【Tech Trend Talk vol.7】社外向け勉強会「ランダムフォレストを用いたスコア予測の実践」を開催しました!

こんにちは。GIG新入社員のこうたそです。入社して2ヶ月になるのですが、僕がGIGにジョインしてからも続々と仲間が増え、だんだんオフィスが人で溢れてきました。
この調子だとオフィス移転の日も近いのでは...!?と、さらに広くておしゃれなオフィスを想像して今からワクワクしています。移転したらみなさん遊びにきてくださいね!
さて、今回GIGは社外のスピーカーをお招きした勉強会「Tech Trend Talk vol.7 ランダムフォレストを用いたスコア予測の実践」を開催しました。
ディレクターやエンジニアなどたくさんの方が参加してくださり、会場はパンパンに。大盛況の勉強会となりました。
スコア実践の予測
今回の講師は、GIGの技術顧問兼外部取締役の中島正成さん。ランダムフォレストを使ったスコア予測の実践方法を教えてくださいました。

中島 正成:株式会社メタップスの取締役CTOとして立ち上げに参画。機械学習とデータサイエンスのプロダクトインプリメントに取り組む。その後、エン・ジャパン株式会社経営戦略室経てIGS株式会社に執行役員CTOとしてジョイン。教育領域へのA.I活用プロダクト開発に取り組む。
過去のTech Trend Talk「機械学習回」はこちら▼
- 【Tech Trend Talk vol.1】社外向け勉強会「中学生レベルの数学で学ぶ機械学習モデルとPythonライブラリの話」を開催しました!
- 【Tech Trend Talk vol.3】社外向け勉強会「機械学習の教師なし学習をやってみる」を開催しました!
- 【Tech Trend Talk vol.5】社外向け勉強会「機械学習の教師あり学習をやってみる」を開催しました!
おさらい1:回帰と判別
本題に入る前に、簡単に前回までのおさらいをします。
機械学習には、大きく分けて「回帰」と「判別」の2つのアルゴリズムがあります。
【回帰モデル】
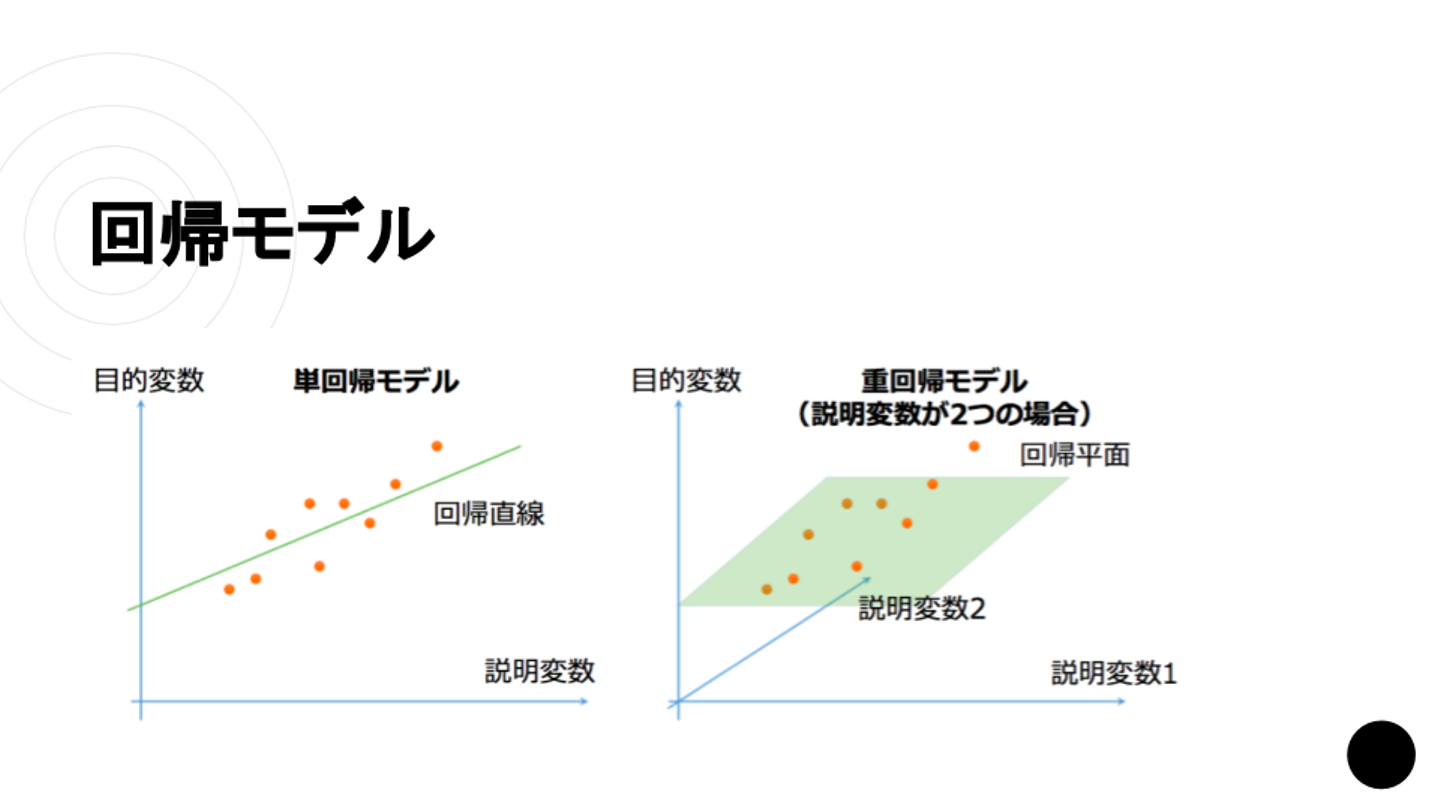
回帰モデルは、関数をデータに当てはめて一方の変数の変動から別の変数の変動に関する説明・予測・関係の検討を行うための手法です。
中島さん:「第一回の中から少しだけ紹介します。これは一番簡単な単回帰モデルと重回帰モデルであり、なおかつ一次関数に当てはめる場合を想定しています」
中島さん:「要するに単回帰とは、データがたくさん散らばってるけど、一次関数に乗っけると、割と全て一次関数の線の近くになる時に、説明変数から目的変数を予測するモデルです」
【判別モデル】

