
こんにちは。ウォンテッドリーでデータサイエンティストをしている右手 (@ghibney) です。
今回は、LLM を用いたリランキング手法「DOKE」の検証事例を紹介します。
目次
LLM と推薦
DOKE: Knowledge Plugins
基本的なアイデア
プロンプトの構成
実装
評価プロトコル
MovieLens-1M での検証
実験設定
精度比較
速度・コスト
考察
Wantedly 実データでの検証
データ
KG の構築
精度比較
速度・コスト
考察
出力形式の最適化: タイトル出力 vs 番号出力
精度比較
コスト・速度比較
考察
まとめ
主要な知見
今後の展望
LLM と推薦
近年、LLM の汎用的な言語理解能力を推薦システムに活用する研究が活発に行われています。LLM は大量のテキストから学習した知識を持っており、アイテムの説明文やユーザーの行動履歴をテキストとして入力することで、従来の推薦モデルとは異なるアプローチで推薦を行うことができると期待されています。
中でも、既存の推薦モデルで生成された候補リストを LLM でリランキング(再順位付け)するアプローチは、既存のパイプラインと組み合わせやすい手法として注目されています。
LLM を並び替えに活用する方法には大きく 4 つのアプローチがあると言われています。(参考ブログ)
- リストワイズ法: 候補リスト全体を一度に入力し、並び替えた結果を出力させる
- ポイントワイズ法: 各アイテムを独立にスコアリングする
- ペアワイズ法: 2 つのアイテムを比較してどちらが良いかを判定する
- セットワイズ法: 候補の一部(サブセット)をまとめて比較し、局所的な順位や最良要素を決定する
本記事で紹介する DOKE はリストワイズ法を採用しており、番号付けされた候補リストを入力として、LLM にランキングを出力させます。このアプローチには以下の利点があります。
- LLM が持つ知識やテキスト理解能力を活用できる
- 候補数を絞ってから LLM に入力するため、コストを制御しやすい
- 同一プロンプト内で複数候補を同時に比較できるため、文脈を考慮した判断が可能
一方で、リストワイズ法には固有の課題もあります。上記のブログでも指摘されているように、アイテム数が増えると一回の呼び出しあたりのタスクが難しくなり、出力の欠落・重複などのエラーが発生しやすくなります。
さらに推薦特有の課題として、LLM の事前知識が乏しいドメインでは推薦精度が伸びにくい点があります。映画や書籍のように広く知られたアイテムであれば LLM の事前知識を活用できますが、ドメイン固有なアイテムでは LLM 単体の推薦能力は限定的です。
DOKE は、この課題に対して協調フィルタリング (CF) やナレッジグラフ (KG) の情報をプロンプトに注入することで、LLM の推薦精度を高める手法です。また、本記事の後半では、出力形式をアイテム名ではなく候補番号にすることで、パースエラーの抑制やコスト削減にもつながることを示します。
DOKE: Knowledge Plugins
DOKE (Domain-specific Knowledge Plugins) は、LLM の推薦能力を向上させるために、外部知識をプロンプトに注入するフレームワークです。
基本的なアイデア
DOKE では、LLM にリランキングを依頼する際に、以下の情報をプロンプトに含めます。
1. ユーザーの行動履歴: 過去にインタラクション (視聴、購入など) したアイテムのリスト
2. 協調フィルタリング (CF) 情報: 各履歴アイテムに対して、他のユーザーが頻繁に共起させたアイテム (以下、I2I CFと表記)
3. ナレッジグラフ (KG) の推論パス: CF で共起するアイテムペア間の関係を KG 上のパスとして説明するテキスト
これにより、LLM が事前知識を持たないドメインであっても、CF 情報を通じて「似たユーザーが好むアイテム」の手がかりを得ることができ、KG の推論パスによってその関係性の理由を理解できます。
プロンプトの構成
DOKE のプロンプトは以下のような構成になっています。
[ユーザーの行動履歴]
このユーザーが過去に視聴・評価した映画: [0. "The Matrix", 1. "Inception", ...]
