みなさん、こんにちは!
プログリットでエンジニアマネージャーをやっている島本です。
この度、プロダクト開発部でブログを始めることになり、その最初としてプログリットのプロダクト開発部のエンジニアがどんなことをやっているのか紹介させてください。
プログリットについて
プログリットは
世界で自由に活躍できる人を増やす
というミッションを掲げ、英語コーチングを提供しているスタートアップです。
プロダクト開発部の紹介
プロダクト開発部の紹介です。
プログリットは今期で5年目なのですが、僕が所属するプロダクト開発部が部として立ち上がる前はユーザ向けのアプリ開発などはしておらず、市販のものなどを組み合わせてサービスを提供しておりました。
契約していただくユーザが増える中、ユーザ体験をより良くしたい、ユーザからのデータを分析して、サービスのクオリティを上げたい、と考えるようになり、外注なども試したりしていたのですが、「やはり社内で組織を作るのがベストだろう」と判断し、発足にいたりました。
開発しているアプリについて
![]()
開発しているアプリは現在、以下の2つを開発しており、英語コーチングのユーザに利用していただいております。
学習管理アプリ
ユーザの学習進捗を入力していただき、プログリットのコンサルタント(社内でコーチングを行うメンバーのこと)がユーザの状況を把握するためのものです。
学習アプリ
ユーザにシャドーイングや多読などの学習を行っていただくためのアプリです。
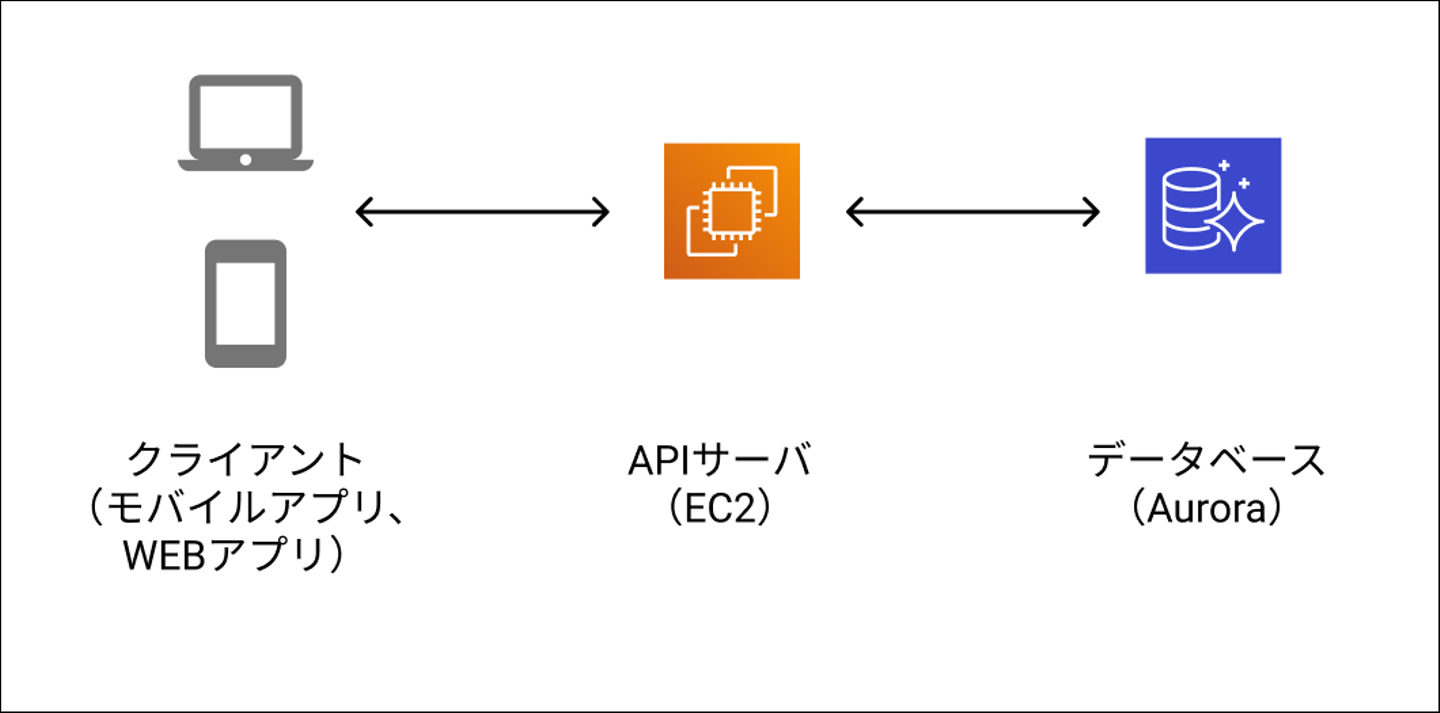
全体構成
仕組みは比較的シンプルな「クライアント(モバイルアプリやWEBアプリ)」「WEBサーバ」「データベース」の3層構造です。
![]()
インフラは基本的にAWSで、一般的なEC2やRDS、SMS、SNSなどを利用しています。
こちらを2020年初期から開発を開始し、同年の夏頃に実際に使い始めていただいております。
データ分析したい!
