンファレンスはペトルッツェリ劇場を使って行われました。現地に行っていないので公式のXの投稿を↓に貼るのですが、とても素敵な会場です(現地参加したかった...)。
大会の概要
学会は10/14 ~ 18の5日間に渡り行われ、初日と最終日はTutorial/Workshop、中3日は本会議という構成でした。本会議初日にはOpening Sessionが行われ、今回の大会の規模などが紹介されました。
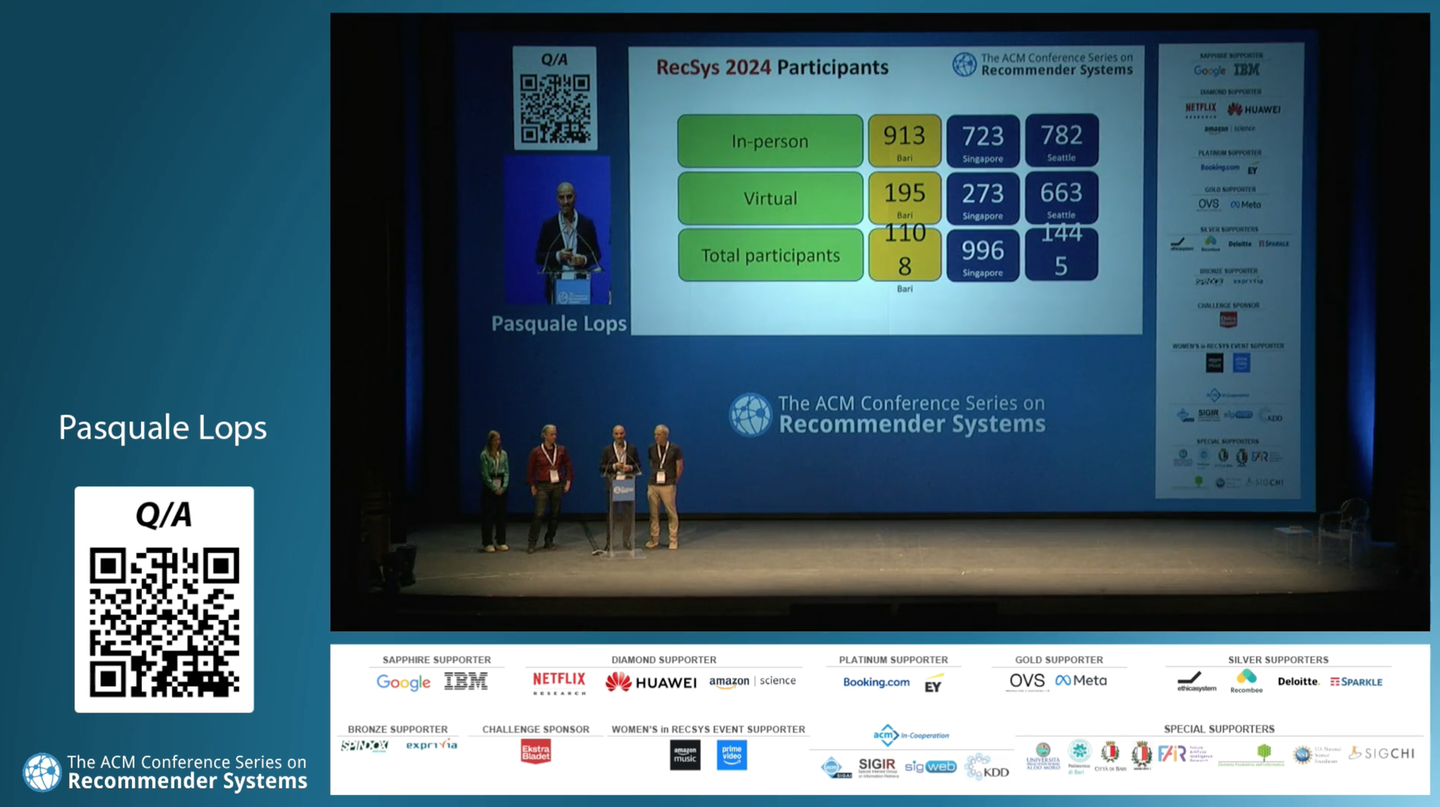
昨年のシンガポール開催の時と比較して参加者総数は増加しており、傾向変化としては、より現地参加する人数が増えたようです。
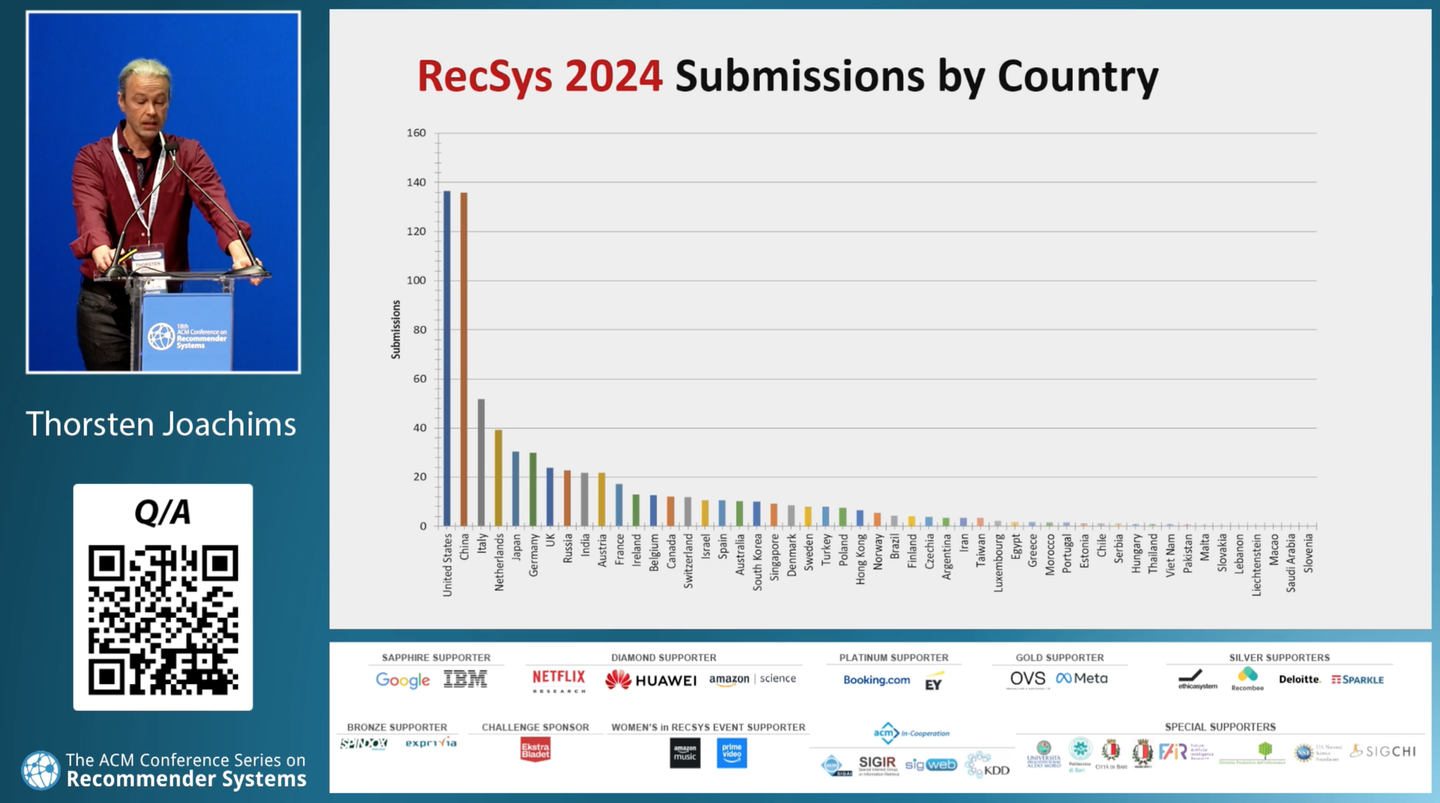
国別の論文投稿数です。アメリカ・中国がTop-2で抜きん出ていますが、日本からの応募も多く、5位につけています。
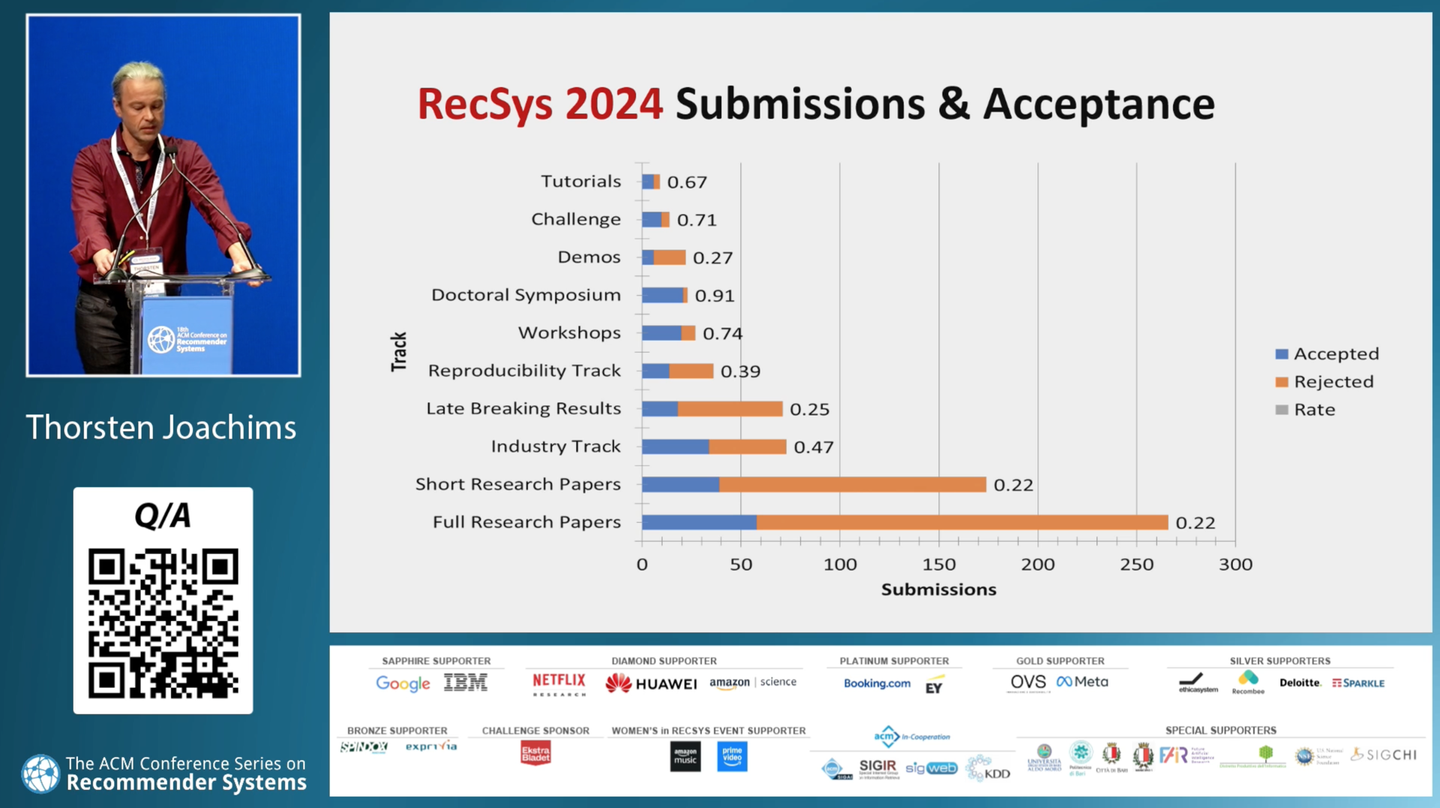
ちなみに論文の採択率に関して見てみると、やはりFull/Short Research Paperは採択率が22 %ほどで、狭き門であることが伺えます。企業が主に論文を出すであろうIndustry Talkは採択率47 %、Workshopsは74 %でした。
