相互推薦システムを活用したユーザーと企業の双方の嗜好を考慮した推薦 | Wantedly Engineer Blog
こんにちは、ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。ウォンテッドリーでは、テクノロジーの力で人と仕事の適材適所を実現するために推薦システムの...
https://www.wantedly.com/companies/wantedly/post_articles/903172
こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。
この記事では、推薦モデルの一つであるDCN V2を検証してみた事例についてご紹介しようと思います。
推薦モデルをオンラインで動かす
DCN V2
交差特徴量(Feature Cross)の学習
計算効率の向上と低ランク近似による軽量化
実装
実データを用いた簡易評価
まとめ
推薦をサービスに組み込む際にはユーザーにとってストレスのない範囲のレスポンスタイムで推薦結果を応答する必要があります。推論結果を事前計算しておくバッチ推論は、オンラインでの処理はユーザーに対応する推薦結果の読み込みだけで応答することができ、高速にレスポンスすることが可能です。
一方で、事前計算しておけるデータ量にも限界があるため、事前計算するパターンが多い場合などバッチ推論自体が採用できない事も考えられます。具体例としては検索に推薦モデルを適用する場合が考えられます。
Wantedlyでは相互推薦技術を活用しておりユーザー体験に良い影響があることが過去の経験上わかっており、ユーザーの検索時にも相互推薦が活用できればユーザー体験の向上が期待できます。相互推薦の詳細につきましては過去に紹介された記事がありますのでこちらも併せてご覧ください。
しかしながら、ユーザーが入力する検索キーワードについて、考えられうるすべてのパターンに対して推薦結果を事前計算するには組み合わせが大きくなりすぎてしまいます。
バッチ推論ではなくオンラインで推論するようにして精度が高くなったとしても、レスポンスタイムが悪化してしまってはユーザー体験が逆に悪化してしまう可能性があり、この場合には精度と速度を両立させる必要があります。
昨今の推薦技術の研究ではニューラルネットワークを用いた推薦モデルによって高い性能を達成した事例も多く報告されています。一方で先に述べたようにオンラインで推論することを考えると、高い性能を発揮するだけでなく高速に推論できる軽量なモデルであることも重要だと考えられます。今回はCPUでも十分動作する程度の軽量なモデルとしてDCN V2を用いて検証してみます。
DCN V2 は、2020年に発表されたCTR(クリック率)予測やランキングシステム向けのニューラルネットワークモデルです。
論文によれば「ユーザーの年齢」×「コンテンツのカテゴリ」のように、複数の特徴量を掛け合わせた 交差特徴量 (Feature Cross) は予測精度を高める要素だと考えられています。しかし、パターン数の関係上これらを手動で組み合わせて作成するのは限界があります。
