
GMOメイクショップ コアグループ エンジニアの越川です。 前職あたりから、AWS関連の仕事をさせてもらうことが多くなってきていて、 弊社の新システムの構成や構築を設計経験させていただきました。 今回は、監視について記載させていただきます。
1. 全体構成図
早速ですが、今回構築した全体図から
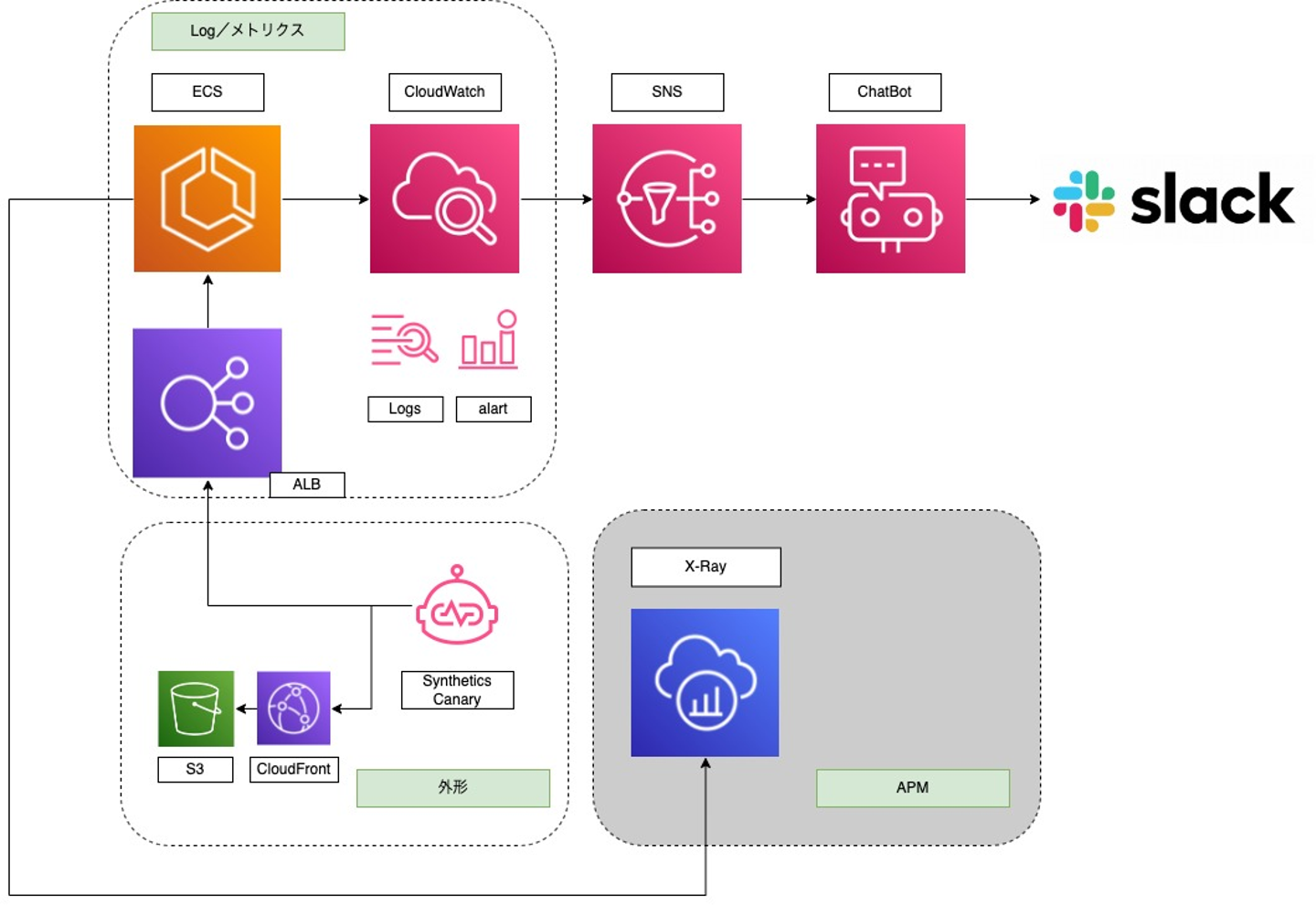
監視の全体イメージ
2. 監視対象
今回導入した各項目は後述いたします。
3. ログ監視
現行システムはCloudWatchの料金が課題の一つとなっておりました。 そのため、今回の構成では、以下の整理を行いました。
