こんにちは、MLデータ部データ基盤ブロックの奥山(@pokoyakazan)です。趣味の範疇ですが、「ぽこやかざん」という名前でラジオ投稿や大喜利の大会に出たり、「下町モルモット」というコンビで週末に漫才をしたりしています。私は普段、全社データ基盤の開発・運用を担当しており、このデータ基盤はGCPのBigQuery上に構築されています。そして、データ基盤内の各テーブルは、大きく分けて以下の2種類に分類されます。
- システムDBのデータやログデータなどが、特に加工されることなく連携されている一次テーブル
- 一次テーブルから必要なデータを使いやすい形に集計したデータマート
本記事では、後者のデータマートを集計するジョブを制御するワークフローエンジンを、DigdagからCloud Composerに移行した事例について紹介します。Cloud Composerとは、GCPにてApache Airflowをマネージドに提供するサービスです。
なお、本記事では、Cloud Composer・Apache Airflowそれぞれのバージョンは以下のものとして話を進めます。
- Cloud Composer: composer-2.0.24-airflow-2.2.5
- Apache Airflow: 2.2.5
そのため、記事内で参考情報リンクとして貼っている公式ドキュメントについても、こちらのバージョンのものとなります。
目次
- 目次
- データマート集計ジョブの仕組み
- 各データマートの依存関係について
- 移行前のシステムのデータマート集計方法
- 各マートのSQLファイルからマート間の依存関係グラフの作成
- 並列に処理しても問題ないマートをまとめた集計グループを作成
- 各集計グループごとにマート集計を並列実行
- データマート集計ジョブの課題
- 1つのマートの集計が失敗すると後続のグループに属する全てのマートの集計が停止する
- 一次テーブルの更新遅延がデータマート集計全体の遅延に繋がる
- 集計グループの増加に伴いデータマート集計ジョブの実行時間が長くなる
- DigdagからCloud Composer(Airflow)への移行移行の契機