[CF 情報]
"The Matrix" を視聴したユーザーは、"Blade Runner", "Minority Report" も視聴する傾向があります。
[知識(属性・関係)]
"The Matrix" と "Blade Runner" はどちらも「Science Fiction」ジャンルに属し、未来社会や人間と機械の関係をテーマとした作品です。
[候補リスト]
リランク対象の候補: [0. "Interstellar", 1. "The Terminator", ...]
[指示]
候補をユーザーが次に視聴する可能性が高い順にランキングしてください実装
今回の検証では、DOKE の OSS 実装 をベースに、AWS Bedrock 上の Claude 4.5 Haiku で動作するように改修しました。
評価プロトコル
論文と同一のプロトコルを採用しました。
- 各テストユーザーに対して、19 件のランダム負例 + 1 件の正解 = 20 候補を構成
- LLM に 20 候補のリランキングを依頼
- NDCG@k, Hit Rate@k 等の指標で評価
評価方法には 2 種類あります。
- TF-IDF タイトルマッチ評価: LLM がアイテムのタイトル (名前) を出力し、TF-IDF による文字列類似度で元のアイテムに名寄せして評価する方法。元論文で採用
- ID ベース評価: LLM が候補番号を出力し、候補リストのインデックスで直接マッピングして評価する方法。名寄せの誤差がないため正確(詳細は「出力形式の最適化」で後述)
MovieLens-1M での検証
まず、論文と同じ MovieLens-1M データセットで DOKE の再現実験を行いました。
実験設定
- データ: MovieLens-1M (ランダムサンプルで取得した 200 人の限定)
- モデル: Claude 4.5 Haiku (Bedrock)
- CF: I2I 共起統計
- 並列数: 5
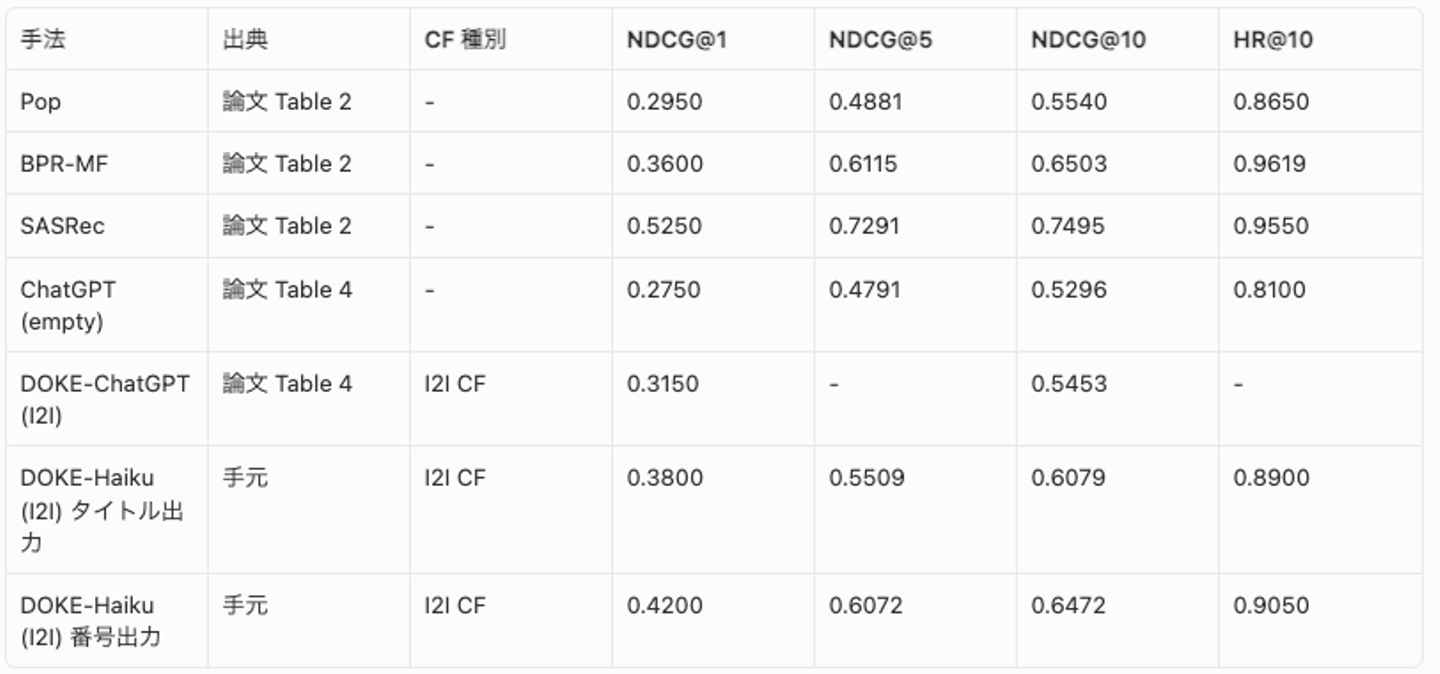
精度比較
古典的な推薦手法との比較結果です。Pop は人気順で推薦する手法です。古典手法と番号出力は ID ベースの評価、タイトル出力は TF-IDF タイトルマッチ評価です(番号出力の詳細は後述)。
速度・コスト

考察
