本記事はAWS Startup Community Advent Calendar 2021の24日目です。
こんにちは、dotDで愛犬/ペットのお散歩・健康の記録管理アプリであるonedogの開発を担当している遠藤です。
▼目次
- 今回の取り組み
- なぜこの取り組みが必要だったか
- まずは負荷の傾向を確認
- 次にボトルネックの確認
- 改善の対策
- ①インデックスの作成
- ②不要なUPDATE処理を削除
- 対応後のDB負荷の確認
- DBインスタンスのスペックダウン
- コスト削減結果
- db m5.2xlargeのコスト
- db m5.largeのコスト
- まとめ
今回の取り組み
今回はインフラコストの削減の取り組みの中で、Amazon RDSのPerformance Insightsを利用してボトルネックとなっている処理を洗い出し、パフォーマンスチューニングを行い、DBの負荷を軽減させ、DBインスタンスのスペックダウンにつなげた取り組みについてお話いたします。
なぜこの取り組みが必要だったか
サービスのインフラコストが月に1ユーザあたり80円近くかかってしまう状況になってしまったことがきっかけです。
onedogのアプリは課金プランがあるものの課金せずに利用できるアプリなので、全てのユーザに課金プランに加入頂いているわけではありません。
なので、残念ながら課金によってインフラコストを賄えている状態ではありません。
ユーザを増やす取り組みを行えば行うほど、インフラコストが増大しサービスとしての赤字が増えてしまいます。
もちろんサービスレベルを維持しつつもインフラコストを削減しなければ、会社の売上にも大きな影響を与えてしまう状況になりかねません。
例えば、ユーザが100万人に増えて、インフラコストが1当たり100円だとすると、単純計算で月々1億円がインフラコストになってしまいます。
そこで、今回インフラコストのうち最も金額の大きかったRDSのコスト削減に、弊社梅田とともにまずは集中して取り掛かりました。
まずは負荷の傾向を確認
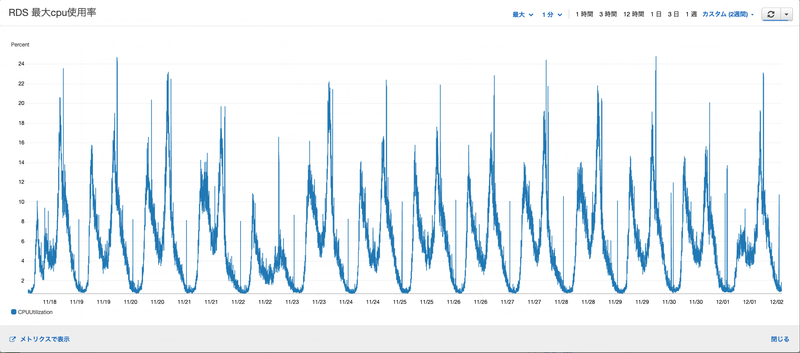
DBのどこに負荷がかかっているのかを探っていくため、まずは負荷の傾向を確認するためにCloudWatchを眺めてみました。
- 使用可能なメモリ量はほぼ変動なく潤沢なままだったので、メモリを多く使っていることはなさそう
- CPU使用率の変動の波が激しい。(特にわんちゃんのおさんぽ時間帯、朝と夕方の負荷が高い)
![]()
CPU使用率
次にボトルネックの確認
今度は、CPUを使用しているものが何かを探るため、SQL単位での負荷状況を確認できるRDSのPerformance Insightsを見てみました。
そこで、いくつか負荷をかけているクエリが見つかり、その原因を探ると特定の原因が見えてきました。
- 全ユーザの日々のおさんぽの記録のため、件数が多いおさんぽ履歴テーブルのSELECT文で常にフルテーブルフルスキャンしていた。
- ユーザテーブルのSELECT文で常にフルテーブルフルスキャンしていた。
- システム内で利用していないカラムをおさんぽ中の位置情報の更新毎にUPDATEしていた。(Performance Insightsに出てくるSQLとしては、COMMITに全てマージされてしまいます)
改善の対策
①インデックスの作成
発見したボトルネックの中でもSELECTの負荷が大きいもので、おさんぽ履歴テーブルもユーザテーブルも検索条件はPK以外のカラムでの検索でした。どちらのSQLも検索条件に指定しているカラムは一意になるデータのカラムで、そのカラムで検索してPKのカラムを取得するSELECT文でした。
そこで、対策としては検索条件で利用しているカラムのインデックスを作成し、インデックスが使われるように改善しました。
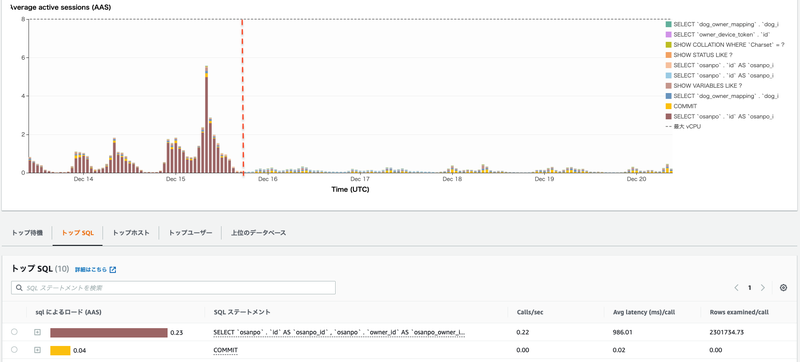
