こんにちは、LAPRASのPRを担当している伊藤哲弥です。
LAPRAS SCOUTのサービスの核となる機能には機械学習の技術が使われています。
代表的なものでは、候補者の転職可能性を予測したり、投稿内容から特徴的な語を抽出して重み付けする機能などに機械学習技術が活用されています。
<経歴情報を基にした転職可能性予測機能(生存時間分析)>
※LAPRASの他の機械学習技術についてはLAPRAS AI LABで紹介しています。
実は上記の他にも、クライアントや候補者には見えない、しかし非常に重要な部分にも機械学習技術を活用しています。
今回の記事では、機械学習を活用したメールのクオリティのフィルタについて、私と、機械学習エンジニアの池(ち)が紹介します。
数千件のメールを目視でチェックし、教師データに。
2017年5月にオープンβ版のサービス提供を開始してから今日に至るまで、LAPRAS SCOUTを通して送信されるスカウトメールは、原則としてすべて目視によって確認していました。
メールをチェックしていた理由は、エンドユーザーである候補者の体験を最優先するためです。LAPRASでは企業側が一方的に、テンプレートをばらまくようなスカウトメールは、多くの候補者にとって不快な体験をもたらすと考えています。
LAPRASでは、エンドユーザーのメリットを最優先しようという想いがあります。
その想いに則り、スカウトメールのクオリティガイドラインを設けており、クオリティに満たないスカウトメールは、クライアントの許可を待たずに送信を取り消しています。
(クオリティをチェックする役割(ロール)も存在します)
実は、これまでこのチェックは非常にアナログに、目視で確認をしていました。
サービス開始から数千件のスカウトメールを人力で確認してきたことになります。
今年になって、ようやくここに機械学習の技術を取り入れることができました。
これまでに目視で送信可否の判断をつけてきたスカウトメールは、教師データとして活用しました。
どのように人力から機械学習でのチェックに切り替えたのかは、機械学習エンジニアの池から紹介します。
人力で分類したメールを教師データにしてモデルを構築
こんにちは。機械学習エンジニアの池です。
メールの品質チェックを行う機械学習モデルの開発を担当しました。
今回のプロジェクトで解決を目指した課題は3つありました。
- LAPRASは候補者名、所属、自動生成文面などを変数名の指定だけで自動入力になるが、自動変換されていない変数名が送信予定メールに含まれている
- 送信予定メールの中にプレースホルダー(ダミー文章)が入っている
- 送信予定メール内容がクオリティガイドラインに達していない