- Airflowでのデータマート集計方法
- タスクの定義
- タスク間の依存関係の設定
- 一次テーブルの更新待ち処理追加
- Cloud Composer移行によって得られた効果
- Cloud Composerの運用Tips
- Tips1: メタデータの読み込み方法は「読み込まれるタイミング」によって使い分けるSchedulerによ
- DAG解析
- Variablesの読み込みはTop level codeで行わない
- メタデータの読み込み方法の使い分け
- Tips2: DAG・タスクのエラーハンドリングは目的に応じてパラメータを使い分ける1つでもタスクがエラー終了したら保守担当者に架電
- エラー終了したタスクの分だけSlack通知
- Tips3: Composer環境自体の外形監視を設定する
- Tips4: 集計遅延の検知の仕組み採用しなかった方法1: タスクにslaパラメータを指定
- 採用しなかった方法2: DAG・タスクのいずれかにタイムアウト値を設定
- Tips5: プライベートIP環境で構築
- まとめ
データマート集計ジョブの仕組み
以下の記事でもご紹介した通り、マート集計処理の実体はデータ基盤利用者が作成したSQLファイルで、全てGitHubで管理されています。
SQLファイルにはSELECT文のみが記述されており、UPDATEやDELETEといったDMLは記載されていません。
各データマートの依存関係について
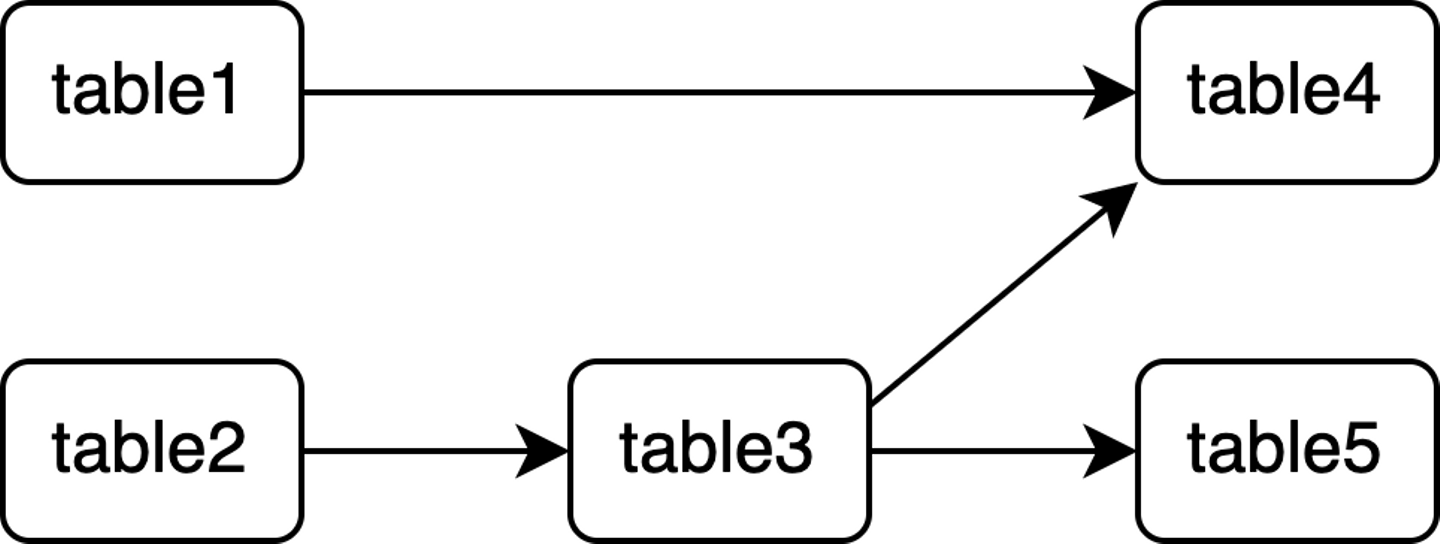
あるマートが他のマートを参照している(依存関係がある)場合、集計の順番を間違えるとデータに不整合が発生してしまいます。例えば、existing_table1, existing_table2という一次テーブルが存在するとし、以下のような集計クエリを持つ5つのマートを構築したい場合を考えます。
table1.sql
SELECT * FROM `project.dataset.existing_table1`;
table2.sql
SELECT * FROM `project.dataset.existing_table2`;
