
Pythonを使って簡単にできるビジネスインテリジェンスツール開発 | APOLLO Tech Blog
アポロ株式会社でインターンをしている菅野と申します。 今回は比較的簡単にWebアプリ開発ができるPythonフレームワークの1つであるDashとグラフ描画ツールであるPlotlyを使ったダッシュボード作成を紹介します。 ...
https://www.wantedly.com/companies/company_3535007/post_articles/488372
アポロ株式会社でインターンをしている菅野と申します。
私は、現在インターン生としてSNS上での情報拡散がどのように売り上げに影響を及ぼしているのかを分析しています。前回はDashを使ったビジネスインテリジェンスツール開発について紹介しました。
ぜひ前回の記事もご覧ください。
今回はSNS上での影響力を持つユーザーを分析する手法について解説したいと思います。
SNS上で影響力をもつユーザーを分析する方法の一つに、評価指標を用いる方法があります。
例えば「フォロワー数」や「いいね数」です。
これらは非常にわかりやすい指標でフォロワー数が多ければより多くのユーザーに投稿が見られる可能性が高くなりますし、いいね数が多ければ投稿が多くのユーザーに共感されていることを示すことができます。
しかし、今回の分析では「情報がどれだけ多くの人に伝わるか」を重要視していました。
フォローされてはいるけど投稿を見られていない可能性も高い「フォロワー数」や、投稿は見たけどいいねしていない人も多い「いいね数」といった指標は、「情報がどれだけ多くの人に伝わるか」を必ずしも示すことができないため、今回の分析では他の手法を考える必要がありました。
今回は情報の拡散に注目していたため、ユーザーがどのように他のユーザーに情報を伝えるかという点に着目し、SNSデータからユーザーのネットワークグラフを作成し、グラフ理論で用いられる指標を使って分析しました。
今回は、ユーザーからユーザーに情報が伝達されているとすればツイートの内容が似る、という仮定のもと、ツイートの類似度からユーザーネットワークグラフを作成しました。
「グラフ」とはいくつかの「点」と、点と点の間を結ぶ「辺」から構成される図形のことで、点のことを「ノード」、辺のことを「エッジ」と呼びます。今回のネットワークグラフでは、ユーザー一人一人がノード、ユーザー間を結ぶ関係がエッジです。また、エッジは情報の伝達を表しているため、方向性があります。このようなエッジに方向性があるグラフを有向グラフといい、反対に方向性がないグラフを無向グラフと言います。
後ほど詳しく説明しますが、具体的にはトピックに関するツイートのうち、あるユーザーのツイートから一定時間以内に一定以上の類似度のツイートをしたユーザーがいた場合、ユーザーからユーザーに有向エッジを繋ぐという方法です。フォロー関係やいいね関係をエッジで表現する方法もありますが、今回は情報の伝達に注目していた上、フォロー関係やいいね関係の取得にはTwitterAPIを使用する必要があり、リクエスト制限により取得に時間がかかるということもあり、今回はツイートの類似度をもとにネットワークグラフを作成する手段を取りました。
グラフにおけるノードの重要性を表現する中心性指標が存在し、指標を用いてネットワークグラフの中で影響力を持つユーザーを特定することができます。中心性指標には以下のようなものがあります。
次数中心性はノードにつながっているエッジの本数で計算されます。より多くのエッジとつながっている、つまり他のノードと関係を持っているノードほど高く評価される指標です。
2. 近接中心性
近接中心性は他のノードまでの最短距離の合計の逆数で計算されます。非連結グラフ(グラフ上のある二頂点間における道が存在しない)においては使いづらい指標になっています。
3. 媒介中心性
媒介中心性はあるノードが他のノード間の最短経路上にどれほど位置しているかをもとにした指標です。他のノード間の通信を仲介している場合に高く評価されるため、ネットワーク内の情報伝播や交流の中心を特定するために使われます。
4. 固有ベクトル中心性
固有ベクトル中心性はあるノードに隣接するノードが高い中心性を持っている場合に、そのノードが高く評価されるような指標で、隣接するノード数が少なかったとしても重要なノードにつながっていれば高く評価されます。