中島さん:「関数を作るまでは回帰モデルと同じですが、判別の場合は線を引いた後にA群とB群に分けるものになります」
中島さん:「判別モデルは分類のためのモデルと思ってもらえれば良いです。例えば、たくさんあるパラメーターがどのカテゴリーに所属するのか予測する際などに使うと考えて、概ね間違いではありません」
中島さん:「ひとまず機械学習は、これらの関数を自動で作っていくものと認識しても良いでしょう」
おさらい2:「教師なし学習」と「教師あり学習」
中島さん:「教師あり学習では、ある程度たくさんのデータを教師データとしてコンピュータに学習させると、教師データと同じパターンで回帰と判別をします」
中島さん:「プロダクトに取り入れられることが多いのが、教師あり学習です」

中島さん:「これに対し、教師なし学習とは教師あり学習と同様に、機械学習の手法の一つです。ただし、『出力すべきもの』があらかじめ定まっていない点で、教師あり学習とは大きな違いがあります」

中島さん:「おさらいの締めくくりとして、『覚えておくとドヤれる』言葉を紹介しておきます。ざっと、前回の勉強会までに出てきた言葉です」
中島さん:「エンジニアの方が機械学習をプロダクトに活用する時に、SVM(support vector machine)、RandomForest、ロジスティック回帰の3つは使い勝手の良いアルゴリズムなので、憶えておくと良いと思います」
中島さん:「ちなみにディープラーニングが巷で流行っていますが、Webサービスの現場ではほぼ使いません。理由はふたつ。単純に学習データが大量にないと精度が上がらないこととと、画像・動画データのように、一つひとつのデータが大きい係数で、なおかつビット配列であることが、プロダクト的に使う条件になっているからです」
スコア予測実践の事前準備
ここまでは前回までの勉強会のおさらいでした。これからいよいよ本題である「スコア予測」に入っていきます。実践するために、まずは準備としてPythonを入れます。
1. Pythonを入れよう

