
MYSQLはRDBMSの一つです、長年発展し、今はOLTP(OnLine Transaction Processing)の場面で最も利用されてるデータベースだと思います!
今回は以下の4つの部分で簡単に共有させていただきます。
- アーキテクチャ
- ログシステム
- トランザクション
- インデックス
アーキテクチャ
MYSQLのアーキテクチャは以下の画像の様になっています。
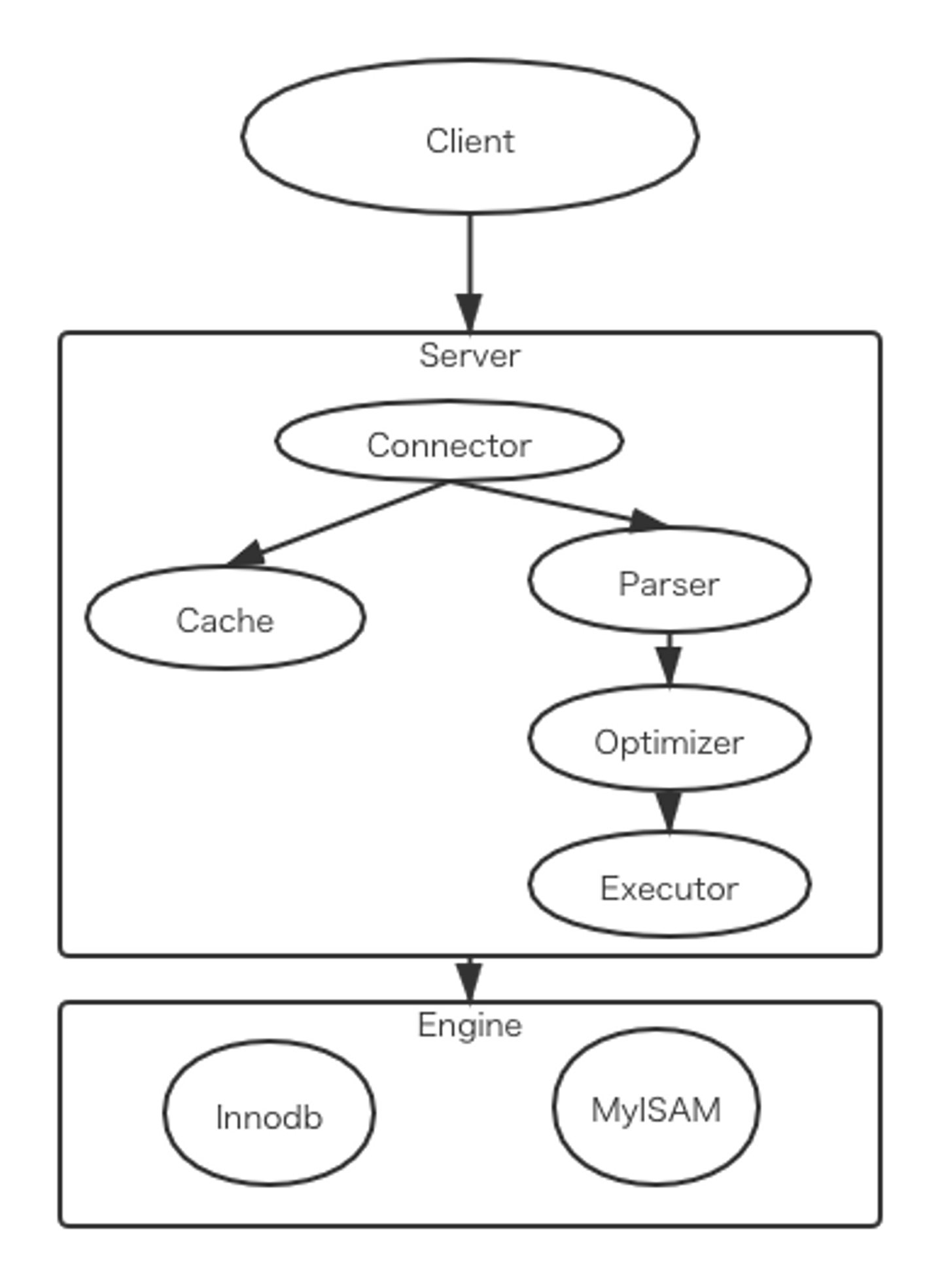
大きく分けると、サーバー層とエンジン層という2つ層があります。
サーバー層には、connector、parser、optimizerとexecutorなどで構成されて、多くのコア機能と組み込み関数がこの層で実装されてます。
エンジン層には、データの保存と取得の機能が実装されてます。プラグインの形で、MyISAM、InnoDB、Memoryなどのエンジンを利用可能です。今は最も利用されてるエンジンはInnoDBです。
- Connector
mysql -h $ip -P $port -u $user -pMYSQLを利用する時、インストールした後で最初の接続コマンドこうなっていますね。