基調講演
本会議では、3つの基調講演が行われました。1件目はジョージア工科大学のMark Riedl教授による説明可能AIに関する講演、2件目はUCバークレーのMichael I. Jordan教授による講演、3件目はSpotifyのMounia Lalmas氏によるSpotifyで用いられている推薦技術に関する講演でした。
なぜ RecSys に参加したのか
ウォンテッドリーでは、推薦システムを技術戦略上の最も重要な領域の一つと位置づけています。推薦システムの成長はプロダクトの成長に直結しているため、この領域の最新技術傾向を把握することは重要です。また、近年ではLLMの急激な発展により、推薦システムでもLLMを活用した手法が次々に提案されています。このように日々発展をし続ける分野において、研究の最前線がどのようになっているのか、他の企業ではどのような取り組みをしているのかを知ることは重要性が非常に高いと考えています。
もちろん、参加しただけでは自分たちのプロダクトを改善することはできません。我々が持っている技術的課題に対して、学会で得られた知見を試していくといった活動によってさらにプロダクトを良くしていければと思っています。
印象に残った論文
ここからは、私が発表を聞いていて印象に残った論文をいくつかピックアップしてご紹介していければと思います。
Pseudo-online Measurement of Retrieval Recall for JobRecommendations - A case study at Indeed
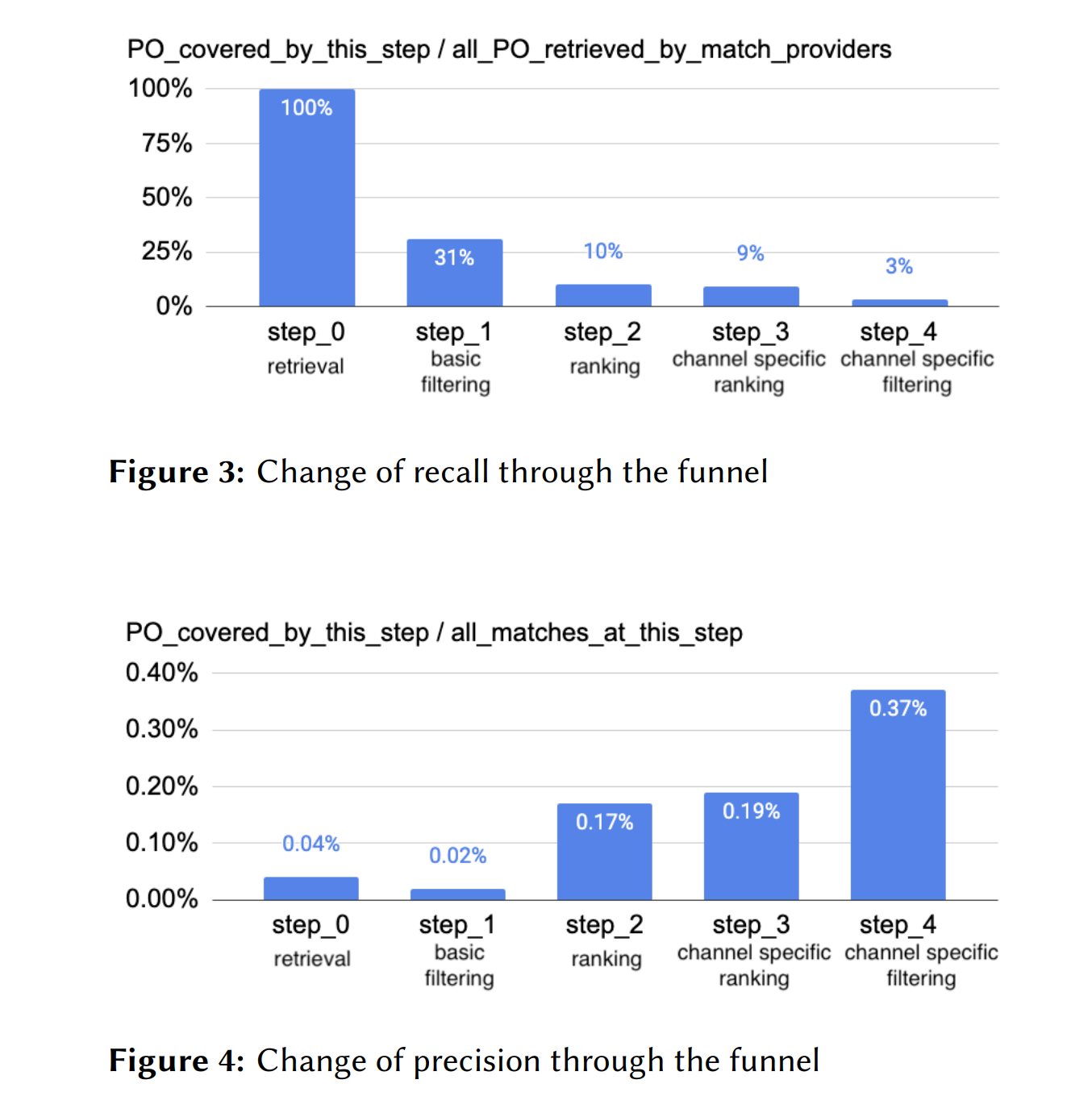
RecSys in HR (Workshop)でのIndeedの論文です。Indeedではmulti stageの推薦システムを運用しており、その中のretrieval stageでのオフラインテスト結果と、オンラインテスト結果の不整合が課題としてあるということでした。論文中ではRecallをビジネス指標に適合させる形で設計して、オンラインテストとの相関を取ることができたというケーススタディが紹介されています。
推薦システムの各ステップでの分析をして、どこにボトルネックがあるのか丁寧に見極めていたことがわかる構成になっておりとても参考になりました。(下図は論文から引用)