中島さん:「Macの場合は、スライドの左画像の手順でインストールします」
中島さん:「環境構築についてですが、pyenvを入れた後、データ分析をする時にはanacondaというパッケージをインストールすると良いかと思います」
中島さん:「anacondaには、機械学習やデータ設定に使うライブラリが、オールインワンで入っているのでオススメしています」
2. Jupyter Notebookを入れよう
次に、Python使って分析や学習させるにあたり、多くのデータサイエンティストに使われているJupyter Notebookを今回の講座では使います。
中島さん:「Jupyter Notebookはブラウザ上でスクリプトを書いて実行して、実行結果の記録や共有ができるツールです」
中島さん:「有料の大層なツールもありますが、Jupyter Notebookでトライアル&エラーをしながらある程度のことはできます。使えば、データサイエンティストは幸せになれるでしょう」
Bostonデータセットを使って住宅価格の予測
準備が終わったらいよいよ、RandomForestとBostonデータセットを使って練習していきます。
RandomForest:
ランダムフォレスト(英:random forest, randomized trees)は、2001年にLeo Breimanによって提案された機械学習のアルゴリズムであり、分類、回帰、クラスタリングに用いられる。決定木を弱学習器とする集団学習アルゴリズムであり、この名称は、ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用することになる。ランダムフォレストをさらに多層にしたアルゴリズムにディープ・フォレスト(機械学習)がある。対象によっては、同じく集団学習を用いるブースティングよりも有効とされる。(Wikipediaより)
中島さん:「簡単にいうとツリー構造の弱分類器をたくさん作って予測するアルゴリズムです。過学習の影響が小さく、データ量がさほど多くなくてもある程度ワークします。回帰分類クラスタリングなどマルチに使えます」
Bostonデータセット:
scikit-learnに含まれている、線形回帰などで使用するデータセット。ボストンの物件の価格にその物件の人口統計に関する情報が付随したもの。
中島さん:「今回はscikit-learnというPythonのライブラリに入っている、『Bostonデータセット』でデータを学習させてスコアを予測させます」

中島さん:「これらのデータに加えて、物件の価格が入っています。パラメータの値が分かっていれば価格が予想できることを試してみましょう」
中島さん:「Bostonデータセットの場合は、割とプロダクトへの適用イメージが湧くと思います。例えばユーザーのプロフィールに対して何かしらを割り当てると、ユーザーが購入する物件を予測できます。ただし、マッチングとなると『マッチングアルゴリズム』という別の世界にはなります」
Bostonデータセットを読み込んでみる
Jupyter Notebookを起動したら、必要なライブラリを読み込みます。