mysqlコマンドはクライアントツールで、TCPの3ウェイハンドシェークをしてサーバと接続します。Connectorはこのコネクションを管理してます。show processlistコマンドで接続のコネクションを確認することができます。
接続した後何もしないと、Commandカラムがsleepになって、一定期間の後で自動的にクローズされてしまいますので、この時Queryを実行すると、Lost connection to MySQL server during queryというエラーが出てきて、再接続が必要になります。この期間のデフォルト値が8時間であり、wait_timeoutパラメータで設定できます。
2. Parser
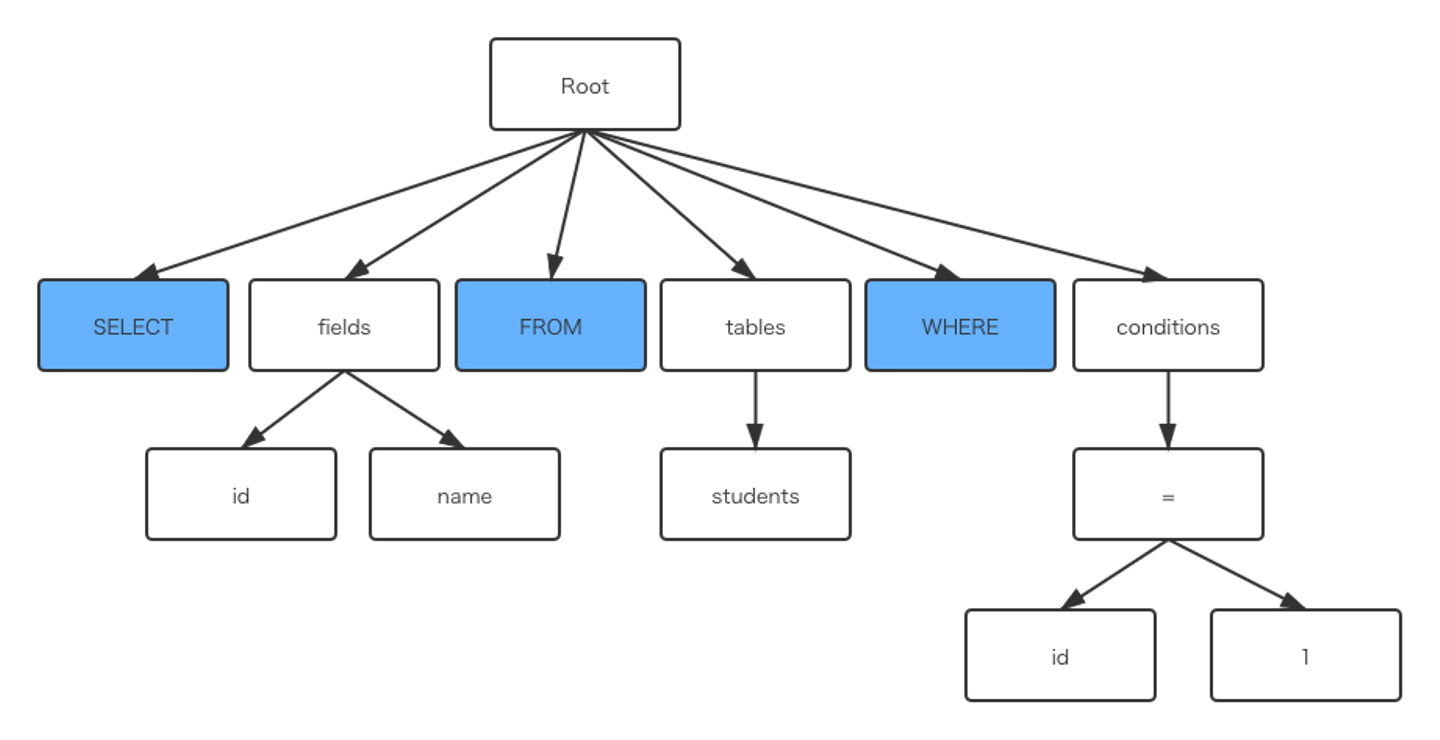
Parserはクエリーコマンドを実行する時、まずコマンドを解析します。
最初は字句解析で、select、カラムというTokenを解析し、この後構文解析を行います。
もし、コマンドを間違ってしまうと、You have an error in your SQL syntaxというエラーが出てきます。 解析したコマンドは以下の様に構造化されます。
3. Optimizer