以下がPerformance Insightsでの例で、赤点線でインデックス作成を行い負荷状況が一変しているのが分かるかと思います。
![]()
インデックス作成前後の負荷状況
②不要なUPDATE処理を削除
無駄なUPDATE処理を発見したので、その処理を削除した。
以下がPerformance Insightsのカウンターメトリックスでの例になります。
オレンジ色がSELECT、青色がUPDATEなので、対応前まではほぼ同じ波形になっていましたが、対応後青色の波形だけが消えています。
![]()
カウンターメトリックスの状況
対応後のDB負荷の確認
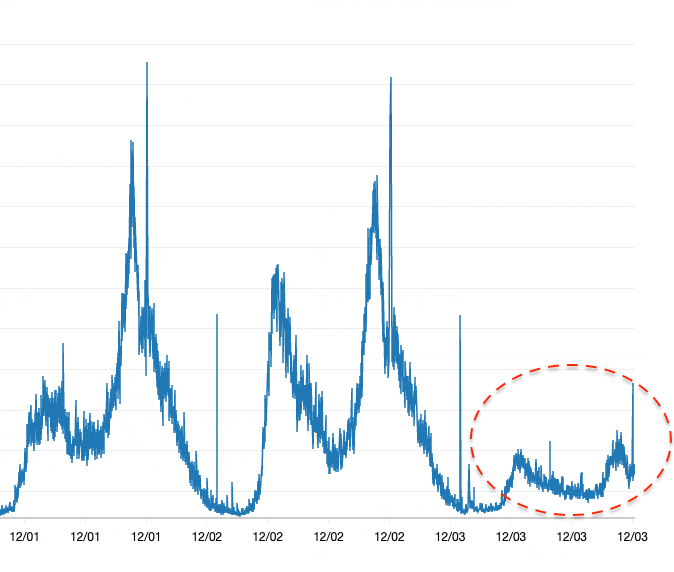
発見した高負荷なSQLへインデックスの作成及び無駄なUPDATE処理の削除の対応を行ったことで、DBのCPU使用率がピーク時の頂点が1/4程度までに抑えられるようになりました。
![]()
対応後のCPU利用率
DBインスタンスのスペックダウン
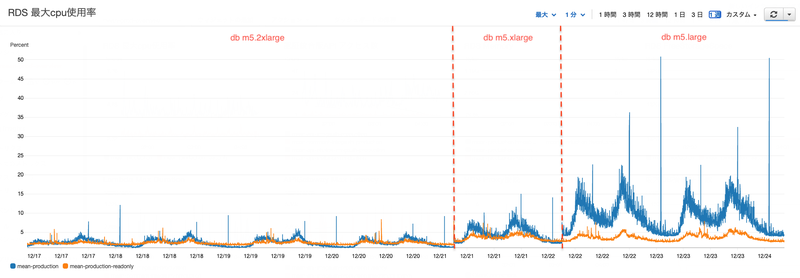
負荷の低減により、現在のDBインスタンス(db m5.2xlarge)では過剰スペックとなったので、スペックダウンを行いました。
安全のため1ランクずつ下げて行くことにしました、スペックダウンし1日様子を確認し、さらにスペックダウンをし様子を確認を繰り返しました。
最終的にDBインスタンスを「db m5.2xlarge」から「db m5.large」までスペックダウンを行いました。
![]()
スペックダウン前後のCPU使用率
負荷の傾向で確認したとおり、メモリはほぼ使用していないのでスペックダウンによって利用可能メモリ量が減ってしまっても問題はありません。
したがって、vCPUが半減するスペックダウンを行い、CPU使用率が倍増するだけになっていることが確認できたので成功といえます。
コスト削減結果
AWS Priceing Calculatorを利用し各スペックの月額コストの見積もり算出し、スペックダウンによりどれほどコスト削減したのかを示します。
db m5.2xlargeのコスト
![]()
db m5.2xlargeのコスト
db m5.largeのコスト
![]()
db m5.largeのコスト
結果、$1400.00-$370.70=$1029.3となり、1000USD程のコスト削減することができました。
まとめ
インフラコストの削減対応で、金額が高いDBについて1000USD程削減することができ、結果的に1ユーザあたりのインフラコストを10円程下げることができました。
また、DB負荷改善前の負荷だけを見れば逼迫した状態ではなかったので、負荷改善対応をするということにはならなかったと思います。けれども今回の対応により、潜在的な危険を解消することができ、さらにスペックダウンすることでコスト削減もすることができました。
改善対応の中でインデックス作成の大きな効果を改めて感じることができました。そして定期的な見直し、改善は行う必要性があることを学ぶことができました。
まだまだ1ユーザあたりのインフラコストが高いので改善を進めていきたいと考えております。
dotDでは一緒にサービスを作ってくれる仲間を大募集中です!
副業から参画でも全く問題ありませんので、すこしでも興味を持たれた方がおられましたら、お気軽にお声がけください!!
▼onedog公式note
▼onedog公式HP
▼dotD公式note
▼dotD公式HP




/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)


/assets/images/4296662/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1574232535)
/assets/images/8864511/original/b80b4f68-ec9e-4cdc-9859-c9bcb75aa27f?1644990968)