いずれもエンドユーザーにそのまま届いてはいけないもので、メールの品質チェックで除外する必要があります。しかし、チェックを必要とするメールの数はかなり多く、相当な時間がかかる単純作業であるため、今回は機械学習の力を借りて作業効率を向上させることを目指しました。
データ観察と問題定義
作業の第一ステップとしてまず過去の送信予定メールデータ(送信されたメールと送信が取り消されたメールを含む)をざっと眺めてみました。機械学習モデル作成において、対象となるデータをまず眺めて、データの傾向、パターンなどを把握する必要があるからです。
データを見た結果、課題1と2は人による操作ミスから発生した問題であることがわかりました。具体的にいうと、課題1はメールに変数を入力する時にスペルミスで間違った変数名を入力したのが主な原因で、課題2はメール内プレースホルダーの書き換えを忘れていたのが原因でした。
幸いなことにいずれも一定のミスパターンがありました。
課題1の場合は、例えば正しい変数名 {{surname}}に対して、
- 波括弧の数が合わない :
{surname}} - 変数名にスペルミスが存在 :
{{sirname}}
といったパターンがあり、課題2の場合は、 '●●', '$$', '##', ... など限られた種類の記号がプレースホルダーとして使われているパターンがあることがわかりました。
したがって、課題1は正規表現を使って波括弧の数があっているか、波括弧の中身にスペルミスが存在しないかをチェックする対策をとりました。一方、課題2では全てのあり得るプレースホルダーをもつ辞書を作成し、該当辞書にあるプレースホルダーが送信予約メール内に含まれているか否かをチェックすることで対応しました。
最も重要なのが課題3です。課題3は間違ってはいない文章のクオリティを判定するため、やや難易度が高く色々な試行錯誤が必要でした。その詳細を語る前にまず、送信予約メール内容の良し悪しを判定するクオリティガイドラインについて話します。
我々は現在、スカウトメールの善し悪しを以下の2つの基準から判定しています。
- 個人言及:エンドユーザーのアウトプットに関して言及しているか
- コメント:そのアウトプットに対する感想など何らかのコメントをしているか
メールに以上の2点(我々はパーソナライズと呼びます。)を加えるとエンドユーザーに親和性をもたらすと共に、メール送信側の真正性も表すことができ、返信率が上がることを我々は事前検証からわかっているからです。
従って、結局メール内にクオリティガイドラインを満たすセンテンス(sentence)が存在するか否かを機械学習技術によって判定し、存在すれば正常メール、存在しなければ異常メールとメールを分類できれば、課題3は解決したことになります。
評価基準
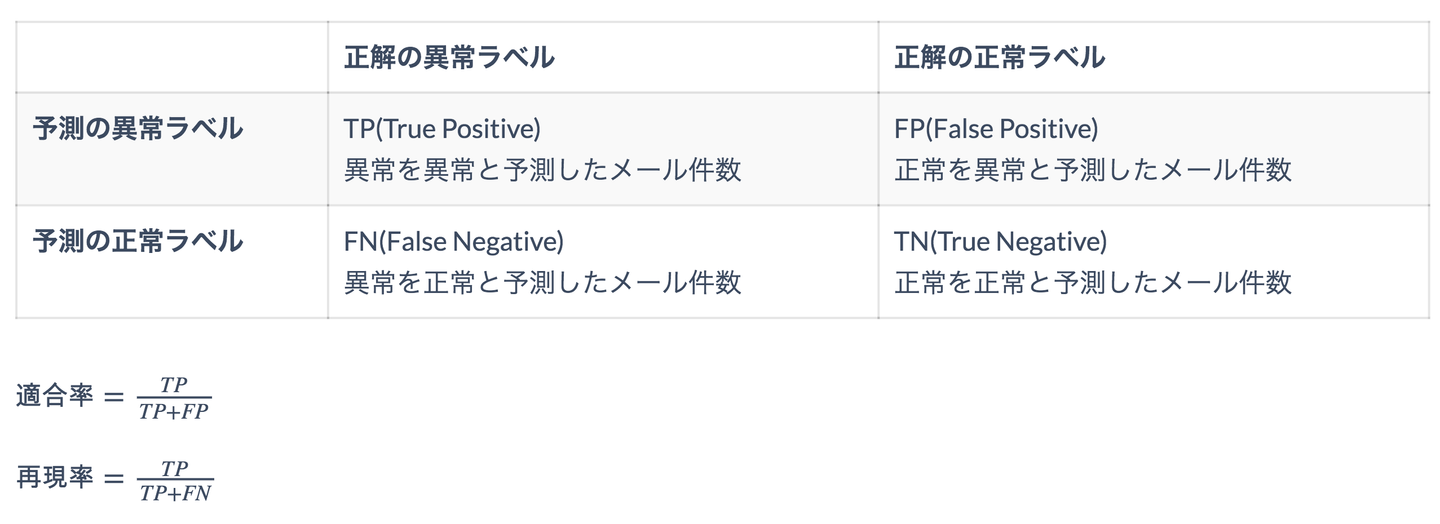
