こんにちは。ウォンテッドリーでデータサイエンティストをしている角川(@nogawanogawa)です。
この記事では、Graph Neural Network(GNN)のアルゴリズムの1つであるLightGCNを用いた推薦候補集合生成について検証してみた事例についてご紹介しようと思います。
目次
LightGCN
モデル定義と学習
候補集合生成
実データでの評価
まとめ
LightGCN
LightGCNはSIGIR 2020で発表されたグラフニューラルネットワークによる推薦の手法です。それまでNeural Graph Collaborative Filtering(NGCF)によってグラフニューラルネットワークが既存の協調フィルタリングと比べて優れた性能を達成すると主張されていましたが、LightGCNではそのNGCFから特徴変換と非線形活性化の処理を取り除いたシンプルな構造ながら性能を向上させています。
![]()
LightGCN: Simplifying and Powering Graph Convolution Network for Recommendationより引用
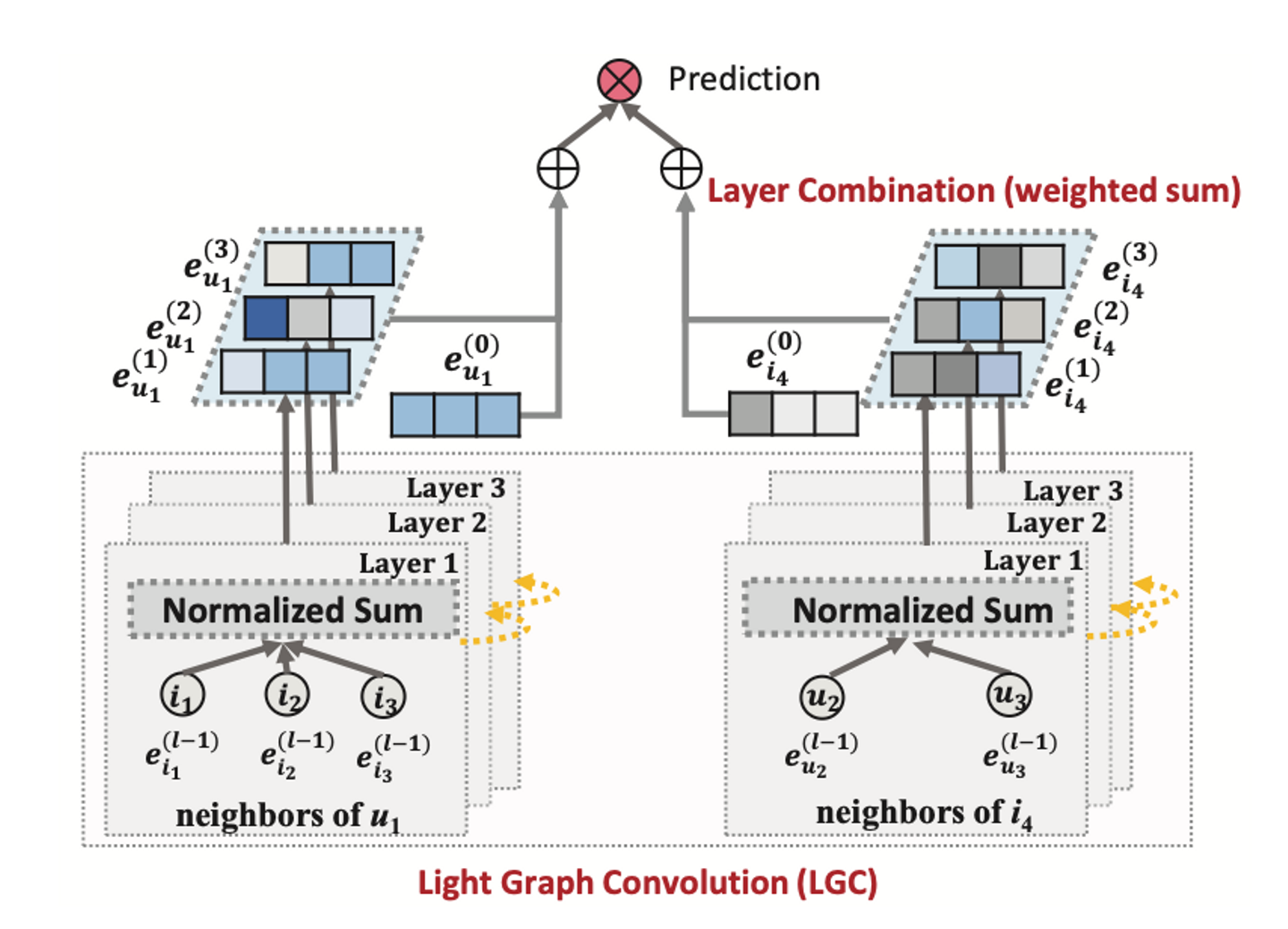
LightGCNでは着目するuserやitemに関して、隣接するnodeについて下記のようなLGC(Light Graph Convolution)を用いて埋め込みの伝播させています。(eは埋め込み、kは何次先のnodeを参照するか、Nは集合に含まれる要素の数を表します)
![]()
LightGCN: Simplifying and Powering Graph Convolution Network for Recommendationより引用
このように伝播させた埋め込みを集約し、着目するnodeの埋め込みを求めます。
![]()
最終的にはuserとitemの間の関係(コンバージョンしたかどうかのラベルなど)を表すラベルを内積によって計算します。
![]()
これに基づいてロスを計算することで、隣接するnodeの関係を考慮して各nodeの埋め込みを学習していく手法になっています。
モデル定義と学習
上記でLightGCNの概要についてご紹介しましたが、PyG (PyTorch Geometric) を用いると非常に簡単に実装が可能で、LightGCNによる推薦については公式の実装例も公開されています。