先程書かせていただいたとおり、「ユーザからのデータを分析」に関してなのですが、プログリットは経営メンバーを含め、 数値化した目標を置いて、PDCAを回す という考えが浸透しています。
少し例を上げると、
- 経営メンバーが毎月、全社会議で、先月の売上や英語の伸びの達成度を細かく伝える
- メンバーのモチベーションや会社に関する評価を把握するための質問表を3ヶ月毎に回答し、結果の振り返りを行っている
- 社員評価も定性、定量目標を置いて、それに対する結果を含めている
という感じです。
この土台もあり、プロダクト開発部でも数値への意識が強く、プロダクトの開発当初からデータを分析できるようにしたい、という考えがありました。
データ基盤の開発にあたって
ここから技術的な話なのですが、データ分析するための基盤を作ると言っても、方法は様々です。CSV出力してExcelで処理することもいれば、BIツールを導入していることもあるかと思います。
どれが良いかはチームの状況、会社の状況、要件、かけられるコストなどによると思いますが、今回はプログリットの状況を説明しつつ、僕らが判断した経緯、そこから得た学びなどを紹介できればと思います。
状況
まずは分析を行う上での要件を整理します。
- なるべく安価に抑えたい
- 将来的にプロダクトのデータベース以外のデータソースを入れる拡張性を残したい
- PdM(プロダクト・マネージャー)などの非エンジニアも触ることができて、レポートを作れるようにしたい
- 更新頻度は1日1回ぐらいで良いが、データの更新は自動的に行いたい
次に仕組みを作る上での要件を整理します。
- サービスで利用しているDB(AWS Aurora)に直接クエリーさせたくない
- APIサーバと同じサーバを使いたくない
- このために専用のサーバを管理したくない
結論:Google BigQuery
いろいろ考えたのですが、Google BigQuery を使うことにしました。
Google BigQueryをは、Googleの提供するサーバレスなデータウェアハウスです。特徴としては
- 安い
- ストレージ10GBまで無料、1TBまでクエリー無料。そこからも安い
- SQLで分析が行える
- ツールやライブラリが豊富
- Googleデータポータルから簡単に接続できる
という感じで、プログリットの規模でも手軽で使いやすく、今回の目的にもマッチしていると考えました。
データの移行どうする?