Parserを通して、どんなコマンドを実行するかをすでに理解しましたが、実行する前にMySQL は実行可能な最適なクエリー計画を計算します。例えば、複数のインデックス存在する時、どんなインデックスを利用するのか、joinの時どんな順序でjoinするのかを決定します。
コマンドのクエリー計画を確認したい時に、以下のように、コマンドの前にexplainを付けるとみえます。
explain select * from xxx where id = 14. executor
最後についに実行します!
executorはエンジンのインタフェースを利用して、コマンドを実行します。
select * from T where C = 20;こういうコマンドを実行すると、以下のように実行します。(InnoDBを利用する)
- InnoDBでテーブルの第一行を取得し、Cが20かを判断します。20でしたら、ResultSetに保存して、そうではないならスキップします。
- 次の行のデータを取得し、1のロジックを最後まで繰り返します。
- ResultSetをリスポンスとして返します。
インデックスがあるテーブルも大体同じようなロジックで実行します。
ログシステム
SQLコマンドを実行する時、redo logとbinlogという2つ重要なログがあります。
redo log
たくさんのデータの中で一つのデータを更新したい時、このデータを検索して更新する必要がありますね。毎回これを実行するとIOのコストが高すぎるため、redo logが設計されました。
まずredo logに操作を記録して、メモリーを更新します。その後、システムが空いている時にフラッシュします。これも一つよく使われる設計で、WAL(Write-Ahead Logging)というものがあります。
redo logのサイズは固定サイズで、設定できます。残りサイズが足りない時、前からログを上書きします。この時、データをディスクにフラッシュします。
redo logがあると、DBに異常があり、 再起動をするときも、アップデートしたデータを修復できます。この能力はcrash-safeと言われます。再起動をする時、redo logの内容を確認してデータを修復します。
binlog
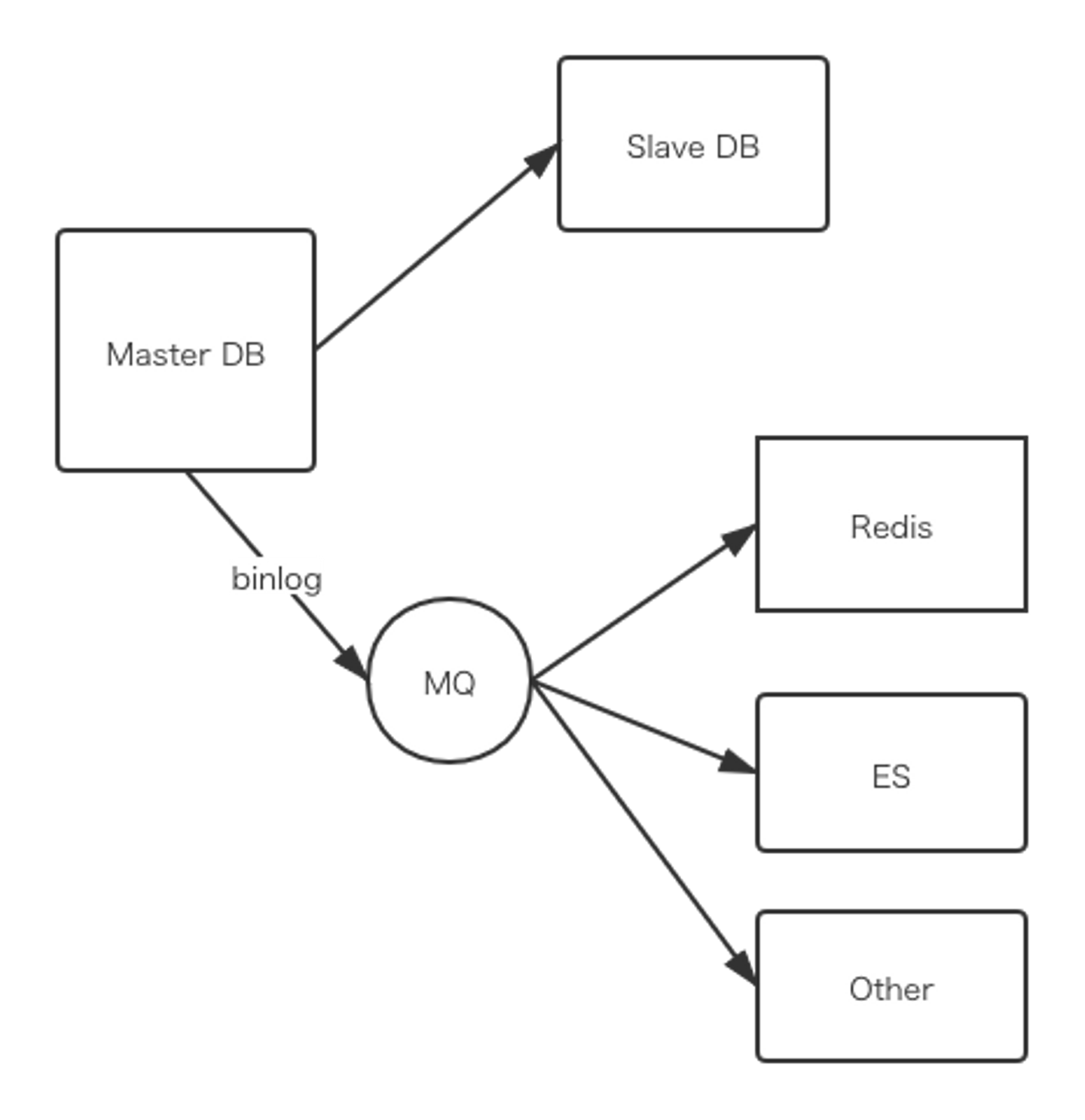
redo logはInnoDBエンジンのログとして、binlogはserver層のログです。InnoDBエンジンが出る前に、mysqlはMyISAMエンジンをデフォルトで利用していました。
binlogにどんなコマンド実行しましたをappendの方式で記録し、Slaveインスタンスにデータを同期したり、RedisとESなどにデータを同期したりする時、よく利用されています!