table3.sql
SELECT * FROM `project.dataset.table2`;
table4.sql
SELECT * FROM `project.dataset.table1`
UNION ALL
SELECT * FROM `project.dataset.table3`;
table5.sql
SELECT * FROM `project.dataset.table3`;
この場合、「table3の前にtable2」「table4の前にtable1とtable3」「table5の前にtable3」が集計されている必要があります。
移行前のシステムのデータマート集計方法
Digdagでマート集計する場合、以下の流れで行います。
- 各マートのSQLファイルからマート間の依存関係グラフの作成
- 並列に処理しても問題ないマートをまとめた集計グループを作成
- 各集計グループごとにマート集計を並列実行
各マートのSQLファイルからマート間の依存関係グラフの作成
マート間の依存関係は、各マートのSQLファイル内の、FROMもしくはJOINの直後にくるマート(自己参照は除く)を調べるとわかります。FROM, JOINの後ろに書かれているマートは、SQLを実行するマートよりも前に集計しなければなりません。そのため、「FROM, JOINの後ろのマート」→「SQLを実行するマート」というように依存関係グラフを作成していきます。例えば、上記の5つのSQLからマート間の依存関係グラフを作成すると以下のようになります。
![]()
これをPythonコードで実装していきます。まず、各マートのSQLファイルから以下の正規表現を使って参照先となるマートを抽出します。
(?i)(?<=FROM|JOIN)[\s \n]*`(.+?)`
そして、参照元: 参照先という形のDictを作成します。
{
'table1': [], # table1の依存先
'table2': [], # table2の依存先
'table3': ['table2'], # table3の依存先
'table4': ['table1', 'table3'], # table4の依存先