BigQueryを使うところが決まったところで、大きなタスク・課題は どうやってデータを持ってくるか ということになります。
こちらも方法は
- 定期的にCSVでエクスポート、BigQueryにアップロード
- Zapierのようなサービス接続要サービスで接続する
- ETL(Extract/Transform/Load)ツールを導入する
等々、いろいろあると思うのですが、プログリットでは
Embulk
を使うことにしました。
少し、サイトのプレビュー用カードが寂しい😅ので、特徴を書き出すと、
- JavaベースのオープンソースETLツール
- オープンソース
- 入力元、出力先もデータベースだけでなく、いろいろなWEBサービスや通常のCSVファイルなどに対応している
- プラグインによる入力元や出力先の拡張が可能
理由としては以下のような感じです。
- 入力元(AWS Aurora)と出力先(BigQuery)のプラグインがある
- 構成がシンプル
特に 構成がシンプル な点ですが、設定ファイルもYAMLファイル1つで、全体的な仕組みも分かりやすいです。
今のプログリットには会社の成熟度やデータ量を考えても程良いツールだな、と感じています。
サーバの課題
Embulkは僕らの規模感にはとても良い頃合いのツールなのですが「APIサーバと同じサーバを使いたくない」「このために専用のサーバを管理したくない」というのが要件があったので、次の課題は どうやって稼働させるか? という話になります。
サーバを使いたくない、ということから、最初はAWS Lambdaを考えたのですが、そもそもLambdaは「何かしらリクエストを受けて、それに対して何かを返す」というものなので、ちょっと目的が異なるな、と思って却下しました。
そんな中、他のインフラと同じAWSで構築する方がいろいろと楽だな、と考え、AWSのサービスを見ている中、AWS Fargateが良いのではないかな、と思い、使うことにしました。
AWS Fargateについて
⬆️ のAWS Fargateの公式サイトに
Fargate ではサーバーのプロビジョンと管理が不要となり、アプリケーションごとにリソースを指定してその分のみ料金を支払うことができ
とあるように、簡単にまとめると
- サーバを明示的に構築しなくて良い
- 使用した分しか課金されない
- Dockerのイメージを使用可能
- スケジュールが必要なバッチジョブも実行可能
となっており、今回のように1日1回だけバッチジョブをWEBサーバなどとは切り離された環境で走らせる、という目的としてはとても合致していると思います。
中身の仕組みとしては、Embulkの実行環境および、設定ファイルを組み込ませたDockerイメージを作成し、そちらをFargateから定期的に実行させています。
結果
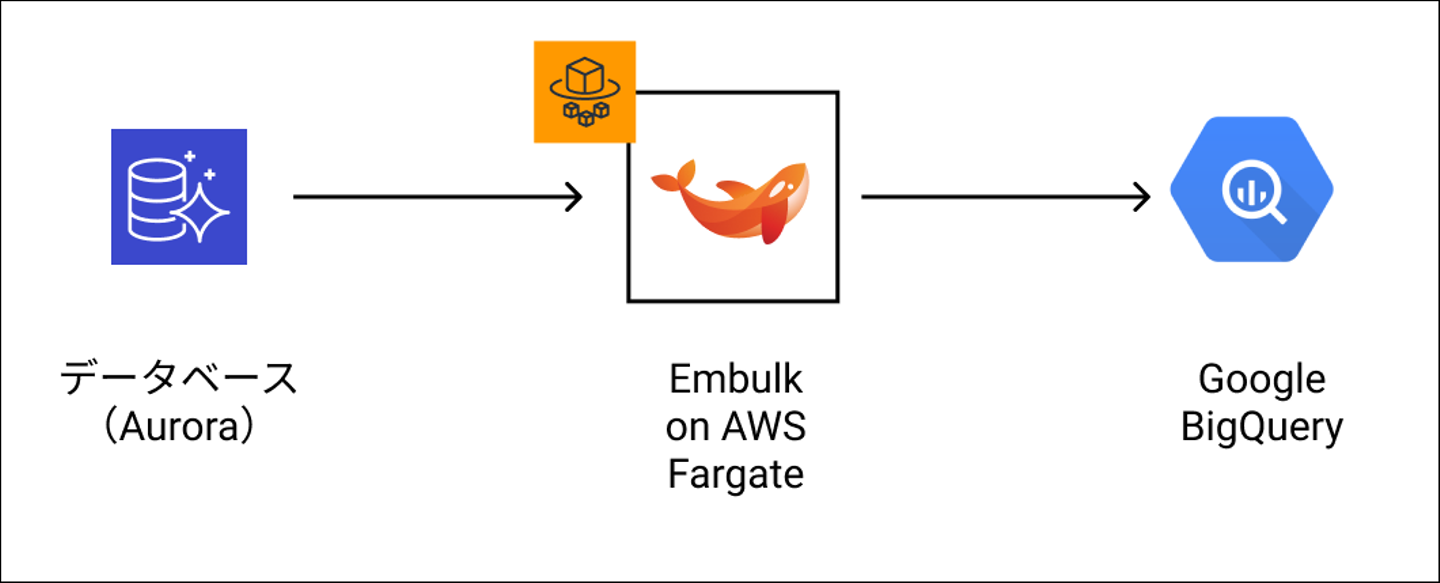
最終的には以下の図のような構成になりました。
![]()
- AWS Fargateの定期実行(Scheduled Task)でEmbulkを起動
- 起動したEmbulkがアプリのデータベースであるAWS Auroraに接続、データを抽出。
- EmbulkがBigQueryに接続し、上記データをアップロード。
という流れになりました。
こちらを毎日、自動実行させておりますので、翌日にはPdMやエンジニア側でBigQueryからデータを抽出し、可視化したり、分析することができております。