トランザクション
トランザクションといえば、ACIDを思い出しますね。マルチトランザクションを実行すると、以下の問題が起こります。
- Dirty Read
- Non-Repeatable Read
- Phantom Read
トランザクションにはREAD UNCOMMITED、READ COMMITED、REPEATABLE READとSERIALIZABLEという4つの分離レベルがあります。
- READ UNCOMMITED: コミットされていない変更を他のトランザクションから参照できる設定です。
- READ COMMITED: コミットされた変更を他のトランザクションから参照できる設定です。
- REPEATABLE READ: 同じトランザクション内の一貫性読み取りはすべて、最初の読み取りによって確立されたスナップショットを読み取ります。
- SERIALIZABLE: 一つ一つトランザクションを順番で実行する設定です。
Reference: https://dev.mysql.com/doc/refman/5.6/ja/set-transaction.html
分離レベルで解決できる問題以下の表となります。
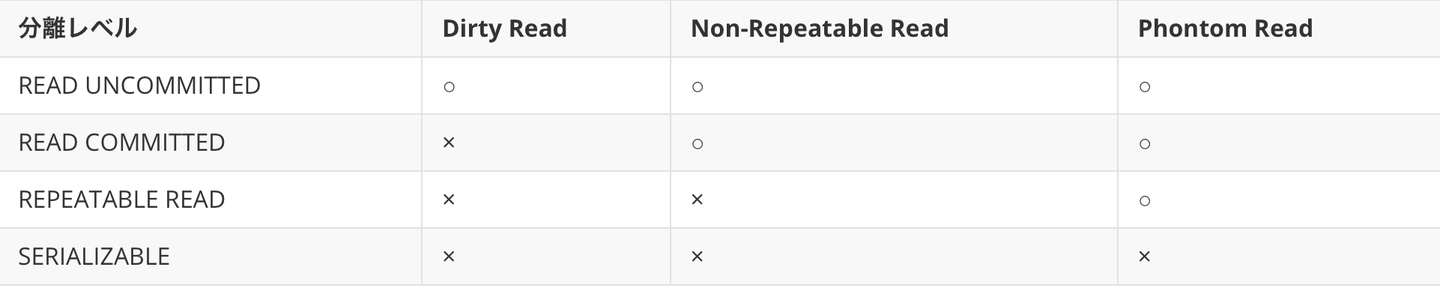
○: 発生する x:発生しない
実装原理
Repeatable ReadレベルでMVCCを説明します。
データをアップデートする時、undo logに前のデータにロールバックする操作が記録されています、最新のデータをロールバックして前のデータを取得できます。
1から4まで更新すると、以下のundo logがあります。(A, B, Cのトランザクションは、同データを取得するだけの処理になります。)
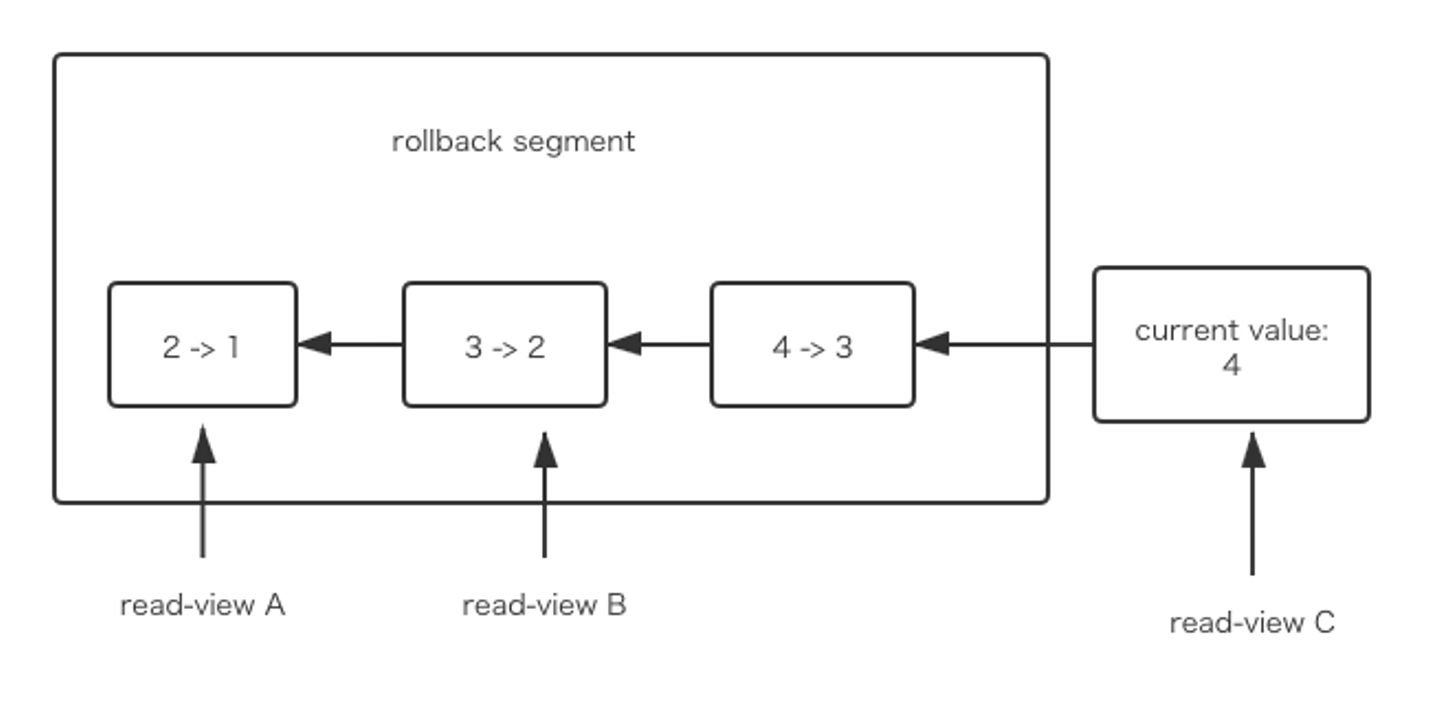
