/assets/images/757014/original/13a2cae7-101c-41ce-a210-055d743ae23c.png?1478761990)

シェアリングテクノロジー株式会社's job postings
はじめに
弊社の看板サイトである「生活110番」のリニューアルが終わり、本年9月上旬に無事にオープンしました。今回のWebサイト・リニューアルで何を考え、何を行ったのかをエンジニア視点でブログに綴ります。
このブログに書かれた内容はすべて弊社内のラボで実証実験を経て、自分たちですべて組み上げたDIYサーバー構成についてです。読んでみて興味のあるエンジニアさんはぜひ弊社に一度遊びに来てください!
開発スタッフからのリクエスト
将来性や開発のやりやすさ等を考えて以下のような構成で開発をはじめました。
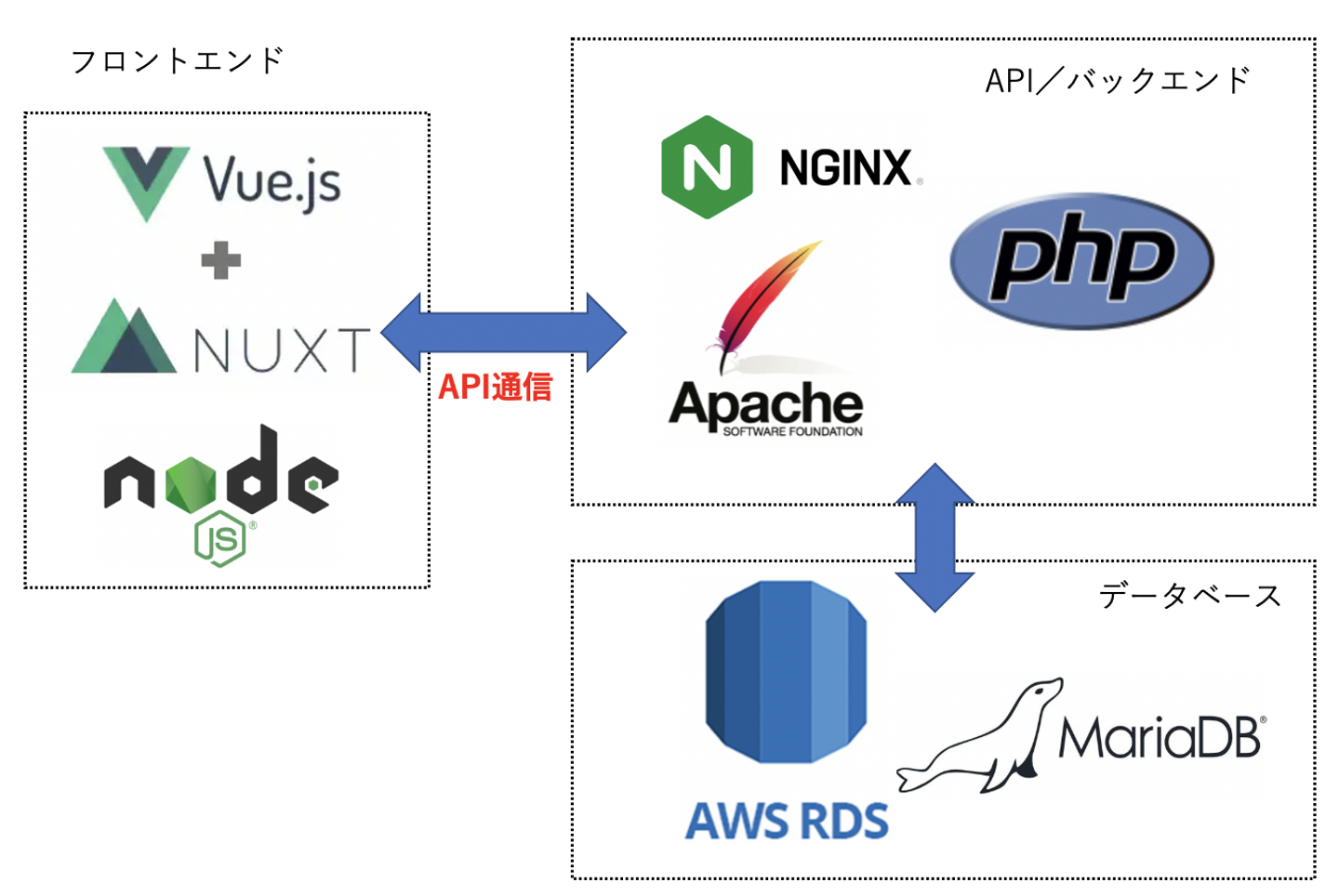
Webサイトは、例えばWordPressのようなCMSで開発すると、PHPプログラミングからデータベース接続、記事取得クエリの実行、デザインテーマのHTMLコーディングまでのすべてを1つのソースとして扱って開発していました。PHPプログラマとコーダーが一緒になって開発します。非常に密な状態であり、疎結合ではありません。
