/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)

/assets/images/3498840/original/34146727-902d-42e5-898f-7c9de258e514?1653291802)
モノグサ株式会社's job postings
- ソフトウェア/データエンジニア
- PdM(Study領域)
- カスタマーサクセス・事業開発
- Other occupations (21)
- Development
- Business
- Other
Monoxer株式会社CTO畔柳です。
本日はMonoxerの基盤となっている学習理論の一つである産出効果(生成効果; Generation Effect)について紹介したいと思います。
産出効果とは、例えば単語を記憶する際には、単純に単語を見て読み上げたりするよりも能動的にアウトプットするのが効果的であるという理論です。読み上げるのもアウトプットなのでは?と思うかもしれませんが、完全に対象を与えられた状態で読み上げるのか、不完全な状態の対象を想起するのかという違いがあります。Norman J. Slamecka and Peter Grafは1978年に The Generation Effect: Delineation of a Phenomenon で産出効果を提唱しました。かなり昔の論文なのですが、この知見は今でもとても重要です。
一般的に、単語を読み上げるのは能動的な行為で記憶にも良さそうだ、と考えられているのではないでしょうか。私も中学生・高校生の頃はそのような学習をしていました。しかし、実は、それよりも遥かに効率の良い方法が存在していたのです!早く知りたかった!
論文中の実験では、英単語のペアのリストが与えられ、それぞれのペアの1つ目の単語に対して2つ目の単語が何なのか記憶するタスクを行っています。以下の2つの方法で学習した場合の結果を比較しています。
GENERATE: ヒントに基づいて記憶したいものを産出する
ヒントとしては先頭の文字とペアの関係性のルール(RULE: 対義語・同義語など)を提示する
READ: ペアのRULEは伝えられた上で、記憶したいものを見て読み上げる
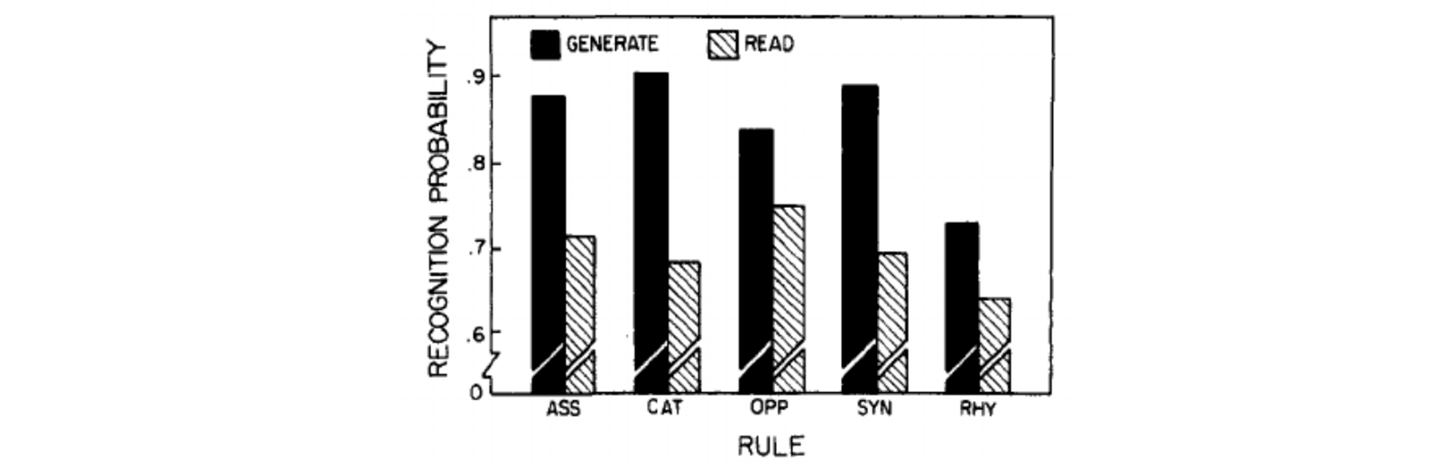
結果は以下の通りです。横軸は方法・ルール(ASS=assosiate; CAT=category; OPP=opposite; SYN=synonym; RHY=rhyme)の別、縦軸は正答率を示しています。
GENERATEで学習した場合は平均すると80%を超える正答率となっているのに対し、READは70%弱の正答率となっています。RULEごとのGENERATE、READの関係性には大きな差はなく、産出効果は記憶対象の性質にかかわらず有効であることが示されていると言えます。単純に見て覚えるだけであれば差があるのも不思議ではないのですが、読み上げるという活動を行ったとしても、これだけの差が出るのは産出効果の力は大きいと感じますね!
Monoxerでは、新しいものを記憶してゆくプロセスの中で、産出効果を活用しています。
産出効果を利用する上での最大の問題点は適切な産出(回答)を行わせる仕組みを用意するのが難しいことです。上記論文のように一律のヒントを用意すると、得意なものには簡単すぎるが、苦手なものは全く答えられない(産出できない)という状況になってしまいます。そのため、産出効果はテスト効果ほど気軽に活用するのは難しいと言えます。
Monoxerでは記憶すべき対象ごとに学習する人がどのくらい記憶しているかを管理しています。その情報に基づき、どのようなヒントを提示するかを動的に調整しています。ヒントの量や出し方は、学習する人が回答できる範囲で最高難易度の問題になるのを目指しています。これにより学習効果が高まるのはもちろんですが、見方を変えると、誰もが間違えるという経験なく学習を進めることができるようになるということでもあります。
間違えることは誰にとっても快いことではないと思います。学習の過程で間違えるという嫌な経験をしなくてはならないことが、記憶嫌い・勉強嫌いを作っている大きな要因の一つなのではないでしょうか。
もし、一切不正解と言われることなく何でも記憶することができたら、全く違う世界がやってくると思いませんか?
これは、Monoxerのミッション"記憶を日常に"を達成するための重要な鍵の一つです。近い将来Monoxer上で実現できるように開発を進めています!
Monoxerではこのような学習プロセスの改善も含め、一緒に記憶のプラットフォームを作ってゆく方を募集しています。
少しでもご関心をお持ちいただけたら、ぜひ一度お話ししましょう!

/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)

![]()


/assets/images/8938972/original/474e8d94-0e78-42ef-bac2-bce8cc93748e?1645852843)