- pandas:データセットを扱うための様々なメソッドが含まれているライブラリ
- sklearn:ボストンデータセットが含まれているデータセットのライブラリ
- RandomForestRegressor:Regressionは回帰の意味
- accracy_score:大量にデータがあるときにテスト用のデータセットと学習用のデータセットに分けるツール。ランダムに切り出したり、何行目で分ける、何割テストにするのといったことが、一行で済ませられる
中島さん:「Bostonデータセットを読み込んだ後に、データフレームの中に表示してみるところまで行なってみましょう」
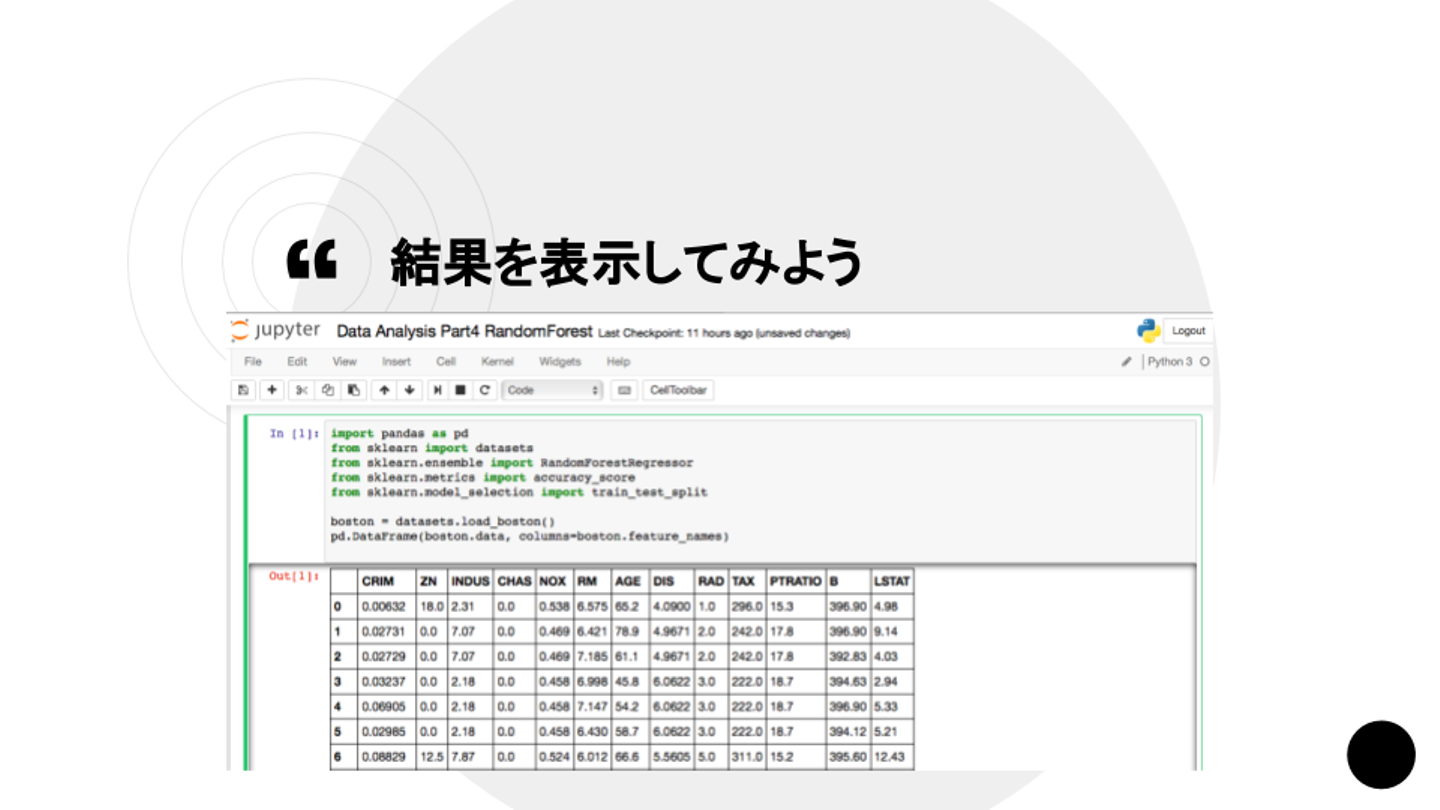
中島さん:「基本的にscikit-learnのデータセットの構造は同じです。データ、フィーチャーネーム、ターゲット予測の結果が表示される構造です」