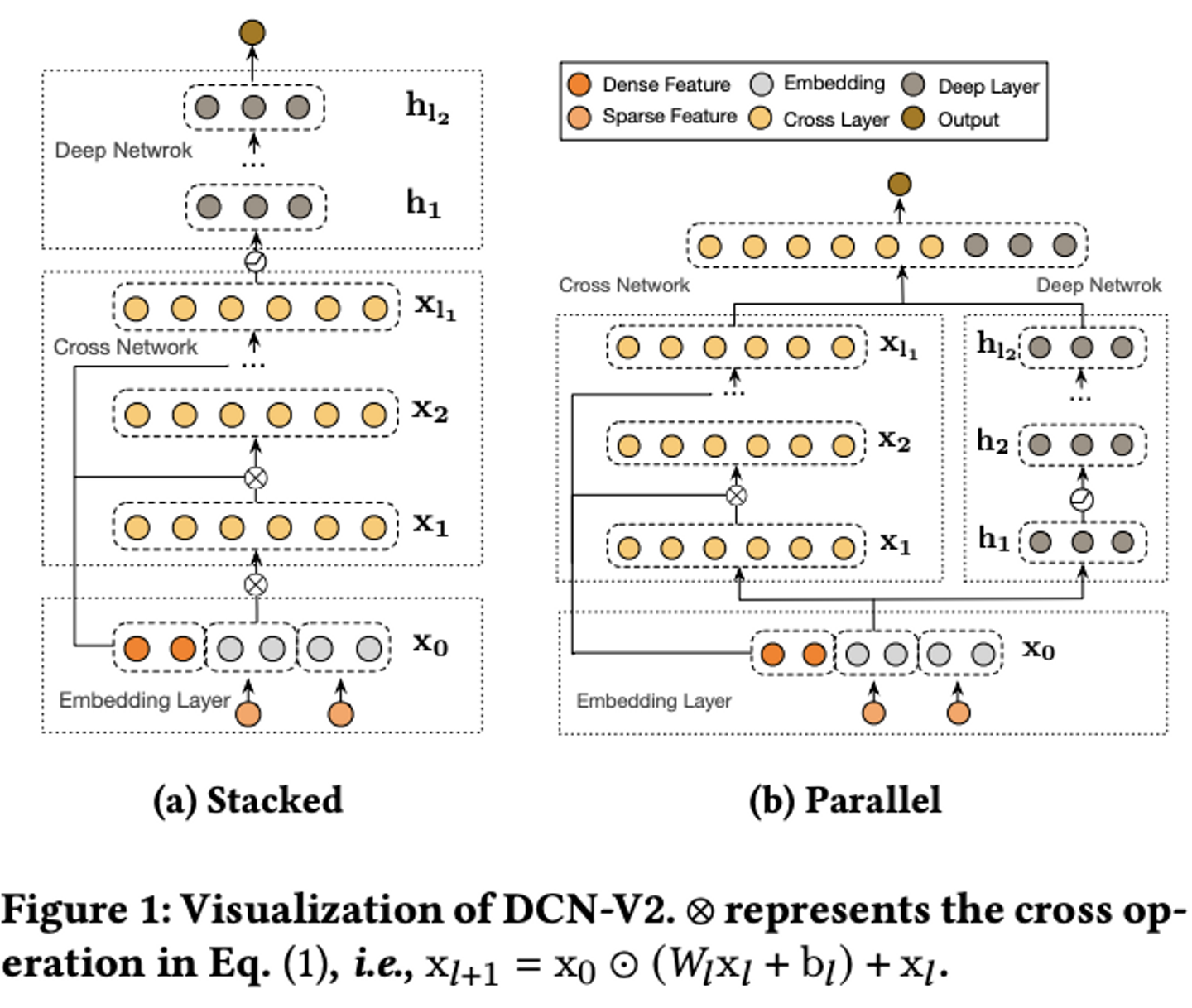
DCN V2では、専用の Cross Network を用いることで、明示的かつ効率的に高次の交差特徴量を扱う特徴があります。
"DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems" より引用
DCN V2全体のアーキテクチャとしては、特徴量交差を専門に行う Cross Network と、非線形な表現を学習する通常の Deep Network を組み合わせる構造になっています。
Cross Networkの内部では行列演算が行われますが、DCN V2では低ランク近似(Low-Rank Matrix Approximation) などのアプローチを組み合わせることで、モデルのパラメータ数と計算量を劇的に削減できる設計になっています。
これにより、高い表現力を維持しながらも軽量・高速に動作することができるといいます。
DCN V2に関する実装についてはTensorFlow Recommendersでの実装があり、Tensorflow実装についてはこちらをご参照ください。
今回はPyTorchで実装したかったため、こちらを参考に実装を進めました。
class DCNv2(BaseModel):
"""Deep & Cross Network v2 (DCNv2) model.
Args:
feature_map (FeatureMap): FeatureMap object containing feature specifications.
model_id (str): Model identifier string. Default: ``"DCNv2"``.
gpu (int): GPU device index, ``-1`` for CPU. Default: ``-1``.
model_structure (str): Model structure, one of ["crossnet_only", "stacked", "parallel", "stacked_parallel"]. Default: ``"parallel"``.
use_low_rank_mixture (bool): Whether to use low-rank mixture cross network. Default: ``False``.
low_rank (int): Low rank for mixture cross network. Default: ``32``.
num_experts (int): Number of experts for mixture cross network. Default: ``4``.
learning_rate (float): Learning rate for optimization. Default: ``1e-3``.