順調に運用も回り始め、実際にPdMやデータアナリストのメンバーがデータの可視化や分析などを行っております。プロダクト開発部としても可視化されたデータを週1の定例会議で振り返りに利用したり、最近では、ユーザのデータからそれぞれの学習進捗と英語力の成長の分析も始めております。
今回行ったことのまとめ
いろいろな細かい話も交えながら話してしまったのですが、今回行ったことをまとめますと
- アプリのデータ分析のためにデータベースのデータをBigQueryにアップロードし分析
- データのETLツールとしては構成がシンプルで分かりやすいEmbulkを利用
- Embulkの動作するインフラ環境としてDockerイメージを作成し、AWS Fargateで動作
次は別サービスで利用しているStripeの決済に関するデータやWEBサイトからの流入などもBigQueryにつなげて横断的に分析をしようとしています。
今回紹介させていただいた土台が存在する以前は想像にしかなかったような環境ができつつあります。
実装をしてみて感じたこと
今回初めてデータの基盤(と呼べるような代物でないもしれませんが)をゼロから考えて作ってみて思ったことは…
要件を満たすものであれば、カッコ良くなくてもよい
今回の仕組みは「特別カッコ良い」とか「先進的」なものではないと思います。
より豪華なBIソリューションを入れることも可能でしょうが、会社やプロダクトの開発に携わる方々のスキルセットによってはやりすぎな場合もありますし、反対に価値が見出せていない状態だと費用対効果が悪くなってしまう場合もあると思います。
今回のように自分たちの身丈にあっていて、要件を満たすものを選ぶことが肝要と考えます。
目的や技術スタックによってはプロダクト本体から切り離すことも重要
今回は使いやすさからEmbulkやFargateを選びましたが、提供しているサービスの部分とは良い感じで切り離せた状態で作れたと感じています。
まず、本来ユーザへ提供するサービスの部分とは目的が異なる分析のための仕組み(コードやライブラリ)をWEBサーバの中など入れずに済みました。少し浅い考えだと本体にBigQueryへアップロードするためのコードを入れて、後々メンテナンスしにくくなる状況になりかねなかったな、と思います。
また、EmbulkはJavaとRubyベースの仕組みなのですが、どちらもプロダクトで使っていないようなものになります(サーバはPHPで、AndroidアプリはKotlinです)。そのため、実行環境をWEBサーバと混ぜると、「JavaやRubyもサーバにインストールするのか」というと、サーバの中が異なる目的で汚れていってしまいます。今回はDockerとFargateで、ある種「閉じた」状態を作ることができ、構造として分かりやすい構造になったと思います。
プログリットプロダクト開発部の技術的な側面を紹介させていただきました。
いかがでしたでしょうか?



/assets/images/4144660/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1569914911)





/assets/images/6571325/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1618570231)


