本記事は「 Wantedly 新卒 Advent Calendar 2021 」の8日目の記事です。
こんにちは! Wantedlyの推薦基盤チームの nasa です。今回は僕が少し前に取り組んだ推薦基盤の設計に起因する課題を解決するプロジェクトについて書いていきます。
背景 まずは、今回の改善対象であるvisit-recommendation-scout(以下vrec-scout)というマイクロサービスについて説明していきます。このマイクロサービスの責務は「ユーザーの検索条件を受け取り、適切なフィルタリング・ソートを行った結果を返す」ことです。
ソート処理では、検索者(ユーザーやその所属企業など)ごとにitemsの並びを決めているランキングと呼んでいる推薦用データを用いて並び替えを行っています。
このランキングはデータサイエンティストが検索者ごとにitemsのスコアを計算し並び順を決めたものです。次の表をイメージするとわかりやすいかもしれません。
vrec-scoutはこの事前に計算されたランキングを使いユーザーにいい感じのitemを返しています。
抱えている課題について ここからはvrec-scoutの抱えている課題について話していきます。
vrec-scoutのフィルタリングとソートはかなりRedisに依存した作りになっておりデータサイズの制限がありました。vrec-scoutのフィルタリング結果やソートに使うランキングはRedisにzset, setといったデータ形式で保持しています。そして、RedisのZINTERSTORE/ZUNIONSTOREのような集合演算命令を用いて最終的にいい感じのitem列を作るという設計でした。
この設計では、すべてのデータが1つのRedisに乗っていること && Redisでサポートされている演算しか行えないといった制約を抱えることになります。
このうちの「データが1つのRedisに乗っていること」という制約のせいでフィルタリング結果やランキングのデータ量に制限がある状態でした。(Redis instanceの最大メモリサイズが400GB?600GB?なのでそこが限界になってしまう)
このデータ量の制限のせいで推薦対象を大量に増やすことが出来なかったり、特定の条件による推薦(特定のユーザーがあるキーワードで検索したとき)などに対応するのが難しかったりと、推薦で出来ることに制限がありました。
この制限をなくすぞ!というのが本プロジェクトのモチベーションになります。
同じ課題をもう一つの推薦サービスでも抱えていた Wantedlyには推薦を行うマイクロサービスは2つあり、1つが先ほど紹介したvrec-scoutで、もう一つvrec-projectというサービスがあります。
vrec-projectも同様にデータサイズの制限がありましたがこれはすでに解消されています。
改善前の処理としては次のような流れでした
filteringを行い結果をRedisに格納 rakingデータは事前に計算されているのですでにRedisに入っている RedisのZINTERSTORE/ZUNIONSTORE命令を使いfiltering結果とrankingの積集合を取り結果をRedisに格納 (この演算はRedis上で行われる。サーバーはRedisにfiltering, rankingデータのkeyを渡すだけ) 最終結果の内、必要な件数だけをRedisから取得する 改善後の流れは次のようになっています。
filtering結果をRedisに格納 rakingデータは事前に計算されているのですでにRedisに入っている filtering結果、rakingデータをともに全件取得しサーバーで並び替えを行う 必要な件数だけ上位から取得する 改善前はRedis上で演算を行っていたのに対して、改善後はRedisにあるzsetを全件取得してサーバー(vrec-project)が並び替えを行っています。つまりRedisから集合演算を剥がすことによりrankingとfiltering結果がRedis上になくても良くなったのです。(例だとRedisにありますが、データストアを自由に選定できるようになった)
「filtering結果、rakingデータをともに全件取得しアプリケーションサーバーで並び替えを行う」
