
人材紹介を、はたらく人の"インフラ"に。Groovesがこの領域に挑む理由 | 株式会社Grooves
今回は、執行役員としてVPoP/VPoDを担当している、ますぶちより、私たちが「人材紹介」という領域に本気で向き合う理由と、それを通じて実現したい未来についてお話ししたいと思います。働くことは、...
https://www.wantedly.com/companies/grooves/post_articles/979413
今回は、執行役員としてVPoP/VPoDを担当している、ますぶちより、当社のプロダクト「Crowd Agent(クラウドエージェント)」で実際に取り組んだAI活用プロジェクトを通して、UX設計の考え方や再現性のある学びを紹介したいと思います!
こんにちは、Groovesで執行役員(VPoP/VPoD)を担当している、ますぶちです。生成AIの進化は早いですね!特に「AIをどう使うか」ではなく、「ユーザーにとって自然な体験とは何か」を起点に設計する重要性を日々感じています。
クラウドエージェントは、人材紹介の可能性を最大化することで「はたらく人と会社」がより良い形で出会うきっかけを生み出すためのサービスです。
なにをしたのか
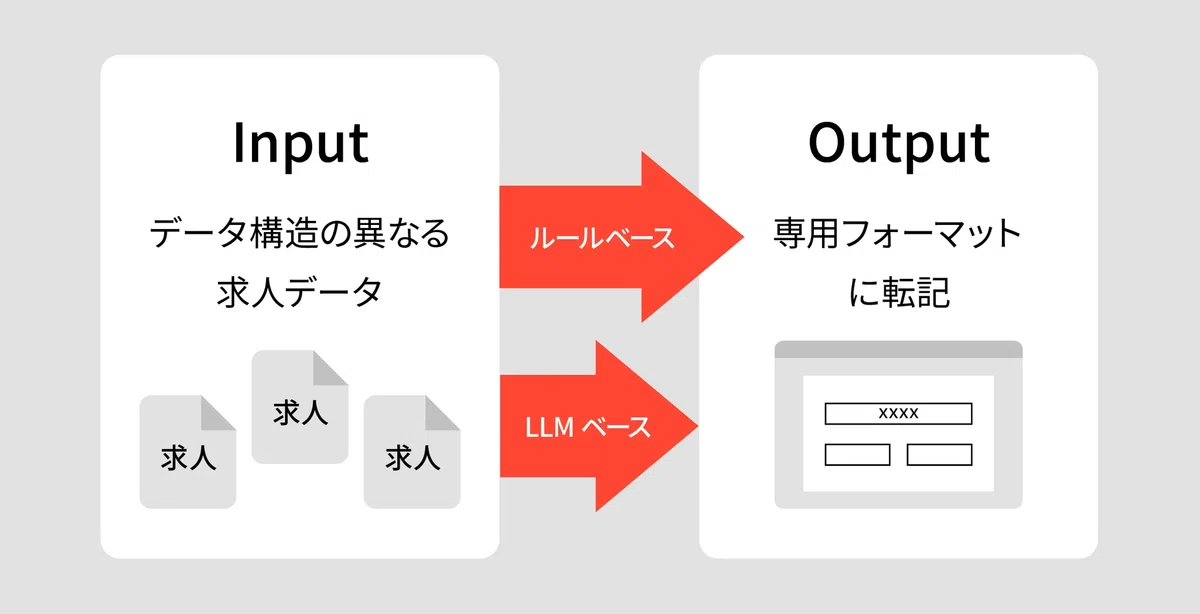
データ構造の異なる求人票の転記作業をルールベースやLLMを用いて楽にする。
どうやったのか?
