こんにちは、ナイトレイインターン生の保科です。
Wantedlyをご覧の方に、ナイトレイのエンジニアがどのようなことをしているか知っていただきたく、Qiitaに公開している記事をストーリーに載せています。
今回はGISエンジニアの徳竹さんの記事です。
少しでも私たちに興味を持ってくれた方は下に表示される募集記事もご覧ください↓↓
CLASSIFY_TEXTがプレビューになりました
CLASSIFY_TEXTが先日プレビューになりました。
CLASSIFY_TEXT 関数は「プロンプトエンジニアリングや後処理、例を提供することなく、テキストレコードにすばやく正確にラベルを付けることができる」というものです。
さっそく試してみましょう!
試す!
施設のカテゴリ分類
まずは、分かりやすそうなテーマで、施設のカテゴリ(観光施設・食事処 等)を分類してみます。
以下のカテゴリー1(大分類)と更に細かいカテゴリー2(小分類)で試してみます。
select
place_name,
get( -- JSON形式で返却されるのでget()で値を取り出します
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(
place_name,
['買い物', '遊び', '交通', '生活', '観光', '飲食']
),
'label'
) as category_1,
get(
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(
place_name,
['レジャー施設', 'スーパー', 'ラーメン屋', 'ゲームセンター', 'カレー屋', 'ライブハウス', '-- 合計45分類にしています_割愛 --' ]
),
'label'
) as category_2
from
sample
;
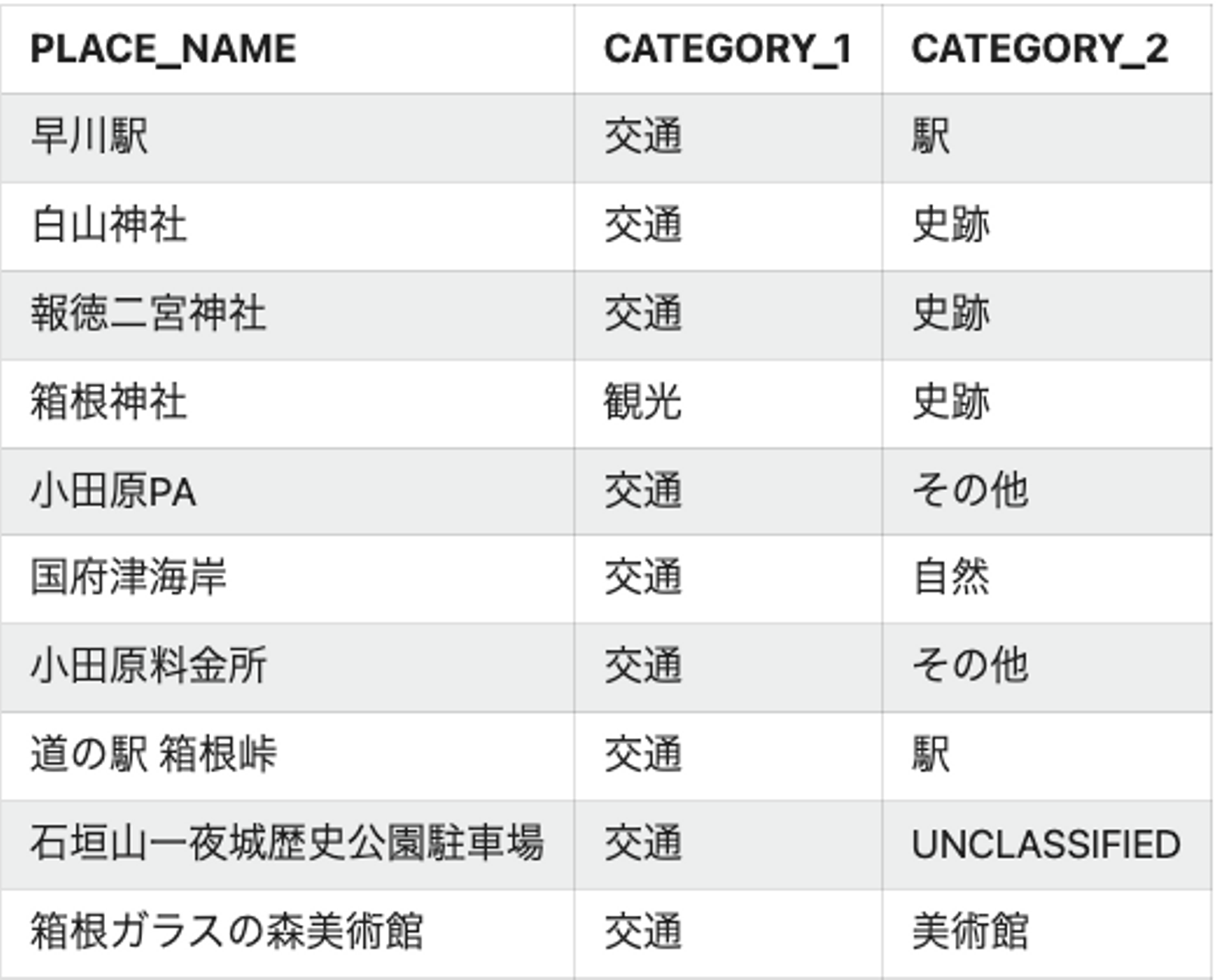
結果は以下のとおり!