Revisiting BPR: A Replicability Study of a Common Recommender System Baseline
BPR損失関数を使った行列分解(Matrix Factorization, MF)モデルの性能を再検証した論文です。MFの実装は本家以外にもさまざまあり、それぞれ微妙に実装が異なるようです。この論文では、
- MyMediaLite(本家のC#での実装)
- Recbole
- Implicit
- Elliot
- LightFM
について、正規化項やオプティマイザ、負例サンプリングのアルゴリズムをさまざまに変えた上で性能を比較しています。報告された結果は下のようになっており、実装によって、私が想像していた以上に性能が変わることには驚きました。(下図は全て論文からの引用)
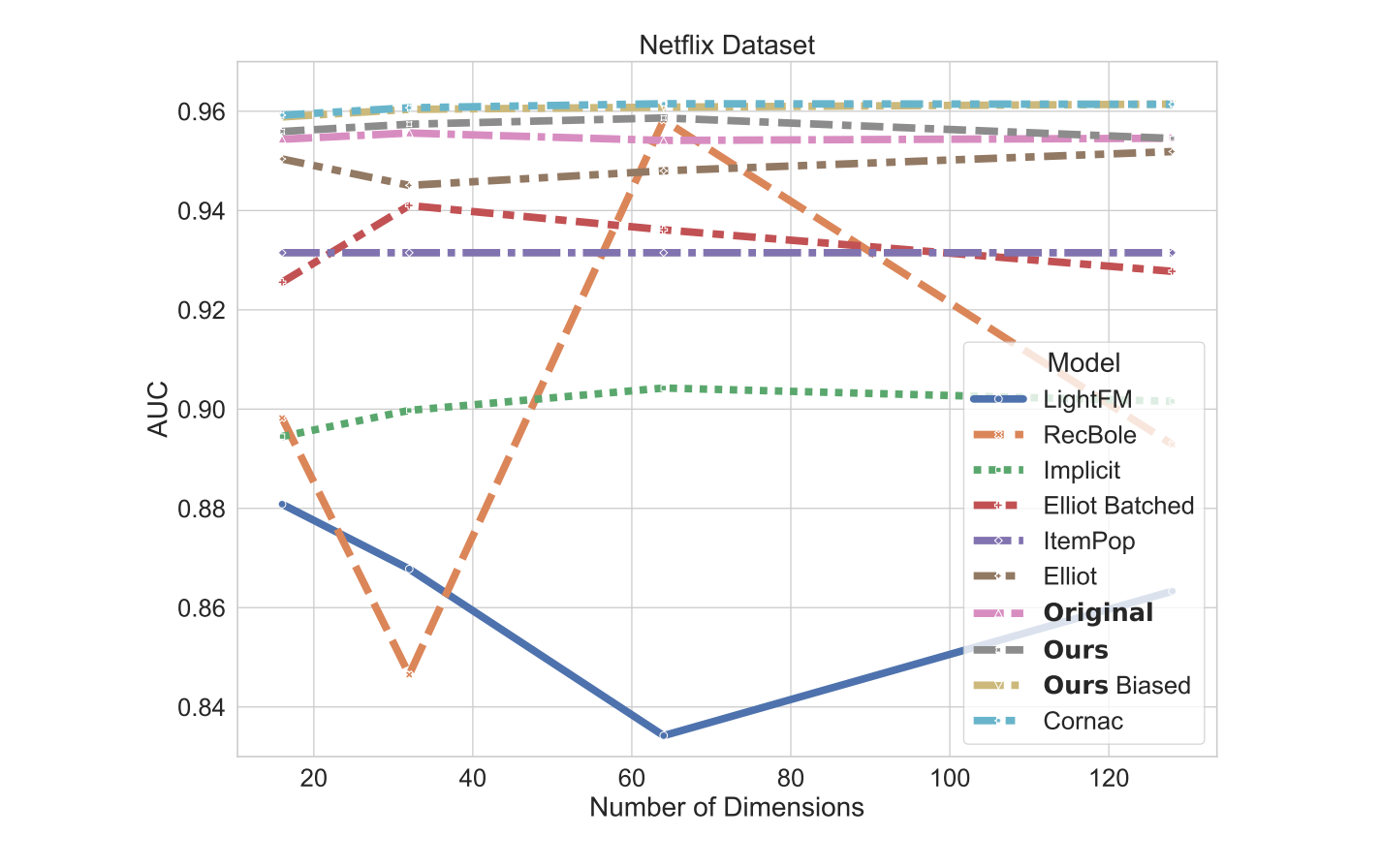
筆者はこの性能差について、負例サンプリングとオプティマイザの相性など議論していたのも非常に興味深かったです。
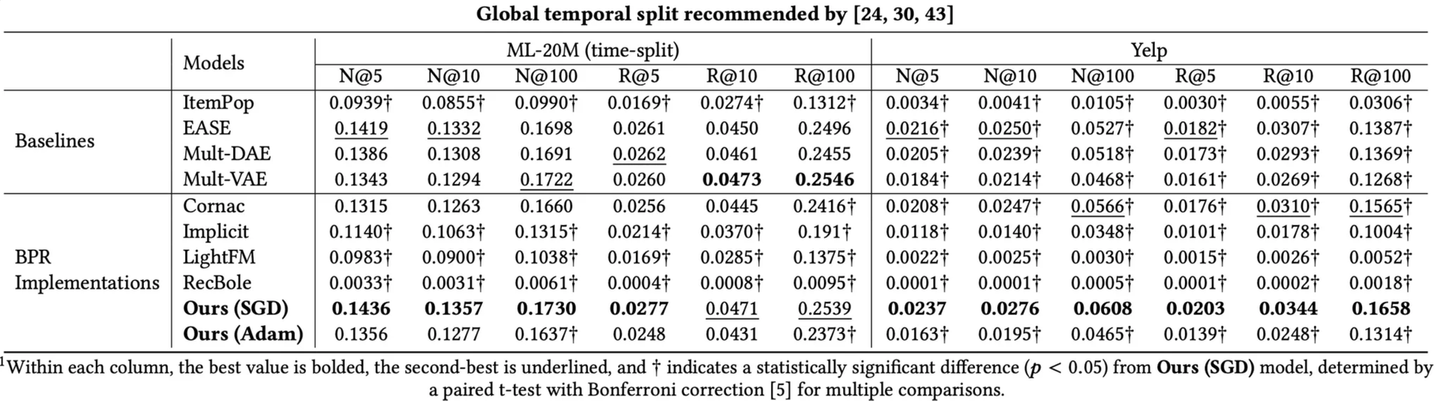