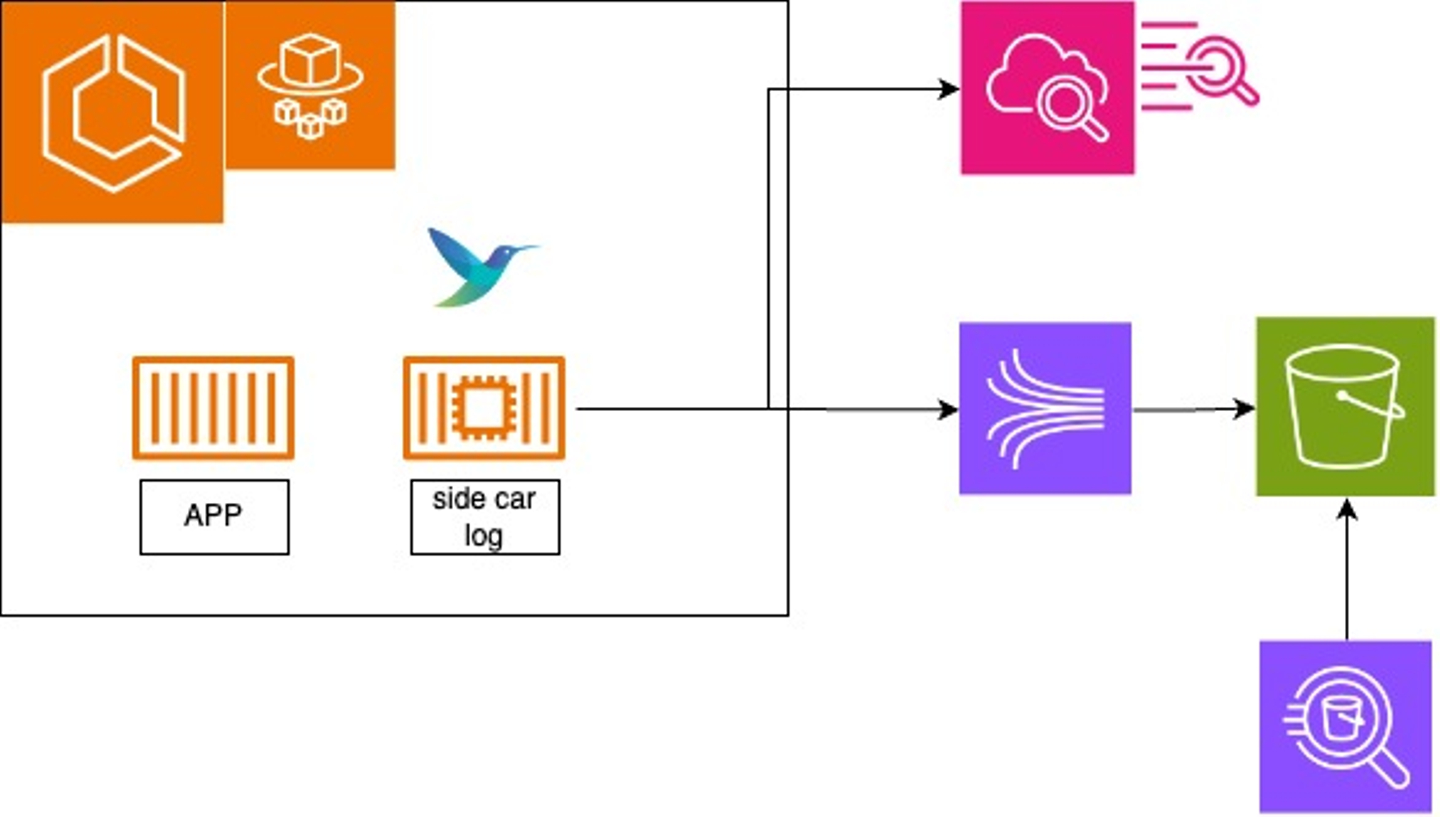
ログルーターのサイドカーを用意して、以下で分けました。 アラートが発砲したら、AthenaでS3のログを検索して調査します。
- ログレベルがエラー以上のログ:CloudWatchLogs→CloudWatchメトリクスフィルター→CloudWatch Alarm→SNS→Chatbot→Slack
- ログの全量:Kinesis Data Firehose→S3
具体的な設定ファイルは以下のような形で準備しました。
