論理レプリケーションを使ってリアルタイムデータ転送を実現する

こんにちは、ウォンテッドリーでインフラエンジニアの巨畠です。本稿では PostgreSQL から BigQuery へのデータ反映時間を2〜3時間から数分へと劇的に短縮したリアルタイム転送基盤「pg-exporter」について解説します 。
注意: 本記事で紹介するリアルタイム転送基盤はリリース前の開発中の機能です。
目次
背景
リアルタイム転送基盤「pg-exporter」の開発
既製ミドルウェアの比較
pg-exporter の概要
課題: バッファリングによってデータが喪失する懸念
解決方法
まとめ
背景
ウォンテッドリーが提供する採用管理システム Wantedly Hire(以下、Hire)には、レポートビルダーと呼ばれる分析機能があります。レポートビルダーは採用活動に関するデータを集計・分析し可視化するための機能です。職種や応募経路など数十種類の項目でのクロス集計、 A is NOT B といった精緻なフィルタリング、ピボットテーブル形式での表示といった柔軟な分析操作が可能です。

レポートビルダーはバックグラウンドで BigQuery を利用しています。ユーザーが構築したフィルタリング条件を SQL に変換して BigQuery に問い合わせています。ユーザーが Hire 上で操作するデータの実体はサービス本体のリレーショナルデータベースである PostgreSQL に存在しており、BigQuery 上にはその PostgreSQL のスナップショット相当を配置して分析クエリを発行する構成を取っています。
この構成における DB / BigQuery の同期は、cronjob でバッチ実行されています。テーブル全体を毎回ダンプして BigQuery にロードし直す方式で、実行には2〜3時間を要していました。バッチ間隔より短い時間で発生した更新は次のバッチまで反映されないため、最大遅延がバッチ間隔と同等になります。即時性が求められるレポートビルダーの要件と、バッチの性質との間にギャップが存在していました。
また Hire 以外にも、「フルダンプ方式によるクラウド間データ転送コストの圧迫」や「インシデント対応や機械学習などで扱うデータのリアルタイム性不足」といった課題を解決することを狙って、リアルタイムにデータ転送を行うための基盤を検討しました。
リアルタイム転送基盤「pg-exporter」の開発
既製ミドルウェアの比較
代表的な選択肢として Debezium と Google Datastream を検討しました。
- Debezium: JVM と Kafka への依存が前提となるが、社内に Java ミドルウェアや Kafka の十分な運用実績がなく、負担が大きい。