論文の最後には後続のSOTAモデルとの比較も行われており、適切にパラメーターを調整すればBPRの性能はこれらのモデルを超える、もしくは同程度のものになることが示されていました。新しい手法を提案する論文ではbaselineとして挙げられることが多いMF-BPRですが、そのポテンシャルの高さは自分の認識を改めなければならないと感じました。
Fair Reciprocal Recommendation in Matching Markets
サイバーエージェントさんの相互推薦モデルにおける公平性に関する論文です。デーティングサービスのようなtwo sideプラットフォームで、両サイドのユーザー(デーティングサービスの文脈では男性と女性)でNash Social Welfare (NSW)を最大化することによって、両サイドの不公平さを大きく減少させられることを、合成データと実データを使った実験で示しています。(下図は論文から引用)
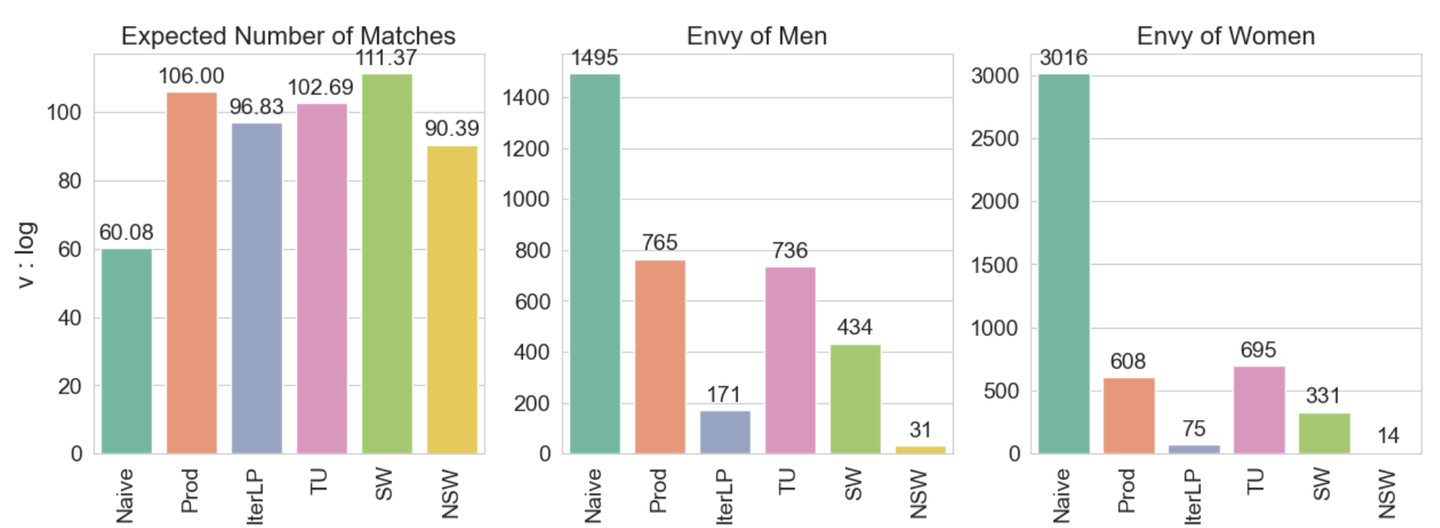
論文中でも述べられているように、相互推薦システムでの公平性を議論した論文は多くはなく、ユーザーと企業のtwo sideプラットフォームである Wantedly Visitの推薦システムを開発している我々にとって非常に勉強になる内容でした。