'table5': ['table3'] # table5の依存先
}
並列に処理しても問題ないマートをまとめた集計グループを作成
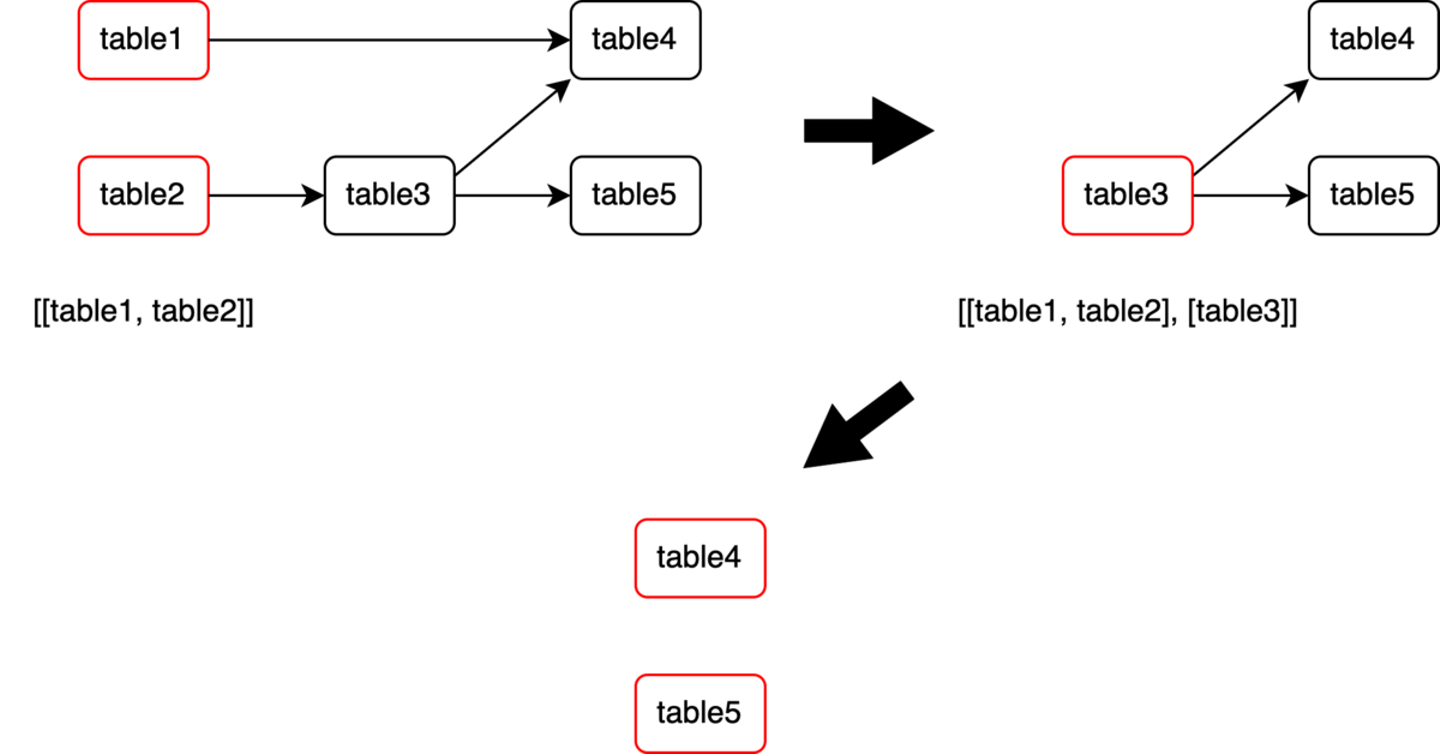
作成した依存関係グラフを利用し、マートの集計順序を担保したまま、可能な限り処理を並列化していきます。具体的には、並列実行しても問題のないマート同士をグループ化します。まず、親ノードがないマート群をリストに追加し、追加したマートをグラフから削除します。そして、もう一度親ノードがないマート群をリストに追加し、追加したマートをグラフから削除…というのを繰り返していきます。
![]()
結果として、以下のような集計グループのリストができあがります。
[[table1, table2], [table3], [table4, table5]]
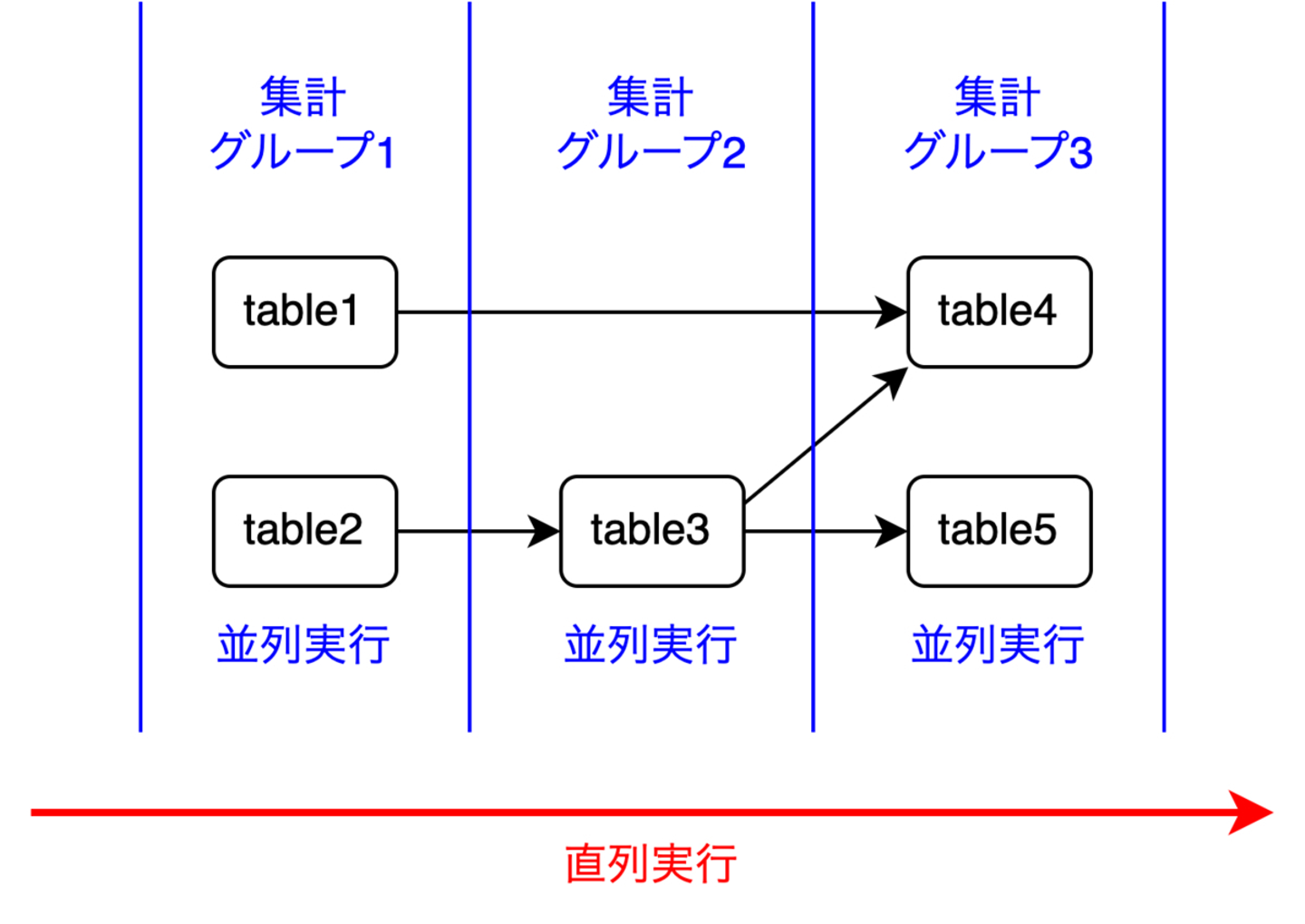
各集計グループごとにマート集計を並列実行
各集計グループ(マートのリスト)は、リストの先頭から順番に実行可能で、同じ集計グループ内のマートの集計は並列化できます。結果として、集計の流れは以下のようになります。
- [table1, table2]を並列実行
- [table3]を実行
- [table4, table5]を並列実行
![]()
データマート集計ジョブの課題
上記の方法で集計すると、依存関係に沿った集計順序が担保され、同じ集計グループ内では処理を並列化できます。ただし、この方法にはいくつか課題も存在します。
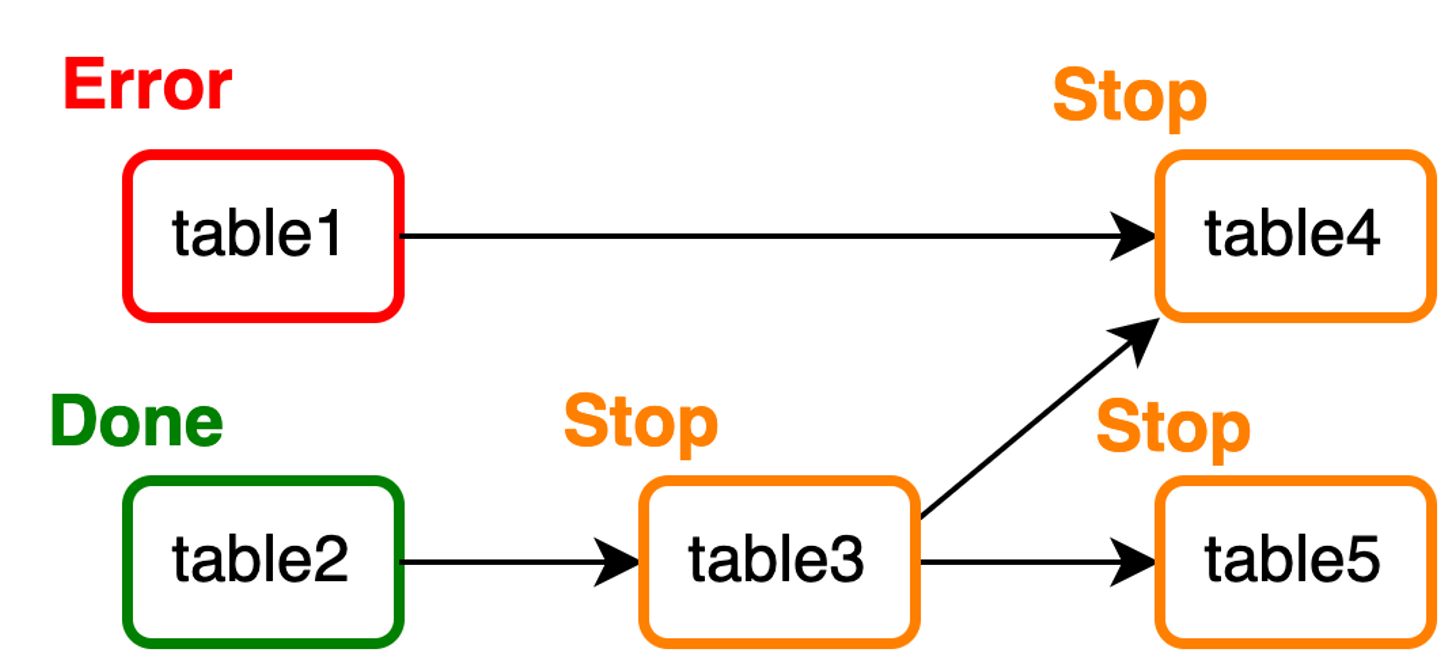
1つのマートの集計が失敗すると後続のグループに属する全てのマートの集計が停止する
あるマートの集計ジョブがエラー終了した場合、このマートと同じ集計グループに属するマートについては、処理が並列化されているため影響を受けません。しかし、失敗したマートが属する集計グループより後のグループは、全て処理が停止してしまいます。例えば、table1の集計がこけた場合、以下のようになります。
- [table1, table2] → table2は実行される