しかし、最近はVue.JS、React.JSのようなJavaScriptフレームワークの登場により、フロントエンド側とAPI側を完全に分業して開発できるようになりました。Git等でコンフリクトすることが激減し、フロントエンド側とAPI側の打ち合わせもAPI仕様を中心に行えるため、非常に中身の濃い話し合いが短時間で行えるようなりました。制約から開放されたような雰囲気もあります。依存関係がAPI仕様にのみ集中し、その他はサーバー環境を含めて疎結合ですね。フロントエンド側はA社がAWS上で運営し、API側はB社がNetlifyで運営するなんてことも不可能ではありません。
さらに、Webサイトをリニューアルするにあたり、フロントエンド、API開発の各スタッフから以下のようなリクエストを受けました。
フロントエンド側
- Vue.JS/Nuxt.JS(SSR)で開発したい
- Gitから自動でサーバーへデプロイして欲しい
- CI/Jestで自動テストしたい
API側
- PHPで組みたい
- PHPUnitで自動テストしたい
- Dockerを使いたい
- RDS(Mariadb)で組みたい
これらの要望を受けて考えたのが、以下の構成です。
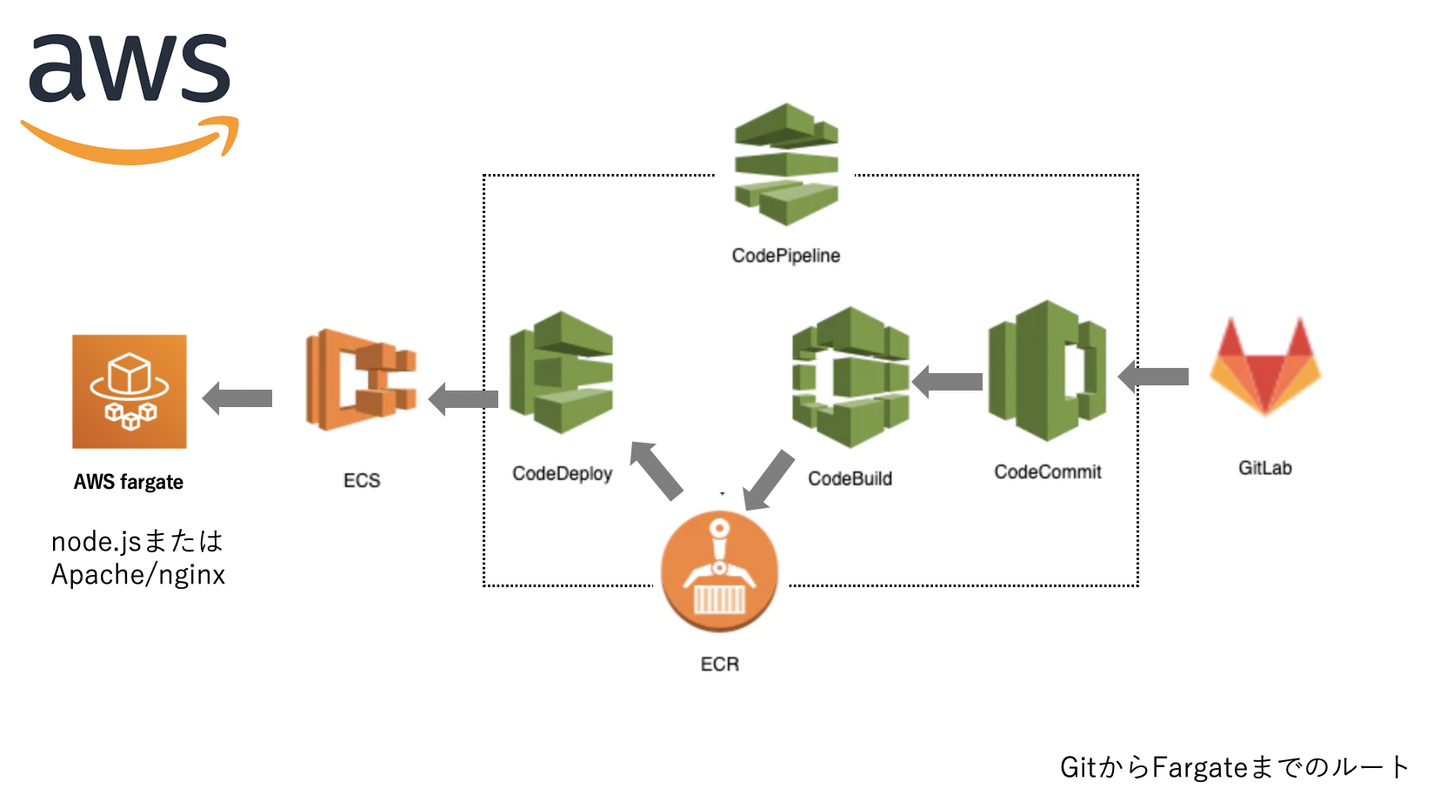
Gitlab/GithubへソースをpushしてMasterへマージすると、CodeCommit〜CodePipelineでECSまで自動デプロイされます。これでサーバーにログインして、git pull origin masterする手間が省けます。この構成をVue.JS/Nuxt.JSのフロント側用と、API側用のHTTPサーバーをそれぞれに独立した形で用意すればOKです。
また、開発環境のDockerをそのままfargate/Docker上で動かすことができます。fargate/Docker/ECSにより混雑時は自動でWebサーバーも追加されるため、冗長化も行えるようになりました。
安全性からのリクエスト
最近はWebサイトが乗っ取られたりする犯罪が横行しており、ニュース等でもよく目にします。主に海外からの不正なアクセスを未然に防ぐため、AWSのWAFを導入しました。WAFの導入は割と手間がかかるものが多いのですが、AWSでは簡単に設定することができました。
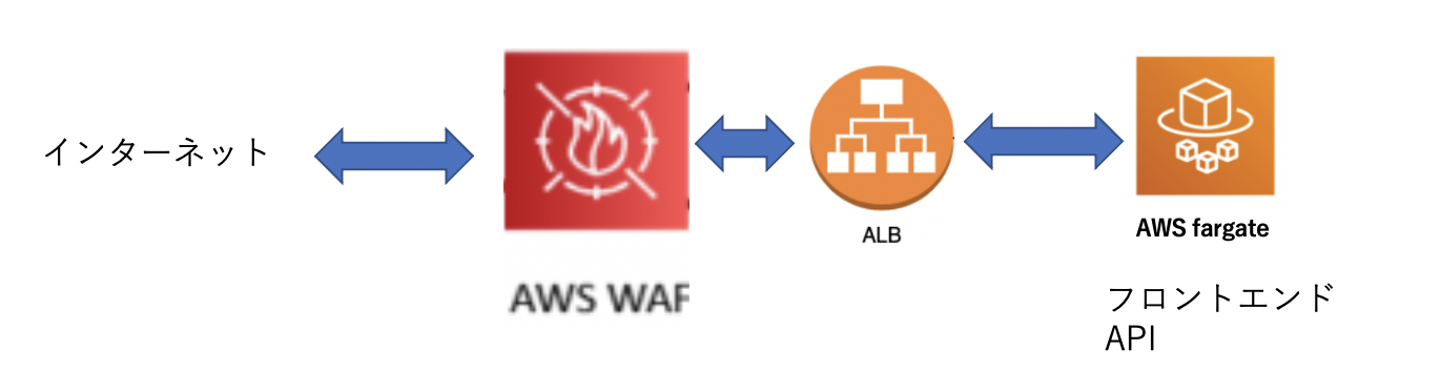
- 正常なBotなのか否か
- 特定の国からアクセスを遮断する(あの国たちです)
