
What is AWS DeepRacer?
It is a miniature racing car that is 1/18th of a real car in term of scale*1. Furthermore, it comes with different type of cameras and sensors that enable autonomous driving. Following are the available sensors (image courtesy of Amazon Web Service):
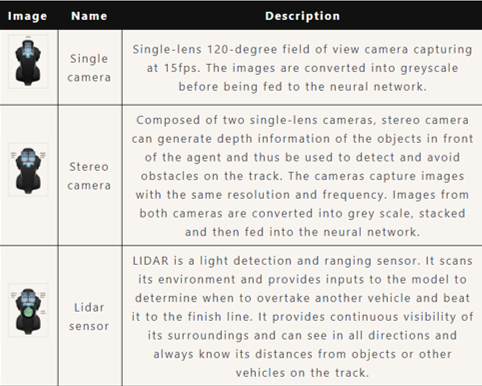
The sensors sample rate is 15 Hz (15 samples per second).
Beside the sensors, the car itself can run up to 4 m/s with maximum steering angle of 30 degrees.
What is reinforcement learning?
Reinforcement learning is a type of machine learning that is capable of planning and decision making. It is one of the big field of research in AI, if you want to know more about it from the ground up, I recommend the book called Reinforcement Learning: An Introduction*2. Below is a diagram showing a general reinforcement learning schema:
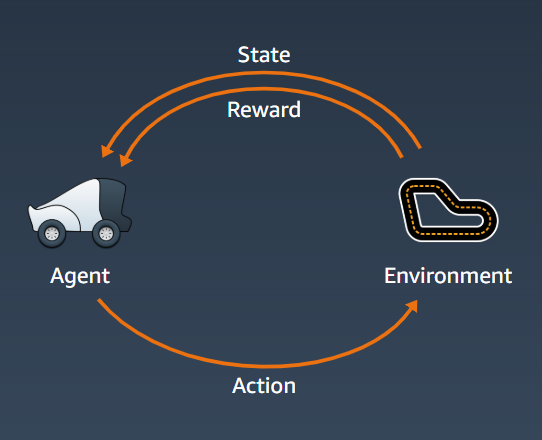
Our agent here is the DeepRacer car. Environment is the actual racing track. Our agent percepts or sees the environment through its sensors, this perception becomes the state of the agent. Then it will perform actions based on its internal set of rules (or model).
The motivation for the model to try to perform better is based on the reward. The model can be a deep learning neural network, trying to approximate the best policy. A policy is a function that map the state and action with highest possible rewards. For example, the rewards can simply be finishing the track, then the policy (agent/model) that manage to finish the track will be awarded higher rewards.
For our current problem, the actions are discrete and separated into 2 groups: steering angle and speed. Steering angle range is 1 - 30 degrees with granularity options 3, 5 or 7. Speed range is 0.1 - 4 ms with granularity options 1, 2, 3. Number of actions is based on granularity only. For example with steering granularity of 3 and speed granularity of 2 will results in total of 3 * 2 = 6 actions.
To actually approximate the best policy, AWS uses PPO (Proximal Policy Optimization)*3*4 method to train the DeepRacer. The underlying neural network is a simple n-layer convolution neural network (CNN). n here can be 3 or 5 in our case.
There are a few parameters we received during training that can be used to calculate the reward functions:

The social distancing F1 race
To the future generation that is not familiar with the word ‘social distancing', this race happened amidst the CoVid-19 virus outbreak. To prevent its spread, we need to social distancing ourselves. This race is done entirely online in the virtual circuit. This is our race track, called Circuit de Barcelona-Catalunya, which is the reproduction of the official F1 Spanish Grand Prix track:

We will refer to this track as the F1 track.
We also do a time-trial focus on this track, called The 2019 DeepRacer Championship Cup:
We will refer to this track as the 2019 track.
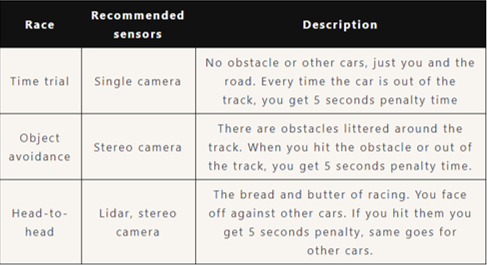
So a time-trial is one of the 3 types of race available:
The ‘rewarding’ journey to the finish line
We had options to customize our agent itself or our reward function and we found out that they are equally important.
The first trial
Firstly we just wanted to make a functional agent to get a feel of how things work. Our first agent was a single camera, 3 layer CNN, max speed 1 m/s granularity 3, max steering angle granularity 3. Our reward function was focusing on stay in the track and avoid steering too much, hence the parameters we used in the function were: all_wheels_on_track, track_width, distance_from_center, steering_angle. And voila! It worked albeit the car was very slow.
The trial and errors
We then tried to play around with the reward function, testing from negative rewards to super simple rewards like just speed and progress.
Some trials worked and some did not. Some never learned:
We started to diverge between the F1 track and the 2019 track. We wanted to try all 3 types of race for the F1 while focus on time trial for the 2019.
The overall trend for both tracks was adding speed multiplicative rewards. But for the F1 track, we actually tried to simplified both the rewards and the agent action space while for the 2019 track we tried to overfit the agent with the optimal path.*5
Tips: you can pre-train a model on easier tracks for it to learn the basic, then clone that model to train on harder tracks.
The realization
Up til now, we had not touch the agent much beside trying to increase its speed and increase the granularity to maximum as we thought it would help the agent to be more flexible and better. However, with great power (number of actions) comes great responsibility. Responsibility, our model had none. It was drunk driving.
The biggest jump in the leader boards for the F1 track was went we crank the speed to maximum and reduce the action space as well as the maximum steering angle. This is our best model action space:
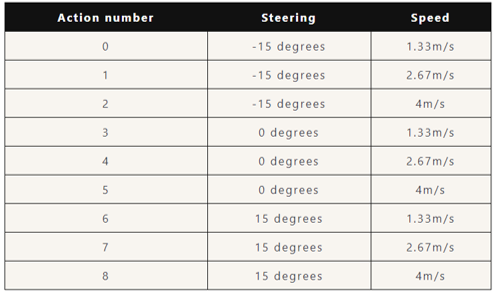
Beside the task specific reward (try to avoid obstacles and other cars), our reward function utilized a speed multiplicative coefficient. So whatever our reward was, it would be multiplied by the current speed. We also gave the agent a big fat reward once it reached the finish line.
The 2019 track also saw many increments. We obtained the optimum path*6*7 by assigning each waypoint a neuron and the sum of distance between each neuron as the loss function to let them converge (minimize the loss). Below was the optimum path for this track after 20K epochs, which was also the shortest path ever possible(the blue line). Now the agent only needed to learn to drive closer and closer to the optimum while remain fast. There were some other algorithms that calculated optimum racing line differently, but here we used the shortest path as our optimum. Below was our calculated optimum path (blue dots) for the 2019 track:

The finish line
Here we are, at the end of the road. The final result of the F1 race was this:
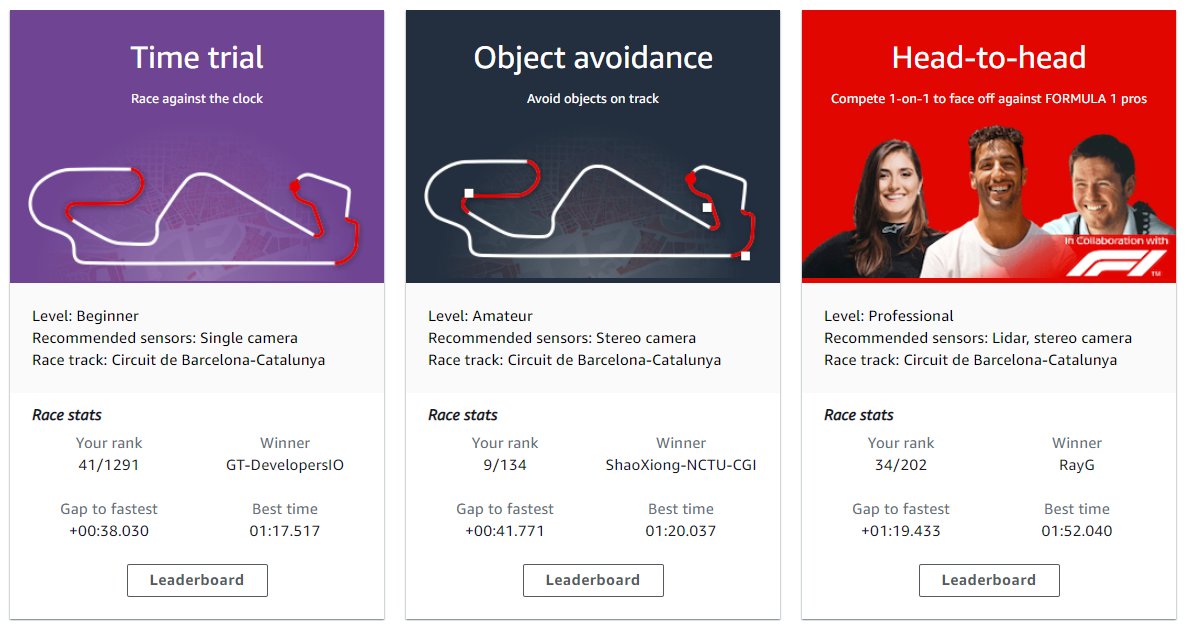
Not too shabby for our first time entering AWS DeepRacer. We are even in top 9 for object avoidance, and hence here is the video for that:
Best obstacle avoidance F1
Our 2019 track also sees promising result, we are 67/341 for the time trial, here is the video:
Our lesson
Training an artificial intelligent agent is not much different from training a baby, you need to be careful and watchful. Give it rewards correctly or else it will have a wrong motivation. Designing the agent and its action space is also equally important!
Authors: Pham Tan Hung (F1 race), Yun Yi Ke (2019 race)
*1:Amazon. (2020). Retrieved from https://aws.amazon.com/deepracer/
*2:Sutton, R. S., & Barto, A. G. (2011). Reinforcement learning: An introduction. Retrieved from https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
*3:Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347. Retrieved from https://arxiv.org/abs/1707.06347
*4:Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017a). Proximal Policy Optimization. Retrieved from https://openai.com/blog/openai-baselines-ppo/#ppo
*5:Lecchi, S. (2009). Artificial intelligence in racing games. Paper presented at the 2009 IEEE Symposium on Computational Intelligence and Games
*6:Xiong, Y. (2010). Racing line optimization. Massachusetts Institute of Technology,
*7:Vesel, R. (2015). Racing line optimization@ race optimal. ACM SIGEVOlution, 7(2-3), 12-20.

/assets/images/156717/original/ae6af5fc-8162-4e6e-aa8d-965069a69079.png?1437026902)
/assets/images/3259399/original/ae6af5fc-8162-4e6e-aa8d-965069a69079.png?1543224435)