- Google Datastream: マネージドサービスである反面、BigQuery 上のテーブル名や構造を調整する自由度が低く、既存システム群との整合が取りづらい。また社内のサービスはすべて Kubernetes クラスタで動作しているが、Google Datastream は Kubernetes クラスタの外で動作する。したがって DB への到達経路とセキュリティ保証が課題になる。
これらの理由から、自分たちのデータ基盤の長期的な発展方向と整合させるには内製化が妥当と判断し、pg-exporter という名前で実装することにしました。
pg-exporter の概要
pg-exporter のゴールは、PostgreSQL の各テーブルを BigQuery 上に結果整合性のある形で再現し続けることです。バッチ処理のように一定間隔でフルダンプを取るのではなく、PostgreSQL に書き込まれたデータ変更をリアルタイムで BigQuery に反映していきます。
pg-exporter のコア技術である論理レプリケーションについても触れておきます。論理レプリケーションとは、データベースの変更内容を Insert、 Update、 Delete といった他のシステムでも理解しやすい共通のメッセージとして抽出して配信する仕組みです。データベースを別の場所に同期させる場合、通常はデータベースの変更内容(WAL; Write-ahead log)をそのままコピーする手法が使われます(ストリーミングレプリケーションと呼ばれます)。しかし、この手法ではコピー先にPostgreSQLを用意しなければデータを読み取ることができません。今回のデータの転送先は、PostgreSQLではなく BigQuery という全く構造の異なるシステムです。そのため、PostgreSQL専用の生のファイルをそのまま送っても、BigQuery側はそれを受け取ることができません。
論理レプリケーションを使えば、PostgreSQL 特有の内部データではなく、「どのデータが、どう変更されたか」という操作のメッセージ(DML; Data Manipulation Language)だけを配信することができます。そのため、相手がBigQueryのような全く別のシステムであっても、データ構造に依存することなく柔軟にデータを連携することが可能になります。
こうして PostgreSQL から抽出されたデータの変更メッセージは、ストリーミングデータとして転送の仲介役となるプログラムである pg-exporter へとリアルタイムに配信されます。pg-exporter は、PostgreSQL の論理レプリケーションを通して絶え間なく流れてくる行の変更情報(DML)を継続的に受け取り、BigQuery 側が効率よく取り込めるようにデータの橋渡しを行います。