- DOKE-Haiku は DOKE-ChatGPT を上回る: 同じ I2I CF 条件で NDCG@1 は 0.385(本検証)に対し、論文では 0.315 で、Haiku 4.5 が gpt-3.5-turbo の結果を上回っている。モデルの精度向上を考慮すると自然な結果と考えられる
- CF 情報の注入は有効: ChatGPT 単体(論文 Table 4: 0.275)に対し、I2I CF を注入した DOKE-ChatGPT は 0.315 と +15% 改善。DOKE-Haiku でも同様に CF 情報が精度向上に寄与していると考えられる
- 古典手法にはまだ及ばない: SASRec (NDCG@1: 0.525) との差は大きいが、LLM がタイトルベースの TF-IDF 評価を受けている影響もある (後述)
Wantedly 実データでの検証
ML-1M での検証に続き、Wantedly の実データで DOKE が有効かを確認しました。
データ
- 対象: 一定期間のインタラクションデータ
- テストユーザー数: 200 (ランダムサンプリング)
KG の構築
元論文では Wikidata をベースに複数種類のノードを持つ大規模な KG を構築し、ChatGPT で枝切りを行っています。今回は簡易的なアプローチとして、求人ノードと職種カテゴリノードの 2 部グラフから推論パスを構成しました。
例えば、CF で求人 A と求人 B が共起している場合:
"看護師の求人A @ 企業A"
→ 医療
→ "看護師の求人B @ 企業B"精度比較
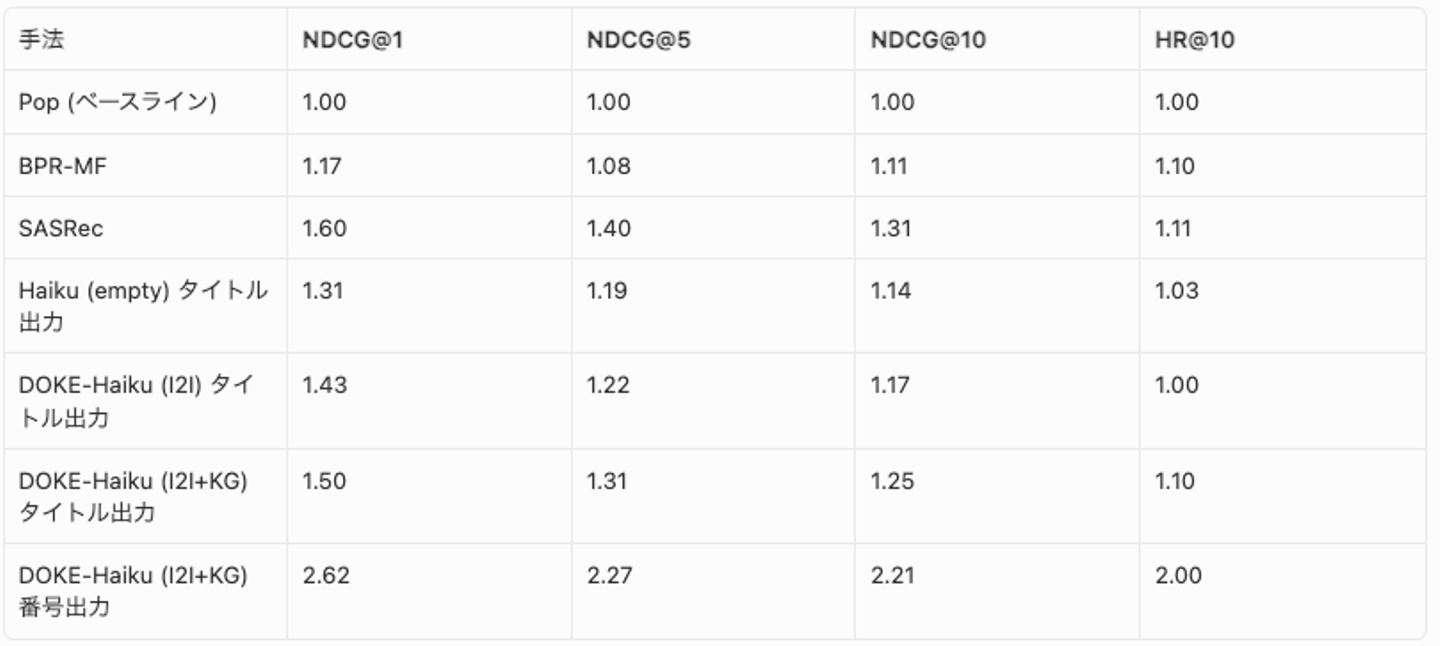
Pop 手法を 1.00 としたときの相対値で比較します。古典手法と番号出力は ID ベースの評価、タイトル出力は TF-IDF タイトルマッチ評価です(番号出力の詳細は後述)。
速度・コスト

考察
- 知識注入の効果は一貫して確認: Haiku 単体 → +I2I → +KG の順に NDCG@1 が Pop 比 +31% → +43% → +50% と段階的に向上。CF 情報と KG 推論パスの追加が推薦精度を改善している
- SASRec が最高精度: NDCG@1 で Pop 比 +60% に対し、DOKE-Haiku (I2I+KG) タイトル出力は +50%。TF-IDF 評価のノイズを受けている可能性がある(後述)