現状の課題
ユーザー観察から始める業務理解
UI要求をまとめる(デザイナー)
技術仕様を検討する(エンジニア×PdM)
Step1:ルールベースによる自動転記の有効性
① 現状の業務との整合性が高い
② 評価・検証がしやすい
③ UX設計にフィードバックを活用できる
Step2:LLMによる柔軟な転記の導入意義
① ルールでは対応しきれない文脈や表現への対応
② 構造化の精度とUX改善の相乗効果
③ UXの探索的改善フェーズへの移行
リリース前の効果予測。約13分削減ができそう。
初期リリース後の結果。Step1のみで生産性が40%向上🎉
まとめ:再現性のある4つの学び
① 行動観察によるワークフロー理解+自身もユーザーとなりトレース
② ジャーニーマップによるシステム・AI導入ポイントの可視化
③ タスクの難易度別分類と判断基準の設計
④ 技術選定をUX設計から逆算する
反省点:AIは“段階的に”導入し「育てる」
おわりに:AIとUXのちょうどいい関係を探し続ける
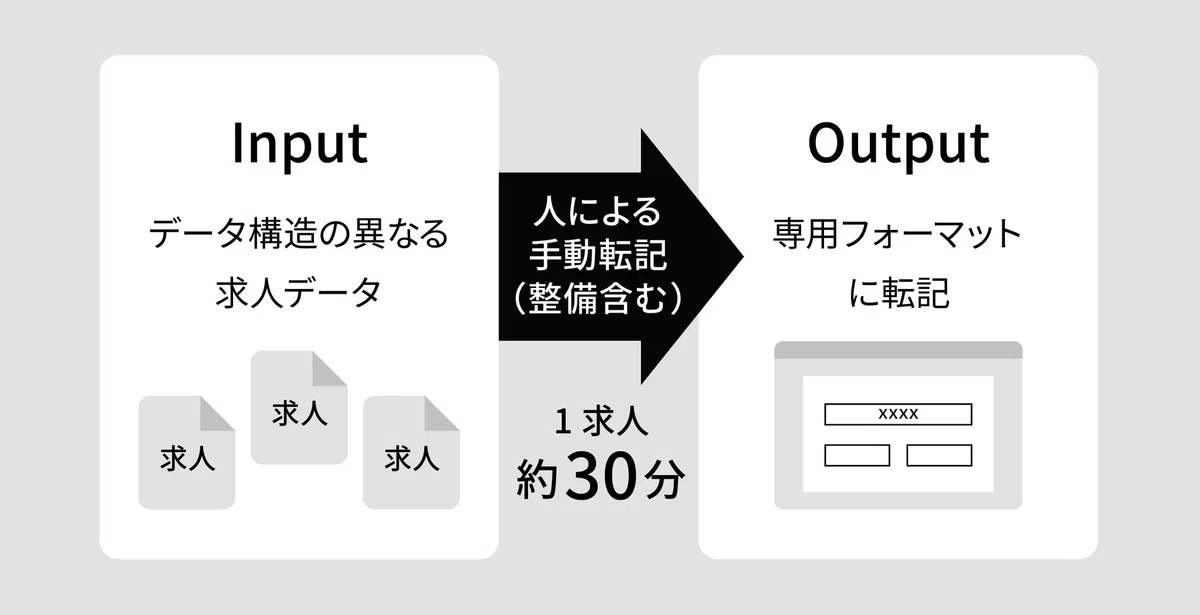
媒体ごとにバラバラだった求人票の項目を、主要な媒体に絞って整理し、過去の転記データを活用。そのうえで、一部の項目をクラウドエージェントに自動転記できる機能を開発しました。(まずは社内向けとして)
実際に、本機能をリリースして1ヶ月ですが、ユーザーの生産性が40%アップしました🎉
実はこのプロジェクト、これまでも何度かチャレンジされたものの、なかなかうまく進まずにいた、いわば“壁”のような存在でした。今回、先人たちの学びを糧にして成果につなげることができました。(先人のみなさま、遂にやったよ!という気持ちです。)
今回のプロジェクトでは、多様な形式で提供される求人情報を自社フォーマットへ転記・整備する作業の効率化に取り組みました。