今回作成したモデルの評価には機械学習の分類問題でもっとも良く使われている適合率(Precision)と再現率(Recall)を使います。
適合率、再現率の計算は、既存メールに付けられた正解の正常、異常ラベルとモデルで予測した正常、異常ラベル結果を用いて計算します。今回の異常メール検知課題に代入すると以下のように解釈できます。
![]()
上の式から適合率はモデルが異常メールと予測した結果がどれぐらいの正解率を持っているか、再現率は見つけるべき異常メールのうちどれぐらい見つけたのかを表すことがわかります。言い換えると、適合率はモデルの信頼性、再現率はモデルの検知力を表しているのです。
今回の場合は、一定の再現率を担保することで異常メールの検知漏れを抑えた上で、なるべく高い適合率を実現するようなモデルの構築を文目指します。
モデルの構築と評価
課題解決に向けて我々は二つのアプローチを考えていました。
- データを望めた結果、ほぼ全てのメールがLAPRAS SCOUTで提案したメールテンプレートに情報を埋め込んだ上で、クオリティ基準を満たすセンテンスを追加した構成になっている。従って、メール内容とテンプレートの類似度を計算して、類似度の値が閾値以上なら正常メール、その他は異常メールと判定できるはず。
- 1のアプローチだと個人言及とコメントセンテンスンテンスの有無は判定できるが、それ自体の善し悪しは判定できないため、精度が低い恐れがある。もうちよっと粒度を細かくして、センテンスレベルで判定できるともっと精度が上がるはず。
類似度による判定
単純にメール内容やテンプレート内容を文字列だと考え、文字列間の類似度を計算して、異常メールを判定するというアプローチです。
テンプレートメールと送信予約メールの差分は、
- テンプレートのプレースホルダーと送信予約メールで埋められた該当情報
- 個人言及とそのコメントセンテンス
と二つから起因することが考えられます。
従って、テンプレートのプレースホルダーと送信予約メールで埋められた情報が類似度に対する影響が少ないと言う仮定の元、類似度から個人言及とコメントセンテンスがあるメールとないメールが区別できると思っていました。
今回類似度の計算では、python標準ライブラリdifflibのうち、SequenceMatcherと言うモジュールを使いました。
その結果、以下のような結果になりました。
![]()
もっと詳細的にいうと、今回の評価で4件の異常メールを含む282件のメールデータをモデルに投入した時に、モデルが異常だと検知したのが10件で、そのうち4件が本当の異常メールでした。単に数値からみるとこのモデルを使った場合、元々282件のメールを目視でチェックしなければならなかったのが、今度は10件だけを目視でチェックすれば良いということになります。