- Haiku 単体でも一定の精度: 求人タイトルから推薦意図を推論できており、空プロンプトでも BPR-MF を上回った (Pop 比 +31% vs +17%)。ML-1M では空プロンプトの ChatGPT が BPR-MF を下回っており(モデルは異なるが)、求人タイトルの方が LLM にとって推薦しやすい可能性がある
- コストは現実的: I2I+KG で $0.0113/ユーザー
出力形式の最適化: タイトル出力 vs 番号出力
ここまでの実験では、LLM にアイテムのタイトル (名前) を出力させ、TF-IDF による文字列類似度で元のアイテムに名寄せしていました。しかし、この方法にはいくつかの課題があります。
- LLM がタイトルを少し言い換えたり省略したりすると、TF-IDF マッチが失敗する
- 出力トークン数が多い (タイトル文字列は長い)
- 日本語タイトルの場合、TF-IDF の精度がさらに低下する可能性がある
これに対して、候補番号 (index) を出力させる方式を検討しました。入力の候補リストにはすでに番号が振られている (`0. "タイトルA"`, `1. "タイトルB"`, ...) ため、LLM に番号のみを返してもらい、候補リストのインデックスで直接マッピングします。
さらに、Bedrock の JSON schema enforcement 機能を利用して、出力を `{"rankings": [3, 1, 2, ...]}` のような整数配列の JSON に制約することで、パースエラーを構造的に排除しました。
精度比較
各データセットの精度比較テーブル(「MovieLens-1M での検証」「Wantedly 実データでの検証」)にタイトル出力と番号出力の両方の結果を掲載しています。そちらを参照してください。
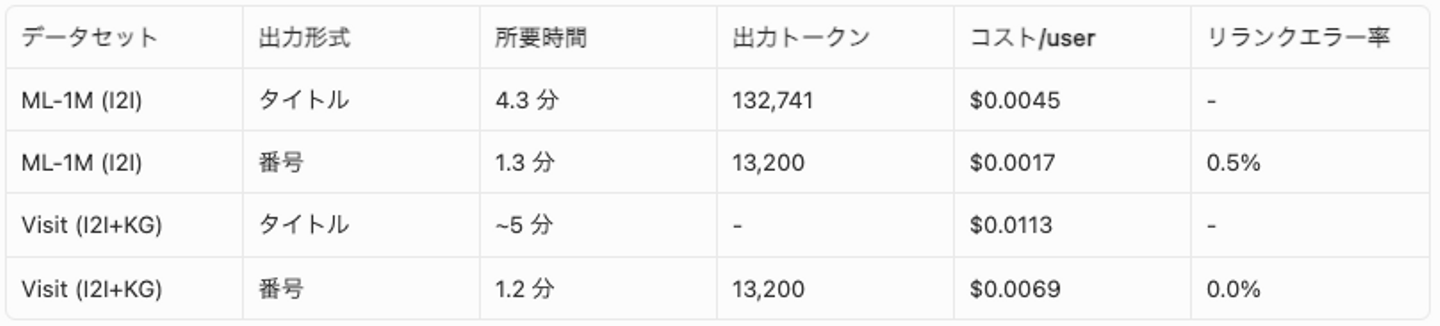
コスト・速度比較
考察
- Wantedly データでは SASRec を上回る: 番号出力により TF-IDF 名寄せのノイズを排除した結果、DOKE-Haiku (I2I+KG) は SASRec を大幅に上回った (Pop 比 +162% vs +60%)。ML-1M では SASRec との差は縮小したものの依然として及ばない (NDCG@1: 0.420 vs 0.525)
- コスト 39-62% 削減: 出力トークンが番号のみ (~13K) となり、コスト全体が大幅に下がる
- 所要時間 72-76% 短縮: 出力トークン削減により生成時間が大幅に短くなる