Utilizing Non-click Samples via Semi-supervised Learning for Conversion Rate Prediction
コンバージョンレート(CVR)予測の精度を向上させた、という論文です。CVR予測モデルを学習するのによく使われるのが、クリックログを使ってそこからコンバージョンが発生するかどうかを予測するタスクを解かせるというものですが、これだとクリックが発生したという前提条件を満たしたデータでの学習になるのでバイアスが乗ってしまいます。だからと言ってクリックされていないデータについても、コンバージョンが発生していないというラベルを単純につけて学習に使うとラベルノイズの影響を受けてしまいます(見逃しなどによるFalse Negativeサンプル)。
筆者らは、CTR予測と組み合わせたマルチタスク学習のフレームワークと、クリックが発生していないデータに対して擬似ラベルを活用することによって上記の問題に対処しています。(下図は論文から引用)
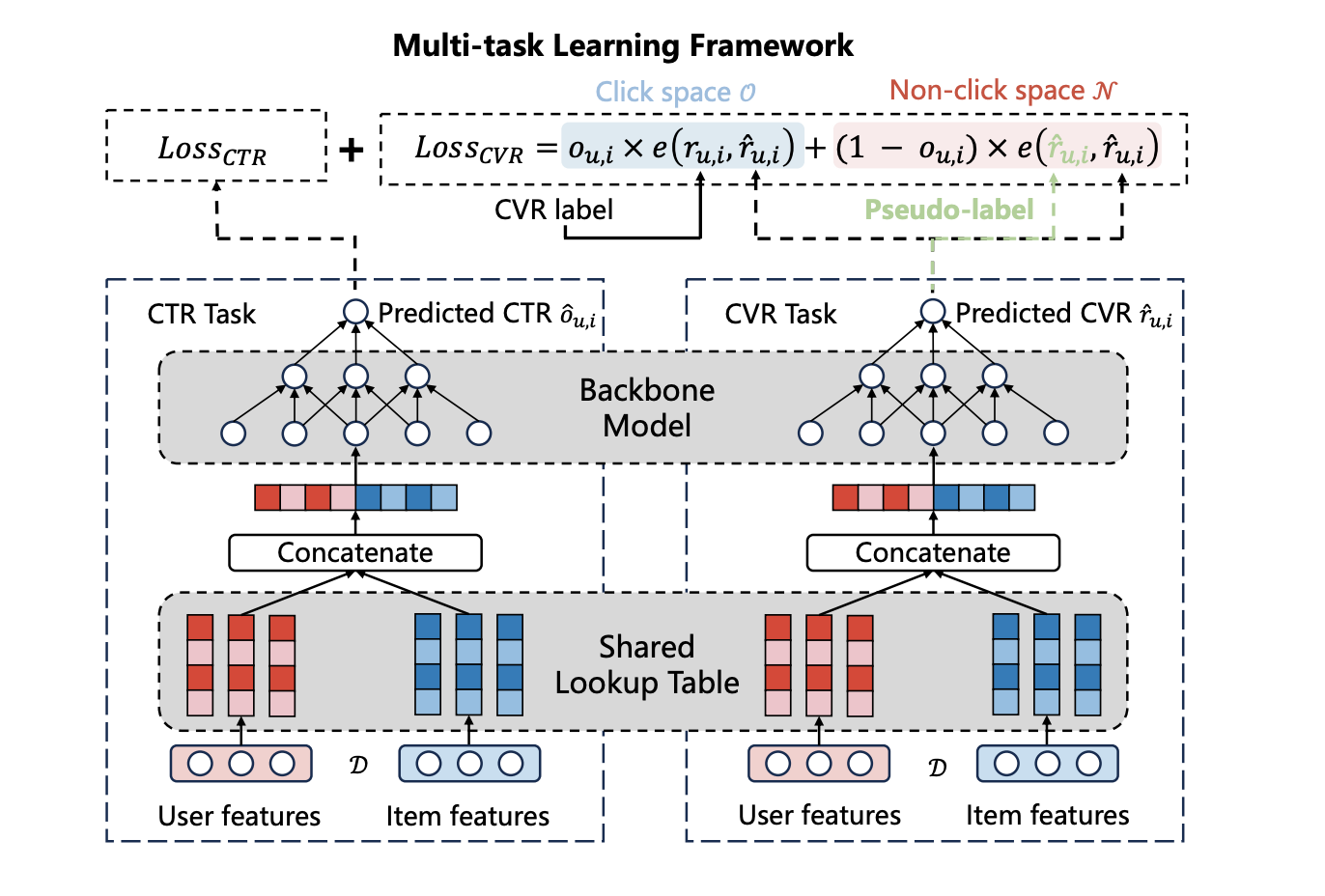
クリックが発生していないアイテムにも、擬似ラベルを使ってラベルを振り分けて学習に使うというアイデアは、実は最近ウォンテッドリーでも似たようなアイデアで研究をしていたので、非常に参考になりました。(論文も公開されていますので興味のある方はぜひ読んでみて下さい)