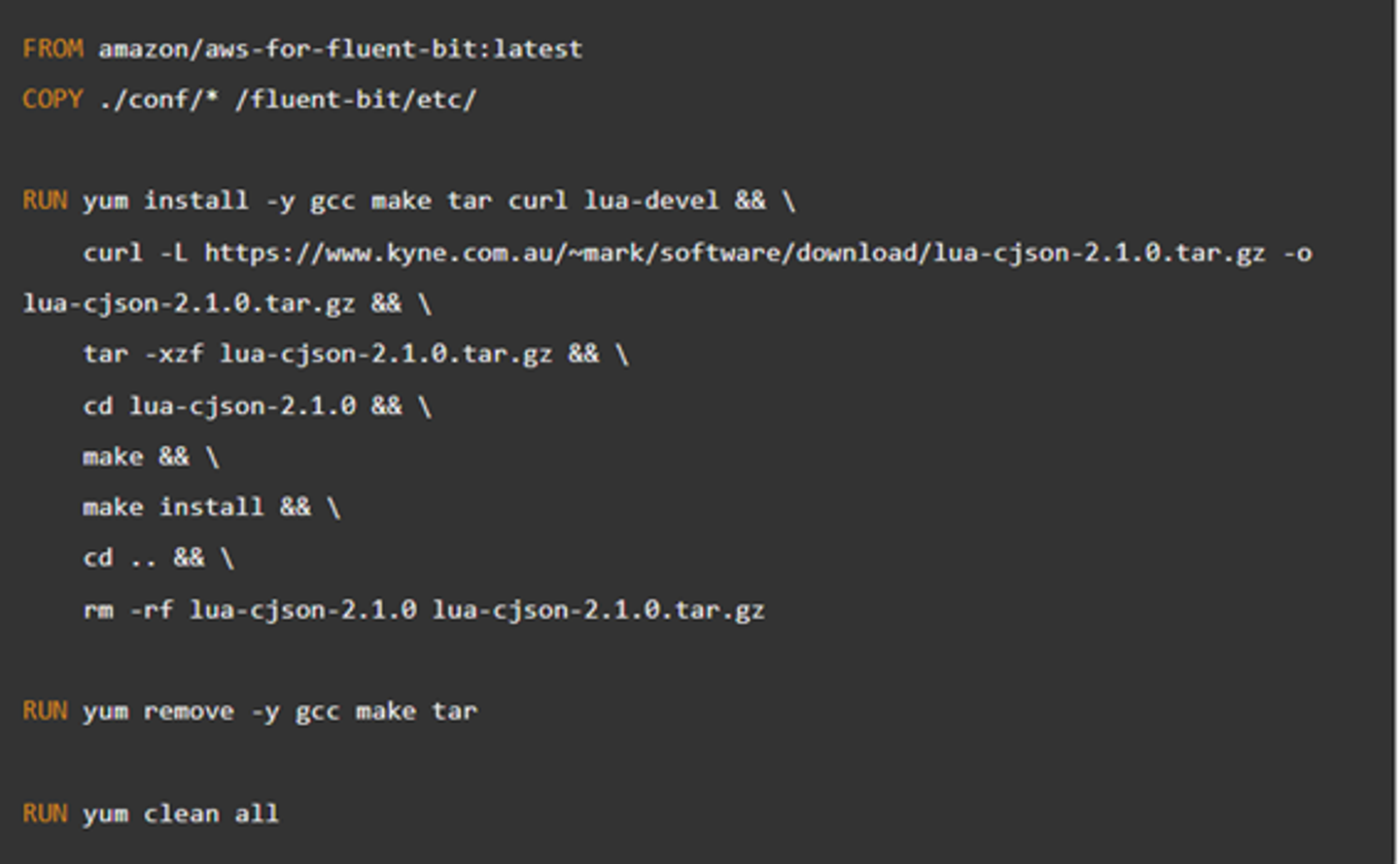
※Luaを使って、出力ログを加工しているので、いくつかのライブラリをインストールしていますが、そういう用途がなければ、最初の2行で動くと思います。
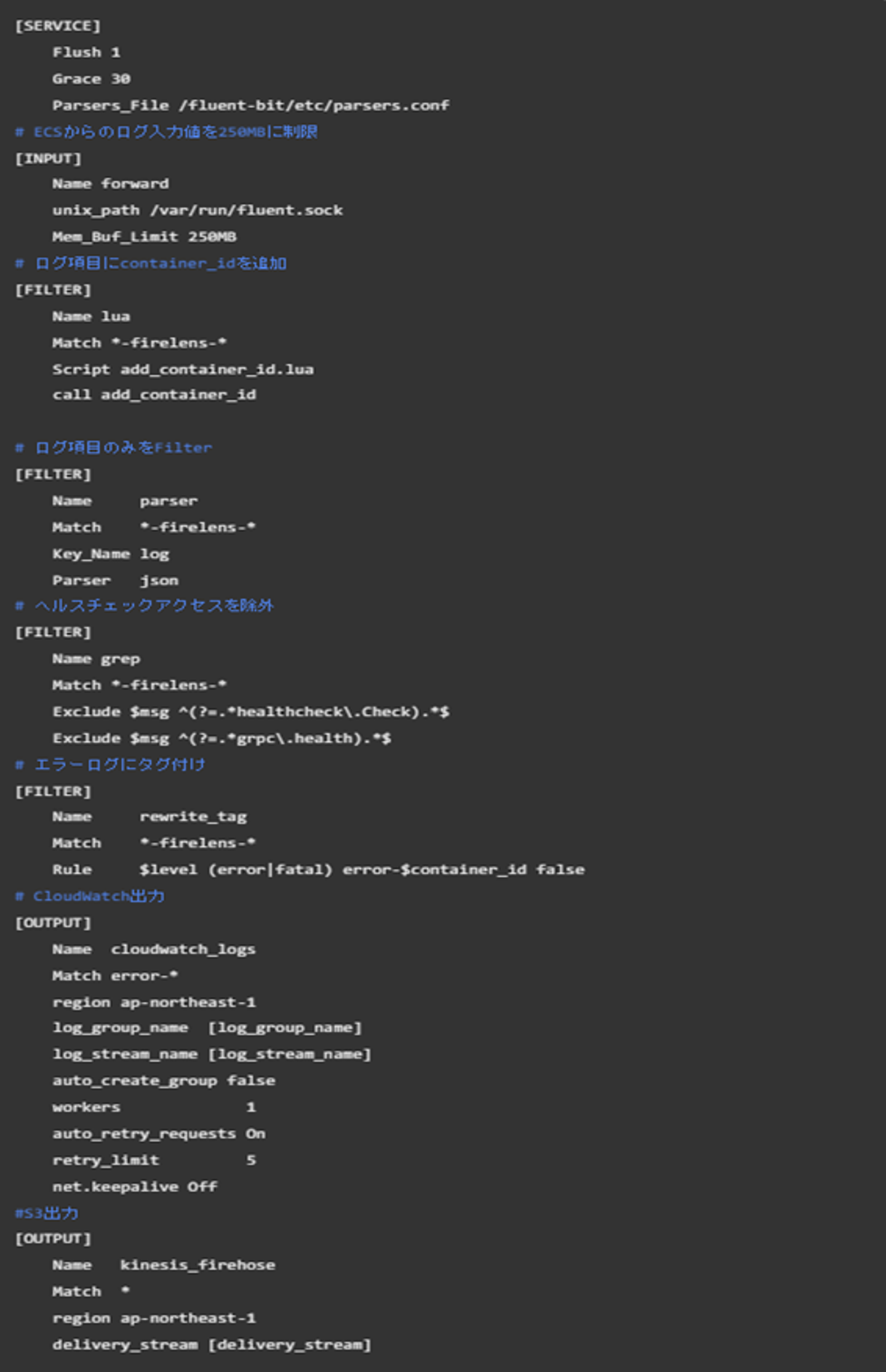
confファイルは大体こんな感じで用意しました。OutPutの部分で切り分けています。 こちらのDockerfileを使って、サイドカー用のイメージを作成し、ECRにPushします。
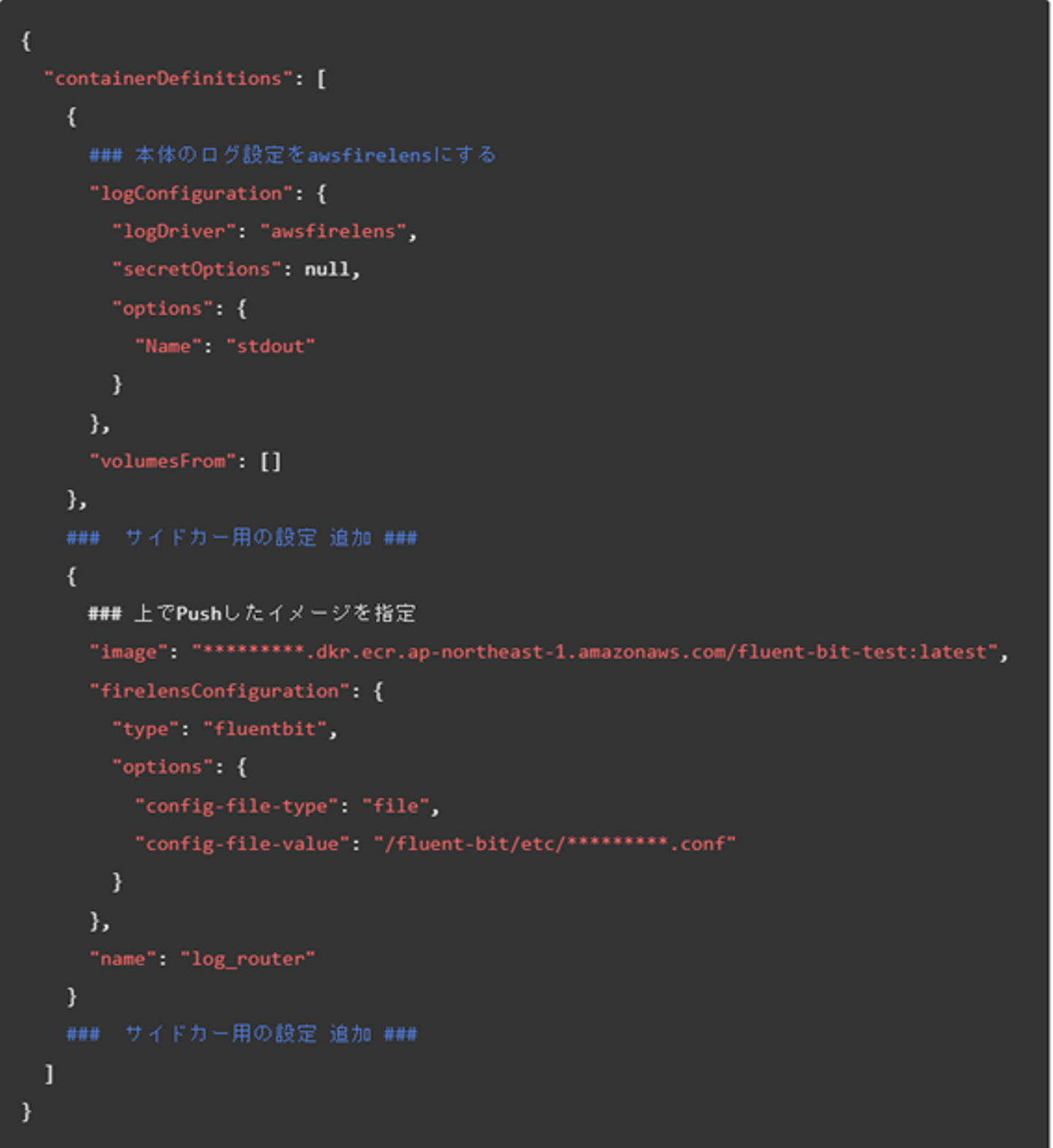