この解決方法をvrec-scoutでもやればええやん!と思ったのですがこの2つのマイクロサービスは扱っているデータ量の違いにより簡単には適応できませんでした。vrec-projectだとitem列は最大でも8万件を扱えればよかったのに対して、vrec-scoutでは20万件扱う必要があります。
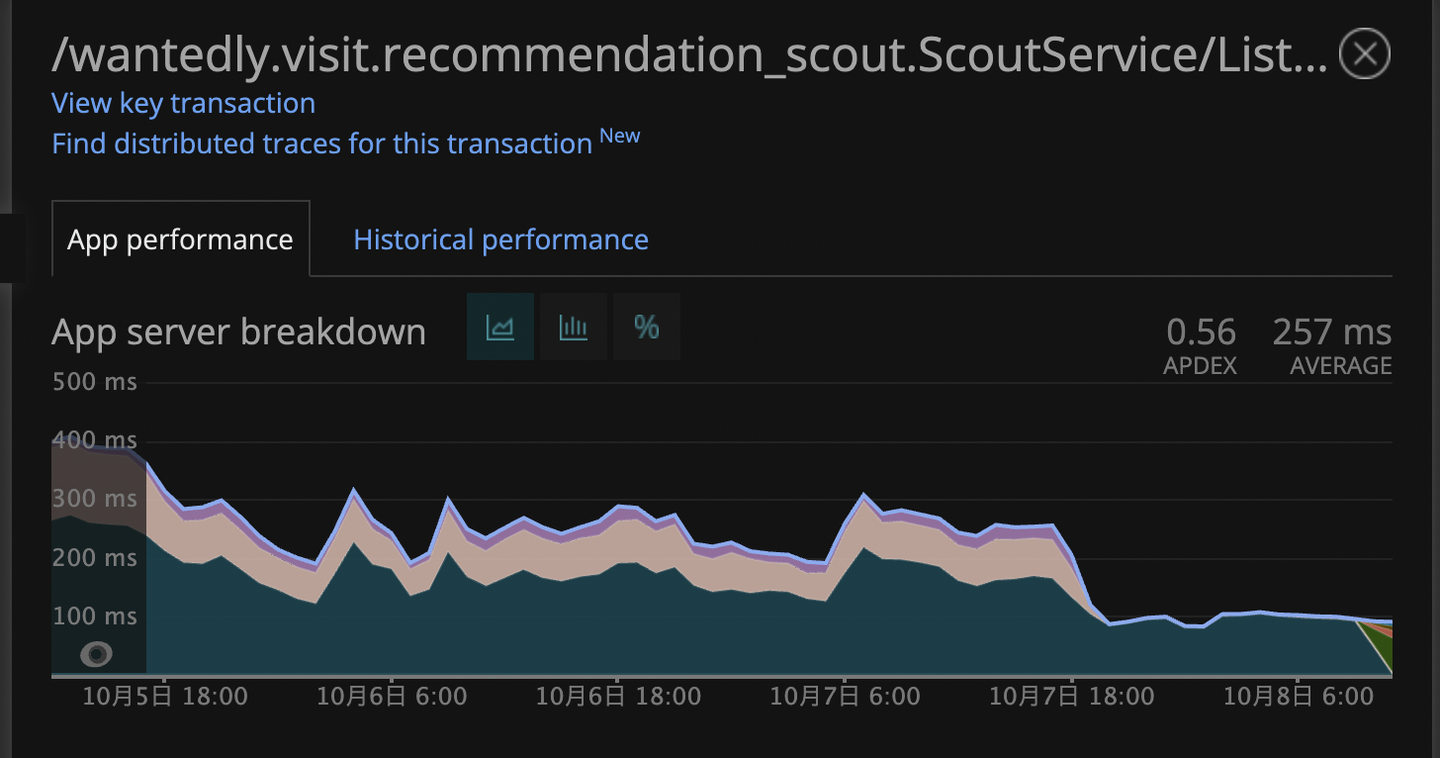
20万件のデータをRedisから全件取得する場合は1,000msほどかかってしまいもともと250msほどだったレスポンスタイムが著しく悪化するという問題がありました。
この「20万件のデータ取得を何とかする」というのが今回の主な戦いになります。
やったこと 次の3つを満たすことをゴールとして改善を行っていきました。
レスポンスタイムは280ms以内とする アプリケーションの振る舞いを変えない、レスポンスタイム目標を達成するために機能を削っての改善は行わない 20万件の取得を行う データ構造を変更しRedisからの全件取得を高速化する試み 元々Redisのデータ構造はzsetをメインで使っていました。zsetを取得するコマンドZREVRANGEを使用して全件取得しようとしていたのですが、 Redisのドキュメント を見ると計算量が O(log(N)+M) となることが分かりました。
O(log(N)+M) with N being the number of elements in the sorted set and M the number of elements returned. これを別のデータ構造を用いることで高速化出来るのでは?と思い計測実験を行ってみました。
20万件のitemを Protocol Buffers 形式でエンコードした結果をRedisにstring形式として保存しGETコマンドで取得を行ってみました。計測の結果50msほどで20万件のitemを取得できることが分かりました。
取得は早くなりましたが、string形式にした場合zsetほどの取り回しの良さはありません。Redisのデータ構造をstring形式に変更することのメリット・デメリットは次のものが考えられます。
メリット 高速な取得 Redisのメモリ使用量を抑えることが出来る デメリット itemsの取得時に個数を指定できないので常に全件取得する必要がある itemを追加・削除するたびに全件取得する必要がある Redisがサポートしている演算処理が使えなくなる デメリットがいくつか出てきますがvrec-scoutのユースケース的には問題が無いものばかりでした。なので、データ構造を変更しRedis上で行っていた集合演算をアプリケーションサーバーで行うことでRedisからの依存を剥がしデータ量の制限を解除することに決めました。
itemsの取得時に個数を指定できない → 全件取得する以外の使い道はないので問題ない itemを追加・削除するたびに全件取得する必要がある → 一度Redisに書き込んだら編集することがない Redisの演算処理が使えなくなる → 頑張って実装する 💪 ここまでのおさらい ここまでの話を一度まとめます。
vrec-scoutの抱えていた問題というのは、推薦に用いるデータサイズに制限があることでした。この制限の要因は次の2つから来ている問題です。
Redis1台あたりのメモリ量には限界があること フィルタリング・ソート時にすべてのデータが1つのRedisに存在しないといけないという設計上の問題 この問題の解決方針としてフィルタリング結果をソートする処理をRedisで行わずアプリケーションサーバで行うことで、「データが1つのRedisに存在しないといけない」という設計上の問題を解消しようと思いました。
アプリケーションサーバでソートを行うためには、フィルタリング結果とソートに用いるランキングをRedisから全件取得する必要があります。このときデータ構造がzsetだと20万件の取得に1000ms以上かかりレスポンスタイムがかなり悪化してしまいます。
この解決としてデータ構造をzsetからstringに変更することで20万件の取得を50msで出来るようになりました。
あと問題として残っているのは、データ構造の変更を適用してvrec-scoutのレスポンスタイムが悪化しないか?280msを保てるのか?というところになります。
ここからはレスポンスタイムを維持するための戦いの話をしていきます。
無限パフォーマンスチューニング編 実際にデータ構造の変更を行い計測を行ったところレスポンスタイムが目標値の280msを大きく上回ってしまいました。