ここまででもある程度業務改善にはなっていますが、やはり個人言及やコメントセンテンスにも
- 短い文章だけど親和性がある
- 長い文章だけどアウトプットを並ぶだけでコメントセンテンスがない
など色々とバリエーションが多く粒度の細かいレベルでの評価しないと「アウトプットを並べて長い文章を追加する」だけで正常メールだと判定されるのを防げないところが気になりました。
まだ今回のモデリングで使ったメール数が1,150件とかなり少ない数であるため、パーソナライズ部分の多様性が増えた場合、モデルの精度が急激に下がる可能性があると判断しました。
従って、センテンスベースでの判定と言う粒度の細かいレベルのアプローチを試しました。
センテンスベース判定
センテンスベース判定の基本的な考え方は以下のようになります。
- メールをセンテンスの集合だと考える
- 各センテンスが個人言及センテンス(S1)、コメントセンテンス(S2)、個人言及とコメント両方含むセンテンス(S3)、その他(S0)と4分類の内どの分類に属すかをモデルによって判定
- メールがS2かS3センテンスを持っている場合正常メール、そうでない場合異常メールと判定
この考え方によるとメール分類問題がセンテンス分類問題に落とされるため、
- データ量が一気に増える
- 個人言及とコメントセンテンスがあるかないか、センテンス内容が良いか悪いかによってメールの異常判定をすることになる
といったメリットがあります。
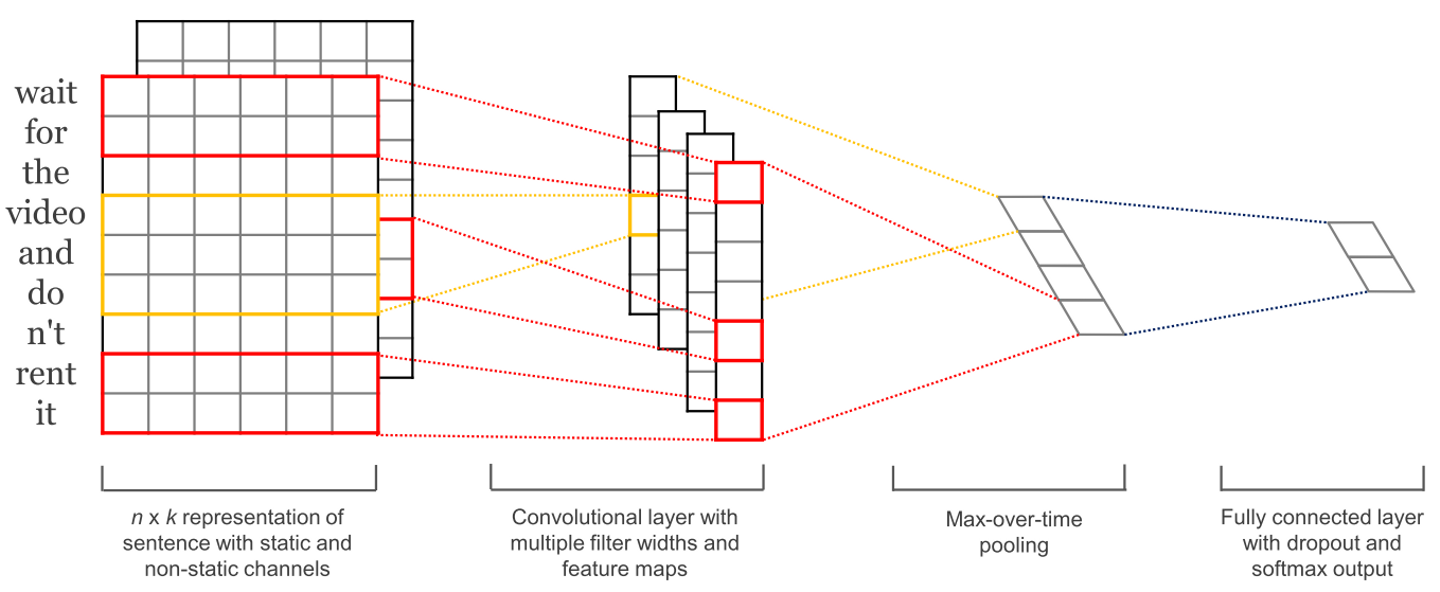
今回はデータ量が充分あると言うことだったので、センテンス分類のニューラル・ネットワーク・モデルであるTextCNN法を用いることにしました。
モデリングに使ったセンテンスデータ詳細
![]()
TextCNN法のネットワーク構成(詳細はTextCNNによる日本語評判文書分類を参照してください)
![]()
自然言語モデルの応用に置いて、単語をベクトルに変換し、それをモデル入力として使うのが一般的でTextCNNの場合、
- 単語にランダム初期値のベクトルを与え、学習が進むに連れて単語ベクトルを学習する
- 事前に学習された単語ベクトルを初期値として与え、学習が進むに連れて単語ベクトルを学習する
という二つのパターンがありますが、今回は学習が速く、精度が上がるといった理由から事前に「日本語版 Wikipedia」の本文全文から学習された単語ベクトルを初期値として用いることにしました。
また、LAPRASではモデリングにTensorFlow(機械学習ライブラリ)を用いていますが、GitHub上に共有されているソースコードにはTextCNN法のtensorflow version完全実装がなかったため、完全実装し公開しました。