- 大分類はなぜか「交通」に分類しがち
- 小分類はなんとなく合ってそう!
- UNCLASSIFIEDで分類できないパターンもある
まずは、細かめに分類をしてもらったものをあとで集約したほうが良さそうな印象。
![]()
テキストから旅行前後か分類
次は、テキストの内容から「旅行前・旅行中・旅行後」の分類をしてみます。
LLMにそれぞれのシチュエーションを想定したテキストを作ってもらいました。
select
text,
status_original,
get(
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(
tweet_text,
['旅行前', '旅行中', '旅行後']
),
'label'
) as travel_classified
from
sample
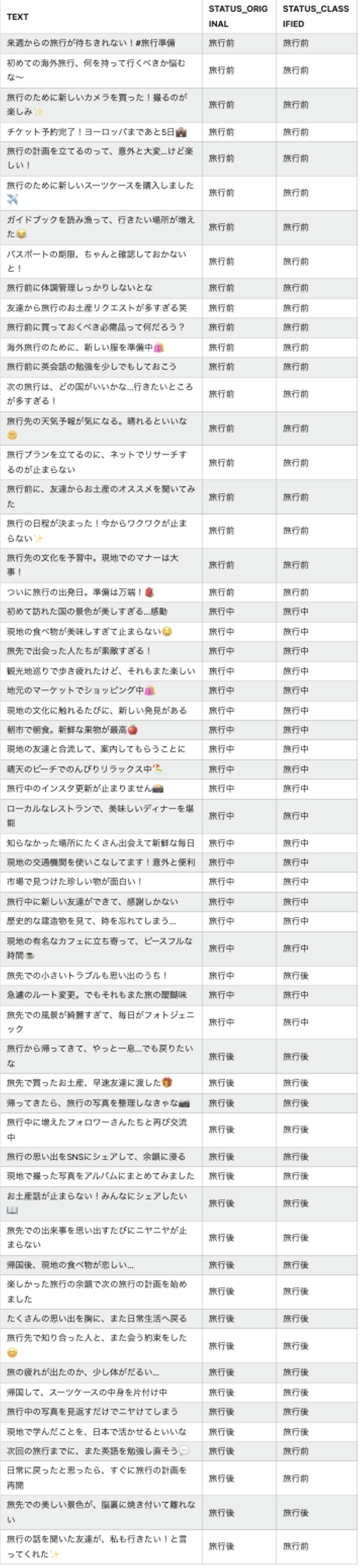
結果は以下のとおり!
※ STATUS_ORIGINALはLLMが文書作成時に想定したステータスです
- 人間と同程度の判断をしている印象
- たしかに「日常に戻ったと思ったら、すぐに旅行の計画を再開」は旅行後か旅行前なのか分類に悩む
先程の施設のカテゴリ分類のように単語を対象とするよりも、ある程度の文章量があった方が良さそうですね!