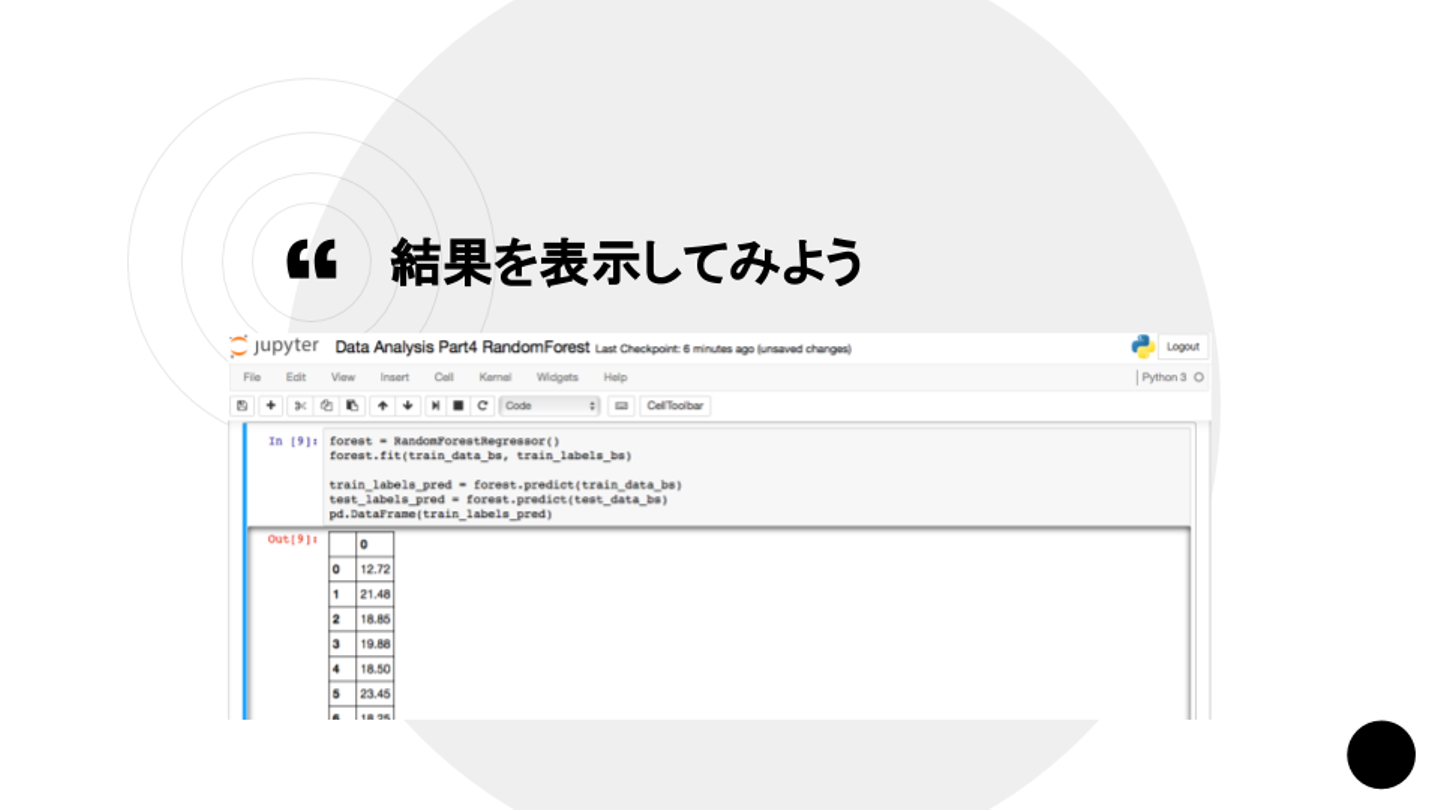
中島さん:「scikit-learnの機械学習のライブラリは、fitで学習してpredictで予測の結果をだすものです」
中島さん:「説明変数を入れると配列も返ってきます。実際に予測したデータがこちらです」
中島さん:「予測精度の数値をだすこともできます。業務のデータですと、30%ほどからスタートすることが多いです」
中島さん:「RandomForestを本番で使おうと思ったら、外れ値を省くですとか平準化、アルゴリズムの選択が必要になります。この辺りは、次回の勉強会で触れる予定です」