TextCNNでセンテンスベースの判定を行なった結果、
![]()
と高い適合率と再現率をもつモデルが構築できました。 詳細を見ると、今回は2,890件の異常メールを含む4,302件のメールデータをモデル評価で使ったときに、3,097件が異常と検知され、そのうち2,791件が本当の異常メールでした。
今回のモデルを使う場合、異常と検知したメールの90%ぐらいが本当の異常メールであると期待されるため、要チェックなメール数が減るのはもちろん、その品質も高く、業務効率が相当上がることになります。ただ、再現率が100%ではないと言うことで、本当の異常メールの内3%ぐらいが正常メールと判定される恐れがあります。
モデルから得たパーソナライズセンテンス
0 Githubにて積極的にリポジトリを公開されているだけでなく、「 OUTPUTTITLE 」や「 OUTPUTTITLE 」等のカンファレンスに参加される等、最新技術のキャッチアップに積極的な点において大変魅力を感じております
1 PERSONNAME様のQiita等を拝見し、深い機械学習の知見をお持ちであるところが目にとまり不躾ながらご連絡させていただいた次第です
2 複雑で理解が難しいトピックについて自分で手も動かしながら 基礎的な部分を丁寧に理解して、それを分かりやすく説明することが できる方だな、と感じ、まさに弊社の求める人材像に マッチしていると思いました
3 また、ユーザーテストに関する記事もいくつか書いておられましたが、弊社でも実際に利用する方々にプロトタイプを操作してもらい、コメントや観察からフィードバックを得てサービスの改善に繋げる取り組みを行っており、技術や機能だけでなくユーザービリティやそれを含んだUXにも配慮して開発される方なのかなと感じました
4 今回、 PERSONNAME 様のQiitaの「 OUTPUTTITLE 」という投稿を拝見したのですが、クラウド前提での開発をする際のメリットデメリットが大変良くまとまっていて、業務レベルでのキャッチアップを日常的にしていると推測され、大変魅力を感じました
5 いずれの記事もVue.jsのテスト環境について PERSONNAME 様の積極的なアウトプットをされようとする気持ちや技術へのご興味が伝わってまいりました
6 書籍から興味をもって PERSONNAME さまのWantedlyを拝見したところ、ソフトウェアエンジニアとしてフロントエンドを中心にしつつも、バックエンドの経験もお持ちであることを確認しました
7 Qiitaの記事を拝見させて頂きましたが、特に「 OUTPUTTITLE 」およびコンテナ編では、実際に PERSONNAME 様が開発からデプロイまでの構築を行ったことが良く分かりました