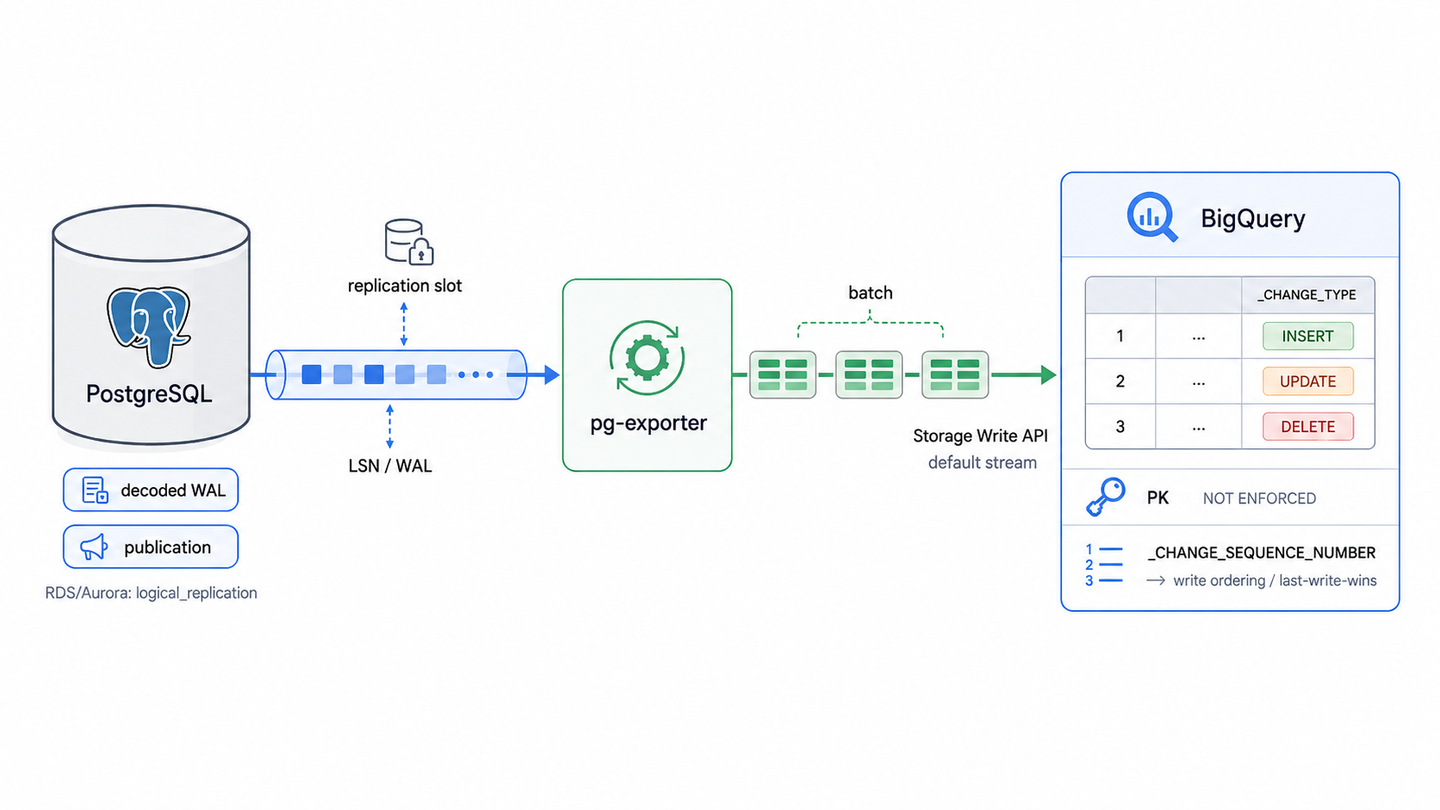
pg-exporter は、受け取った DML をその都度送信するのではなく、メモリ上で一時的にバッファリングし、バッチとしていくつかの DML をまとめて BigQuery へ書き込みます。BigQuery 上でデータベースの変更を正しく適用(CDC; Change Data Capture)するため、BigQuery への書き込み時には以下の仕組みを利用しています。
- 変更の種類の判別 (_CHANGE_TYPE): 書き込むデータに _CHANGE_TYPE という拡張列を付与することで、「追加(INSERT)」「更新(UPSERT)」「削除(DELETE)」のどの操作に該当するかを BigQuery へ伝えます。受け取った BigQuery は拡張列に記載された操作をテーブルに適用します。
- 対象行の特定(プライマリキー): 過去のデータを更新・削除する際、「どの行を変更するか」を正確に特定するため、BigQueryのテーブル側にプライマリキーの設定が必須となります。
- 適用順序の指定 (_CHANGE_SEQUENCE_NUMBER): BigQuery にはデータが書き込まれた順序の概念がありません。そのため、同一行に対して複数の変更が連続して発生した場合でも、_CHANGE_SEQUENCE_NUMBER で順序を管理し、常に最新の変更が正しく反映されるよう制御しています。
課題: バッファリングによってデータが喪失する懸念
pg-exporter の実装を進める中で注意深く扱う必要があったのが、バッファリングに起因するデータ喪失の可能性でした。ここでいうデータ喪失とは、PostgreSQL 側にコミットされた変更が BigQuery 側に反映されないまま、PostgreSQL の WAL からも消えてしまう状況を指します。
pg-exporter では先述の通り、BigQuery への書き込みをバッチ化しています。当初は PostgreSQL から DML を受け取るたびに、その都度 BigQuery へ書き込んで応答を待つ実装も検証しました。しかしこの方式では、リアルタイム転送として期待される「反映まで数分程度」というレイテンシには到底届きませんでした。原因は BigQuery 側にデータを送り込むための Storage Write API の仕組みにあります。この API は AppendRows と呼ばれる呼び出しでデータを送りますが、1 回の呼び出しごとに通信往復のオーバーヘッドがかかり、その時間が全体の処理速度を決めてしまいます。そのため、1 行ごとに 1 回ずつ AppendRows を呼び出していては、単位時間あたりに送れる行数が頭打ちになってしまいます。この制約を回避するために、pg-exporter では複数行をまとめて 1 回の AppendRows で送るバッチ方式を採用しています。