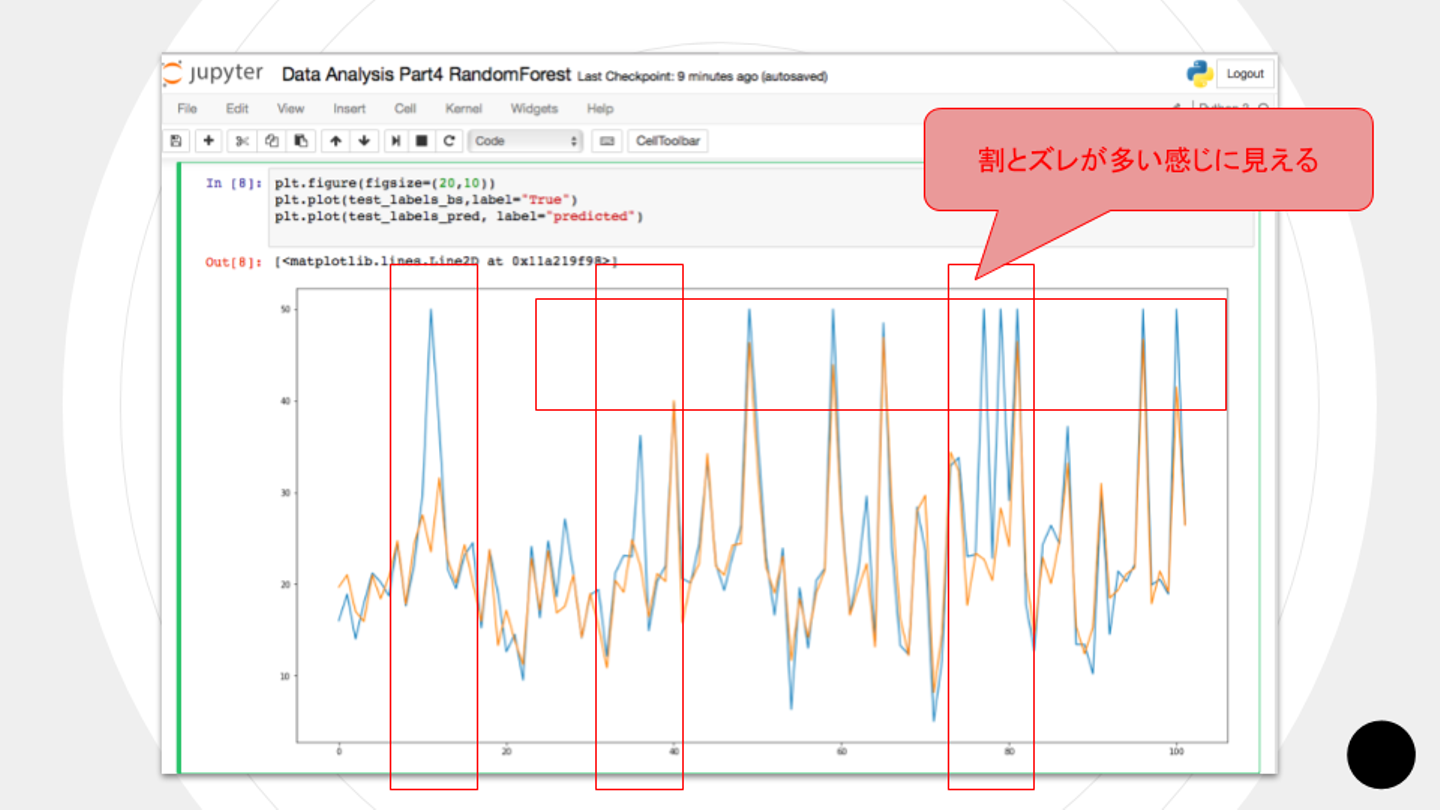
中島さん:「ブルーがもともとの正解データのグラフです。オレンジが予測した値です。このズレを改善できないかということで、ハイパーパラメータで精度を上げてみたいと思います」
精度をあげる為に出来る事
最後にハイパーパラメータのチューニングで精度を上げる方法です。
中島さん:「RandomForestのクラス自体、事前のパラメータを与えることで予測の精度を調整できます」
中島さん:「RandomForestのハイパーパラメータは他にもたくさんありますが、比較的重要なもの、よく使うものを次のスライドで挙げています」