トランザクションを開始する時、この時のread-viewのデータの値を取得します。read-view Aの値が1、read-view Bの値が2です。同じデータの複数バージョンが存在している機能を、MVCC(MultiVersion Concurrency Control)と言われています。read-view Aの値を取得するのは、今の値4からread-view Aまでのロールバック実行して計算されます。
システムにundo logより古いread-viewがない時、そのログを削除します。
以上より、長いトランザクションをなるべく避けようとします。長いトランザクションがあると、古いread-viewがずっと存在していて、rollback segmentがずっと溜まってしまいます。
インデックス
インデックスはよく利用されていて、とても重要な概念です。
クエリーの効率を向上するため、インデックスが設計されました。
インデックスのデータ構造
いろんな構造がありますが、ここでは普段よく使われる構造を挙げます。
Hash Tableはkey-valueのDBにはよく使われて、特定のキーを元に探索する場合にはとても有効な構造です。
Binary Search Treeもイコールの範囲の探索もできますが、データをディスクに保存したり取得したりしますので、普通はm-ary treeを使います。Binary Search Treeを使うと、ツリーが深くなって、IOの回数が増えてしまいます。
InnoDBのすべてのテーブルのデータはIDでインデックスの形で保存されています。B+ Treeを使っており、データはすべてB+ Treeに保存されていることです。
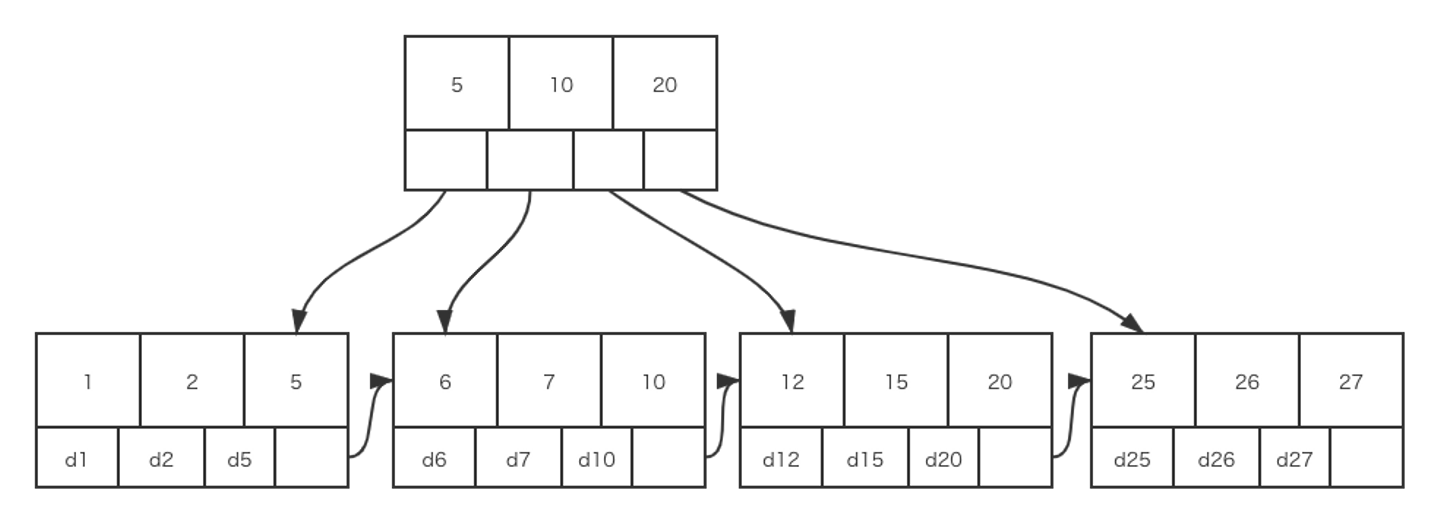
Leaf Nodeの内容によってインデックスがprimary keyとkeyという2種類のインデックスがあります。
- primary keyのLeaf Nodeの内容はこの行のデータです。InnoDBでは、primary keyがClustered Indexとも言われます。
- keyのLeaf Nodeの内容はIDの値です。InnoDBでは、keyがSecondary Indexとも言われます。