今回の分析の目的は、より多くの人に情報を伝えられる「インフルエンサー」を発見することであったので、固有ベクトル中心性を中心性指標として選択しました。
ここから実際のツイッターデータを用いてネットワーク分析を行いたいと思います。
今流行りの「ChatGPT」についてツイートしているユーザーで誰が影響力を持っているのか分析していきます。
今回もGoogle Colabを使って実装します(Jupyter Notebookでも可)。
まず、ツイートデータを取得します。
実際の業務では、snscrapeを使用しツイッターデータの取得をしました。
しかし、ツイッターの仕様の変更により、生データの取得が困難になってしまったので、今回はダミーデータを作成し、使用したいと思います。
ChatGPTに「ChatGPT」という単語を含んだダミーツイートを100個考えてもらい使用しました。投稿日時は2023年4月23日~2023年4月30日までの間でランダムに生成したものを使用ました。
データは辞書のリストとしてtweets変数に格納しておきます。
ツイートの類似度を用いてネットワークを作成するため、類似度を計算できるようにツイートをベクトル化します。今回はBERTの学習済みモデルを用いてツイートをトークンに分け、ツイートベクトルを生成していきます。
実際のコードは以下の通りです。
#文書のベクトル化に必要なパッケージのインストール
!pip install transformers
!pip install sentencepiece
!pip install fugashi
!pip install ipadicimport torch
import transformers
vectors = {}
def vectorize(text): #入力テキストのベクトル化
device = 'cuda' if torch.cuda.is_available() else 'cpu' #GPUが使用可能ならGPUを使用
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
tokenizer = transformers.BertJapaneseTokenizer.from_pretrained(model_name) #学習済みモデルを使用したトークナイザー
bert_model = transformers.BertModel.from_pretrained(model_name).to(device) #学習済みモデル
max_len = 256 #入力文書の上限
inp = tokenizer.encode(text) #トークン化
len_inp = len(inp)
# 入力トークン数の調整
if len_inp >= max_len:
inputs = inp[:max_len]
else:
inputs = inp + [0] * (max_len - len_inp)
# モデルへ文書を入力し特徴ベクトルを取り出す
inputs_tensor = torch.tensor([inputs], dtype=torch.long).to(device)
seq_out = bert_model(inputs_tensor)[0]
pooled_out = bert_model(inputs_tensor)[1]
if torch.cuda.is_available():
return seq_out[0][0].cpu().detach().numpy()
else:
return seq_out[0][0].detach().numpy()
for tweet in tweets:
vectors[tweet['id']] = vectorize(tweet['text'])ツイートベクトルを用いてコサイン類似度を計算します。
コサイン類似度とはベクトルAとベクトルBの内積をそれぞれのベクトルのノルムの積で割ったもので、ベクトルの偏角が0に近い(文章が近い)ほど値は1に近づき、遠いほど-1に近づきます。
計算したコサイン類似度をもとにネットワークグラフを作成していきます。あるツイートから一定時間以内のツイートでコサイン類似度が閾値以上の場合に「情報が伝播した」とみなし、有向エッジを結んでいきます。