- 異常な回数のアクセスを防ぐ
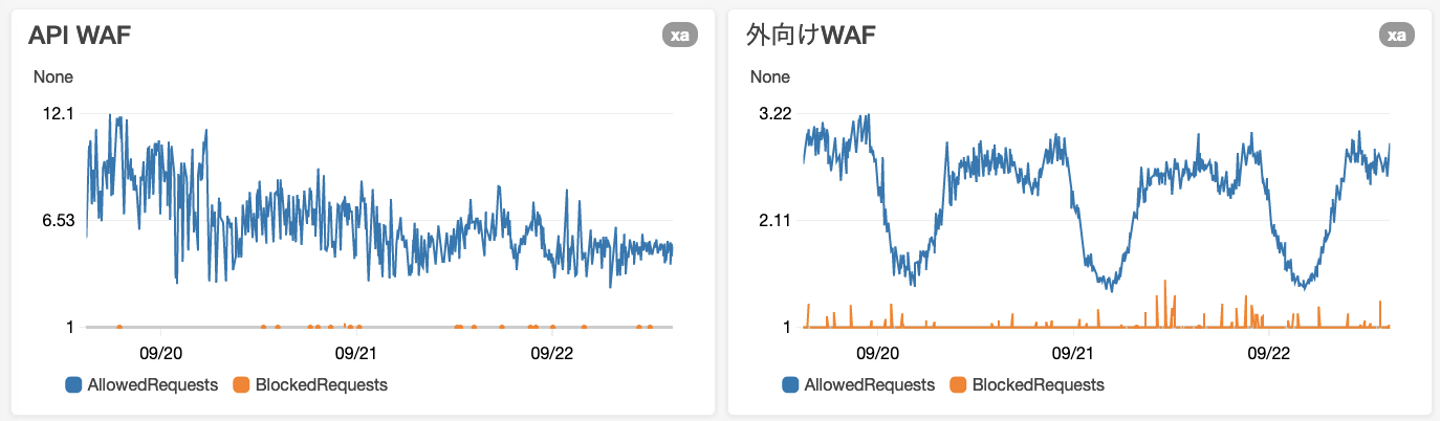
レスポンスの優れたWEBサーバーにしたい
Staticな素のHTML/CSSだけで構成されたWEBページの多くは、サーバーからのスピードが速いです。Vue.JSやAPIを利用しながらもStaticなHTMLのWebページのようなスピードを得るには、キャッシュサーバー(AWS CloudFront)を利用するといいですね。
- StaticなHTMLのWEBページのように速いレスポンスが欲しい
- API/データベースへのアクセスを減らして負荷I/Oと費用低減したい
- アクセス過多になっても安定して稼働してほしい
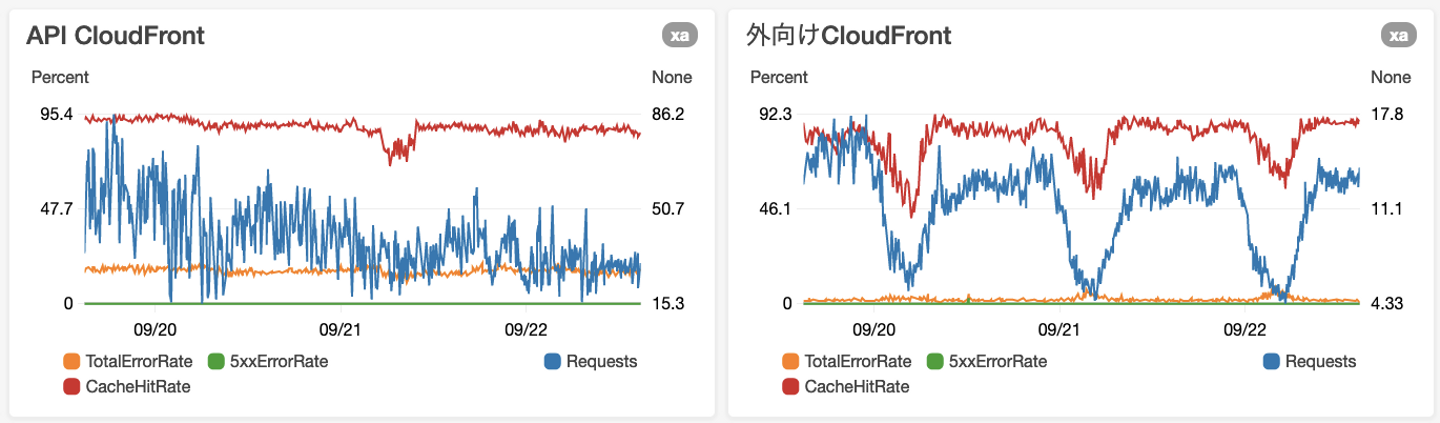
上図にように、フロントエンド側、API側の両方にAWS CloudFrontを導入しました。赤い線がキャッシュを返しています。非常に高いレートでキャッシュを返却していることがわかります。このキャッシュをみなさんのブラウザに返却すれば、データベースやPHPを動かす必要はありません(※例外あり)
安定運用のためにサーバーを監視したい