例えば、テーブルTにIDがClustered Indexで、COLがSecondary Indexです。以下の2つのクエリーを実行するとどんな違いがありますか?
1. select * from T where ID = 10
2. select * from T where COL = 10- 1のクエリーでは、IDのB+ Treeを探索すれば、データを取得できます。
- 2のクエリーでは、まずCOLのB+ Treeを探索してIDを取得します。その後、IDのB+ Treeを探索してデータを取得します。
インデックスのメンテナンス
インデックスの順序性を守るため、新しいデータを登録する時、B+ Treeの調整が必要です。インデックスにインサートする時、その場所のデータを後ろにずらしたり、新しいページを申請したりする必要があります。もしデータを後ろのページにずらす時、後ろのページがすでに空いているところがないと、Page Splittingが発生します。
以上より、IDをAuto Incrementにするのはデータを移動したり、Page Splittingしたりするのは抑えますので、おすすめです。
OLAP
インターネットの発展により、データ量が爆発的に増加しています。そのデータに対して集計や複雑で分析のクエリー、結果を素早く抽出することが必要です。MYSQLというRDBMSには、この場合に向いていないため、OLAP向けのDBが段々出てきました。
一般的には、OLAP向けのDBはRow orientedよりColumn oriented のデータ構造を使っています。BI用のシステムを作る場合は、そちらのDBも検討しましょう!

/assets/images/4144660/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1569914911)



/assets/images/6571325/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1618570231)