- リランクの安定化: JSON schema enforcement により出力形式は保証される。残る失敗は候補番号の範囲外や重複といった内容レベルのものだが、ML-1M・Wantedly データともに 0%。タイトル出力では LLM がタイトルを言い換え・省略するリスクがあり、名寄せ失敗の原因となる
番号出力 + JSON schema enforcement は、精度・コスト・速度・安定性のすべての面でタイトル出力を上回る結果となりました。
まとめ
主要な知見
- CF 情報の注入は有効: ML-1M では I2I CF の注入効果を、Wantedly データでは I2I CF に加え KG 推論パスの追加による段階的な精度向上を確認した
- LLM 単体の推薦能力は限定的: ML-1M では CF 情報がない場合、LLM は BPR-MF にも及ばない精度にとどまった。Wantedly データでは求人タイトルの情報量により空プロンプトでも BPR-MF を上回ったが、SASRec には及ばず、CF 情報の注入で精度が向上した
- 番号出力で Wantedly データでは SASRec を超えた: タイトル出力では SASRec に及ばなかったが、番号出力(ID ベース評価)では SASRec を大幅に上回った (Pop 比 +162% vs +60%)。ML-1M では依然として SASRec が優位だが、差は縮小した
- 番号出力 + JSON schema enforcement が最適: タイトル出力に比べてコスト 39-62% 削減、所要時間 72-76% 短縮、リランクエラー率は両データセットで 0%
- コストは現実的: 番号出力の場合、$0.002-0.007/ユーザー程度
今後の展望
今回の事前検証により、DOKE の有効性とコスト面での実現可能性が確認できました。今後は実運用環境 (LightGBM ランキング結果のリランク) での評価や、補助情報の追加 (企業メタデータ、マッチ率シグナルなど) による精度向上を検討しています。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。推薦システムを作ることに興味があるという方は、ぜひ話を聞きに来てください!
/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)