NewRelicによりRedisのSet命令でかなり時間を食っていることが分かりました。ここからはかなり想像が混じっているのですが、Redisがシングルスレッドで動いているためか3MBほどのデータをSetする際に詰まってしまいこれまで高速に動いていたexistsやttlといった命令も遅くなるという状態でした。
この改善方法としては、データをできる限りRedisではなくメモリに置くようにする対応を行いました。(この割り振りは格納したデータを再利用するか、再利用の頻度は高いかによって決めました)
従来の設計では ZUNIONSTORE,ZINTERSTORE とRedisにデータが有る前提だったのに対して、String形式にに変更したあとは集合演算はすべてGoで実装されており、データがどこにあろうと問題ない設計になっています。そのため、Redisに常に保存する必要もないため、再利用しないデータはサーバー上のメモリに置くようにしました。
次のような保存方法を指定できる Storeコンポーネント を実装し再利用の可能性が低いデータに関してはRedisへの保存を行わないように変更しました。itemの取得時はメモリ or Redisのどちらにあるかを区別したくないのでどちらにあっても同じに見えるようなinterfaceにし、保存箇所をうまいこと隠蔽することができました。
// NOTE 読み書きに時間がかかる。外部ストレージに保存する。外部ストレージに障害がない限りデータを永久に保持する
func Persistant() SaveOpt {
...
}
// NOTE 読み書きに時間がかかる。外部ストレージに保存するので指定された時間データが保存されることが保証される
func Expire(t time.Duration) SaveOpt {
...
}
// NOTE 高速な読み書きが出来る。
storeの生存期間しかデータが残らない
func Oneshot() SaveOpt {
...
}
type Store interface {
Save(ctx context.Context, key string, items []Item, opt SaveOpt) error
GetItems(ctx context.Context, key string) ([]Item, error)
} メモリ使用量を減らす この変更によって700msほど改善が見られたもののまだ目標値には届きません。あと90msほど高速化する必要があります。。。 🙈
newrelicからボトルネックがintersection, reorder, unionといった集合演算に移ったことが分かりました。pprofを用いでgoコードの計測を行い、結果mapやsliceのメモリ確保に多くの時間を使っていることが分かりました。
ここの改善を積集合の計算を例にとって話していきます。
Intersection(a, b []Item) []Item {
// XXX ここで時間を食っていた
m := make(map[uint64]struct{}, len(a))
for _, data := range a {
m[data.ID] = struct{}{}
}
// XXX ここで時間を食っていた
ret := make([]Item, 0, len(a))
for _,:= range restItem {
if _, ok := m[data.ID]; !ok {
continue
}
ret = append(ret, data)
}
return ret
} 実装を見るとitem aの長さを元にメモリ確保を行っています。積集合はa, bよりも大きくなることはないので最小限で済むような実装に変更しました。
func Intersection(a, b []Item) []Item {
var minItem, restItem []Item
if len(a) < len(b) {
minItem = a
restItem = b
} else {
minItem = b
restItem = a
}
m := make(map[uint64]struct{}, len(minItem))
...
ret := make([]Item, 0, len(minItem))
...