このため pg-exporter は PostgreSQL から受信した DML をプロセス内のメモリにバッファリングし、ある程度まとまった段階で BigQuery に書き出すという実装にしています。言い換えれば、PostgreSQL から受け取り済みだが BigQuery にはまだ書き終えていない DML が、pg-exporter プロセスのメモリ上にのみ存在する状態が発生する可能性があります。
ここで論理レプリケーションのプロトコルが効いてきます。論理レプリケーションでは、配信されるそれぞれの DML に対して LSN(Log Sequence Number)と呼ばれる WAL 内の位置を示す番号が割り当てられます。受信側は処理し終わった LSN を PostgreSQL 側に確認応答として返し、PostgreSQL 側はその位置までの WAL を破棄して良いとマークします。
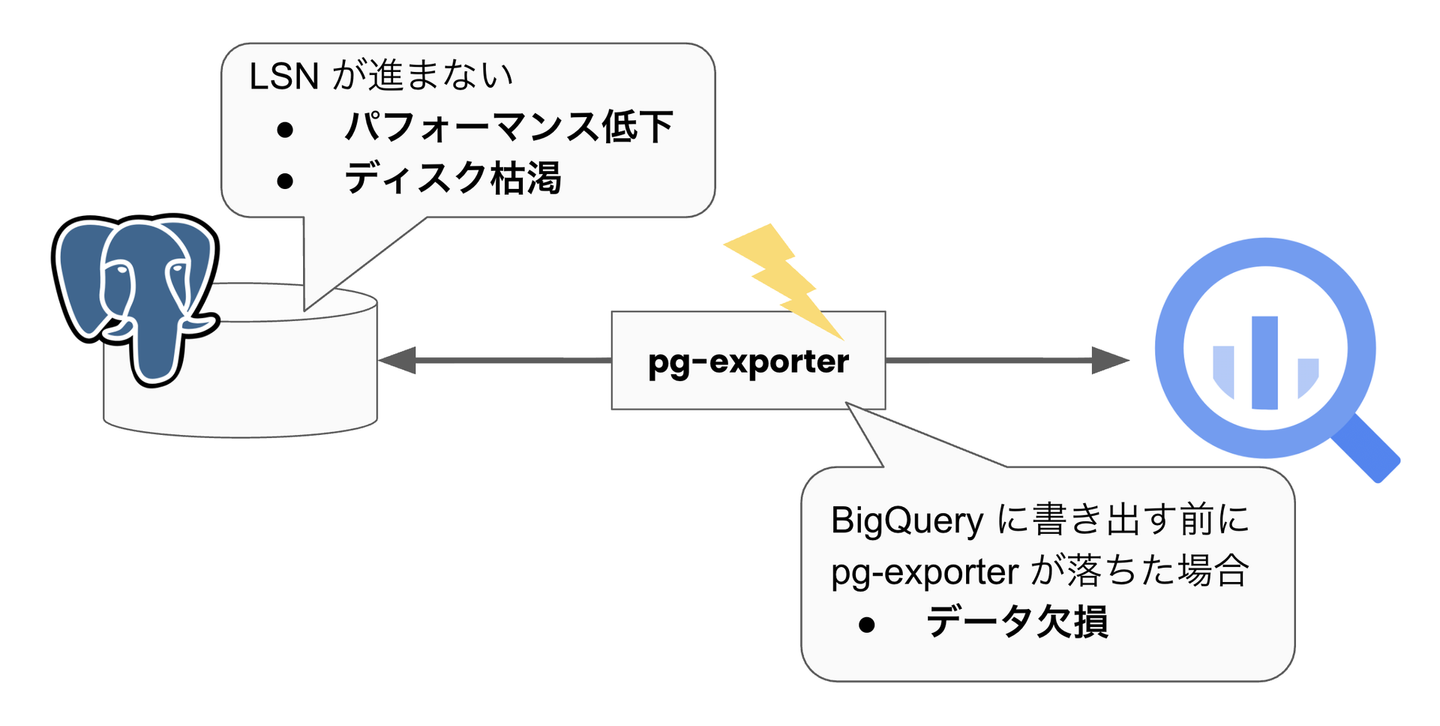
仮に BigQuery への書き込みが完了していないにもかかわらず、受信しただけの段階で LSN を応答してしまうとどうなるでしょうか。PostgreSQL はその LSN 以前の WAL を破棄してよいと判断するため、対応する DML はもはや pg-exporter の再起動時にも再配信されません。この状態で pg-exporter が障害により停止すると、まだ BigQuery に書き込まれていない DML はメモリ上のバッファとともに失われ、PostgreSQL 側にも残っていないため CDC で結果整合を保てなくなります。
一方で、PostgreSQL への応答を意図的に遅らせれば良いというわけでもありません。応答しないままだと PostgreSQL 側に WAL が滞留し続けます。最悪の場合、DB がストレージ枯渇によって停止し、本来のサービスとしての書き込みそのものが止まるといった本体側の障害に発展する恐れがあります。
解決方法
この問題に対する基本的な解決方針は、BigQuery への書き込みが完了したタイミングでのみ、対応する LSN を応答するという原則を徹底することでした。
具体的には、まだ BigQuery への書き込みが完了していない DML の LSN のうち最小のものを PostgreSQL に報告します。すると報告された LSN 未満の WAL は有効ではないとマークされます。LSN 応答前に pg-exporter が停止しても、BigQuery に書き込まれていない DML は PostgreSQL 側に残っているため、再起動後に同じ DML を受信することができます。BigQuery 側は同じ DML が複数回適用されても最終状態は変わりません。