今回は24時間以内のツイートでコサイン類似度が0.997以上の場合にエッジを結びました。今回生成したダミーデータは、内容が似ていることが多く、非常に高い閾値を設定しましたが、実際の業務では閾値を0.9に設定しました。
以下コードです。
def calc_cos_similarity(vec1,vec2): #コサイン類似度の計算
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def generate_network(tweets,vectors): #エッジを繋いでネットワークを生成
network = {'nodes':[], 'edges':[]}
for tweet1 in tweets:
network['nodes'].append({'id':tweet1['id'], 'datetime':tweet1['datetime']})
edge = {'source':tweet1['id'], 'targets':[]}
for tweet2 in tweets:
if calc_cos_similarity(vectors[tweet1['id']],vectors[tweet2['id']]) > 0.997: #コサイン類似度が0.997以上
if (tweet1['datetime'] < tweet2['datetime'])&(tweet1['datetime']+timedelta(1) > tweet2['datetime']): #あるツイートから1日以内に投稿されたツイートにエッジを結ぶ
edge['targets'].append({'target':tweet2['id'], 'datetime':tweet2['datetime']})
network['edges'].append(edge)
return network
network = generate_network(tweets,vectors)作成したネットワークグラフをDashを使って可視化していきます。Dashでのグラフの可視化にはDash Cytoscapeを用いるのがインタラクティブに操作することができ便利です。
ネットワーク分析のためのライブラリであるNetworkxを用いて各ノードの中心性を計算し、中心性が高いほどノードのサイズを大きく表示するようにします。また、グラフ上での距離と見かけ上の距離の誤差を小さく表示するアルゴリズムを用いて配置を計算します。
以下がネットワークをDashを用いて可視化するコードです。
#可視化に必要なパッケージのインストール
!pip install dash
!pip install jupyter_dash
!pip install dash-cytoscapefrom jupyter_dash import JupyterDash
from dash import html, dcc, Input, Output
import dash_cytoscape as cyto
import networkx as nx
G = nx.DiGraph()
G.add_nodes_from([node['id'] for node in network['nodes']])
G.add_edges_from([(edge['source'],target['target']) for edge in network['edges'] for target in edge['targets']])
cent = nx.degree_centrality(G) #固有ベクトル中心性の計算
pos = nx.kamada_kawai_layout(G) #配置の計算、グラフ上での距離と見かけ上の距離の誤差を小さく表示するアルゴリズム
cy_edges = [{'data':{'source':str(edge['source']),
'target':str(target['target'])}} for edge in network['edges'] for target in edge['targets']]
cy_nodes = [{'data':{'id':str(node['id']),