モデル定義は下記のように非常に簡単に記述することができます。
model = LightGCN(
num_nodes=data.num_nodes,
embedding_dim=64,
num_layers=2,
).to(device)
学習も下記のようにそれほど多くないコード量で記述することができるようになっています。
def train():
total_loss = total_examples = 0
for index in tqdm(train_loader):
pos_edge_label_index = train_edge_label_index[:, index]
neg_edge_label_index = torch.stack([
pos_edge_label_index[0],
torch.randint(num_users, num_users + num_books,
(index.numel(), ), device=device)
], dim=0)
edge_label_index = torch.cat([
pos_edge_label_index,
neg_edge_label_index,
], dim=1)
optimizer.zero_grad()
pos_rank, neg_rank = model(data.edge_index, edge_label_index).chunk(2)
loss = model.recommendation_loss(
pos_rank,
neg_rank,
node_id=edge_label_index.unique(),
)
loss.backward()
optimizer.step()
total_loss += float(loss) * pos_rank.numel()
total_examples += pos_rank.numel()
return total_loss / total_examples
候補集合生成
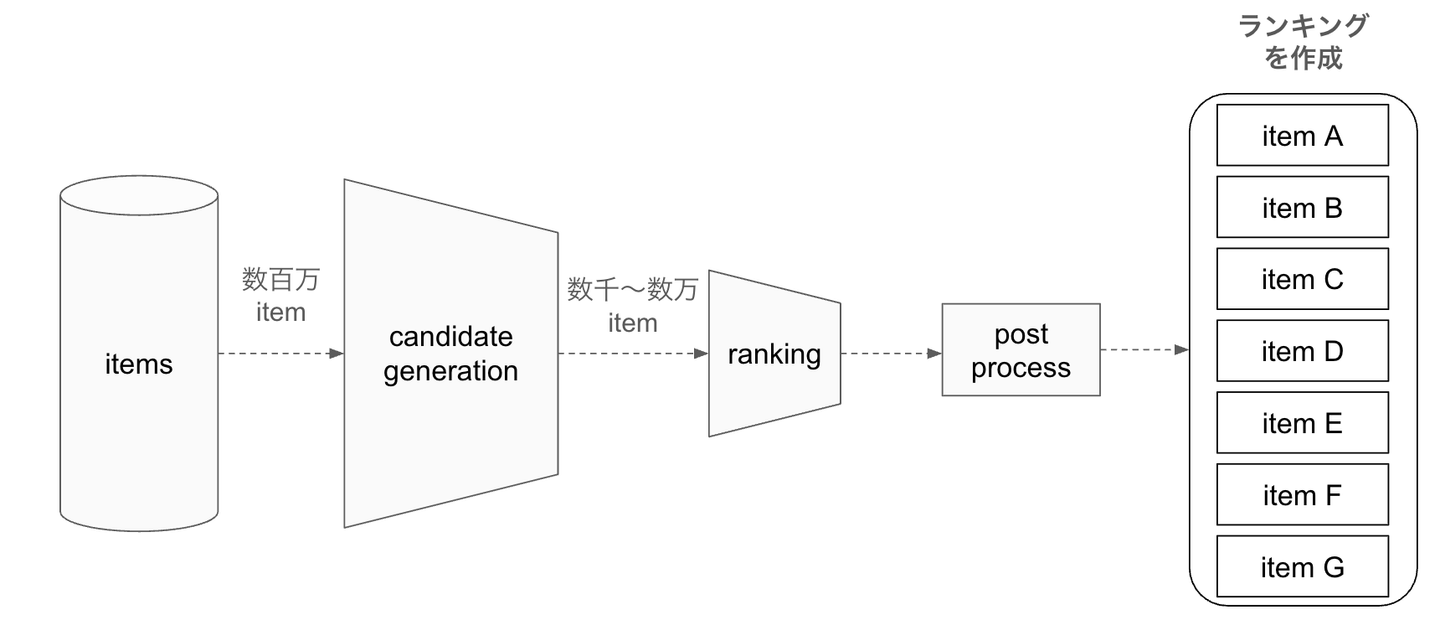
最近の推薦アルゴリズムでは下図のように多段階にフィルタリングを行いながらスコアリング対象を絞っていく推薦の手法が一般的になっており、最終的なスコアリングを行う候補を絞る工程(下図で言うcandidate generation)が設けられていたりします。