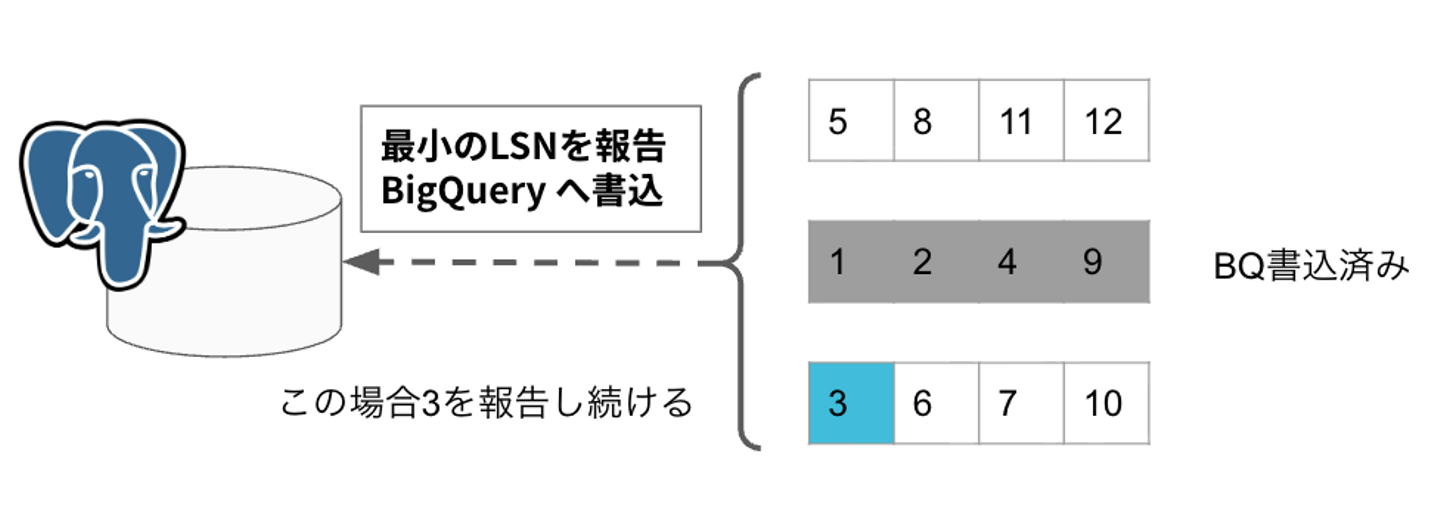
ただし、この方針だけでは PostgreSQL 側で WAL が肥大化するリスクが消えたわけではありません。何らかの異常で pg-exporter が長時間停止した場合や、BigQuery への書き込みが大きく遅延した場合、LSN 応答されない WAL が DB のディスクを圧迫していく構造です。
WAL の肥大化の予兆は、PostgreSQL 上に存在する replication slot の状態を観測することで捉えられます。Replication slot は論理レプリケーションの購読を表すオブジェクトであり、それぞれの Replication slot が「どこまで読まれたか」という状態を保持しています。WAL の保持期間も replication slot の状態に従って決まるため、replication slot の状態を継続的に監視することが運用上重要です。
pg-exporter は関連メトリクスを送信することで監視できるようにしています。PostgreSQL の pg_replication_slots をポーリングして、購読の活性状態、遅延量、実際に保持されている WAL のバイト数、購読の健全性を表すステータスといった値を監視基盤である Datadog に送出しています。遅延量や保持量を見ることで WAL が想定以上に溜まり過ぎていないかどうかを確認しています。
まとめ
pg-exporter の導入により、レポートビルダー向けのデータ反映時間はバッチ ETL 時代の2〜3時間から数分の単位に短縮されました。これによりレポートビルダーでリアルタイムに更新される数値をもとに即時に判断することができるようになります。また、フルダンプを前提にしていた既存の ETL を順次差分転送に置き換えていく道筋ができ、クラウド間データ転送費の削減やデータ活用の幅の拡張といった効果も視野に入ってきています。
確実なデータ連携を実現し、障害時にもデータを守り抜くためには、論理レプリケーションが内部でどのように振る舞うのかといった、データベースの低レイヤーの挙動に踏み込むことが時に必要となります。こうした技術領域に正面から向き合い、堅牢な基盤を自分たちの手で組み上げていく営みこそが、ウォンテッドリーにおけるインフラ開発の実態であり、本記事を通じてその魅力の一端が伝われば幸いです。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