} 和集合に関しても同じように必要な分量を前もって計算し、メモリ確保の回数が一度で済むように変更を行いました。
func unionItem(a []Item, bs ...[]Item) []Item {
itemsSlice := append(bs, a)
size := 0
for _, items := range itemsSlice {
size += len(items)
}
m := make(map[uint64]Item, size)
...
...
} このようにメモリ確保の回数に気を使って実装を行った結果、無事280msを下回る200msほどでレスポンスを返せるようになりました。データ量が大きくなるとメモリ確保の回数や量に気を使わないと100msくらいなら簡単に遅くなるんですね。。。大きなデータを扱うときや少ないメモリ量での実装を行わないとこういったことの意識は難しそうだなと感じました。
ぬるっと200msを達成してしまったので速度改善はここで終わりです。
結果 ここからはこの設計変更のリリース後にメモリ使用量やレスポンスタイムがどのように変化したかを話してきます。
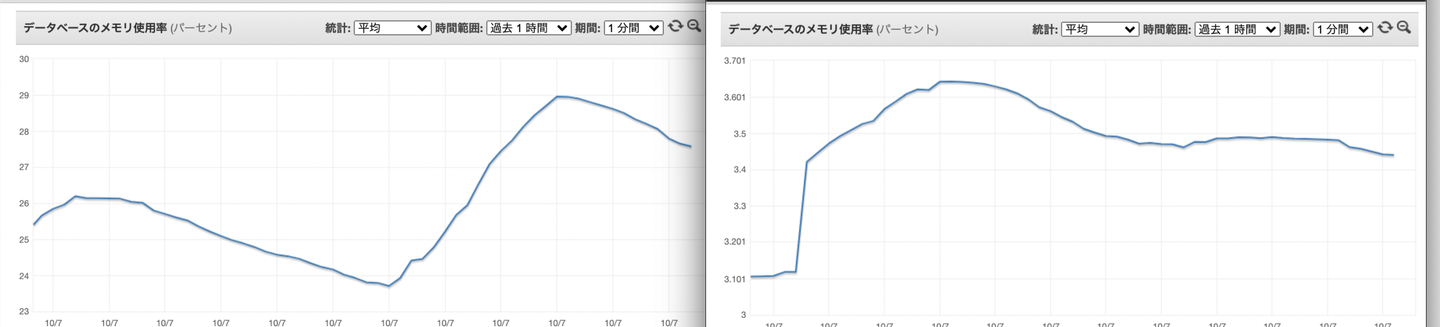
メモリ使用量の変化 左がリリース前で右がリリース後です。(Redisインスタンスがまるっと変わっているため1つのグラフとして表示することができなかったです。。。)
パット見変わっていないように見えるのですが、リリース前はメモリ使用量が27%だったのに対してリリース後は3%とかになっています。だいたい1/9になっていますね。
このRedisインスタンスのメモリは52GBなので14BG → 1.5GBくらいの改善です。パチパチ888