![]()
通常、このcandidate generationでは推薦候補となるitem は膨大に存在することが多く、candidate generationのフェーズでは大量のアイテムの中から効率よく絞り込む必要があります。こうした目的のために埋め込みを用いた近似近傍探索が使用されることが多くなっています。
今回のLightGCNでもuser, itemそれぞれの埋め込みを計算しています。userがitemに対してコンバージョンするかの予測は埋め込みの内積によって求めるように学習しているので、userの埋め込みに対して近傍のitemを推薦候補とみなすことで推薦候補集合生成として扱うことが可能です。
学習から候補集合生成までの一連の流れについて、前回作成したデータセットを用いて実装したサンプルノートブックもこちらに公開していますのでご興味ある方がいらっしゃいましたら御覧ください。
実データでの評価
最後に、実際に社内の推薦で実際に使用しているデータセットを使用して、他の協調フィルタリング系のアルゴリズムと性能比較することで、実際に利用できそうか確認してみます。
今回は候補集合生成がテーマなのでRecallで性能評価します。行列分解のRecallを基準にしたとき、LightGCNのRecallの向上率を計算した結果が下記の表の通りになりました。
![]()
単純な行列分解と、特にパラメータ調整もしていないLightGCNでの比較なのでどちらも改善の余地は多々あるとは思いますが、今回の実装では既存の行列分解の手法より若干優れた候補集合が得られており、実データを用いた場合でも性能が向上する可能性があることがわかりました。
まとめ
今回はLightGCNを用いた候補集合生成についてご紹介しました。実際に社内のデータセットを使用して実験してみたところ多少精度が向上しそうなことが確認でき、ここからさらに工夫する余地があるなと感じました。今後どこかで活用できないか検討してみよう思います。
ウォンテッドリーでは、ユーザーにとってより良い推薦を届けるために日々開発を行っています。ユーザーファーストの推薦システムを作ることに興味があるという方は、下の募集の「話を聞きに行きたい」ボタンから気軽に話を聞きに来ていただけるとうれしいです!