8 その中でも「 OUTPUTTITLE 」や「 OUTPUTTITLE 」は興味深く読ませていただきました
9 以前Laravel Vue.js勉強会にご参加いただきありがとうございましたまたGitHubを拝見させていただき、schedule calendarやdocker laravelなどを公開されており、LaravelやVue.jsに関して興味がある方かなと思い、ご連絡させていただきました
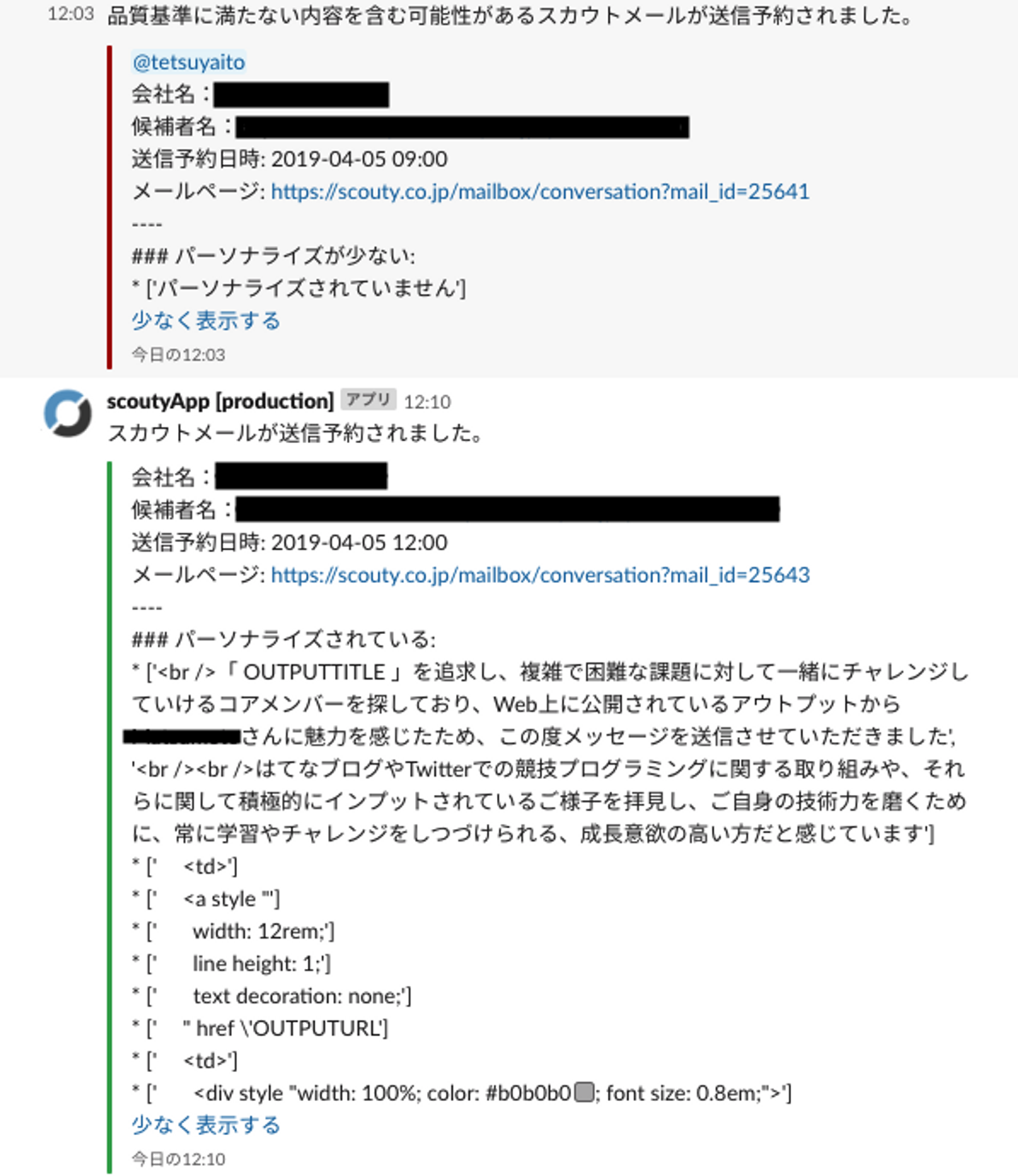
最後に、LAPRASではパーソナライズが十分でなく、候補者にとって不快に感じられるメールは下記の画像のようにSlackにアラートを通知して随時確認する体系を整っています。
![]()
本モデルを業務へ投入して2ヶ月弱になりますが、現時点での実績を見ると、精度は90%ほどと予想通りの動きをしています。
ただ、「メールの正解ラベルつけを一人で行ったため、かなりの主観的な基準が働いている」と言う理由からもうちょっと客観的な正解ラベルが得られたらより精度が高くなるのではないかと思っております。従って、Slackで投げられたアラートをみて明らかに予測結果がおかしい場合、ラベルを付け直したデータを積極的に集めています。
おわりに
最後に再び、私伊藤からまとめさせていただきます。
現在は、90%の精度ですので、いくつかのメールはチェックをすり抜けてしまうことが予想されます。そこで、ユーザー体験を損なわないために、導入直後のクライアントを中心に人力のチェックも併せて実施しています。
しかし、将来的にはモデルの精度を向上させて機械学習モデルでのチェックのみの体制を敷いていきたいと考えています。ビジネスのスケールに比例してこういった単純作業は増えていきます。労働集約から抜け出すためにはシステムで代替していかなければいけません。
LAPRASには、アンチ労働集約というバリューもあります。
エンドユーザーのメリットを最優先すること、アンチ労働集約、どちらも叶えるためのソリューションが機械学習技術でした。
世の中にはこういった肥大化する、人間がやるべきではない作業が多くあります。
LAPRASでは、今後もこういった社内の業務についても機械学習技術を用いて解決していこうと考えています。
LAPRAS株式会社's job postings
/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)






/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)




/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)