embedding_dim (int): Dimension of feature embeddings. Default: ``10``.
stacked_dnn_hidden_units (list): Hidden units for stacked DNN. Default: ``[]``.
parallel_dnn_hidden_units (list): Hidden units for parallel DNN. Default: ``[]``.
dnn_activations (str): Activation functions for DNN. Default: ``"ReLU"``.
num_cross_layers (int): Number of cross layers. Default: ``3``.
net_dropout (float): Dropout rate for network. Default: ``0``.
batch_norm (bool): Whether to use batch normalization. Default: ``False``.
embedding_regularizer (str or None): Regularizer for embeddings. Default: ``None``.
net_regularizer (str or None): Regularizer for network parameters. Default: ``None``.
**kwargs: Additional keyword arguments.
"""
def __init__(self,
feature_map,
model_id="DCNv2",
gpu=-1,
model_structure="parallel",
use_low_rank_mixture=False,
low_rank=32,
num_experts=4,
learning_rate=1e-3,
embedding_dim=10,
stacked_dnn_hidden_units=[],
parallel_dnn_hidden_units=[],
dnn_activations="ReLU",
num_cross_layers=3,
net_dropout=0,
batch_norm=False,
embedding_regularizer=None,
net_regularizer=None,
**kwargs):
super(DCNv2, self).__init__(feature_map,
model_id=model_id,
gpu=gpu,
embedding_regularizer=embedding_regularizer,
net_regularizer=net_regularizer,
**kwargs)
self.embedding_layer = FeatureEmbedding(feature_map, embedding_dim)
input_dim = feature_map.sum_emb_out_dim()
if use_low_rank_mixture:
self.crossnet = CrossNetMix(input_dim, num_cross_layers, low_rank=low_rank, num_experts=num_experts)
else:
self.crossnet = CrossNetV2(input_dim, num_cross_layers)
self.model_structure = model_structure
assert self.model_structure in ["crossnet_only", "stacked", "parallel", "stacked_parallel"], \
"model_structure={} not supported!".format(self.model_structure)
if self.model_structure in ["stacked", "stacked_parallel"]:
self.stacked_dnn = MLP_Block(input_dim=input_dim,
output_dim=None, # output hidden layer
hidden_units=stacked_dnn_hidden_units,
hidden_activations=dnn_activations,
output_activation=None,
dropout_rates=net_dropout,
batch_norm=batch_norm)
final_dim = stacked_dnn_hidden_units[-1]
if self.model_structure in ["parallel", "stacked_parallel"]:
self.parallel_dnn = MLP_Block(input_dim=input_dim,
output_dim=None, # output hidden layer
hidden_units=parallel_dnn_hidden_units,
hidden_activations=dnn_activations,
output_activation=None,
dropout_rates=net_dropout,
batch_norm=batch_norm)
final_dim = input_dim + parallel_dnn_hidden_units[-1]
if self.model_structure == "stacked_parallel":
final_dim = stacked_dnn_hidden_units[-1] + parallel_dnn_hidden_units[-1]
if self.model_structure == "crossnet_only": # only CrossNet
final_dim = input_dim
self.fc = nn.Linear(final_dim, 1)
self.compile(kwargs["optimizer"], kwargs["loss"], learning_rate)
self.reset_parameters()
self.model_to_device()
def forward(self, inputs):
"""Forward pass of DCNv2.
Args:
inputs: Input data containing features.
Returns:
dict: Dictionary with ``y_pred`` key containing the prediction tensor.