実際の作業風景を観察し、以下の手法でタスクを分解・分析しました。
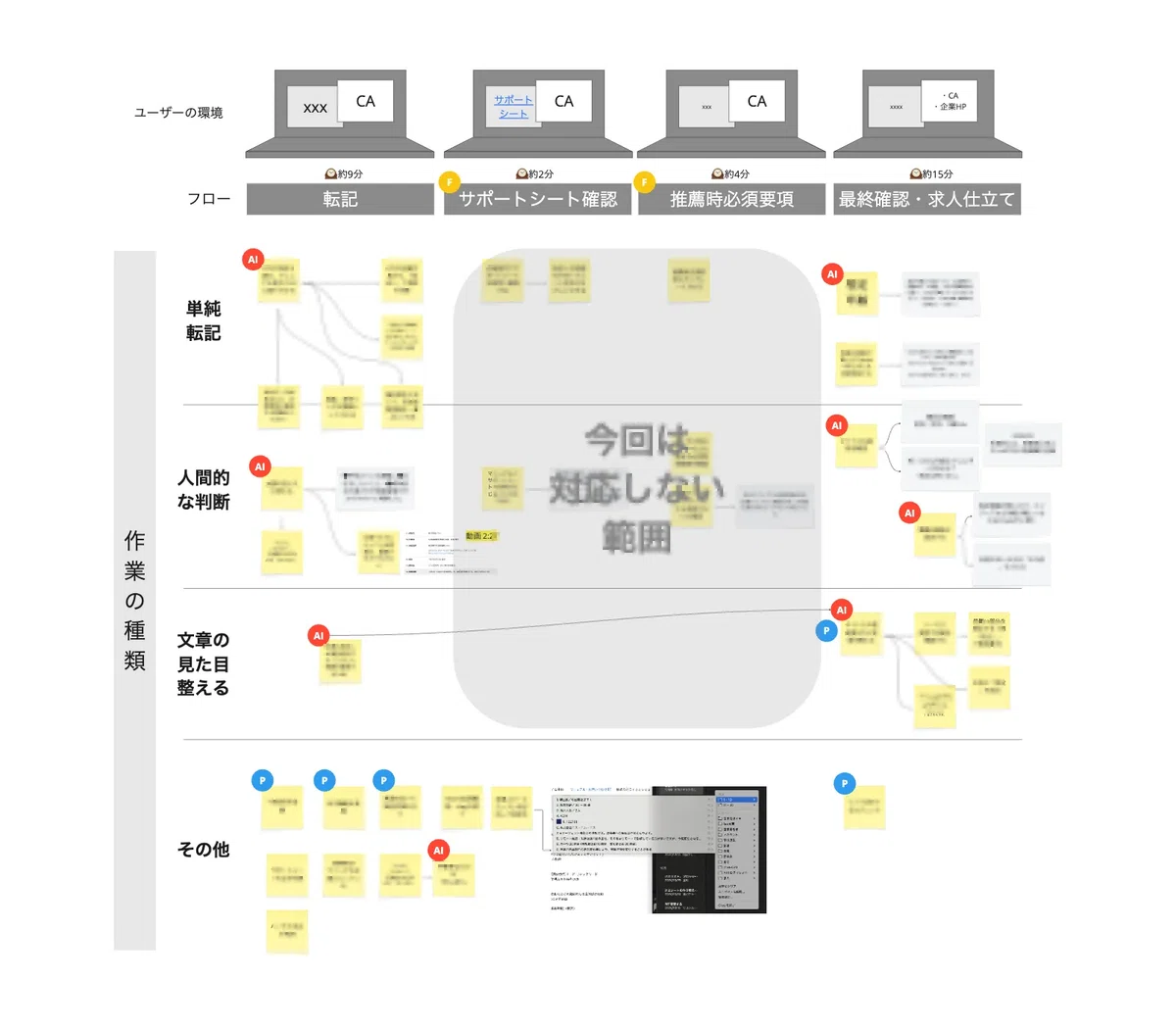
これにより、人間がやった方が良いタスク、AIやシステムがサポートできそうなタスクが分類できました。また、分担されたタスクの状況はUI上でモニタリングでき、人間がチェックしやすい状態が良さそうというイメージが見えてきました。
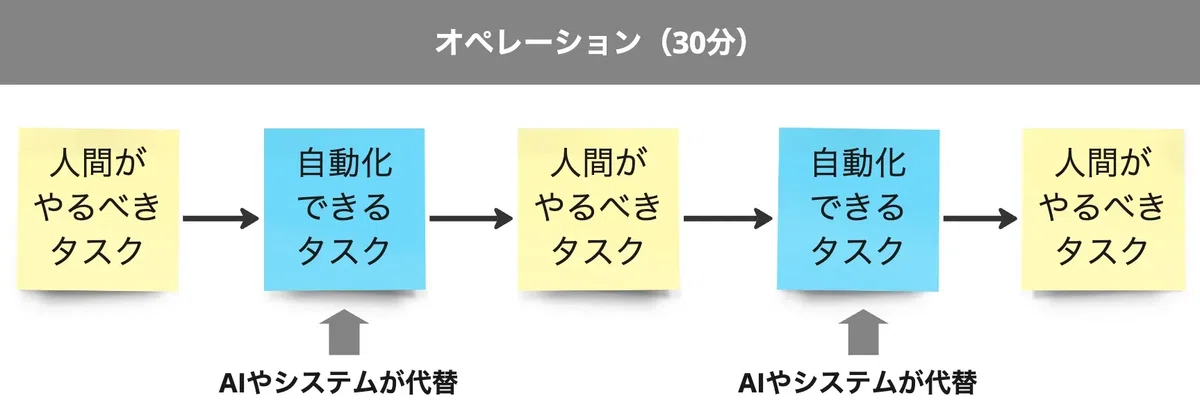
ユーザーの行動を観察し、複数の使い方(ユースケース)と、それぞれに対する価値を整理して、UIに必要なことをまとめました。
AIやシステムが作業をサポートする場面でも、ユーザーが混乱せずにスムーズに作業できるように工夫しました。 ユーザーが自動転記してくれるシステムの動きを見ながら、自分で全体の流れを把握・管理しやすいことを目指しています。

UX観点から設計した構造をもとに、大きく以下のステップで実装計画を立てました。
手動での転記体験から、自動転記体験をユーザーが受け入れやすく、且つPDCAが回しやすいやり方として、ルールベースと転記しやすいUIで信頼と精度を確保し、LLMで柔軟性と拡張性を実現する段階的アプローチが有効と考えました。

この方針により、まず精度と再現性の高い成果を短期間で実現し、その上で柔軟性を高めていくことができます。
ルールベースによる自然文からの構造化データ抽出
求人情報などの文章から、事前に設計した「転記ルール」を用いて、選択肢や数値などを自動的に抽出する仕組みを構築。
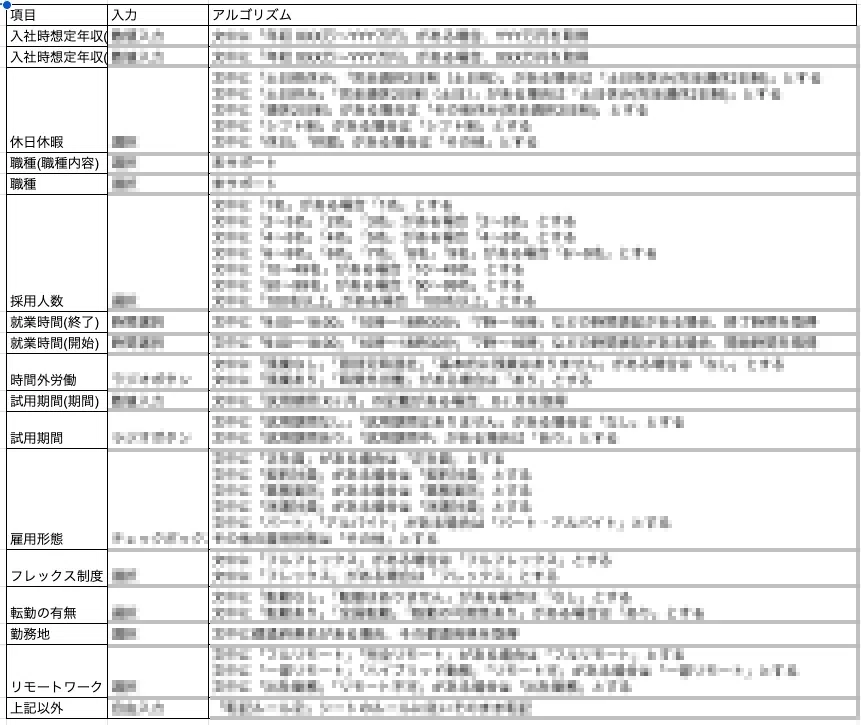
過去の転記履歴を活用したルールベース処理