中島さん:「これらを一つ一つ手動で変えてチューニングすると大変骨が折れるので、今回はscikit-learnのGridSearchCVを使って、条件を設定し、自動で良い感じのチューニングを探します」
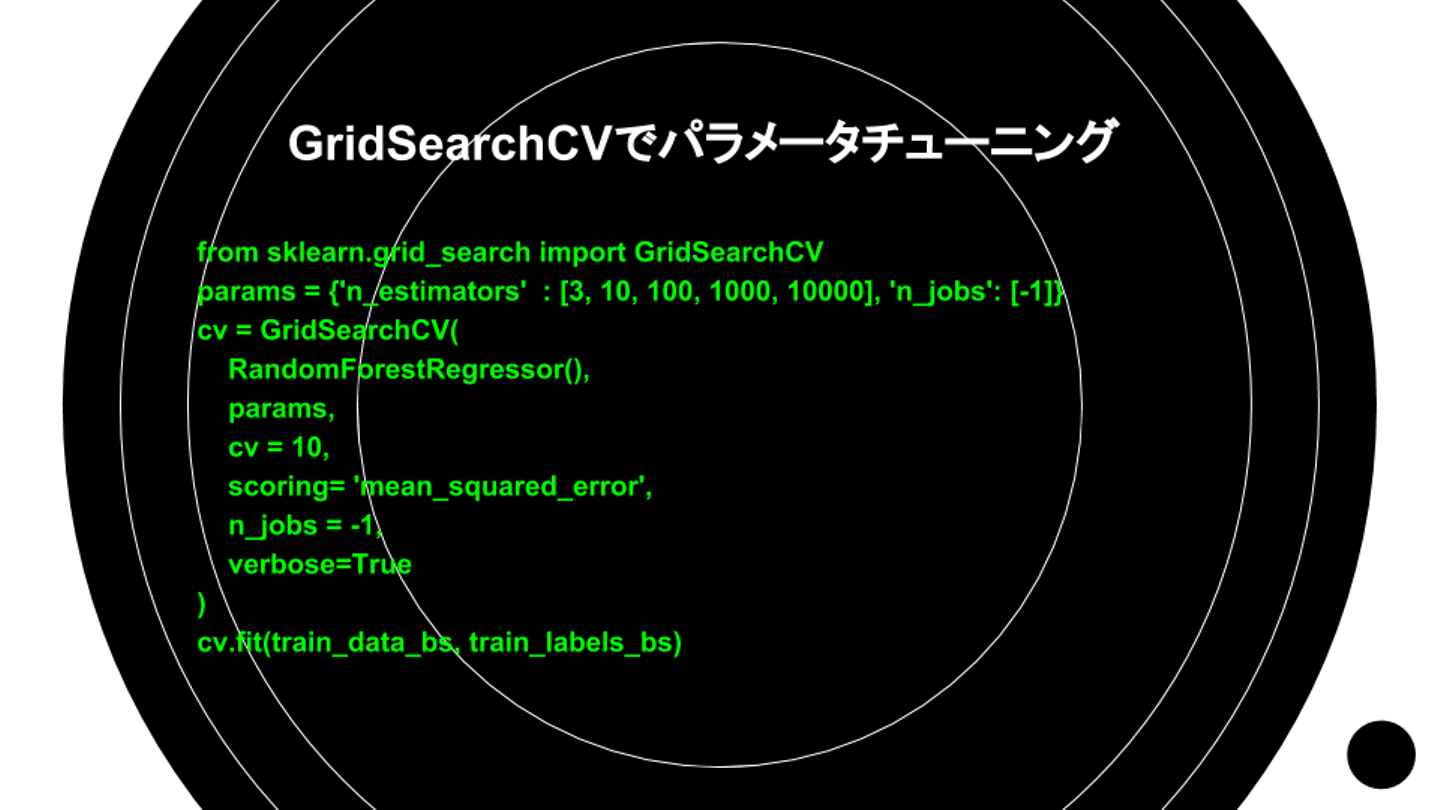
中島さん:「パラメータチューニングをするために、数字はなんでも良いので条件を設定します。さまざまなパターンを試してみてください」
中島さん:「指定するパラメータは、RandomForestのハイパーパラメータから自由に追加できます。例えば、それぞれ配列で指定していくと、全て試行した上でmin、max、 medianを取ってきてくれます」
中島さん:「matplotlibを使ってグラフを表示し、チューニング前後を比べたものがこちらです」
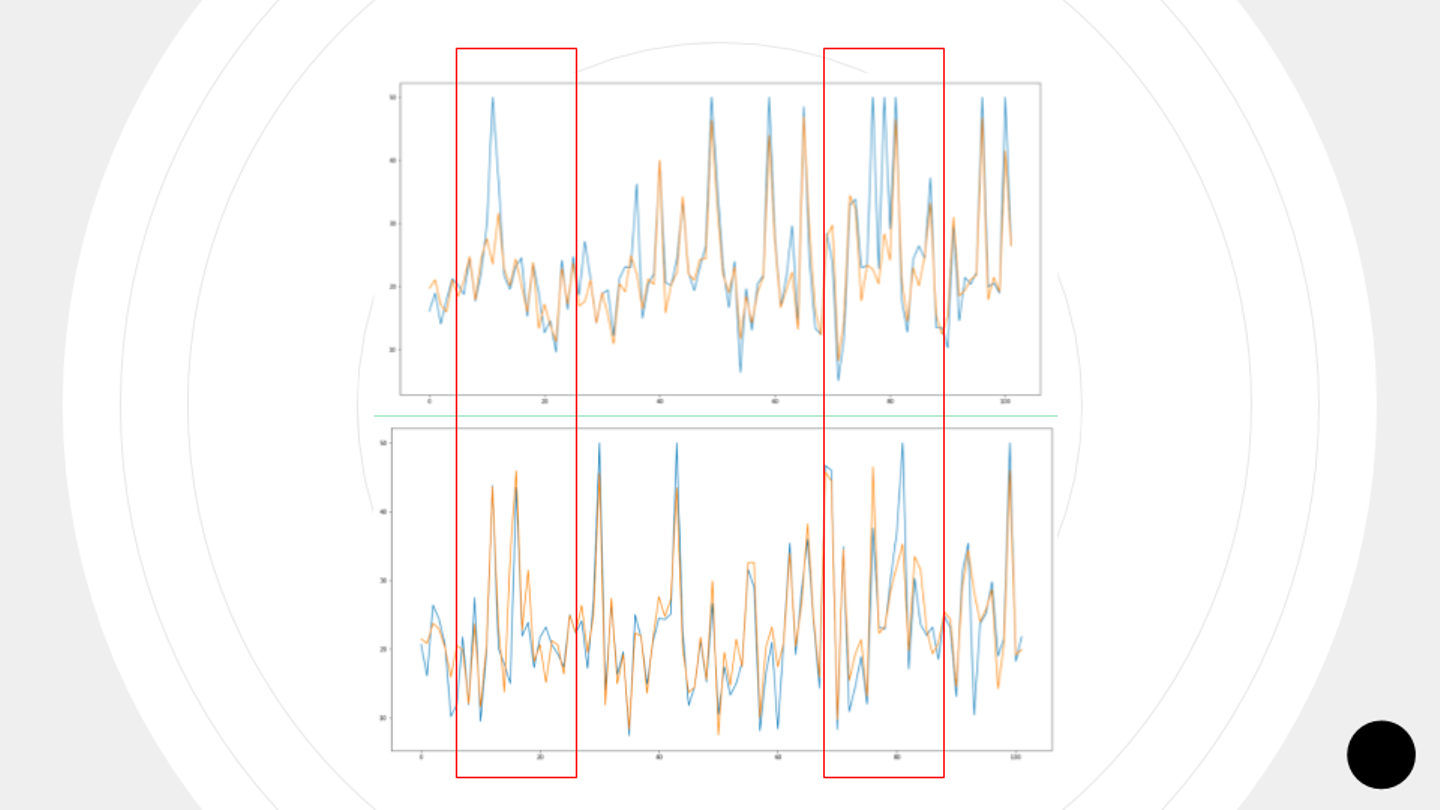
中島さん:「データセットが悪い時にはこのチューニングで割と改善することもあります。GridSearchの手順を憶えておくとRandomForestを扱えると思います」
中島さん:「機械学習をする時に最初に難しいことを行いがちですが、RandomForestで十分な可能性もあるので、一番最初に使ってみても良いでしょう。RandomForestの存在は憶えておいてください」
最後は懇親会で乾杯!

勉強会のあとは懇談会のお時間です! 参加者のみなさまと各々お酒やソフトドリンクを手に、乾杯しました!

中島さんに質問したり、参加者同士で情報交換をするなど、社内外関係なく交流しました。
まとめ

GIGでは月1回のペースで社外向けの勉強会を開催しています。エンジニアに限らず、デザイナーやディレクターなども勉強会に参加しており、全社的なスキル向上の良い機会となりました。
僕はエンジニアではないこともあって機械学習にも疎いのですが、中島さんのお話はとても興味深かったです。これからも積極的に勉強会に参加しようと思いました。
GIGでは機械学習、IoT、ブロックチェーンなどの最新トレンドに関する勉強会を今後も定期的に開催していきます。イベントの詳しい情報は、connpassのGIGページをチェックしてください!

/assets/images/3497018/original/442e1f20-9ff4-41e2-a35a-d5b3251e0c45?1550453029)





/assets/images/3494878/original/0208f604-e13c-4566-bdb6-d3d29cbca61e.png?1550377824)