Distillation Matters: Empowering Sequential Recommenders to Match the Performance of Large Language Models
シーケンシャルレコメンデーションにおいて、LLMを知識蒸留することによって高い性能と推論速度を両立させたモデルを学習できることを示した論文です。ご存知のようにLLMはコンテキストを理解する高い能力を持っており、それを活用することで推薦システムに対しても大きな性能向上をもたらします。しかし、一方で推論速度は比較的低く、多くのユーザー・アイテムペアで推論をしようとすると膨大な時間を必要とするという欠点がありました。
筆者らは、LLMを教師モデルとして、従来のシーケンシャルレコメンデーションモデルに対して知識蒸留を行うという手法を提案してその有効性を示しました。(下図は論文から引用)
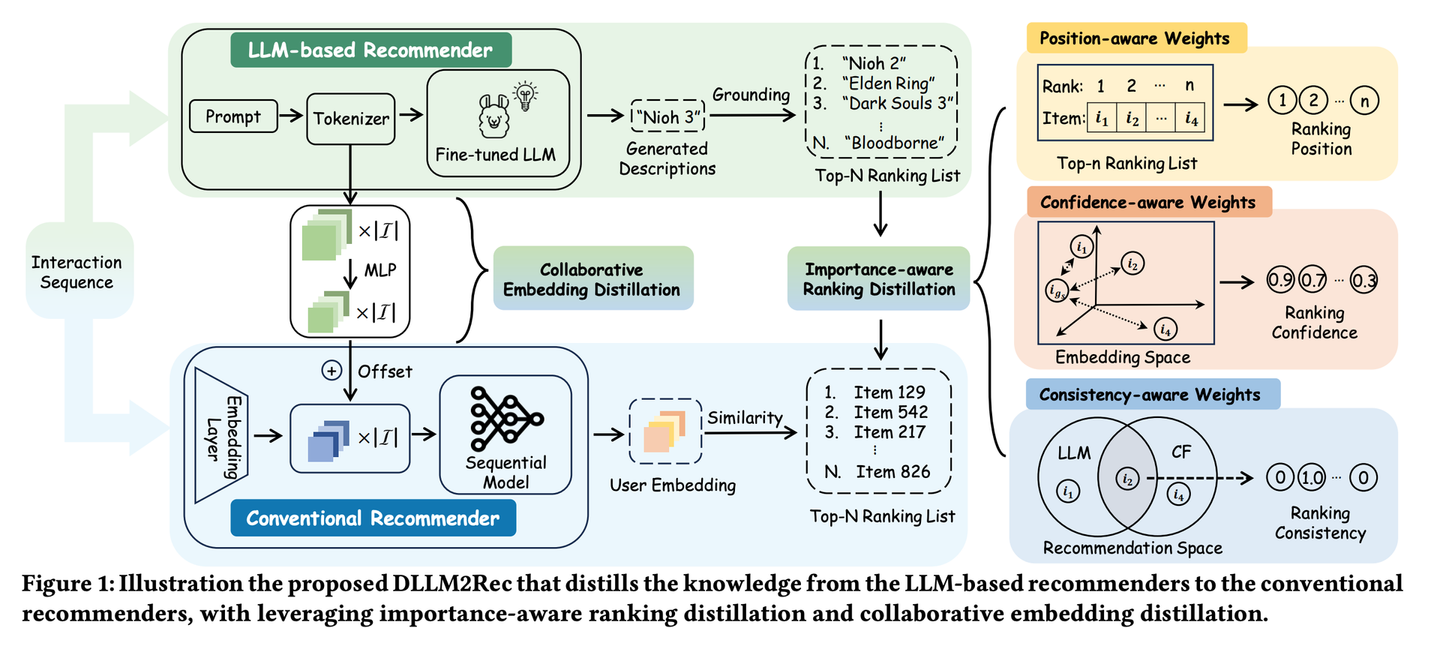
LLM同士での知識蒸留は有名で様々なところで活用されていると思いますが、それ以外のモデル(例えばここではGRU4RecやSASRec)への蒸留は、私の不勉強もあると思いますがあまり聞いたことがなく、これがうまくいくというのは驚きでした。もちろん単純に蒸留するだけでは上手くいかないようで、LLMの出力の信頼度をうまく蒸留時に考慮するなどの工夫も様々凝らされており、非常に勉強になりました。
共により良い推薦システムを突き詰めていく人 Wanted
私たちは「究極の適材適所により、シゴトでココロオドルひとをふやす」というミッションのもと、複数のプロダクトの開発及び運用をしています。非常に複雑な「人」と「シゴト」の関係を紐解き、データと技術を駆使して適材適所の仕組みを作り出す必要があり、これを実現するためには推薦システムという技術の進化が必要不可欠です。
私たちと一緒に、推薦システムという技術活用を促進して究極の適材適所を追求し続けるデータサイエンティスト・機械学習エンジニアの仲間を探しています。少しでも興味を持っていただけたら、以下の募集から「話を聞きに行きたい」ボタンをクリックしてください。カジュアルにお話しできるのをお待ちしております。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