"""
X = self.get_inputs(inputs)
feature_emb = self.embedding_layer(X, flatten_emb=True)
cross_out = self.crossnet(feature_emb)
if self.model_structure == "crossnet_only":
final_out = cross_out
elif self.model_structure == "stacked":
final_out = self.stacked_dnn(cross_out)
elif self.model_structure == "parallel":
dnn_out = self.parallel_dnn(feature_emb)
final_out = torch.cat([cross_out, dnn_out], dim=-1)
elif self.model_structure == "stacked_parallel":
final_out = torch.cat([self.stacked_dnn(cross_out), self.parallel_dnn(feature_emb)], dim=-1)
y_pred = self.fc(final_out)
y_pred = self.output_activation(y_pred)
return_dict = {"y_pred": y_pred}
return return_dictこちらの実装をベースにGoogle Colabのnotebookで動かしてみた実装はこちらになります。
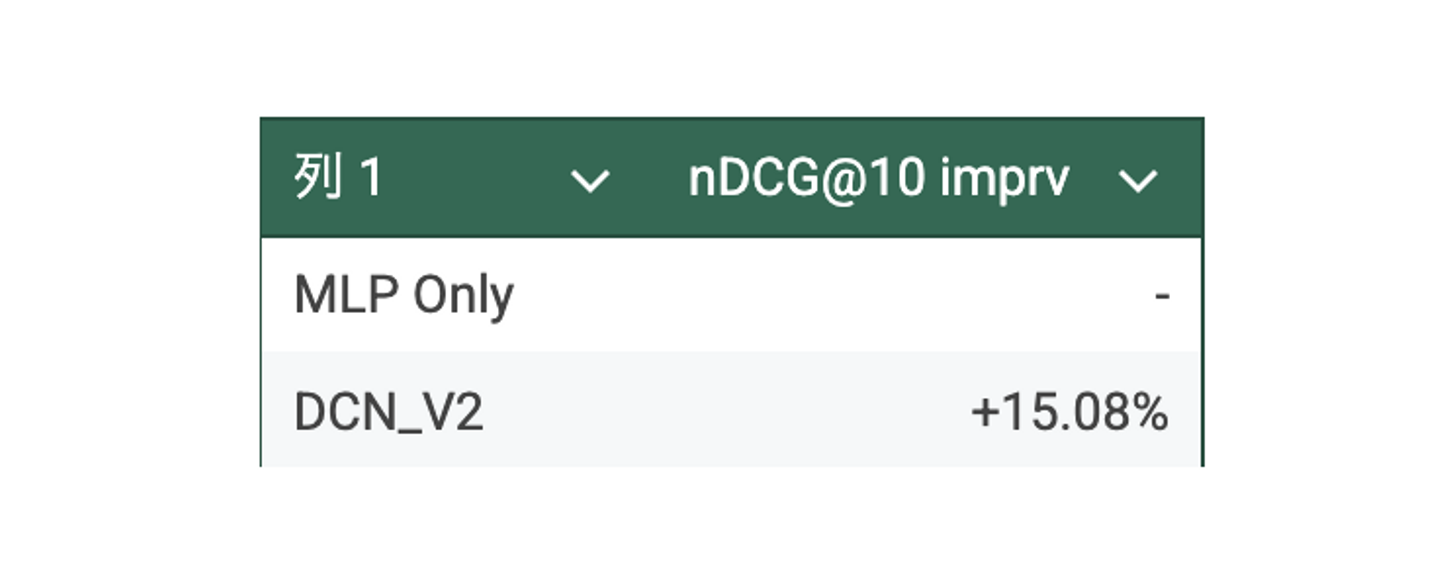
実際のWantedlyの検索に関するログデータを用いて、オフラインでの性能評価を行います。今回はDCN V2 の性能を確認するために、比較対象として単純なMLPのみのニューラルネットワークモデルとします。また、推薦のランキング精度を評価するため、nDCGを指標として使用します。
評価結果 (MLPのみのニューラルネットワークモデルを基準にnDCGの改善率) は以下の表のようになりました。机上評価では単純なDNN単体と比較して、DCN V2は高い精度になっていることが確認できました。
今回はDCN V2を用いたオンライン推論を想定した推薦の検証を行った事例についてご紹介しました。机上評価では単純なMLPモデルよりも高い精度を達成できそうなことが確認できました。今後オンラインで推論するモデルを開発する際には、レスポンスタイムのオーバーヘッド等を確認しつつ、こちらのモデルの利用も検討していこうと思います。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。ユーザーファーストの推薦システムを作ることに興味があるという方は、下の募集の「話を聞きに行きたい」ボタンから気軽に話を聞きに来ていただけるとうれしいです!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
![]()
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)


/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