ECS側の設定はこんな感じです。簡単ですね。
4. メトリクス監視
ECSやRedisなどのメトリクスの監視を行います。 メモリ、CPUの使用率が閾値超えたら、オートスケールを行いつつ、Slackにも通知がくるようにしました。
ログと同じく、メトリクスフィルターでコンテナやRedisの使用率を測って、閾値超えたらアラートが発砲するようになっています。
通知の流れは、メトリクスフィルターで検知した閾値越えを、エラーログと同じフローでSlackまで流しています。
5. 外形監視
Synthetics Canariesを使用して、コンテナの外形監視を行います。 ヘルスチェック用のエンドポイントに向けて、リクエストを投げて、監視しています。 具体的に設定しているの以下の通りです。
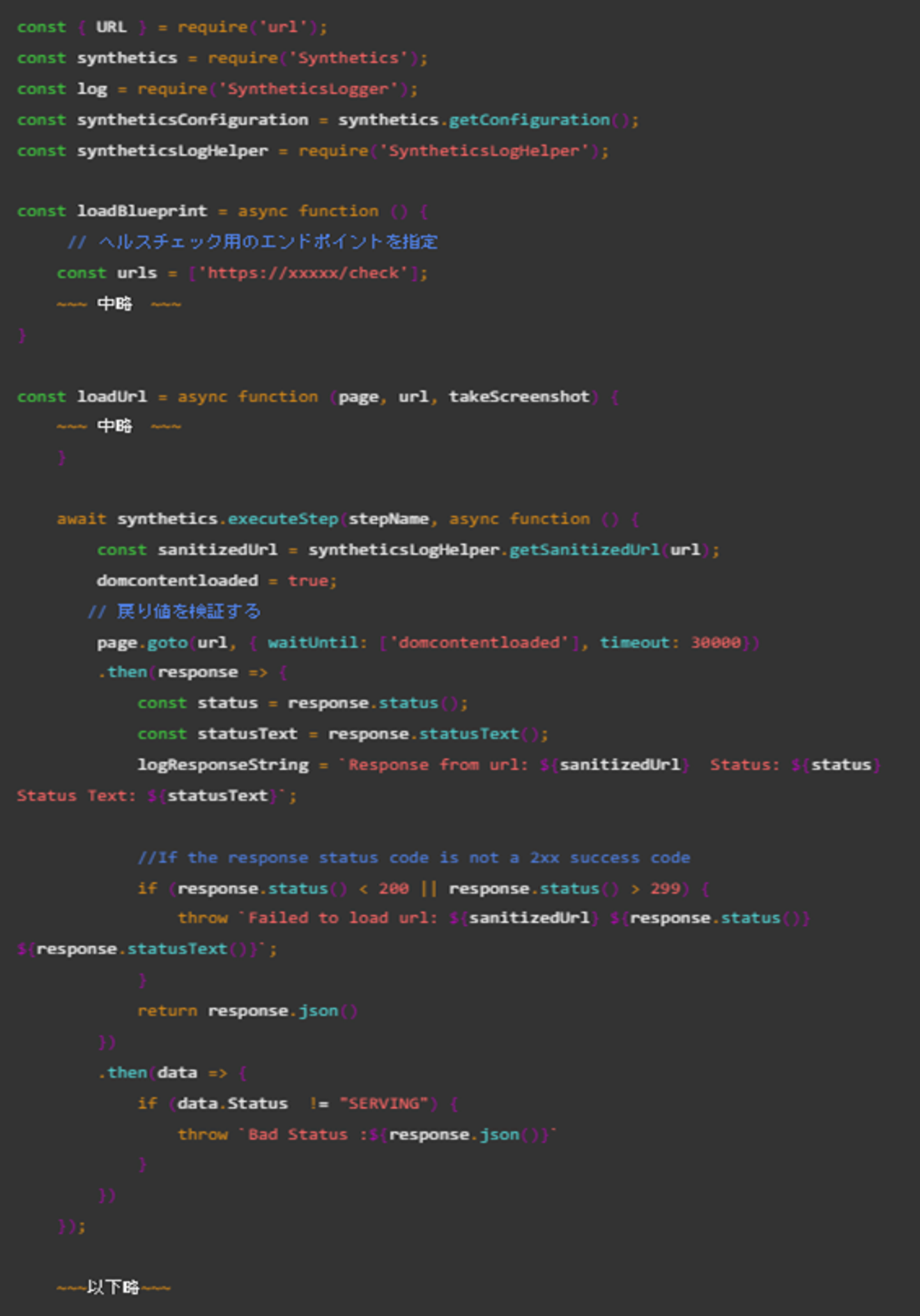
通知のフローはこちらもメトリクスフィルターで異常を拾ってSlackまで流し込んでいます。
5. まとめ
この仕組みを作って運用を開始し、お客様からお問い合わせいただく前にエンジニアがエラーについて検知し、 予め確認することができたり、大分運用がしやすくなったと思います。 ただ、まだ改善すべき点がある仕組みだと思いますので、これからも改善していきたいです。 導入してみて、成果があった監視や記事に関して、ご意見・ご感想を頂けますと幸いでございます。
参考
最後までお読みいただきありがとうございました。
◆ 他のBlogはこちらから⇒ https://tech.makeshop.co.jp/ ◆
ご応募お待ちしています!

/assets/images/32062/original/9178d6ef-9569-4fc7-8f84-ecd75cfcc597?1596514385)
/assets/images/32062/original/9178d6ef-9569-4fc7-8f84-ecd75cfcc597?1596514385)