これまでユーザーが行ってきた手動転記の統計データをもとに、類似度指標(例:レーベンシュタイン距離や文脈埋め込み)を活用した項目マッチングを行い、変換パターンの構造を解像度高く捉えた上で、あえてルールベース実装として定式化する方針を取りました。これにより、精度と再現性の確保だけでなく、業務仕様への可視性・保守性を担保した形でのAI的アプローチを実現しています。(弊社エンジニアより)
データだけでは判断に迷う項目がいくつもあり苦戦
ここが一番泥臭い作業だったかもしれません。求人フォーマットは媒体ごとにデータ構造が異なり、さらに人の判断が必要な転記作業も多いため、シンプルなルールやアルゴリズムでは対応しきれない項目がたくさん出てきました。
その都度に、エンジニアとPdMで一つひとつの項目について丁寧に話し合い、細かい判断を積み重ねて仕様を決めていきました。

観察結果をもとにした改善案により、約30分→17分への時間短縮が見込まれました。
この13分の削減により、年間で数百件規模の業務対応数の向上や、サポートメンバーの業務負荷軽減が期待され、定量的な経済価値にもつながると試算しました。
ルールベースと転記しやすいUIで信頼と精度を確保することができ、求人の作成効率化が大幅にアップしました。Step2(LLM実装)は、現在進行中です。ユーザーからフィードバックのあった項目を中心に、LLM対応を進めています。こちらリリース後にまたお伝えします!
このプロジェクトから得られた、他プロジェクトにも応用できそうな再現性の高いアプローチを以下にまとめます。
インタビューでは表面化しづらい、業務の“実際の痛み”や無意識の行動パターンを捉えるには、行動観察が不可欠です。そして自分も試し痛みを知る。
ユーザーの操作・思考プロセスをマッピングすることで、システムやAIが自然に入り込む接点を見つけやすくなります。