'label':str(node['id']),
'size':cent[node['id']]*300}, #中心性が高いほどノードを大きく表示する
'position':{'x':pos[node['id']][0]*1000,'y':pos[node['id']][1]*1000}} for node in network['nodes']]
elements = cy_edges + cy_nodes
#stylesheetでノードやエッジのサイズを設定
stylesheet = [{'selector':'node',
'style':{'width':'data(size)',
'height':'data(size)'}},
{'selector':'edge',
'style':{'target-arrow-shape': 'triangle',
'curve-style': 'bezier'}}] #有向エッジにするために矢印を表示
#appの定義
app = JupyterDash(__name__)
#レイアウトの設定
app.layout = html.Div(
[
html.H1('Twitter Network'),
cyto.Cytoscape(id='network',elements=elements,stylesheet=stylesheet,layout={'name':'preset'},style={'width':'100%', 'height':500}) #Cytoscapeでインタラクティブなネットワークグラフの生成
]
)
#appを実行
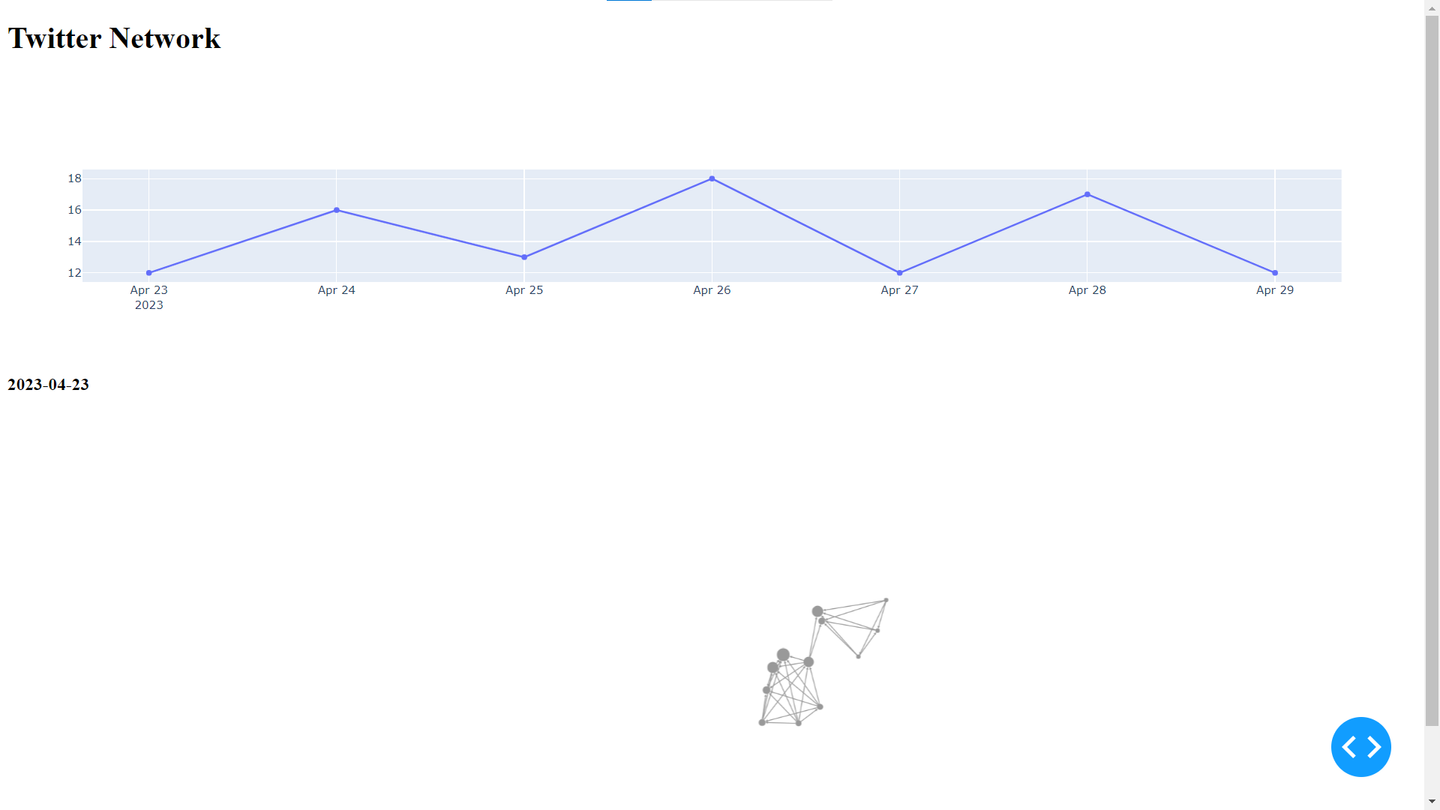
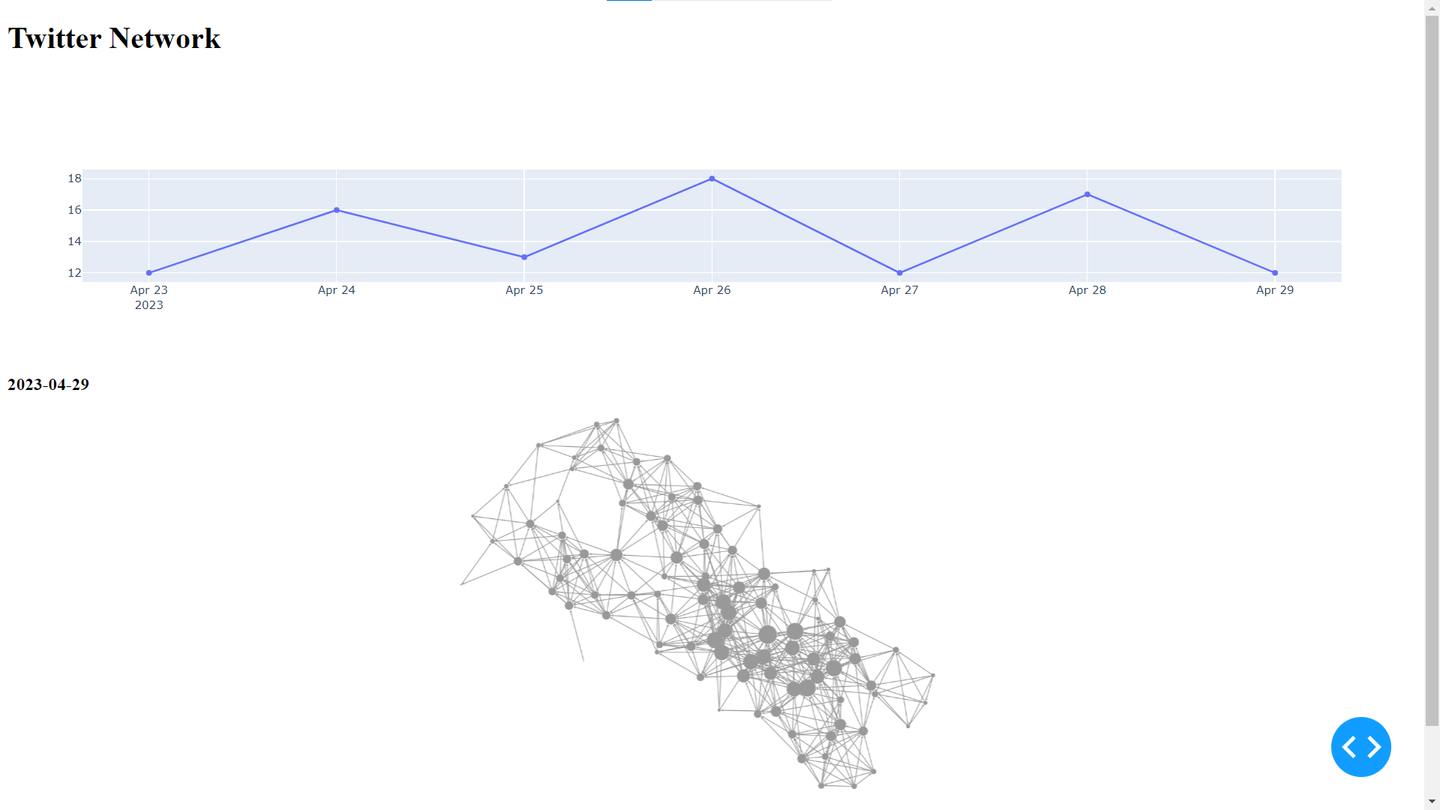
app.run_server(port=4040)また、今回のネットワークグラフは時系列で変化していくものであるため、その変化も可視化したいと思います。
ツイート数の推移を表した折れ線グラフを上でカーソルを動かせば、その日時におけるネットワークグラフを表示するように改良していきます。hoverDataとcallbackを用いることで実装することができます。
from jupyter_dash import JupyterDash
from dash import html, dcc, Input, Output
import plotly
import plotly.graph_objects as go
import dash_cytoscape as cyto
import networkx as nx
#ツイート数の推移のグラフを作成
df = pd.DataFrame(data=tweets)
df['count'] = 1
df = df.set_index('datetime').resample('d').sum()['count'].reset_index()
fig = go.Figure()
fig.add_trace(go.Scatter(x=df['datetime'], y=df['count']))
fig.update_layout(hovermode="x",height=300)
#appの定義
app = JupyterDash(__name__)
#レイアウトの設定
app.layout = html.Div(
[
html.H1('Twitter Network'),
dcc.Graph(id='graph',figure=fig),
html.Div(id='network')
]
)
#ツイート数の推移のグラフ上でカーソルを動かすのに合わせてネットワークグラフも変化するようにする
@app.callback(Output(component_id='network',component_property='children'),
Input(component_id='graph',component_property='hoverData'))
def draw_network(hoverData):
date = hoverData['points'][0]['x'] if hoverData != None else '2023-05-01'