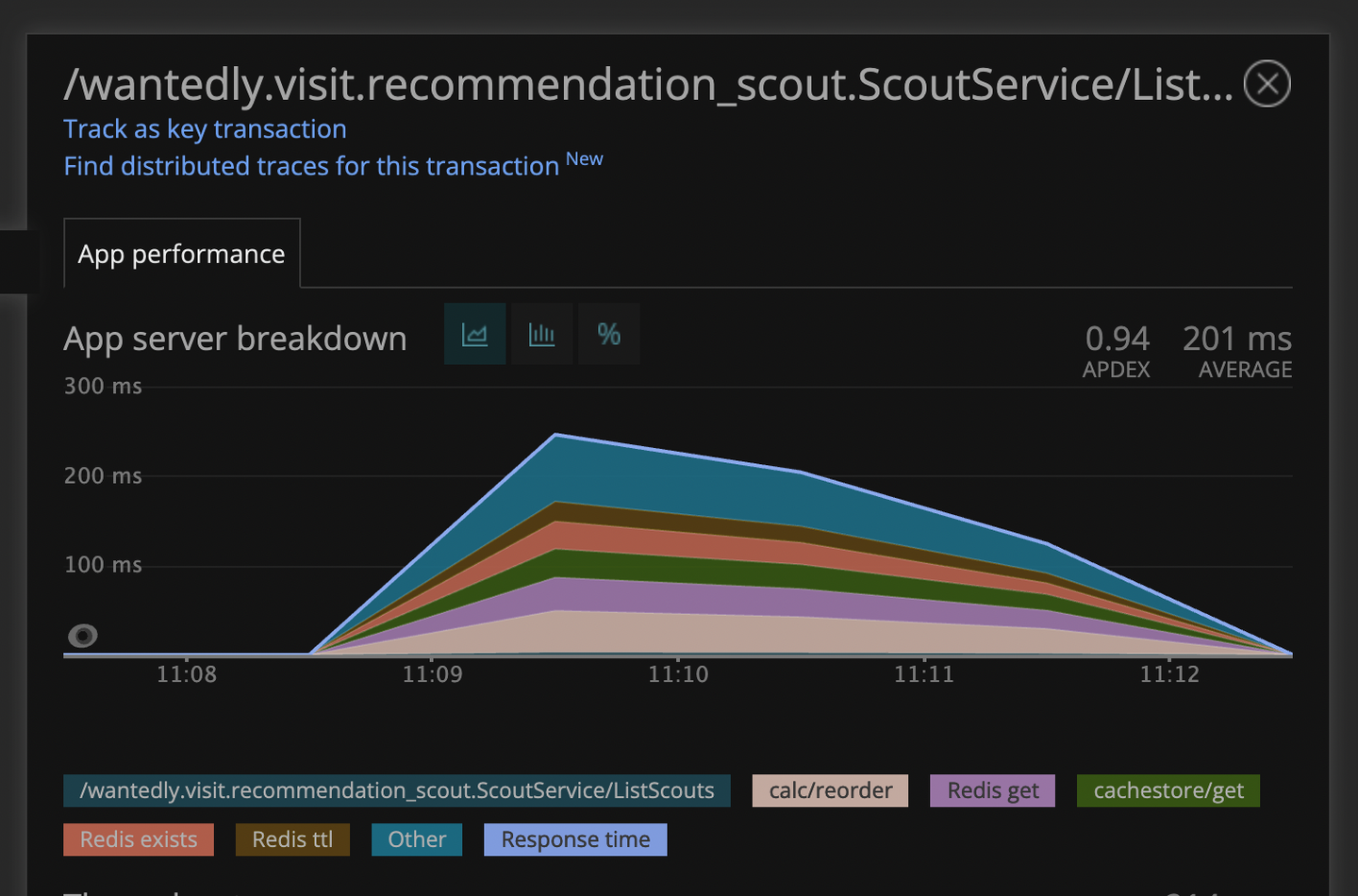
レスポンスタイム レスポンスタイムも明らかに早くなりました。もともと平均が250msとかでしたが現在は平均80msになっています。パチパチ8888
リリース直後だけでなく今も元気に働いてくれています
ここで余談というか失敗話なのですが、速度改善を繰り返す中でベンチマークの並列度を適当に設定した結果本番よりも10倍くらい負荷が高い状態で改善を行っていました。(汗)
目標とするレスポンスタイムはどの程度の負荷状況の時に満たすべきなのかちゃんと考える必要がありますね、、、
まとめ 今回は推薦基盤の抱えたていたデータ量の制限解除の話をしました。
抱えていた課題としては推薦に使用するデータサイズに制限があるせいで実現できることに制限があることでした。これはvrec-scoutがRedisに依存した設計になっていることが要因だったのでこの依存を取り払いました。
Redisの依存を取り払うことでデータサイズの制限を解除しました。このおかげで今後の推薦施策の自由度が増しました。
また副次的な効果もいくつかあり
Redisが用意していない演算も出来るのでこれからの改善の自由度が高まった Redisの仕事が減り詰まる要因が減った。そのおかげで速度が安定するようになった。95, 99パーセンタイルの速度改善が見られた Redisのメモリ使用量が1/9くらいになった。インフラコスト削減 などなどかなりインパクトのある改善となりました。
今後もこのような技術的問題をドシドシ解決していきたいです 💪





/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