![]()
テキストから年齢層を分類
次は、テキストの内容から筆者の年齢層を分類してみます。
先ほどと同様に、LLMで各年齢層を想定したテキストを生成したものを使います。
select
text,
age_original,
get(
SNOWFLAKE.CORTEX.CLASSIFY_TEXT(
text,
['10代', '20代', '30代', '40代', '50代', '60代']
),
'label'
) as age_classified
from
sample
;
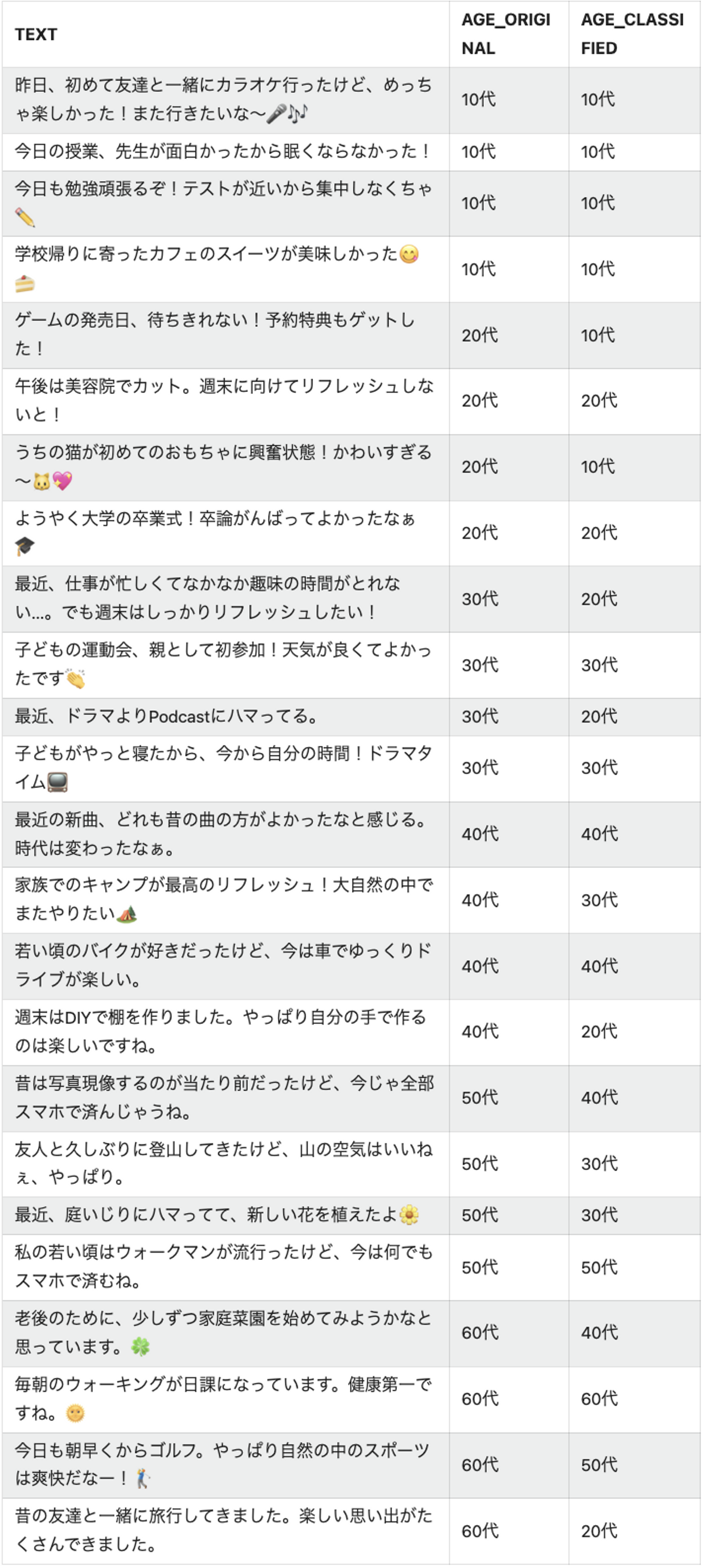
結果は以下のとおり!
※ AGE_ORIGINALはLLMが文書作成時に想定したステータスです
- LLMが想定したステータスと概ね同じような分類になった
- 「そのぐらいの年齢層っぽいね」くらいの分類にはなっている
そもそも正しい年齢層が不明なので精度の判断が難しいですが、「良さそう」という印象です。
![]()
下記の記事にあるように、単純にテキストを分類するだけでなく、LLMアプリケーションにおいて、ユーザーからのプロンプトを分類してルーティングに活用するというのも良さそうですね!
活用方法は幅広そうなので、研究していきたいと思います!

/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)


/assets/images/17514/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1427288547)
/assets/images/8300070/original/558f701b-5611-44f3-bc41-0c96b473917a.png?1639042247)