G = nx.DiGraph()
G.add_nodes_from([node['id'] for node in network['nodes']])
G.add_edges_from([(edge['source'],target['target']) for edge in network['edges'] for target in edge['targets']])
cent = nx.degree_centrality(G)
pos = nx.kamada_kawai_layout(G)
cy_edges = [{'data':{'source':str(edge['source']),
'target':str(target['target']),
'visibility':'visible' if str(target['datetime'].date())<=date else 'hidden'}} for edge in network['edges'] for target in edge['targets']] #推移のグラフ上のカーソルの日付より前なら表示、後なら非表示
cy_nodes = [{'data':{'id':str(node['id']),
'label':str(node['id']),
'size':cent[node['id']]*300,
'visibility':'visible' if str(node['datetime'].date())<=date else 'hidden'}, #推移のグラフ上のカーソルの日付より前なら表示、後なら非表示
'position':{'x':pos[node['id']][0]*1000,'y':pos[node['id']][1]*1000}} for node in network['nodes']]
elements = cy_edges + cy_nodes
stylesheet = [{'selector':'node',
'style':{'width':'data(size)',
'height':'data(size)',
'visibility':'data(visibility)'}},
{'selector':'edge',
'style':{'target-arrow-shape': 'triangle',
'curve-style': 'bezier',
'visibility':'data(visibility)'}}]
return([html.H3(str(date)),
cyto.Cytoscape(elements=elements,stylesheet=stylesheet,layout={'name':'preset'}, style={'width':'100%', 'height':500})])
#appを実行
app.run_server(port=4040)今回はSNSにおける影響力を持つユーザーを分析する手法として、ツイート類似度を用いて作成したネットワークグラフを分析するアプローチを紹介しました。
SNSにおいて影響力を持つユーザーを分析することは、ターゲット層の把握や情報拡散力の向上につながり、マーケティングにおいて重要な意味を持ちます。
今後の展望としては、異なるSNS間での情報伝播に関する分析、SNS以外のウェブサイトなどからの情報拡散に関する分析、機械学習による情報伝播や影響力を持つユーザーの予測モデルの構築などが考えられます。
SNSの情報拡散について分析する機会があればぜひ参考にしてみてください!
最後まで読んでいただき、ありがとうございます。
アポロならではの技術的課題に対する取り組みやプロダクト開発の試行錯誤で得た学びなどを定期的に発信していきます。少しでも業界へ貢献できれば嬉しいです。
今後ともよろしくお願いいたします。

/assets/images/9860917/original/6aeaee91-bfdb-4165-b853-ae49093ad674?1657193033)

![]()



/assets/images/11376212/original/6aeaee91-bfdb-4165-b853-ae49093ad674?1669977589)