- [table3] → 実行されない
- [table4, table5] → 実行されない
集計グループ単位で見ると、先頭の集計グループの処理が失敗しているので、2番目と3番目の集計グループの処理は開始されません。そのため、table1に依存しないtable[3, 5]の集計は実行されてほしいところですが、これらのマートの集計も停止してしまいます。
![]()
一次テーブルの更新遅延がデータマート集計全体の遅延に繋がる
の更新が遅延している場合、以下のようになります。データマートは、一次テーブルから必要なデータを使いやすい形に加工し抽出したテーブルです。そのため、一次テーブルが更新される前に、一次テーブルを参照しているマートの集計が行われるとデータの不整合が発生します。そこで、一次テーブルを参照するマートは、一次テーブルが正常に更新されるまで集計開始を待つ必要があります。さらに、集計グループ内の1つのマートのみ集計を停止させることはできないため、その場合は集計グループ自体の実行を停止(グループ内の全マートの集計を停止)させる必要があります。つまり、なんらかの理由で一次テーブルの更新が失敗・遅延すると、この一次テーブルを参照するマートが属する集計グループ内全てのマートの集計タスクが実行されません。また、一次テーブルに依存するマートの集計タスクは先頭の集計グループに属することが多いため、一次テーブルの更新遅延はマート集計ジョブ全体の大幅な遅延に繋がります。例えば、一次テーブルexisting_table1の更新が遅延している場合、以下のようになります。
続きはこちら
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)

/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)


/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)
/assets/images/7661308/original/3a023d97-0ee4-488d-a826-b9ee662c0ee1?1632994701)