サーバーは放置しているとどんなトラブルに見舞われるかわかりません。突然停止してしまったり、データの消失、異常なレスポンスを返したりします。企業にとっては大きなダメージが出てしまいます。
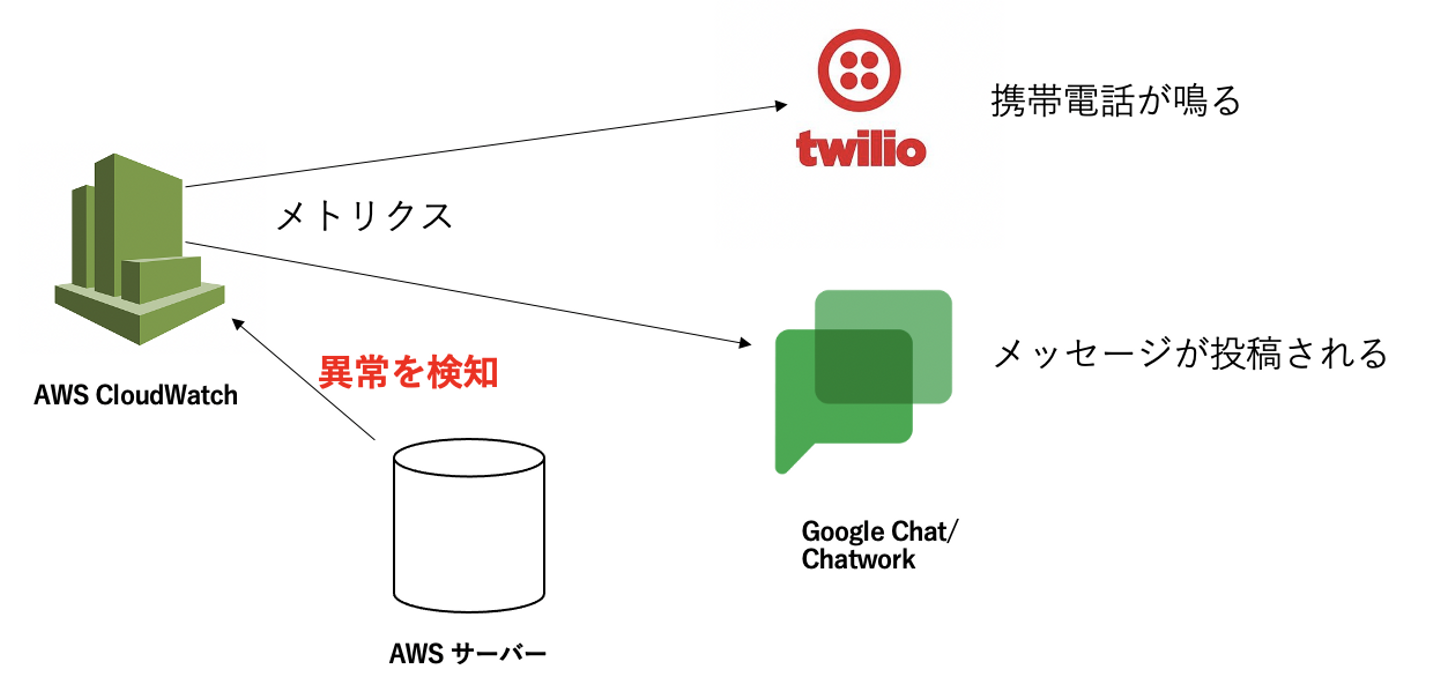
- 異常を知らせるメトリクスのしきい値を設定する
- Lambaを書いて外部サービスと連携する
- 外部サービスからサーバー保守スタッフに異常を通知する(電話とメッセージ)
AWS CloudWatchが登場する以前は、Zabbixなどのツールを用いてサーバーを監視していました。だいたい同じうようなことができますが、CloudWatchはなんといってお手軽です。サーバーダウンや急なアクセス過多が発生した場合も、瞬時にわかります。
※電話はTwilio以外にもAWS Callがあります。
最後に泣いた苦労話
サイトがオープンしてからしばらくして、サーバーを監視するCloudWatchから、RDS(データベース)のCPUが異常に高くなって、アラートが頻繁に届いたことがありました。
アクセス過多になるとAWS ECS(コンテナ管理)によりWebサーバーを自動で追加しますが、個々に立ち上がるWebサーバーの負荷に応じて、設定数上限まで自動で追加されます。注意すべき点として、それに応じた数のデータベースへのリクエスト数が増加します。Webサーバーを増やし続ければOKかと言うとそうではなく、逆にDBへの負荷を高めてしまいます。
- ECSによる自動追加できるサーバー数のしきい値
- 各Webサーバーの負荷に対するしきい値
- RDSに必要なスペック
これらのしきい値やスペックが複雑に絡み合っています。細かなチューニングを実施しなければ、適正値まで近づけることができません。

上図:Webサーバーの台数、各Webサーバーの負荷状況、RDSの負荷状況
以上が、バックエンド、インフラエンジニアが実際に職場で行っているお仕事の一例になります。最後まで読んでいただきましてありがとうございました。シャアリングテクノロジーでは一緒に働くメンバーを募集しています。気軽に遊びに来てくださいね!!
AWSの大規模構成でエンジニアが泣いたお話(泣)

/assets/images/757014/original/13a2cae7-101c-41ce-a210-055d743ae23c.png?1478761990)




/assets/images/6171785/original/13a2cae7-101c-41ce-a210-055d743ae23c.png?1611898482)