AIが対応すべきか、ルールベースで解決すべきか、人間でなければ難しいかを見極める判断基準を設け、開発の迷いを減らしました。
方針が明確になった状態で技術選定を行うことで、開発チーム内での認識統一と設計ブレの防止につながりました。
最初は「AIを使えば、あれもこれも自動化できるかも?」という期待が先行し、初期の設計段階では、つい欲張って全部AIで実現できないかと検討しすぎてしまい、企画に時間がかかってしまいました。
その経験から、「まずは小さく始めて、確実な成果を積み重ねながら広げていく」ことの大切さを、改めて実感しました。
AIを使うことが前提になりつつある今だからこそ、私たちが向き合いたいのは、「何をAIに任せて、何を人がやるか」をちゃんと見極めることだと思います。
その境界線は、ユーザーの体験や業務の文脈によって変わる。だからこそ、ドメインモデリングで構造を捉えながら、MVPで素早く試し、デュアルトラックアジャイルで育てる。そんな地に足のついた進め方が大事になると感じています。
AIの精度や派手さよりも、現場で本当に役に立つ体験をどうつくるか。その問いに、これからもチームで向き合い続けていきたいと思います。
(最後に社内の方へ)プロジェクト関係者のみなさま!多大なご協力、フィードバックをいただき本当にありがとうございました!まだまだカイゼンでより良くできると思いますので、引き続きよろしくお願いします🙇

/assets/images/17565318/original/cfc52d83-6ef8-4b6d-9c77-db4480733e8e?1712721757)

![]()


/assets/images/17565318/original/cfc52d83-6ef8-4b6d-9c77-db4480733e8e?1712721757)