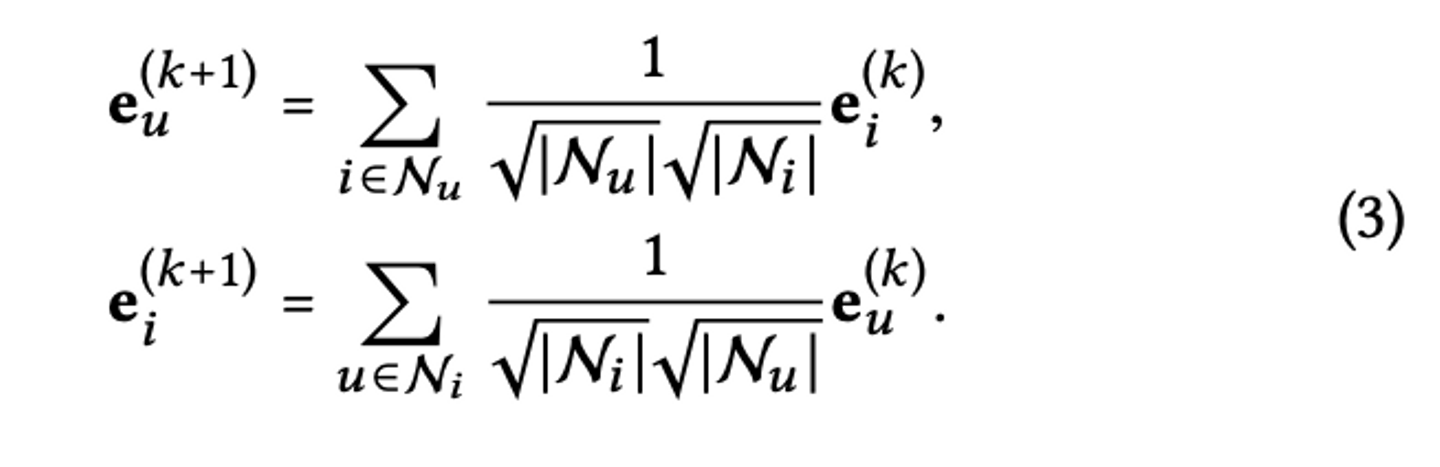
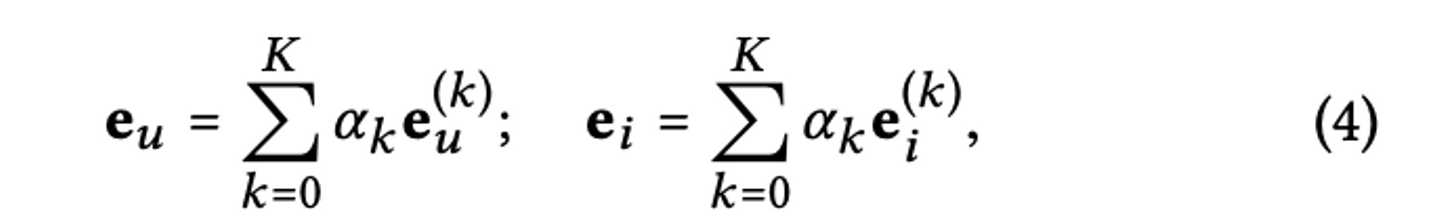
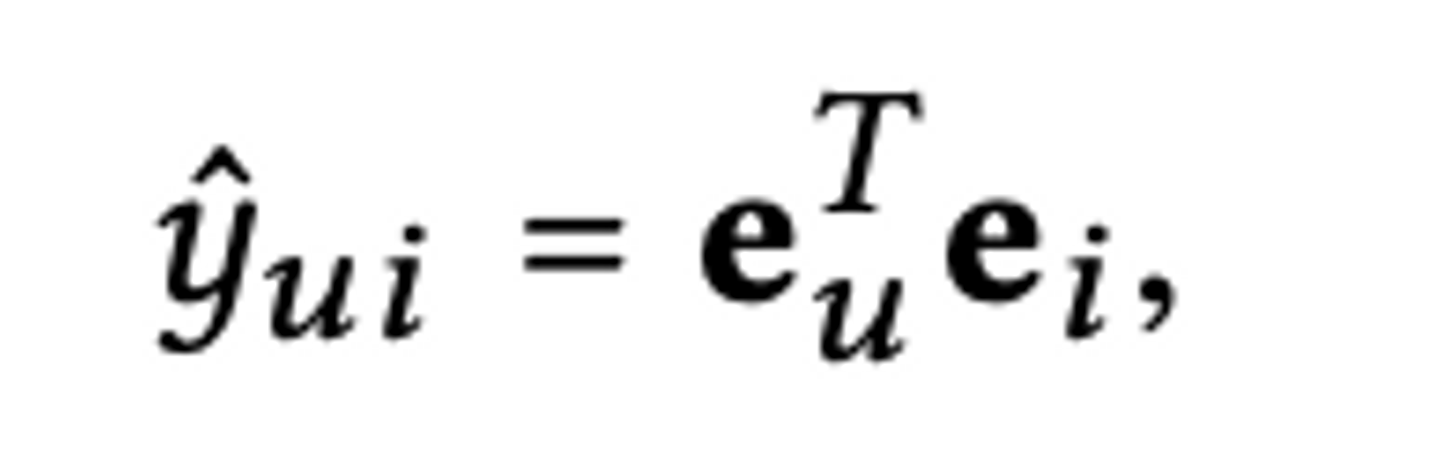

/assets/images/20737273/original/ba3d2c63-f0b7-4bce-899c-fc5d90f59700?1742873917)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

